
基于DiffNodeset结构的最大频繁项集挖掘算法
2019-01-07 12:26郑云俊
计算机应用 2018年12期
尹 远,张 昌,文 凯,郑云俊
(1.重庆邮电大学 通信新技术应用研究中心,重庆 400065; 2.中国电信股份有限公司 重庆分公司,重庆 401121; 3.重庆信科设计有限公司,重庆 401121)(*通信作者电子邮箱wszhangchang@yeah.net)
0 引言
数据挖掘指的是挖掘大量数据之间的隐藏关系,数据挖掘的分析方法包括分类、估计预测、频繁项集挖掘和聚类等。其中频繁模式和关联规则是数据挖掘的主要研究领域,Agrawal等[1]于1994年提出频繁模式挖掘算法——Apriori算法,Han等[2]于2004年提出了频繁模式增长(Frequent Pattern growth, FP-growth)算法等。但如果数据库比较庞大并且支持度阈值设置较低时,频繁项集的数量就会非常庞大,这是频繁项集挖掘所面临的一个问题。
在数据挖掘中,通过挖掘最大频繁项集来代替挖掘频繁项集可以大大地提升系统的运行效率,近年来已经有很多专家学者对最大频繁项集挖掘算法进行了较为深入的研究。Bayardo[3]最先提出了最大频繁项集挖掘的概念并提出了一种最大频繁项集挖掘算法——Max-Miner算法,该算法主要采用了广度优先搜索的思想,然后结合了前瞻剪枝策略以及动态排序技术,由于广度优先搜索用于挖掘最大频繁项集时有缺陷,所以该算法性能不够好。Agrawal等[4]提出了DepthProject算法,该算法融合了深度优先搜索的思想以及动态记录的技术,其算法性能较Max-Miner算法提升了一个数量级。Burdick等[5]提出了一种最大频繁项集挖掘算法(MAximal Frequent Itemset Algorithm, MAFIA),该算法将项集网格和子集树作为框架,同时采用纵向位图来存储数据,然后结合了父等价剪枝、前瞻剪枝等多种剪枝技术,其算法性能较DepthProject算法提升了3~5倍。Zou等[6]提出SmartMiner算法并采用了与MAFIA相似的数据存储结构,但该算法采用了动态记录启发式深度优先搜索策略,所以该算法特点在于产生的搜索树相对MAFIA与GenMax[7]算法更小,算法性能相对更优。沈戈晖等[8]提出了基于N-list的MAFIA(N-list based MAFIA, NB-MAFIA),该算法在基于深度优先搜索的框架之下,引入了基于项集前缀树节点链表的项集表示方法N-list[9]来表示项集,最后再结合相应的优化剪枝策略和超集检测策略来提升算法的效率,但还可以针对稀疏数据集场景下的NB-MAFIA的性能进行进一步优化。
针对现有的最大频繁项集挖掘算法挖掘的时间消耗较大的问题,本文提出了一种基于DiffNodeset[10]结构的最大频繁项集挖掘(DiffNodeset Maximal Frequent Itemset Mining, DNMFIM)算法。该算法采用了一种新的数据结构DiffNodeset来实现高效的求交集运算以及支持度的快速计算,并引入一种新的线性复杂度的连接方法来降低两个DiffNodeset在连接过程中的复杂度,避免了多次的无效计算。实验结果表明,DNMFIM算法在时间效率方面优于MAFIA与NB-MAFIA,该算法在不同类型数据集中进行最大频繁项集挖掘时均有良好的效果。
1 相关知识
1.1 基本概念
假定I={i1,i2,…,im}是m个不同项组成的集合,包含n(0≤n≤m)个项的集合称为项集。
定义1[9]频繁项集。若项集X的支持度大于或等于用户规定的最小支持度阈值,则称X是频繁项集。
定义2[5]最大频繁项集。若频繁项集X的任意超集Y均不是频繁项集,则称X为最大频繁项集。
1.2 前序后序编码树
首先给定一个数据库和设置一个最小支持度阈值,然后开始构建前序后序编码树(Pre-order and Post-order Code tree, PPC-tree)[9]。
PPC-tree由根节点(root)以及项目的前缀子树组成。项目前缀子树的每个节点由5个部分构成(item-name、count、children-list、pre-order、post-order),这5部分分别表示节点的项目名称、经过该节点的事务数目、子节点、前序编码、后序编码。构建PPC-tree的算法[9]如算法1所示(详细的构建过程参考文献[9])。
算法1 Construct-PPC-tree(DB,minSup)。
输入 事务数据库DB和minSup;
输出 生成所有频繁1-项集和PPC-tree。
1)
[Frequent 1-itemsets generation]
2)
According tominSup,scanDBonce to findF1, the set of
frequent 1-itemsets (frequent items), and their supports.
