
基于深度信念网络的异常点集间的匹配算法
2019-01-07 12:16李舫,张挺
计算机应用 2018年12期
李 舫,张 挺
(上海电力学院 计算机科学与技术学院,上海 200090)(*通信作者电子邮箱tingzh@shiep.edu.cn)
0 引言
点集配准是计算机视觉、医学图像分析、模式识别和信号处理的基本和关键问题之一[1-3]。点集配准的目标是找到两个点集之间的正确匹配关系,并确定出能对准它们的空间变换。通常从图像中提取或由3D扫描仪生成的点集所表示的物体表面,由于测量方法的可变性、实验误差、光照变化等因素,不可避免地在图像采集和特征提取的过程中产生噪声、异常值和缺失点。因此,点集配准问题面临着一些挑战,最关键的挑战之一是能否在存在异常值、缺失点和噪声的情况下建立正确的匹配关系。
已有研究提出了迭代算法以解决配准问题,它交替地估计匹配关系和计算变换关系以获得近似最优解。这类方法使用的匹配关系是基于局部特征描述符的,其中,典型的迭代最近点(Iterative Closest Point, ICP)算法就是试图将两组点之间的距离最小化[4]。考虑到这种点对点的匹配关系,ICP的一个重要缺陷就是缺乏对噪声、异常值和缺失点的稳健性。针对这个问题已经作了一些研究,如:文献[5-8]提出了鲁棒点匹配(Robust Points Matching, RPM)及其变体算法,并广泛用于非刚性配准。 RPM方法使用软分类、松弛点匹配关系的变量以建立模糊匹配,并采用确定性模拟退火方法逐步估计点的匹配关系。虽然模糊匹配减轻了噪声等的影响,但错误的匹配关系仍然存在。另一方面的研究是基于概率统计理论的新度量方法建立点集间的匹配关系,其中连续密度函数,如高斯混合模型(Gaussian Mixture Model, GMM)被用来表示点集[9-12]。文献[9]利用一致点漂移(Coherent Point Drift, CPD)之类的概率方法将配准视为最大似然估计问题;文献[10]则基于GMM的方法将配准视为与点集相应的两个分布之间的对准。
为了提高算法对异常值、噪声和缺失点的鲁棒性,文献[1]利用基于混合模型的流形正则化一致向量场(Manifold Regularized Coherent Vector Field, MRCVF)从异常点集中排除外部数据,寻求点集间的正确匹配关系。由此,考虑到正常点和异常点之间存在某种关系或区别的先验知识,可以通过机器学习的过程来模拟对匹配关系的估计。本文提出了一种基于深度信念网络(Deep Belief Network, DBN)的学习方法来训练具有正常点集的网络,使用训练好的DBN就可以在异常点集中识别异常值和不匹配的点,从而实现鲁棒的点集配准。
1 点集间匹配关系的学习框架
1.1 基于深度信念网络的学习
作为一种无监督学习方法,DBN可以使用训练数据集来训练获得数据的特征表示。DBN是通过限制玻尔兹曼机器(Restricted Boltzmann Machine, RBM)的多级连接组成的,在RBM中一个可见层和一个隐藏层之间是双向和完全连接的[13]。DBN的结构如图1所示。
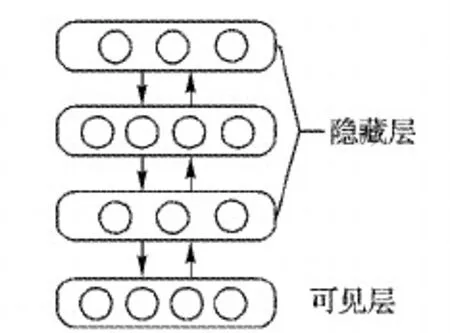
图1 DBN 的结构Fig. 1 Structure of DBN
波尔兹曼机器(BM)是对数线性马尔可夫随机场(Markov Random Field, MRF)的一种特殊形式,RBM将BM限制为没有可见层-可见层连接和隐藏层-隐藏层连接关系的BM。RBM的能量函数定义如下:
(1)
其中:vi和hj分别表示可见层和隐含层的单元;bi和cj分别表示可见单元和隐层单元的偏差;Wij表示连接可见单元和隐藏单元的权重。机器学习的过程中需要通过给DBN输入训练样本集,学习可见层和隐藏层的偏差向量以及两层之间的权重矩阵,以便使网络能够表征数据的分布。
1.2 利用DBN学习点集之间的匹配关系
实际中的采样点集可能会出现某些异常情况,如噪声、异常值和缺失数据等,这可能会影响点集之间匹配关系的确定。因此,有必要学习检测数据中存在的异常点,以利于在两个采样点集之间建立正确的匹配关系。
假设两个点集X和Y分别是原始的和经过变换后的样本。根据正常情况下X和Y匹配点的关系,两点集之间的误差符合具有均值为零且均匀标准差的高斯分布特征[14-15],这正是通过训练DBN所需学习的特征。设X-Y为DBN的输入,将输入样本划分为子块,然后依次输入到网络。本文采用的DBN由三级RBM组成,每一级的隐层单元数目为10。每一级的训练都是独立完成,训练次数设定为5次,具体训练过程为:
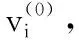
(2)
(3)
cj=cj+P(hj|v(0))-P(hj|v(1))
(4)
2)由子块训练得到第一级的参数后,再随机选取新的子块输入到这一级,按照同样的方法训练会进一步调整权重和偏差参数,直到所有的样本数据都被训练过为止。
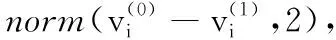
对于异常情况下的两个采样点集,一些异常值、噪声和缺失点可能会影响正常点的匹配关系。考虑到正常匹配点误差的高斯分布,异常点间的误差与该高斯分布不一致,因此,可以通过训练好的DBN从点集中检测噪声和缺失数据。
1.3 利用训练好的DBN识别异常点
考虑到数据不完整的情况,两点集的大小可能不一致。因此将每个点集分组为多个分块,然后将一个点集的分块与另一个点集的分块之间的误差依次输入到网络中。
利用正常点集训练DBN,除了学习权重和偏差参数外,还学习了分块的平均重构误差σ。当检测含有异常点集的数据时,由于含有异常点的分块间的误差不符合高斯分布,经过训练好的DBN之后将不能重建可见单元,因而分块的重构误差将远远大于σ。对于具有噪声的两个采样点集,如果来自一对分块的重构误差接近于σ,则将这对分块中的点视为点集的正常点。否则,若一对分块的误差大于k×σ,则其中的点被认为是点集中的噪声,而系数k的大小可以通过实验确定出最优值。
特别是对于有缺失数据的两个点集,当定义为Xb和Yb的一对分块间的误差大于k×σ时,其中一个分块肯定是没有匹配关系的。为了确定不匹配的分块,将Xb的相邻分块和Yb之间的误差重新输入到网络中。如果其中一对分块的输出接近于σ,说明在点集Y的某个区域中存在缺失点,并且Xb被标识为不匹配的分块;否则,将Yb的相邻分块和Xb之间的误差重新输入网络,以找到输出接近于σ的匹配分块,说明在点集X的某个区域中存在缺失数据,并将Yb标识为不匹配的分块。
2 模拟实验及分析
采用的实验数据包括鱼的2D点集、人脸的3D点集和兔子的3D点集,如图2所示。待配准的两个点集中,一个是原始采样数据,另一个则是由原始数据经过空间变换得到的。实验中模拟了缺失数据由5%上升到10%,以及噪声由30%上升到50%的情况。通过应用本文算法建立了点集间的匹配关系,并对实验结果作了定量评估。

