
基于翻转梅尔频率倒谱系数的语音变调检测方法
2019-01-06 07:27林晓丹邱应强
计算机应用 2019年12期
林晓丹 邱应强


摘 要:语音变调常用于掩盖说话人身份,各种变声软件的出现使得说话人身份伪装变得更加容易。针对现有变调语音检测方法无法判断语音是经过了何种变调操作(升调或降调)的问题,通过分析语音变调在信号频谱,尤其是高频区域留下的痕迹,提出了基于翻转梅尔倒谱系数(IMFCC)统计矩特征的电子变调语音检测方法。首先,提取各语音帧 IMFCC及其一阶差分;然后,计算其统计均值;最后,在该统计特征上利用支持向量机(SVM)多分类器的设计来区分原始语音、升调语音和降调语音。在TIMIT和NIST语音集上的实验结果表明,所提方法无论对于原始语音、升调语音还是降调语音都具有良好的检测性能。与MFCC作为特征构造的基线系统相比,所设计的特征的方法明显提高了变调操作的识别率。在较少的训练资源的情况下,所提方法也获得了比基于卷积神经网络(CNN)的框架更好的性能;此外,在不同数据集和不同变调方法上也都取得了较好的泛化性能。
关键词:语音变调;翻转梅尔频率;倒谱系数;统计矩;多分類
中图分类号: TN912.3文献标志码:A
Disguised voice detection method based on inverted Mel-frequency cepstral coefficient
LIN Xiaodan*, QIU Yingqiang
(College of Information Science and Engineering, Huaqiao University, Xiamen Fujian 361021, China)
Abstract: Voice disguise through pitch shift is commonly used to conceal the identity of speaker. A bunch of voice changers substantially facilitate the application of voice disguise. To simultaneously address the problem of whether a speech signal is pitch-shifted and how it is modified (pitch-raised or pitch-lowered), with the traces of the electronic disguised voice in the signal spectrum especially the high frequency region analyzed, an electronic disguised voice detection method based on statistical moment features derived from Inverted Mel-Frequency Cepstral Coefficient (IMFCC) was proposed. Firstly, IMFCC and its first-order difference of each voice frame were extracted. Then, its statistical mean was calculated. Finally, on the above statistical feature, the design of Support Vector Machine (SVM) multi-classifier was used to identify the original voice, the pitch-raised voice and the pitch-lowered voice. The experimental results on TIMIT and NIST voice datasets show that the proposed method has satisfactory performance on the detection of the original, pitch-raised and pitch-lowered voice signals. Compared