3)
SortF1in support descending order asL1,
4)
for each transactionTransinDBdo
5)
Select the frequent items inTransand sort out them according
to the order ofF1. Let the sorted frequent-item list inTrans
be [p|P], wherepis the first element andPis the remaining list.
6)
Call insert tree([p|P],Tr).
7)
Scan PPC-tree to generate the pre-order and the post-order of
each node.
8)
ReturnTrandL1.
根据算法1来构建TB-tree,设事务数据库DB如表1所示(minSup=0.4),图1是针对事务数据库DB运行算法之后构建成的PPC-tree。

表1 事务数据集DBTab. 1 Transaction data set DB
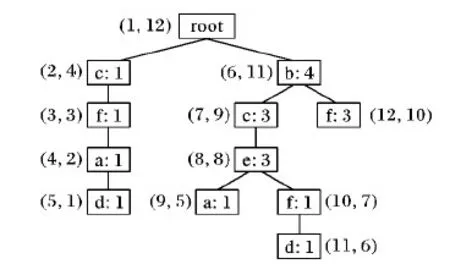
图1 PPC-treeFig. 1 PPC-tree
根据图1的PPC-tree,各节点的节点编码归纳如表2所示,该1-项集的Nodesets表有助于更加清楚地理解DiffNodeset的连接过程。

表2 1-项集的NodesetsTab.2 Nodesets of 1-itemsets
给定一个PPC-tree,有以下的性质[9]:
性质1 对于PPC树中的任意两个节点N1和N2(N1≠N2),当且仅当N1.pre-order
证明 由PPC-tree构建算法可知,祖先节点总是先于子孙节点构建,因此,祖先节点对应的pre-order总是小于子孙节点的pre-order;又因为祖先节点总是晚于孩子节点构建完成,因此祖先节点对应的pre-post值总是大于子孙节点的pre-post。
性质2 对于在PPC-tree中任何两个具有相同节点名称的N1和N2(N1≠N2),如果N1.pre-order 证明 若N1.pre-order 近年来,数据挖掘领域为了提高频繁项集的挖掘效率,已经有很多种数据结构被提出,例如:Node-list[11]、N-list、Nodeset[12]等。它们都是基于前缀编码树来存储频繁项集的信息,Nodeset相对于N-list、Node-list的区别在于N-list和Node-list需要前序编码和后序编码来表示节点,而Nodeset只需要前序(或后序)编码来表示节点,所以Nodeset结构对内存的消耗更小。但在很多数据集中采用Nodeset结构时,产生的节点集基数会很大。针对这一问题,引入了一种新的项集表示方法DiffNodeset[10],它只表示项集在生成频繁项集产生的差异节点集,产生的DiffNodeset基数相对于Nodeset结构少得多。DiffNodeset是一种高度压缩且结构简便的数据结构,可以高效地挖掘频繁项集。 DiffNodeset是一种基于Nodeset的一种数据结构,这里介绍一下Nodeset结构及定义[10](以下定义及详细证明过程参考文献[10])。 定义3 设L1是按支持度降序排列的频繁项集,对于任意两个项集i1,i2(i1,i2∈L1) ,若存在项集i2在i1之前,则用i1⊂i2来表示。 定义4 前序后序编码(Pre-Post code, PP-code)给定一个PPC-tree,节点N的PP-code为(N.pre-order,N.post-order,count)。该PP-code包含前序编码和后序编码,文献[12]中的原始定义只包含前序编码,由于前序和后序都可以唯一标识PPC树中的节点,所以差异可以忽略不计。在本文中,采用定义4来定义项目的节点集是为了设计出构建2-项集DiffNodeset的有效方法。 定义5 1-项集的Nodesets。