
基于逐跳计算的分布式负载均衡算法
2019-01-07 12:24耿海军刘洁琦
计算机应用 2018年12期
耿海军,刘洁琦
(山西大学 软件学院,太原 030006)(*通信作者电子邮箱ghj123025449@163.com)
0 引言
随着互联网的普及和快速发展,部署在互联网中的视频业务与日俱增[1]。研究表明,随着网络中流量的增加,网络拥塞频繁发生。然而目前互联网部署的域内路由协议采用最短路径转发报文,无法灵活应对网络拥塞问题[2-3]。因此,因特网服务提供商(Internet Service Provider, ISP)通过配置链路权值来优化资源利用,尽量减少由于流量增加而引起的网络拥塞问题发生[4]。由于该问题的重要性,在过去的几十年里大量的研究者致力于对网络拥塞问题[5]的研究。
文献[4]中介绍了基于IP的域内负载均衡算法——优化开放最短路径优先(Open Shortest Path First, OSPF)权值(Optimizing OSPF Weights, OPW),该研究的核心思想为给定一个网络拓扑结构和流量矩阵,通过设置网络中链路代价来优化流量的分配。文献[4]研究将该最优化问题表示为一个多商品流问题,然后利用领域搜索算法计算近似最优解;但是该算法必须采用集中式解方案,并且算法的代价较大,因此无法直接应用在逐跳计算的链路状态路由协议中。链路状态路由协议即运行协议的路由器之间首先建立邻居关系,然后邻居间交换链路状态信息,如链路类型和带宽等,接着每个路由器根据交换得到的链路状态信息建立链路状态数据库,最后每个路由器根据该链路状态数据库计算以自己为根的最短路径树,逐跳计算即每个路由器独立地计算自己的路由表,不需要辅助协议的支持,如隧道、特殊地址等。多协议标签交换(Multi-Protocol Label Switching, MPLS)[6]是一种高效的报文交换协议,该协议不受最短路径路由协议的约束,可以任意配置路由。MPLS处于开放式系统互联(Open System Interconnect, OSI)模型的第二层和第三层中间,当分组达到网络的时候,为其分配固定长度的标签,并且将该标签和分组封装在一起,利用标签转发报文,从而实现报文的高速转发。文献[7-8]中将利用MPLS实现负载均衡的问题归结为线性整数规划模型,然后利用线性规划(Linear Programming, LP)计算器求解。文献[9]提出了利用基于路径的路由保护算法,在节点间通过使用多条路径并行传输数据,并且设计了负载均衡算法实现分流,以实现故障恢复期间的负载均衡。文献[10]提出了利用配置合适的链路权值在基于逐跳计算的链路状态路由协议中实现链路负载均衡,然而该算法计算开销极大,并且容易导致网络不稳定。
上述所有的负载均衡算法都需要完整的流量矩阵,并且需要集中式方法求解。研究[11]表明,从网络中获取实际流量矩阵是一件相当困难的工作,基本无法实现。因此,本文研究如何在没有流量矩阵的前提下实现一种基于逐跳计算的分布式负载均衡算法(Distributed Load Balancing algorithm based on Hop-by-hop computing, DLBH)。
1 网络模型和问题描述
图G=(V,E)表示一个网络拓扑结构,在该图中,V代表该网络拓扑中节点的集合,E代表该网络拓扑中边的集合。对于∀v∈V,N(v)表示该节点的所有邻居节点的集合。对于∀(i,j)∈E,w(i,j)为该边对应的代价,c(i,j)为该边对应的带宽。对于网络中的任意两个不相同的节点∀x,y∈V(x≠y),C(x,y)表示这两个节点之间的最短路径对应的代价;B(x,y)表示节点x到节点y的最优下一跳;H(x,y)表示这两个节点之间的最短路径对应的跳数,当两个节点之间有多条最短路径时,取具有最小跳数的路径作为H(x,y)的数值。
由于互联网中的域内路由协议一般采用分布式方法,因此本文研究如何采用分布式方法进行负载均衡,以降低网络拥塞。因为本文利用的是分布式解决方法,所以下面仅仅讨论节点c的计算过程。为了防止网络拥塞,当某条链路的链路利用率较高时,可以将该条链路的权值设置为较大的数值,这样就可以降低该链路的链路利用率。但是网络中链路利用率随着时间的变化而变化,如果链路的权值也随着时间的变化而变化,将会导致网络不稳定,引发路由震荡。因此,为了设计一个分布式的负载均衡算法,需要解决下面两个问题。
1)如何获得链路的链路利用率。
因为实际网络中的流量随时间的变化而变化,所以网络中链路的链路利用率也是时间的函数。下面将描述如何获得链路的链路利用率。

