
泊车机器人障碍物视觉识别系统研究
2019-02-07 05:32王帅杨建玺
软件导刊 2019年12期
关键词:立体匹配
王帅 杨建玺


摘要:针对智能停车库中的泊车机器人视觉系统研究需求,提出一种基于双目视觉的泊车机器人障碍物识别系统。通过双目摄像头进行图像采集,利用张正友棋盘标定法进行双目相机标定;采用Bouguet进行立体校正,将高斯滤波与拉普拉斯算子相结合进行图像预处理;采用YOLO卷积神经网络对目标障碍物进行快速识别;利用区域匹配算法进行立体匹配并生成目标障碍物视差图;通过成像点和目标障碍物的立体几何关系计算得到目标障碍物的深度信息。实验结果表明,该系统具有良好的实时性和较高精度,障碍物识别时间平均为0.0901s,在2600mm具有最佳测距精度,可为泊车机器人自动泊车提供保障。
关键词:泊车机器人;双目视觉;相机标定;立体匹配;YOLO卷积神经网络
DOI:10.11907/rjdk.191255
中图分类号:TP303 文献标识码:A 文章编号:1672-7800(2019)012-0026-04
0引言
随着人们生活水平的提高,汽车保有量呈井喷式增长,停车成为日常出行的难题,智能停车库应运而生,而作为其核心运载工具的泊车机器人日趋受到科研人员关注,成为移动机器人领域应用重点。文献[2]中提到的泊车机器人采用激光导航方式,可完成较高精度的导航,但遇到障碍物就会自动停止,需人工干预,不能获取障碍物三维信息而进行自主避障;文献[3]中由德国Serva Trans-port Systems GmbH公司研制的新型泊车机器人Ray虽已应用到德国杜塞尔机场,但由于其采用3D激光扫描与激光导航方式,运行速度不高,技术难度大,很难得到推广;文献[4]中的国产最新泊车机器人导航方式为“激光导引+磁钉导航”,虽能完成泊车导航,但前期需对停车场进行较大改造,铺设磁钉,使机器人运行路径固定,使用不方便,成本较大,缺少对泊车路径上障碍物三维信息的检测。
以上文献中的泊车机器人虽能完成泊车导航功能,但均采用了激光导航技术,成本较高、技术难度大,不利于推广,且缺少对泊车路径上的障碍物(人为误进、车辆附属物脱落等)进行实时检测并获得障碍物三维信息的功能,易发生泊车事故。本文采用价格低廉的视觉传感器代替成本较高的激光传感器,利用双目视觉技术,设计一套泊车机器人障碍物视觉识别系统,利用Matlab进行双目相机标定,通过高斯滤波与拉普拉斯算子相结合进行图像预处理,采用YOLO卷积神经网络结合双目视觉完成目标障碍物的快速识别,具有成本低、精度较高并能实时获得丰富的障碍物信息等优势,弥补了国内泊车机器人缺少障碍物视觉识别功能的缺陷,为泊车机器人视觉避障奠定基础。
1系统设计
障碍物视觉识别系统作为泊车机器人的“眼睛”,必须保证其实时性和准确性,故本系统搭建双目视觉系统以实时获得丰富的环境信息。
系统由软、硬件系统两部分组成。硬件系统包括两台MV-3000UC相机、LP-03微调长型云台板、Inter i7、GTX970和16G内存,软件系统包括VS2015、Matlab2016a、OpenCV 3.3.0和Ubuntu14.04。
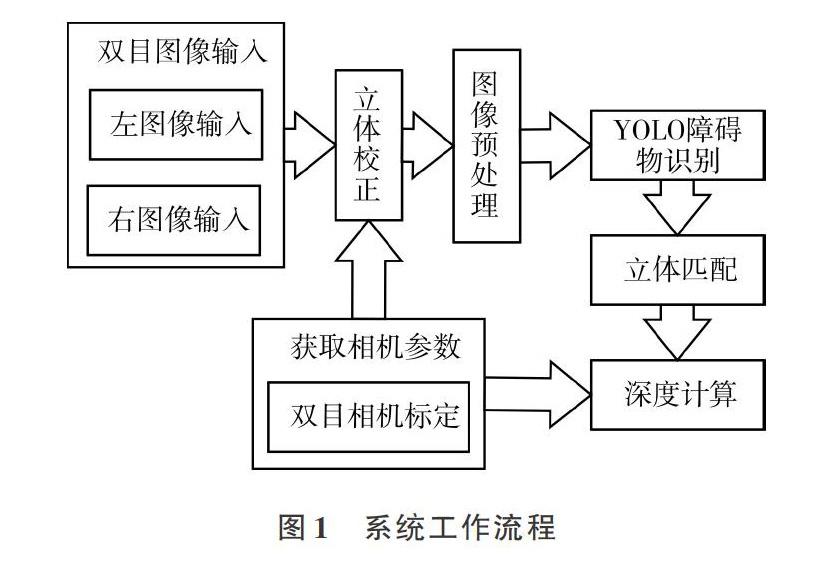
系统工作流程为:通过双目相机捕捉前方障碍物的目标图像,采集的图像经过立体校正、预处理、YOLO障碍物识别、立体匹配和深度计算,实现泊车机器人障碍物视觉识别功能。系统工作流程如图1所示。