图2 实验中的2D和3D点集Fig. 2 2D and 3D point sets in the experiment
实验主要分为两个阶段。首先,将原始点集和变换后的点集输入到DBN之前,这两个正常点集都被分块处理,并且分块的大小为10。通过DBN来训练样本,学习与点集有关的特征参数。接下来,将含有噪声或者缺失数据的点集输入训练好的DBN,对异常情况下的点集进行测试以检测异常值或未匹配点。
点集间要建立正确的匹配关系,首先就要能尽量减少异常点的影响,所以异常点误判为正常点的情况应降低。为此,本文采用精确率来评估所提出的方法的性能。根据异常点和正常匹配点的预测结果,假定用TP(True Positive)表示真正,TN(True Negative)表示真负,FP(False Positive)表示假正,FN(False Negative)表示假负,则评估标准精确率可以定义为:
precision=TP/(TP+FP)
(5)
从式(5)可以看出,精确率越高,说明配准受异常点影响的程度越小。
另外,为了进一步分析模型的性能,实验中根据系数k的大小在不同取值下绘制了受试者工作特征(Receiver Operating Characteristic, ROC)曲线,以反映模型区分正常点、异常点的性能,并且从中确定出最优的系数值。ROC曲线的横坐标是假正率(False Positive Rate, FPR),纵坐标是真正率(True Positive Rate, TPR),其中TPR、FPR分别定义为:
TPR=TP/(TP+FN)
(6)
FPR=FP/(FP+TN)
(7)
2.1 具有缺失数据的点集
为了模拟实际应用中数据缺失的情况,其中一个点集中的5%和10%的点被分别移除。缺失数据的两点集间的匹配结果如图3所示。
图3(a)中,鱼的正常点集随机选取的两个区域中有10%的点被移除,通过算法检测出两个点集中有匹配关系的点,并用箭头连接表示,无箭头连接的则为未匹配的点,如图3(b)所示。图3(c)中,人脸的一个正常点集中5%的点被移除,经过检测两个点集之间的匹配关系如图3(d)所示,其中有匹配关系的点以线连接。
2.2 具有噪声的点集
对于两个正常点集,在每个点集中分别添加30%和50%的随机噪声。含有噪声的两点集间的匹配结果如图4所示。
图4(a)中,鱼的两个点集中加入50%的噪声,它们之间有匹配关系的点在图4(b)中用箭头连接表示,无箭头连接的为未匹配的点。图4(c)中,人脸的每个点集中加入了30%的随机噪声,两个点集之间的匹配关系如图4(d)所示,其中有匹配关系的点以线连接。
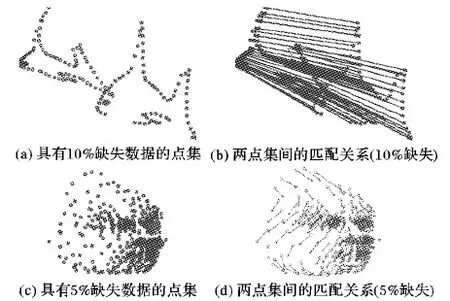
图3 缺失数据的两点集间的匹配结果Fig. 3 Matching results of two point sets with missing data