with the baseline system using MFCC as feature construction, the method with the proposed features has significantly increased the recognition rate of the disguise operation. And the method outperforms the Convolutional Neural Network (CNN) based framework when limited training data is available. The extensive experiments demonstrate the proposed has good generalization ability on different datasets and different disguising methods.
Key words: voice disguise; inverted Mel-frequency; cepstral coefficient; statistical moment; multi-classification
0 引言
语音变调能够改变说话人的声音特征。变调语音除了具有娱乐功能外,还可用于说话人身份的伪装。传统的非电子变调方法是通过捏住鼻子或捂住嘴巴等物理方法来实现[1]。近年来,各种变声软件的出现,极大地方便了人们对声音的变调处理。通过电子变声的语音,还能获得较好的语音自然度。已有的研究表明,变调伪装语音将会严重影响说话人识别系统的性能[2]。倘若犯罪分子通过变声器伪装身份进行互联网或电话诈骗,将给案件侦破和司法鉴定带来前所未有的挑战。因此,如何自动检测语音是否经过变调是信息安全和司法取证领域一个亟待解决的问题。
在语音伪装的检测问题上,目前更多的研究针对的是语音合成和语音转换的检测[3-4]。这类语音伪装的目标是为了提高说话人识别系统的错误接受率,即:伪装语音可以欺骗说话人识别系统从而实现非法闯入的目的。本文的研究对象是另一类伪装语音,即:通过电子变调的方法实现语音伪装。这类伪装的目标是提高人耳或说话人识别系统的错误拒绝率,从而掩饰说话人身份。文献[5]提出了基于梅尔倒谱系数(Mel-Frequency Cepstral Coefficient, MFCC)的变调语音检测方法,该方法通过多个支持向量机(Support Vector Machine, SVM)分类器的设计并采用投票表决机制在变调语音的检测问题上取得了良好的效果。文献[6]提出了一种将MFCC特征参数用于高斯混合模型的训练从而获得变调语音的检测特征。该方法在少量的数据集上能够鉴别语音是否经过变调,然而缺乏在更丰富的数据集上的验证。文献[7]在短时傅里叶谱的基础上,將卷积神经网络用于变调语音的鉴别并取得了优异的检测性能。然而,上述方法缺乏对语音变调痕迹的分析,也无法进一步甄别语音是经过升调或者降调处理。通过语音的升调操作,可使男声转换成女声;反之,利用降调操作,可使女声转换成男声。因此,判断语音经过了何种变调操作也具有重要的现实意义。文献[8]探索了卷积神经网络在原始语音、升调语音和降调语音检测方面的应用,该方法依赖于大量的标注训练样本,并且在原始语音和升调语音的区分上仍存在较大的提升空间。
本文的研究表明,尽管MFCC在说话人识别等应用场合中取得了良好的性能,然而在语音变调检测的问题上,该特征并非是最优的。针对语音是否经过变调以及经过了升调或者降调的问题,在深入研究语音变调原理的基础上,本文提出了一种基于翻转梅尔倒谱系数(Inverted MFCC, IMFCC)统计特征的方法用于语音变调操作的检测。
1 语音变调的基本原理