2)如何根据链路利用率设置该链路的代价。
对于任意的目的地址,当计算出某条链路的链路利用率后,如何设置该链路的代价是本文需要解决的另外一个关键问题。在设置链路代价的时候需要考虑两个方面的因素:
a)链路代价是链路利用率的函数,即w(vi,vj,d)=F(μ(vi,vj,d))=F(T(d)*(H(vj,d)+1)β/c(vi,vj))。链路代价和链路利用率之间的变化趋势相同,即链路利用率越高,该链路的代价越大;反之,链路利用率越低,该链路的代价越小。
b)为了防止路由环路,链路代价函数F(T(d)*(H(vj,d)+1)β/c(vi,vj))必须保证左保序性。
下面给出左保序性的定义,对于两条路径p和q,如果两者都表示从节点s到节点d的路径,如果W(p) 图1 左保序性例子Fig. 1 An example for left isotonicity 从上面的讨论可知,对于不同的目的地址,某条链路的代价是不相同的。链路代价的具体数值由式(1)表示: (1) 由式(1)可知,链路利用率越高,链路的代价越高,该代价函数满足了代价函数必须满足的第一个要求。下面通过定理1来证明该代价函数具有左保序性。 定理1 链路代价函数F(T(d)*(H(vj,d)+1)β/c(vi,vj))具有左保序性。 DLBH是一个分布式的解决算法。运行DLBH的路由器仅仅需要知道自身的局部信息(如网络拓扑结构)即可,而不需要获取网络中的实时流量矩阵信息。每个路由器根据DLBH计算出到达所有目的的最优下一跳,从而减低网络拥塞,达到负载均衡的目的。 下面将详细描述算法DLBH的执行过程。 该算法的输入为网络拓扑G(V,E),计算节点c和目的地址d,输出为节点c到目的地址d的最优下一跳。在算法中,每个节点有一个访问标记属性visited,当该属性的值为true时,表示该节点已经被访问,反之该节点未被访问。算法维护一个优先级队列Q(u,v,p,q),该队列中元素包括4个属性,其中:u表示节点本身,v表示节点u的父亲节点,p表示节点u到目的地址d的代价,q表示节点u到目的地址d的跳数。初始化参数,将所有节点(除去d)到d的最小代价设置为无穷大,将d到d的最小代价设置为0,将所有节点(除去d)到d的最小跳数设置为无穷大,将d到d的最小跳数设置为0,将所有节点的访问属性标记为未访问,将节点d加入到优先级队列(第1)~8)行)。当队列不为空时,执行下面的过程。从队列中取出第一个元素u(第10)行),当该元素为计算节点c时,返回节点c到目的地址d的最优下一跳,程序结束。当该元素不是计算节点c时,更新该节点的属性(第14)~17)行)。计算该节点到目的节点d的最优下一跳(第18)~22)行)。访问节点u的所有邻居节点,对于节点u的邻居节点v,如果节点v未被访问,计算链路(v,u)的代价,更新节点v的属性(第23)~34)行)。 算法DLBH的伪代码如下。 算法1 DLBH。 输入G(V,E),计算节点c和目的地址d; 输出 节点c到目的地址d的最优下一跳B(c,d)。 1) For ∀v∈Vdo 2) C(v)←∞ 3) v.visited←false 4) H(v)←∞ 5) EndFor 6) C(d)←0 7) H(v)←0 8) Enqueue(Q,(d,0,0,0)) 9) WhileQ不为空 do 10) (u,p,tc,th)←Extractmin(Q) 11) Ifu=cthen 12) returnB(c,d) 13) else 14) u.visited←true 15) P(u)←p 16) C(u)←tc 17) H(u)←th 18) IfP(u)=dthen 19) B(u,d)=d 20) else 21) B(u,d)=B(P(u),d) 22) EndIf 23) Forv∈N(u) do 