
基于主动维保的城轨列车停车精度数据分析方法研究
2019-01-10 06:57李沃
科技视界 2019年35期
关键词:数据分析
李沃
【摘 要】通过对城轨运营主动维保模式的研究,提出了一种列车停车精度的分析方法。该方法通过对停车精度历史数据的分析和对比,可以精准定位和预判停车精度发生偏差的列车和站台,以及停车精度发生偏差的严重程度。一定程度上达到了停车精度的预警,为主动维保提供信息化智能化的支持。
【关键词】主动维保;停车精度;数据分析
中图分类号: U239.5 文献标识码: A文章编号: 2095-2457(2019)35-0014-002
DOI:10.19694/j.cnki.issn2095-2457.2019.35.006
0 引言
随着各行业的数据爆发增长,传统的数据处理技术已经不能够满足业务的要求,信息行业随之推出的各种针对海量数据处理的技术-大数据技术。大数据技术经过几年的发展已经成为成熟的技术,最初在金融行业应用,现在已经扩展到了各行各业。在大数据技术的基础上,国家层面提出了智慧城市的发展方向。交通是城市运转的重要组成部分,其中的轨道交通每时每刻都产生大量的运行数据。数据规模已经达到了大数据的标准,可以应用大数据技术对轨道交通的数据进行分析处理。停车精度时ATO(列车自动驾驶系统)所采集的重要的数据,是关系到轨道运营安全的关键数据,通过大数据技术对停车精度数据进行分析,可以对停车精度趨势进行预测,综合提升轨道运营和维护的水平。
1 研究背景和意义
车停车精度是城轨列车运行时的关键指标,停车精度的准确性,关系到列车乘客上下车速度,列车制动性能等指标[1],关系到行车安全和列车的运载能力,停车精度频繁发生过标,欠标或者停车精度不稳定的情况,会导致列车频繁进行自动运行调整,增加了ATO系统的负担,增加了轨道运营的风险。列车停车精度数据是通过ATO系统实时采集上来[2],以支撑列车和信号设备的实时监测系统的显示,但是目前建设的线路对这些数据的利用程度有限,主要包括以下几方面:
(1)数据多作为历史数据存储起来,没有进一步的整理和挖掘。
(2)数据格式繁多,维度不统一难以支撑数据分析。
(3)用户和供应商对数据本身价值的认识程度不高。
(4)用户只关注停车严重过标和欠标的情况,不关注整体列车停车精度的变化情况以及变化趋势。
所以有必要通过对历史数据的研究来发掘数据的价值,通过历史数据的分析得出有趣的趋势和预警的结论,从未提升运营和维护的水平,提升运维的主动性。
2 主动维保模式介绍
城市轨道交通系统主动运维决策支持技术是指一系列能够让城市轨道交通系统由被动运维(定期、事后维护保养)变事前基于系统状态进行运维决策的技术,包括实时监测、关键信息特征识别、故障演变规律、状态评估预警等一系列的技术[3]。传统的运营的维保工作主要是基于线路和列车设备发生的具体故障来进行,属于故障修的范畴。主动运维技术应用到轨道运营和维保工作当中后,会整体提升轨道运营维护的水平,将故障修全面提升到状态修,提升整体城轨运维的自动化和智能化水平,将维保工作由被动转化为主动。
3 列车停车精度介绍
停车精度是由列车自动停车控制,作为ATO系统的一项关键技术。为保证乘客安全,现在越来越多的站台都带有屏蔽门[4]。停车精度不准确会对乘客上下车造成影响,还会对列车的通信造成影响,严重影响城轨列车的运行效率,还会影响乘客的上下车,从而降低交通系统的运行效率。列车标准的停车精度设定的范围为±30cm,列车ATO系统会根据列车和环境的一系列参数和因素,去调整列车制动的精确性,从而保证列车停车精度的准确性。当列车出现了不准确的停车精度记录时候,说明ATO系统在制动控制方面出现了误差。然而更多的时候列车停车精度是在标准的范围之内,但是停车精度数值会出现周期性或者规律性的变化,具有偏离标准值的趋势,这种变化就要通过数据分析的方法去研究分析,得出一定的结论,在列车停车精度出现偏差之前,发现其趋势,及时检修维护,达到主动维保的目标。
4 大数据分析方法
大数据分析典型的分析方法的基础都是通过数据比较而进行的,经典的算法有以下几种,聚类分析,关联分析,矩阵分析,多维度分析等。其中的聚类分析是大数据分析众多方法当中,使用的最为广泛的一种分析方法,该方法可以将各种零散不连续的数据通过数据之间的距离进行科学的分类,每一类数据都具备相同的特性[5]。
对这些历史的设备状态数据进行数据分析可以得到许多有趣的结果。聚类分析是数据分析方法中发展比较早,相对成熟的方法,它将一个数据集合按照空间距离分为几个不同的子集合,是一种经典的分类算法。该算法的原理是随机选定子集的中心点,然后计算集合中每个元素之间的相对距离,通过不断的迭代和计算,调整每个子集的中心点,将每个离中心点空间距离最近的元素形成新的集合,直到子集不再发生变化,从而形成分类的子集,也就是最终的聚类。