基音是语音的一个重要参数,在语音识别、语音合成、说话人识别等应用中具有重要的意义。当前变声软件主要采用的是通过修改声音基频的方式进行变声。语音变调方法基本可归为两类:时域变调和频域变调。这两类方法都能够实现变调不变速,并保持变调后语音较高的自然度。典型的时域变调法有:SOLA-FS(Synchronized OverLap-Add and Fixed Synthesis)[9-10]、TD-PSOLA(Time-Domain Pitch Synchronized OverLap-Add)[11]、WSOLA(Waveform Similarity OverLap and Add)[12]等。其基本原理是通过信号在时域上抽取或内插改变语音信号音调,信号抽取可实现语音升调,信号内插实现降调。在此基础上进行时长规整使语速保持不变,具体为:利用帧插入实现时域拉伸,利用帧删除实现时域压缩。频域变调的典型方法有:FD-PSOLA(Frequency Domain Pitch Synchronized OverLap-Add)[13]、相位声码器法[14]等。这类方法直接在频域中进行信号插值抽取,或通过调整信号幅度、频率参数从而实现变调。为了保持相位连续性,频域变调方法通常会引入帧间重叠处理技术。
在语言学中,基音通常被认为最高降低或升高一个八度。世界上普遍采用的是12平均律将一个八度音分成12个相等的半音,相邻半音频率相差21/12倍。如果原始基音为f0,那么按照12平均律修改后的基音为f0′,则f0′和f0应满足如下关系:
f0′ = 2N/12×f0; N = ±1,±2,…,±11(1)
当N>0时为升调,N<0时为降调。N每升高或减少1,音调就升高或降低一个半音。文献[6]指出,在取证应用中,N取[-8,-4]和[4,8]是较好的选择。因为N太小变调不明显,无法掩盖说话人身份,N太大又容易引起怀疑,因此,本文仅考虑这一范围的变调。图1给出了使用Adobe Audition CS6软件对语音进行N =6和N =-6变调前后的音调变化轨迹图。由图1可见,语音升调将导致基音频率发生上移,降调将导致基音频率发生下移。从图1中还能发现变调前后的基音变化轨迹在时间轴上还存在一定程度的不同步现象。其中可能的原因是语音信号在时间规整过程采用的分析窗和合成窗长度、偏移量不一致。对于变调导致的时间轴失真可以利用频谱的动态特性进行捕获。
除了基音的变化,还能从语音的时频谱变化中找到变调对于语音的影响。图2给出了原始语音、同一语音经过N =6的升调语音、同一语音经过N =-6的降调语音的语谱图,使用的变调工具为AUDICITY[15]、ADOBE AUDITION[16]、PRAAT[17]、RTISI(Real-Time Iterative Spectrogram Inversion)[18]。其中,PRATT和RTISI分别采用时域TD-PSOLA和频域FD-PSOLA变调方法。而AUDICITY和ADOBE AUDITION所使用的变调方法未知。从图2中可以看出,变调将使语音的频谱发生搬移,具体为:降调语音的频谱被压缩,升调语音的频谱被扩展。因此,降调语音在高频区频谱分布较为稀疏,而升调语音相对原始语音和降调语音具有更高的频率分辨率。因此,高频区域频谱特征的分析在区分变调语音和原始语音时起了至关重要的作用。为了更好地捕获变调语音和原始语音在高频区的差异,本文使用在高频区域计算精度更高的翻转梅尔滤波器组并结合倒谱分析获得语音的频谱特性。
2 基于IMFCC的语音变调检测
由于MFCC的设计是为了模拟人耳的听觉特性,因此所使用的滤波器更注重低频区,在低频区具有更好的计算精度,而对于中高频区的变化较不敏感。通过第1章的分析我们知道,提升高频区的信息分辨能力对于鉴别变调语音至关重要。翻转梅尔倒谱系数(IMFCC)能够弥补MFCC在高频区信息提取的不足,提高中高频信息的计算精度[19]。IMFCC采用的是如式(2)所示的频率变换:
使用的翻转梅尔滤波器组如图3所示。由图3可知,随着频率的增大,滤波器的带宽和间隔变小。翻转梅尔滤波器组正是利用这一特点提升了高频区的计算精度。此外,对于变调引起语音在时间轴上的不同步现象,将进一步利用IMFCC的动态特性进行描述。因此,本文选取19维的IMFCC系数(去除直流分量)和19维的差分特征ΔIMFCC用于区分原始语音、降调语音和升调语音。我们将变调语音的鉴别问题转换成一个三分类问题,因此可以利用机器学习中多分类器的设计实现这三类语音的鉴别。
2.1 特征提取
本文使用IMFCC及其一阶差分特征用于原始语音、升调语音和降调语音的识别。IMFCC特征提取方法如下:
1)对语音信号进行预加重、分帧和加窗处理。接着通过VAD(Voice Activity Detection)检测算法[20]判断语音帧是否为静音,若为静音则丢弃该帧。本文所用汉明窗长为512。
2)对加窗后的语音帧x(n)进行短时傅里叶变换,从而得到离散的功率谱X(k)。