24) Ifu.visited=false then 25) t(v,u,d)=T(d)*(H(u)+1)β 26) μ(v,u,d)=t(v,u,d)/c(v,u) 27) 根据式(1)计算w(v,u,d) 28) IfC(u)+w(v,u,d) w(v,u,d)=C(v) andH(v) 29) newdist=C(u)+w(v,u,d) 30) h←H(u)+1 31) Enqueue(Q,(v,u,newdist,h)) 32) EndIf 33) EndIf 34) EndFor 35) EndIf 36) EndWhile 定理2 算法DLBH的时间复杂度为O(VlgV+E)。 证明 算法DLBH在标准的迪杰斯特拉算法的基础上仅仅增加了第25)~27)行,这几行语句的时间复杂度为O(1),不会影响算法的时间复杂度。因此在最坏情况下DLBH的时间复杂度为O(VlgV+E)。DLBH仅仅计算出了节点c到目的节点d的最优下一跳,为了计算节点c到所有目的的最优下一跳,需要运行V次DLBH。因为对于不同的目的,DLBH可以独立运行,所以在实际中可以采用并行方法实现。因此,计算节点c到所有目的的最优下一跳的算法复杂度等于标准的迪杰斯特拉算法的算法复杂度。 本章将全面分析DLBH的性能。在实验中,将DLBH和OPW、OSPF两种算法进行比较。运行DLBH和OPW、OSPF的网络拓扑包括ABILENE和GEANT[13],它们的具体参数如表1所示。之所以选择这两个拓扑作为实验结构,这是因为这两个拓扑公布了部分真实流量数据。因为已有的研究[14-16]衡量负载均衡能力主要包括两个方面:1)最大链路利用率,该指标用来衡量网络拥塞程度;2)每条链路的链路利用率,该指标用来衡量网络中所有链路的整体链路利用率。因此,本文实验的评价指标为最大链路利用率和链路利用率累计概率分布。在实验中,取α=0.2,β=0.1。 表1 拓扑参数Tab. 1 Topology parameters 在本节将利用最大链路利用率来衡量不同算法的负载均衡能力。最大链路利用率越低,负载均衡能力越强,反之最大链路利用率越高,负载均衡能力越弱。不同算法在ABILENE和GEANT的运行结果分别如图2(a)和图2(b)所示,图2(a)中流量数据的采集时间为2004年3月8日,图2(b)中流量数据的采集时间为2005年5月8日。 从图2(a)和图2(b)可以看出:在ABILENE中,DLBH的最大链路利用率小于OPW和OSPF的最大链路利用率,OSPF的最大链路利用率是最大的:在GEANT中,DLBH和OPW的最大链路利用率基本相同,它们的最大链路利用率远远小于OSPF的最大链路利用率。 不同算法在ABILENE和GEANT的运行结果分别如图2(c)和图2(d)所示,图2(c)中流量数据的采集时间为2018年5月12日,图2(d)中流量数据的采集时间为2018年3月4日。从图2(c)和图2(d)中,可以得出如图2(a)和图2(b)同样的结论。 图2 最大链路利用率随时间变化规律Fig. 2 Change of maximum link utilization with time 3.1节分析了DLBH和OPW对应的最大链路利用率。为了进一步细化网络中所有链路的利用率,本节利用链路利用率累计概率分布来评价两种算法的性能。图3(a)和图3(b)分别表示不同算法在ABILENE和GEANT的运行结果。图3(a)中流量数据的采集时间为2004年3月8日晚上8点;图3(b)中流量数据的采集时间为2005年5月8日晚上8点。 图3 ABILENE和GEANT中链路利用率累计概率分布Fig. 