假设一个PPC-tree,每一个i的节点集都按PP-codes中的pre-order的升序排列(1-项集的Nodesets如表2所示)。 性质3 给定一个项集,假设{(x1,y1,z1), (x2,y2,z2),…, (xl,yl,zl)}是相应的Nodeset,在此存在x1 证明 根据定义5,有x1 定义6 2-项集DiffNodesets。假设两个项集i1和i2(i1,i2∈L1∩i1⊂i2),给它们的节点集分别定义为Nodesesti2和Nodesetsi2。2-项集i1i2的节点集可以用DiffNodesetsi1i2表示,定义如下: DiffNodesetsi1i2= {(x.pre-order,x.count) |x∈Nodesetsi1∩⎤(∃y∈Nodesetsi2,the node corresponding toyis an ancestor of the node corresponding tox)}(DiffNodesetsi1i2中的元素按前序编码pre-order的升序排序)。 为了较好地理解该定义,以b和f的Nodeset为例说明,从表2可得b和f的Nodeset分别为(6,11,4)和(3,3,1)(12,10,3)(10,7,1)。bf的DiffNodeset连接过程如下:显然根据性质1可得(6,11,4)是(12,10,3)(10,7,1)的祖先而不是(3,3,1)的祖先,那么根据该定义可得bf的DiffNodeset为(3,1),同理可得bc的DiffNodeset为(2,1)。 假设两个项集i1、i2的长度分别为m和n,可以通过检查i1中每个元素与i2中每个元素之间的祖先-子孙关系来构建DiffNodesetsi1i2。这种遍历所有元素的方法显然效率会比较低下,因为它的计算复杂度是O(m*n)。在此,通过性质1和性质3来引入一种线性复杂度的方法来构建2-项集DN(),这种方法的复杂度为O(m+n),大大降低了计算的复杂度。 定义7k-项集DiffNodesets。假设P=i1i2…ik-2ik-1ik是一个项集(满足ij∈L1且i1⊂i2⊂i3⊂…⊂ik)。P1=i1i2…ik-2ik-1的Nodeset记为NodesetP1,P2=i1i2…ik-2ik的Nodeset记为NodesetP2。P的DiffNodeset记为DiffNodesetP可以由如下计算得到: DiffNodesetP=NodesetP1/NodesetP2 其中:“/”表示集合差。 性质4 假设P=i1i2…ik-2ik-1ik,P1=i1i2…ik-2ik-1,那么P的支持度计算方式如下: support(P)=support(P1)-∑(E∈DNP)E.count 其中DNP即为DiffNodesetP。 证明 假设X=i1i2…ik-3ik-2,Y=i1i2…ik-3ik-1。X、Y、P1和P2的Nodeset记为NSX、NSY、NS1、NS2。在k-项集的Nodeset中存在NS1=NSX∩NSY,在k-项集的DiffNodeset中存在DN1=NSX/NSY。 support(P1)=∑(E∈NS1)E.count= ∑(E∈NSP∪DNP)E.count= ∑(E∈NSP)E.count+∑(E∈DNP)E.count= support(P)+∑(E∈DNP)E.count 性质5 假设P=i1i2…ik-2ik-1ik是一个项集(满足ij∈L1且i1⊂i2⊂i3⊂…⊂ik)。P1=i1i2…ik-2ik-1的DiffNodeset记为DN1,P2=i1i2…ik-2ik的DiffNodeset记为DN2。P的DiffNodeset记为DNp,其计算式如下: DNP=DN2/DN1 证明 假设X=i1i2…ik-3ik-2,Y=i1i2…ik-3ik-1。X、Y、P1和P2的Nodeset记为NSX、NSY、NS1、NS2。在k-项集的Nodeset中存在NS1=NSX∩NSY,在k-项集的DiffNodeset中存在DN1=NSX/NSY。 