3)由X(k)得到x(n)的能量谱,并采用图3所示的翻转梅尔滤波器组,按照式(3)进行滤波:
mi=∑N-1k=0X(k)2Hi(k); i=1, 2, …, P(3)
式中:Hi(k)为滤波器的频率响应;P为滤波器个数;N为傅里叶变换点数。
4)对mi进行对数变换得到输出对数能量谱。
5)将上述对数能量谱进行离散余弦变换(Discrete Cosine Transform, DCT),得到前20个DCT系数,即IMFCC系数。
6)对所得IMFCC特征求取差分,得到ΔIMFCC。
7)求取各语音帧所得IMFCC系数(去除直流分量)和ΔIMFCC的统计平均共38维特征作为提取的特征。
上述的特征提取使不同时长的语音可获得相同维度的統计特征,这些特征将被用于分类器的训练。利用t分布随机近邻嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)算法[23]对上述38维特征进行降维并映射到二维平面上,得到如图4所示的三类语音分布。图4中可见,本文设计的基IMFCC的统计特征能够将三类语音分离开来。相比降调语音,区分原始语音和升调语音的难度更大。
2.2 分类器设计
本文采用SVM用于原始语音、升调语音和降调语音的三分类。三分类SVM采用的实现方式是一对一方式,即:对于三分类问题将产生3个二分类器。对于待预测语音每个二分类器会产生一个输出标签0、1或2,把出现次数最多的标签作为最终预测输出。由于本文使用的变调语音共有10种变调因子,若训练集原始语音样本数是N,则对于同一种变调方法,升调样本和降低语音样本数各5N。由于变调语音样本数比原始语音大很多,为了保持样本平衡,从每种变调因子的语音中随机选取N/5的样本用作训练集。SVM的训练和测试流程如图5所示。其中,使用的核函数为式(4)所示的多项式核,实验中γ、C、d分别设置为1、1、2。
C(xi, xj) = (γxiTxj + C)d(4)
3 实验与结果分析
实验中使用两个不同的数据库TIMIT[21]和NIST[22],所有音频都是8kHz采样率,16比特量化。两个数据库具有不同的录音环境和录音设备。其中:TIMIT数据库包含630个不同的说话人,一共6300段音频;NIST数据库包括356个不同说话人,一共3560段音频。使用的变调工具包括AUDICITY、ADOBE AUDITION、PRAAT、RTISI,变调因子有10种,包括±4、±5、±6、±7、±8。变调语音仍保持8kHz采样率和16比特量化位数。3.1 同一数据集的检测结果
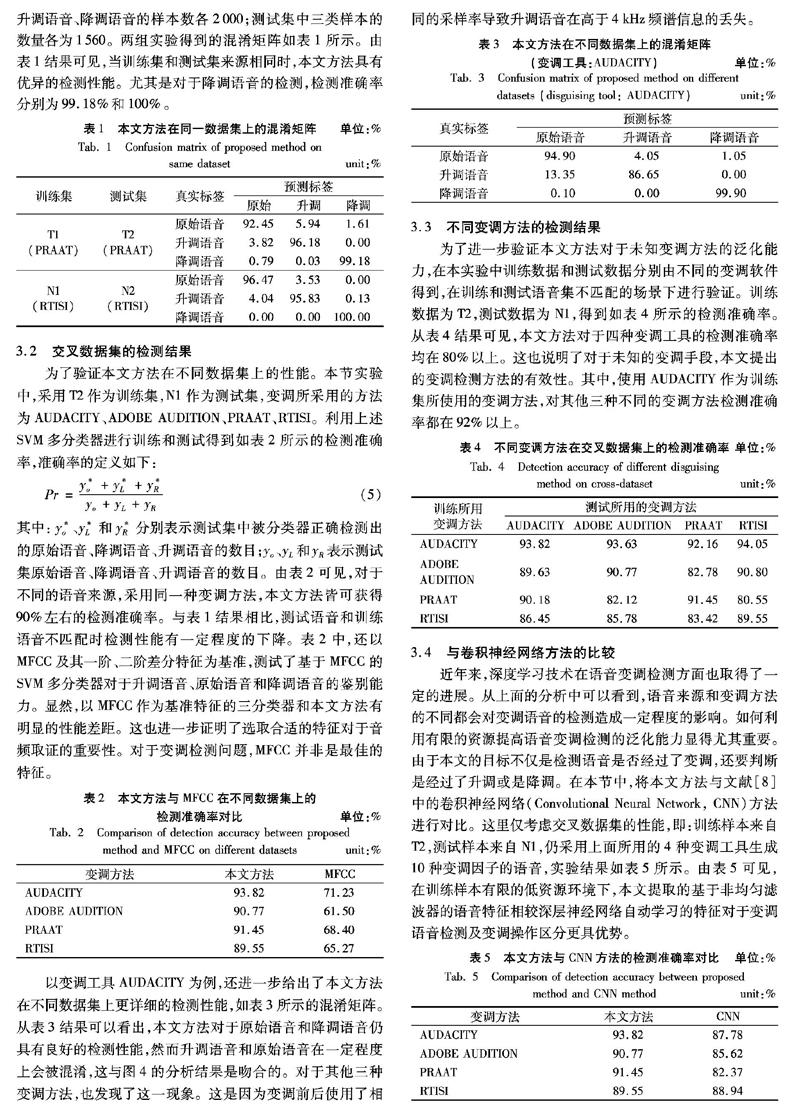
把TIMIT和NIST分成说话人不重叠的两部分,分别记为T1、T2和N1、N2。其中T1包含3000段语音,T2包含3300段语音;N1包含2000段语音,N2包含1560段语音。其中,TIMIT使用的变调方法是基于时域的PRAAT方法,NIST使用的变调方法是基于频域的RTISI方法。在第一组实验中,把T1及其对应的变调语音用作训练集,T2及其对应的变调语音用作测试集;此时训练集中的原始语音、升调语音、降调语音的样本数各3000;测试集中三类样本的数量各为3300。在第二组实验中,把N1及其对应的变调语音用作训练集,N2及其对应的变调语音用作测试集。此时训练集中的原始语音、升调语音、降调语音的样本数各2000;测试集中三类样本的数量各为1560。两组实验得到的混淆矩阵如表1所示。由表1结果可见,当训练集和测试集来源相同时,本文方法具有优异的检测性能。尤其是对于降调语音的检测,检测准确率分别为99.18%和100%。
3.2 交叉数据集的检测结果
为了验证本文方法在不同数据集上的性能。本节实验中,采用T2作为训练集,N1作为测试集,变调所采用的方法为AUDACITY、ADOBE AUDITION、PRAAT、RTISI。利用上述SVM多分类器进行训练和测试得到如表2所示的检测准确率,准确率的定义如下:
Pr=y*o+y*L+y*Ryo+yL+yR(5)