3 Link utilization cumulative probability distribution on ABILENE and GEANT 从图3(a)可知,DLBH链路的利用率均小于12%;OPW链路的利用率均小于14%;而OSPF最大链路利用率为17%,小于12%的链路不到70%。从图3(b)可知,DLBH和OPW的链路利用率累积概率分布基本相同,DLBH和OPW链路利用率均小于65%,而OSPF最大链路利用率达到了96%。 当β=0.1时,DLBH在ABILENE和GEANT中最大链路利用率和α的关系如图4所示。图4(a)中流量数据的采集时间为2004年3月8日,图4(b)中流量数据的采集时间为2018年4月12日。从图4可以看出,在ABILENE中,随着α的增加,最大链路利用率略微增加,当α增加到某个值时,最大链路利用率基本不再随α的变化而变化;在GEANT中,随着α的增加,最大链路利用率略微增加。 图4 DLBH最大链路利用率和α的关系Fig. 4 Relationship between maximum link utilization and α by DLBH 当α=0.2时,DLBH在ABILENE和GEANT中最大链路利用率和β的关系如图5所示。图5(a)中流量数据的采集时间为2004年3月8日,图5(b)中流量数据的采集时间为2018年4月12日。从图5可以看出,在2004年的ABILENE中,最大链路利用率基本不随β的变化而变化;在GEANT中,当β的值在0.2和0.8之间时,最大链路利用率基本不随β的变化而变化,当β增加到0.8时,最大链路利用率随着β的增加而增加。在2018年的ABILENE和GEANT中,当β的数值在0.1和0.3之间时,最大连路利用率随着β的增加而增加,当β大于0.3时,最大链路利用率基本不随β的变化而变化。 图5 DLBH最大链路利用率和β的关系Fig. 5 Relationship between maximum link utilization and β by DLBH 从上述的实验结果可知,DLBH在实际网络中的负载均衡能力明显优于OPW的负载均衡能力;并且从实验中可知,当α=0.2、β=0.1时,DLBH可以得到较优的计算结果。 针对目前已有负载均衡算法需要实际流量矩阵,采用集中式算法,并且算法复杂度较高的问题,本文提出了一种基于逐跳计算的分布式负载均衡算法(DLBH)。该算法不需要实际流量矩阵,并且采用分布式计算方法,算法复杂度和标准迪杰斯特拉算法的复杂度相同,没有引入过多的额外代价。实验结果表明,与OPW相比较,DLBH不仅拥有较小的计算复杂度,并且具有较低的最大链路利用率。因此,DLBH可以为互联网服务提供商提供一种兼顾执行效率和最大链路利用率的域内负载均衡算法。本文仅仅利用实验验证了DLBH的有效性,下一步将从理论方面进行分析。
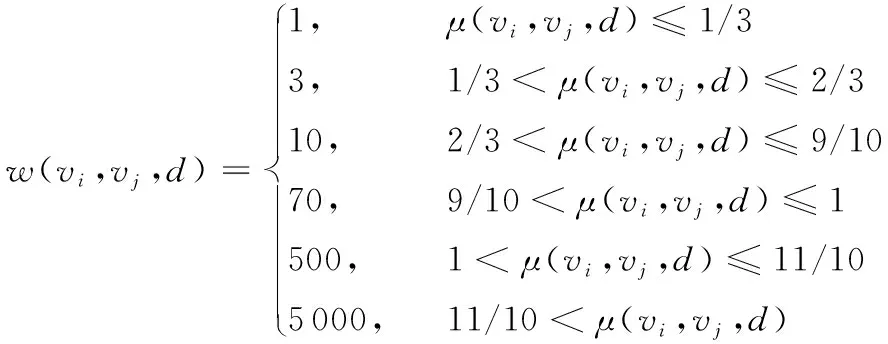

2 本文算法
2.1 算法设计
2.2 算法复杂度分析
3 实验结果及分析

3.1 最大链路利用率

3.2 链路利用率累积概率分布

3.3 最大链路利用率和α的关系

3.4 最大链路利用率和β的关系

3.5 总结分析
4 结语
猜你喜欢
密码学报(2021年4期)2021-09-14成都信息工程大学学报(2021年6期)2021-02-12计算机与网络(2020年9期)2020-07-29华东师范大学学报(自然科学版)(2020年1期)2020-03-16网络安全和信息化(2019年11期)2019-11-25传播力研究(2019年24期)2019-10-21华东师范大学学报(自然科学版)(2019年2期)2019-06-11科技与创新(2018年1期)2018-12-23海峡姐妹(2017年12期)2018-01-31语文世界(初中版)(2017年5期)2017-06-22