根据上述两个条件可以得到: NSX=(NSX∩NSY)∪(NSX/NSY)=NS1∪DN1 NS1∩DN1=∅ 然后得到NS1=NSX/DN1。 同理可得: NSX=NS2∪DN2 NS2∩DN2=∅ NS2=NSX/DN2 最后可得: DNP=NS1/NS2= (NSX/DN1)/(NSX/DN2)=NSX∩(DN1)T∩DN2= DN2∩(DN1)T=DN2/DN1 DiffNodeset采用性质5可以使DiffNodeset直接计算构成k-项集的DiffNodeset,不需要再进行Nodeset的计算。 DNMFIM算法采用了集合枚举树作为搜索空间,然后集合深度优先搜索的思想进行处理,即对于集合枚举树中的每个节点,都需要与右侧的邻居节点进行合并产生子节点,同时求并集得到子节点所表示的项集。 定义8 在集合枚举树中的节点C的项集记为C.head,该节点的可扩展项的集合记为C.tail,每个扩展项集都是C节点的可扩展1-项集。 深度优先搜索策略的核心思想是检测每个节点的项集C.head与该节点的可扩展项集C.tail中的每个可扩展项i的并集C.head∪i的支持度,如果每个并集的支持度都小于minSup,那么说明在频繁模式树中C就是一个叶节点。然后再检测C.head是否是最大频繁项集MFI中任意集合的子集,若不是,就将C.head加入到MFI。如果C.head∪i支持度均大于minSup,则继续向下递归。结合DiffNodeset的深度优先搜索算法融合了文献[10]中基于DiffNodeset交集的思想,算法的流程如算法2所示。集合枚举树示例如图2所示。 图2 集合枚举树Fig.2 Set-enumeration tree 算法2 基于DiffNodeset交集求解算法[10]。 输入 当前节点N1与右侧邻居节点N2; 输出 子节点DiffNodeset。 1) DNxy←∅; 2) k←0 andj←0; 3) lx← the length ofNx(Nodeset ofix) andly←the length of Ny(Nodeset ofiy); 4) Whilek 5) IfNx[k].post-order>Ny[j].post-orderthen 6) j←j+1; 7) Else 8) IfNx[k].post-order Nx[k].pre-order>Ny[j].pre-orderthen 9) k←k+1; 10) Else 11) DNxy←DNxy∪{(Nx[k].post-order, Nx[k].count)}; 12) k←k+1; 13) Endif 14) Endif 15) Endwhile 16) Ifk 17) Whilek 18) DNxy←DNxy∪{(Nx[k].post-order,Nx[k].count)}; 19) k←k+1; 20) Endwhile 21) Endif 22) ReturnDNxy 实际上,构建2-项集DN()采用了双向比较的策略来构建ixiy的DiffNodeset。根据双向比较原理,构建2-项集DN()的计算复杂度为O(m+n),其中m和n分别为对应节点集的长度。构建过程的伪代码如算法2所示。 构建2-项集DN()需要比较两个Nodeset中PP-codes,直到其中一个Nodeset的所有元素都比较完毕。对于这种两个元素之间的比较,有三条原则来降低比较的复杂度。 原则一 如伪代码的第5)行,若存在Nx[k].post-order>Ny[j].post-order,则表明对应于Ny[j]的节点不是对应于Nx[k]的节点的祖先,由于各项集的Nodeset都是按照post-order的升序(根据性质3),因此就不用再考虑Ny[j],并选择Ny[j+1]与Nx[k]进行比较,如伪代码第5)、6)行所示。 原则二 如伪代码的第8)行,若存在Nx[k].post-order 原则三 如伪代码第10)行,若存在Nx[k].post-order 当所有的比较完成之后,需检查在ix的Nodeset中是否存在一些未参与比较的元素,根据定义6,这些元素是可取的。