其中:y*o、y*L和y*R分别表示测试集中被分类器正确检测出的原始语音、降调语音、升调语音的数目;yo、yL和yR表示测试集原始语音、降调语音、升调语音的数目。由表2可见,对于不同的语音来源,采用同一种变调方法,本文方法皆可获得90%左右的检测准确率。与表1结果相比,测试语音和训练语音不匹配时检测性能有一定程度的下降。表2中,还以MFCC及其一阶、二阶差分特征为基准,测试了基于MFCC的SVM多分类器对于升调语音、原始语音和降调语音的鉴别能力。显然,以MFCC作为基准特征的三分类器和本文方法有明显的性能差距。这也进一步证明了选取合适的特征对于音频取证的重要性。对于变调检测问题,MFCC并非是最佳的特征。
以变调工具AUDACITY为例,还进一步给出了本文方法在不同数据集上更详细的检测性能,如表3所示的混淆矩阵。从表3结果可以看出,本文方法对于原始语音和降调语音仍具有良好的检测性能,然而升调语音和原始语音在一定程度上会被混淆,这与图4的分析结果是吻合的。对于其他三种变调方法,也发现了这一现象。这是因为变调前后使用了相同的采样率导致升调语音在高于4kHz频谱信息的丢失。
3.3 不同变调方法的检测结果
为了进一步验证本文方法对于未知变调方法的泛化能力,在本实验中训练数据和测试数据分别由不同的变调软件得到,在训练和测试语音集不匹配的场景下进行验证。训练数据为T2,测试数据为N1,得到如表4所示的检测准确率。从表4结果可见,本文方法对于四种变调工具的检测准确率均在80%以上。这也说明了对于未知的变调手段,本文提出的变调检测方法的有效性。其中,使用AUDACITY作为训练集所使用的变调方法,对其他三种不同的变调方法检测准确率都在92%以上。
3.4 与卷积神经网络方法的比较
近年来,深度学习技术在语音变调检测方面也取得了一定的进展。从上面的分析中可以看到,语音来源和变调方法的不同都会对变调语音的检测造成一定程度的影响。如何利用有限的资源提高语音变调检测的泛化能力显得尤其重要。由于本文的目标不仅是检测语音是否经过了变调,还要判断是经过了升调或是降调。在本节中,将本文方法与文献[8]中的卷积神经网络(Convolutional Neural Network, CNN)方法进行对比。这里仅考虑交叉数据集的性能,即:训练样本来自T2,测试样本来自N1,仍采用上面所用的4种变调工具生成10种变调因子的语音,实验结果如表5所示。由表5可见,在训练样本有限的低资源环境下,本文提取的基于非均匀滤波器的语音特征相较深层神经网络自动学习的特征对于变调语音检测及变调操作区分更具优势。
4 结语
随着各种变声软件的出现,电子伪装语音将具有巨大的应用前景,然而也給司法鉴定带来新的挑战。本文针对电子变调语音的取证问题,在两种不同的语音变调算法和两种常用语音编辑软件的基础上提出了一种基于翻转梅尔倒谱特征和多分类SVM的变调语音检测方法。相较现有的研究,本文方法深入分析了语音变调原理,研究了变调在信号时域和频域留下的痕迹,并在此基础上找到更好的检测特征。该特征不仅能检测语音是否经过变调,对于变调语音,还能进一步区分语音是经过了升调或者降调操作。本文的研究结果为变调语音鉴定提出了新的思路,即:梅尔倒谱特征更注重人耳的听觉特性,然而在取证问题方面并非是最佳的特征。此外,在训练样本有限的低资源环境下,本文方法获得了比卷积神经网络更好的性能。本文方法对不同说话人、不同录音场景和未知变调方法也具有较好的泛化性能。
参考文献 (References)
[1]PERROT P, AVERSANO G, CHOLLET G. Voice disguise and automatic detection: review and perspectives [M]// STYLIANOU Y, FAUNDEZ-ZANUY M, ESPOSITO A. Progress in Nonlinear Speech Processing, LNCS 4391 . Berlin: Springer, 2007: 101-117.
[2]ZHANG C, TAN T. Voice disguise and automatic speaker recognition [J]. Forensic Science International, 2008, 175(2/3): 118-122.
[3]MUCKENHIRN H, KORSHUNOV P, MAGIMAI-DOSS M, et al. Long-term spectral statistics for voice presentation attack detection [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(11): 2098-2111.