图4 含有噪声的两点集间的匹配结果Fig. 4 Matching results of two point sets with noise
2.3 测量结果
对于鱼的2D点集以及人脸和兔子的3D点集,根据所有实验的预测结果估算了点集匹配的精确率,结果如表1所示。表1中,分别给出了点集中的噪声比和点集中缺失数据的比例。

表1 实验中所用点集的精确率 %Tab. 1 Precision of point sets used in the experiment %
从表1结果可以看出,对于有噪声的采样点集,两个点集之间的匹配关系受随机噪声的影响很小,即使对于噪声为50%的点集也是如此。另外,对于数据缺失的采样点集,精确率稍有下降,反映出数据缺失对点集的匹配关系有一定影响。
实验中还对鱼的2D点集、人脸和兔子的3D点集,分别在含有50%噪声和缺失10%数据的两种情况下,根据系数k的6个取值(0.5,2,4,6,8,10)确定出相应的假正率(FPR)和真正率(TPR),并绘制了ROC曲线,结果如图5~6所示。
从图5~6可以看出,在两种情况下,FPR较低而TPR较高,这说明点集中的正常点较多地被归为匹配点,同时异常点较少地被误归入正常匹配的点集中。为了获得最优性能,本文选取曲线靠近左上角的点对应的系数k作为算法的最优系数,k=6,该系数对应的FPR相对较低,TPR相对较高。由此,利用这个训练好的DBN就能够识别点集中的异常点,排除了异常值对正常匹配关系的影响,同时保证了正常点的匹配关系,这有助于接下来获得较高的点集配准精度。
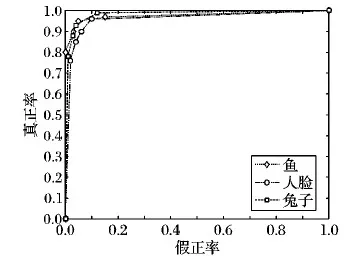
图5 含有50%噪声的三种点集的ROC曲线Fig. 5 ROC curve of three point sets with 50% noise

图6 缺少10%数据的三种点集的ROC曲线Fig. 6 ROC curve of three point sets with 10% missing data
对比图5~6可以看出,图5中的FPR明显低于图6中的FPR,说明在噪声情况下异常点很少被误判为正常匹配的点;同时图5中的TPR略高于图6中的TPR,说明在噪声情况下正常点能较多地保留在匹配点集中。图5~6对比结果说明,本文算法在噪声情况下比在缺失数据的情况下能更好地区分正常点和异常点。这是由于含噪分块间的误差分布不同于正常分块,而在缺失数据的情况下,由于点集邻域的相关性,未匹配的分块与缺失数据的邻域间的误差分布接近于正常分块,从而会将未匹配的点误归入正常点,导致了FPR的数值较高。
2.4 算法的比较
流形正则化一致向量场(MRCVF)算法能够在异常点集中排除外部数据,为此,将本文算法和MRCVF算法在同样的数据集上进行了比较。实验中利用人脸的3D点集,在加入噪声和数据缺失的情况下,比较了两种算法的精确率,结果如表2所示。

表2 不同算法精确率的比较结果 %Tab. 2 Comparison results of precision of different algorithms %
从表2精确率的结果可以看出:在含噪声情况下,MRCVF算法的精确率明显低于本文算法,说明MRCVF算法会将较多的噪声点引入到正常匹配关系的点对中,这不利于下一步点集间的配准;而在缺失数据情况下,两种算法的精确率都较高,说明缺失点对正常点的匹配关系影响较小。
3 结语
由于异常值、噪声和缺失数据会影响点集间匹配关系的确定,本文提出了基于DBN的学习方法来识别异常点和不匹配点。两个正常采样点集之间的误差分布可以通过训练DBN来学习,利用异常值或缺失数据的不一致的误差分布,可以由训练好的DBN识别出异常点。对2D和3D点集的实验结果表明,本文算法可以在噪声和缺失数据情况下识别出异常点,确保点集之间建立正确的匹配关系。不过由于点集邻域的相关性,缺失点对正常点的匹配关系有较小影响。未来的工作将着重于机器学习方法在点集配准中的应用,并将探索医学成像和图像引导的神经外科系统的配准方法。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
计算机应用与软件(2020年5期)2020-05-16
新生代(2019年10期)2019-10-18
劳动保护(2019年3期)2019-05-16
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