然后生成与这些元素相对应的所有结果,并添加到ixiy的DiffNodeset,如伪代码第16)行到第21)行所示。最后输出所有2-项集的DiffNodeset。 性质6[13]设X∈C.head,y∈C.tail,若存在X的事务集与X∪{y}完全相同,即t(X)=t(X∪{y}),那么∀S∈C.tail,都有X∪S与X∪{y}∪S的支持度相同。 证明 由于t(X)=t(X∪{y}),则support(X)=support(X∪{y}),所以任意包含X的事务必然包含y。所以,包含S的任意项集也必然包含y,所以support(X∪S)=support(X∪{y}∪S)。 DNMFIM算法根据性质6采用了父等价剪枝技术来缩小搜索空间。当搜索C节点时,若遇到性质6中的情况,就可以将y从C.tail中删除,并放入C.head,这样会提高挖掘的效率,并不会影响最大频繁项集挖掘的准确性。 性质7[14]若当前节点与右侧所有邻居节点的并集是已挖掘的最大频繁项集的子集,则以当前节点为根节点的子树不可能存在最大频繁项集。 证明 反证法。若以当前节点为根节点的子树中存在最大频繁项集,那么该最大频繁项集必然不是已挖掘的最大频繁项集的子集。 得证 由于每将一个项集加入MFI时,就必须检测该项集的超集在MFI中是否存在,这个过程称之为超集检测。 定义9 局部最大频繁项集。给定一个节点P,MFI中只有一部分是P.head的超集,则这部分项集称之为P的局部最大频繁项集(Local MFI, LMFI)。 本文引入一种在MAFIA[5]中所采用的超集检测策略,从而进一步提升算法效率。对于任意的y∈P.tail,将P.head与P的可扩展1-项集y合并得到节点P1。显然,P1的LMFI都包含y元素且P1的LMFI是P的LMFI的子集。将P的LMFI进行排序,包含y的项集集合就是P1节点的LMFI。若将以P节点为根节点的子树搜索完成时,那么在该子树上所挖掘到的所有MFI都将是P的超集。所以当有新的项集加入P的MFI的项集时,也会将该项集加入到P的LMFI中。故是否要将一个项集加入到MFI,只需要判断该节点的LMFI是否为空即可,即实现超集检测。超集检测算法的详细过程如算法3所示。 算法3 超集检测算法[5]。 输入 进行剪枝后的项集M; 输出 超集检测之后的MFI。 1) MFI←∅ 2) root.head←∅ 3) root.tail←DB 4) HUT=C.head∪C.tail 5) If(HUTis inMFI) 6) Stop searching and return 7) Endif 8) Count all children,usePEPto trim the tail,and reorder by increasing support 9) For each itemiinC.tail 10) C.extension=C.head∪{i} 11) If(all extensions are frequent) 12) SortMFIby new itemiand update left and rightLMFI pointers forCn(itemsets put inLMFIleftwhich include i,else put inLMFIright) 13) Adjust rightLMFIpointer ofCfor any new itemsets added toMFI 14) Endif 15) Endfor 16) If(C.LMFIis empty) do 17) addC.headtoMFI 18) Endif NB-MAFIA采用的是基于N-list的的最大频繁项集挖掘方法,N-list的高压缩率和高效的求交集方法可以实现项集支持度的快速计算,该算法采用了MAFIA的优化剪枝与超集检测策略,所以NB-MAFIA性能相对于MAFIA提升很多。