5 停车精度大数据分析方法研究
ATO系统是一个全自动驾驶系统,系统在运行过程中会输出各种运行过程中的状态值。状态值包含了,速度,牵引,制动,停车精度,开关门,司机驾驶等各种状态值信息。这些状态值信息中有一部分信息具备都离散的特点,是适合做聚类分析的样本数据。聚类分析是数据分析当中最为有效的一种分析方法。该方法可以通过数学的方式对样本进行科学分类,具有相似性的样本会聚集在一类。通过聚类分析很快就可以明确数据样本当中所具备的群组,然后再对每个群组进行有效的分析,可以对一类问题进行统一的定位和处理。
大数据聚类分析的过程以2017年9月16日到2017年10月16日MSS系统采集上来的ATO系统识别的停车精度数据来说明问题。该数据的采集地点是北京7号线全线站台的停车精度,时间跨度为一个月,共计采集的样本数据为149342条数据,数据量近15万条数据,适合初步进行大数据分析的数据规模。
数据中针对停车精度包含了三个维度的属性。分别为停车时刻,车辆号和站台三个属性。可以针对这三个属性进行数据分析。
首先通过K-MEANS算法对停车精度的采集数据进行分类,根据维保经验,将停车精度的聚类分析深度定义到8个群组。经过10次迭代计算,最终得到了8个群组。分类结果中可以得出聚类分析已经可以将样本划分为8个群组,所有的样本都是有效的样本,没有的无效样本。样本聚类过程成功,说明停车精度数据确实在特定的条件下,存在不同程度的数据聚集。
将样本数据带入群组当中。得出每一个群组的中心点。中心点可以简单理解为每一组数据的二维平均值。计算结果为:1号样本,中心点为66.47,样本数量为36个;2号样本,中心点为1.12,样本数量为7737个;3号样本,中心点为-16.06,样本数量为71979个;4号样本,中心点为-9.28,样本数量为34714个;5号样本,中心点为32.45,样本数量为622个;6号样本,中心点为-22.7,样本数量为31381个;7号样本,中心点为2633,样本数量为7737个;8号样本,中心点为125.89,样本数量为240个。计算完成样本的中心点以后,可以明显看出有两个群组是不正常停车点的状态,分别是:
1号样本,中心点为66.47,样本数量为36个。
8号样本,中心点为125.89,样本数量为240个。
根据过标的标准,这两个群组样本数据已经严重的过标了,虽然都是严重过标,但是经过数据分析以后,严重过标的数据形成了两个群组中心,所以极有可能是由于两种原因引起的过标数据。这样就需要针对两个数据样本做进一步的维度分析一确定问题的根源。
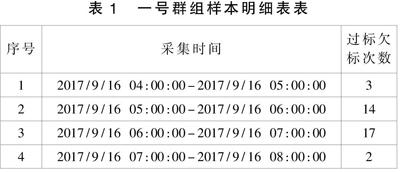
表1 一号群组样本明细表表
因为1号群组的样本数据不多,所以可以通过直接观察数据的方法进行问题的排查,经排查,车号,日期和站台数据都没有明显的集中,经过对数据的仔细比对以后,发现出现问题的时间都集中在早上的5点-7点。这样就发现了问题的规律。可以给维护人员和设备研发人员发出明确的关注信号,要其关注每天早上5點-7点之间的列车制动数据和停车精度数据,以分析停车精度出现少量过标的问题。
8号样本的中心点是125.89,其样本数量为240个。这个样本的数据量很大,而且125.89的停车精度也说明了停车过标问题极为严重,一定是需要重点排查和解决的问题。通过数据分析和对比,其他站台的过标欠标次数都是3个以内,焦化厂下行站台过标次数为220次。
通过智能化的分析,最终在站台维度上看到了问题的发生集中在焦化厂下行站台。
6 总结
通过对停车精度数据进行相应的数据分析,可以快速定位停车精度出现偏差的位置和时间,极大程度上提高了城轨运维的主动性,为主动运维提供了有效的数据支持。
【参考文献】
[1]罗岩.预测控制在列车自动驾驶系统中的应用研究[D].上海交通大学,2015.
[2]侯赞.ATO系统综合性能评价与列车多目标优化操纵方法研究[D].北京交通大学,2012.
[3]蒋益冲.轨道交通电源网管监控系统设计与开发[D].西南交通大学,2017.
[4]陈东.城轨列车停车控制算法及仿真研究[D].兰州交通大学,2018.
[5]游丽平,陈德旺,陈文,刘林.聚类集成技术在地铁站点类型研究中的应用[J].小型微型计算机系统,2019,40(01):236-240.
猜你喜欢
商情(2016年40期)2016-11-28
科技资讯(2016年18期)2016-11-15
考试周刊(2016年84期)2016-11-11
商场现代化(2016年22期)2016-10-18