[4]WANG L, NAKAGAWA S, ZHANG Z, et al. Spoofing speech detection using modified relative phase information [J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(4): 660-670.
[5]WU H, WANG Y, HUANG J. Identification of electronic disguised voices [J]. IEEE Transactions on Information Forensics and Security, 2014, 9(3): 489-500.
[6]李燕萍,林乐,陶定元.基于GMM统计特性的电子伪装语音鉴定研究[J].计算机技术与发展,2017,27(1):103-106.(LI Y P, LIN L, TAO D Y. Research on identification of electronic disguised voice based on GMM statistical parameters [J]. Computer Technology and Development, 2017, 27(1): 103-106.)
[7]LIANG H, LIN X, ZHANG Q, et al. Recognition of spoofed voice using convolutional neural networks [C]// Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing. Piscataway: IEEE, 2017: 293-297.
[21]GAROFOLO J S, LAMEL L F, FISHER W M. TIMIT acoustic-phonetic continuous speech corpus [EB/OL]. [2019-02-20]. http://www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC93S1.
[22]NIST Multimodal Information Group. NIST speaker recognition evaluation database [EB/OL]. [2019-02-20]. http://catalog.ldc.upenn.edu/LDC2010S03.
[23]VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605.
This work is partially supported by the National Natural Science Foundation of China (61871434), the Scientific Research Fund of Huaqiao University (Y19060).
LIN Xiaodan, born in 1983, Ph. D., lecturer. Her research interests include multimedia forensics, signal processing.
QIU Yingqiang, born in 1981, Ph. D., associate professor. His research interests include information hiding.
收稿日期:2019-05-23;修回日期:2019-06-20;錄用日期:2019-07-03。
基金项目:国家自然科学基金资助项目(61871434);华侨大学科研基金资助项目(Y19060)。
作者简介:林晓丹(1983—),女,福建泉州人,讲师,博士,主要研究方向:多媒体取证、信号处理; 邱应强(1981—),男,福建龙岩人,副教授,博士,主要研究方向:信息隐藏。
文章编号:1001-9081(2019)12-3510-05DOI:10.11772/j.issn.1001-9081.2019050870