但NB-MAFIA在稀疏数据集中运行时效果还需进一步改善,本文中提出的DNMFIM算法针对这一点进行了改进,DNMFIM算法的优势在于引入一种新的线性复杂度的连接方法来降低连接两个DiffNodeset在连接过程中的复杂度,从而避免了多次无效的计算,由于这一特性,DNMFIM算法能够快速挖掘稠密数据集中的最大频繁项集,再结合相应的优化剪枝策略与超集检测策略使DNMFIM算法在稀疏数据集中依然有良好的效果。 将DNMFIM算法与经典的最大频繁项集挖掘算法MAFIA及其改进算法NB-MAFIA进行比较。在不同类型的数据集中运行这三种算法来对比这三种算法的时间效率。用C++语言在实验环境为Inter Core i5 3317U@1.7 GHz CPU,内存4 GB,64位操作系统的设备上实现了DNMFIM算法 MAFIA和NB-MAFIA。在每组实验中,这三种算法所挖掘到的最大频繁项集都是相同的,从而验证了BNMFI算法的正确性。在本次实验中选取了稠密型数据集Connect、稀疏型数据集Retail以及由IBM Almaden生成的人工数据集T10I4D100K来作为本实验的测试数据集,数据集参数如表3所示。然后,通过改变最小支持度阈值来进行最大频繁项集的挖掘。最后,通过对比分析了这三种算法在不同数据集中的时间消耗情况,结果如图3所示。为了保证实验结果的准确性,本人在同一台设备上进行了实验。 由图3可以看出,DNMFIM算法在时间效率方面效果优于MAFIA与NB-MAFIA,该算法在不同类型数据集中进行最大频繁项集挖掘时均有良好的效果。当这三种算法在稠密数据集Connect中运行时,DNMFIM算法性能优于其他两种算法,在最小支持度阈值设置得较小时优势更加明显,随着最小支持度阈值的逐渐增加算法的运行时间越来越短,DNMFIM算法的优势也越来越不明显。当这三种算法在稀疏数据集Retail中运行时,其运行时间相比在稠密数据集中较长一些。当最小支持度阈值为0.05%时,DNMFIM算法的运行时间较少,约为MAFIA运行时间的1/5;随着最小支持度阈值的升高,DNMFIM算法的优势越来越不明显,当最小支持度阈值大于0.2%时,三种算法的运行时间基本一致。当这三种算法在人工数据集T10I4D100K中运行时,由于在存储数据和处理数据方面的结构性优势,DNMFIM算法和NB-MAFIA的运行时间明显优于MAFIA,在该数据集中DNMFIM算法仍保持着最优的性能。 表2 数据集参数Tab. 2 Dataset parameters 图3 不同算法运行时间对比Fig. 3 Runtime comparison of different algorithms 本文提出了一种新的最大频繁项集挖掘整合算法——DNMFIM算法。该算法采用了一种新的数据结构DiffNodeset来实现高效的求交集以及支持度的快速计算,并引入一种新的线性复杂度的连接方法来降低连接两个DiffNodeset在连接过程中的复杂度,从而避免了多次无效的计算。实验结果表明,DNMFIM算法在不同类型的数据集中挖掘最大频繁项集的性能优于MAFIA与NB-MAFIA。随着互联网数据的飞速发展,将DNMFIM算法与Spark平台相结合,从而研究出并行化处理大数据的最大频繁项集挖掘算法,将是下一步需要研究的方向。1.3 DiffNodeset结构
2 DNMFIM算法
2.1 基于DiffNodeset的深度优先搜索算法

2.2 优化策略
3 实验结果及分析


4 结语
猜你喜欢
保健医苑(2022年5期)2022-06-10辽宁大学学报(自然科学版)(2022年1期)2022-04-26密码学报(2021年4期)2021-09-14成都信息工程大学学报(2021年6期)2021-02-12成都信息工程大学学报(2021年6期)2021-02-12计算机应用(2020年5期)2020-06-07华东师范大学学报(自然科学版)(2020年1期)2020-03-16计算机技术与发展(2019年7期)2019-07-23华东师范大学学报(自然科学版)(2019年2期)2019-06-11计算机与数字工程(2018年10期)2018-10-23