2基于natlab的双目相机标定
由于OpenCV中的StereoCalibrate标定结果极不稳定,甚至会得到很夸张的结果,故本识别系统采用Matlab标定工具箱进行双目相机标定,标定步骤如下:
(1)采用棋盘标定法,利用Microvision USBDevice为左、右相机采集38张棋盘标定图片,并将图片分别命名为leftl-38,rightl-38,棋盘格规格为25mmx25mm。
(2)左相机标定:在Matlab环境下,调用Camera Cali-bration ToolBox,选择Standard选项,通过Image names自动读取文件名为left的棋盘标定图片。
(3)点击Extract grid corners完成对每张棋盘标定图片的角点检测。检测完成后利用Calibration进行左相机标定,验证标定结果,去除误差较大的图像对,保存标定结果。
(4)重复步骤(2)、步骤(3)进行右相机标定。
(5)在Matlab环境下,通过stereo_gui指令调用StereoCamera Calibration Toolbox,分别载人左右相机的标定信息,执行Run stereo calibration完成相机标定,双目标定结果如图2所示。
3基于openCV的Bouguet立体校正
根据双目视差求解距离公式是在双目视觉系统处在理想状态下推导的,在实际操作中,由于相机畸变、相机装配等原因,两个相机完全共面行对准的成像平面是不存在的。因此,必须对其进行校正以减少实际误差,校正步骤如下:
(1)共面:校正过程中两个图像平面均按照相机旋转矩阵R旋转一半,使重投影畸变最小。此时两个相机图像平面共面(畸变校正后光轴也平行),但是行不对准。
(2)行對准:极点是两个相机坐标系原点的连线和图像平面的交点,要想使得极点处于无穷远处(行对准),就必须使两个相机的图像平面和两个相机坐标系原点的连线平行,可通过计算Rrect矩阵使得极点处于无穷远处。
将Rrect左乘到旋转矩阵R分解后,作用于左右相机坐标系的矩阵,即可得到最终的立体校正矩阵。
4图像预处理
由于电磁信号干扰、左右光照不同等因素,导致采集的图像存在噪音,故本文设计一种图像预处理算法以达到消除噪音并增强图像边缘的目的。
首先,将彩色图像进行灰度化处理。鉴于噪音是在拍摄时产生的,故采用高斯滤波器消除此噪音,但高斯滤波器将图像进行一定程度的模糊处理后图像细节被破坏。针对这一问题,采用拉普拉斯算子锐化图像,提高图像边缘信息。
5障碍物识别与深度计算
5.1基于YOLO卷积神经网络的障碍物快速识别
YOLO全称You Only Look Once,是一个十分容易构造的目标检测算法,它将目标区域预测和目标类别预测整合于单个神经网络模型中,可在准确率较高的情况下实现快速目标检测与识别,适合泊车机器人应用环境。
YOLO卷积网络模型共有24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。YOLO卷积神经网络采用PAS-CAL VOC数据训练卷积层,然后利用卷积层和全连接构成RPN(Region Proposal Network)实现目标的类别和物体位置预测。
YOLO目标检测算法:首先把输入图像划分成SxS的格子,然后对每个格子都预测B个检测框(bounding boxes),每个检测框包含5个预测值:X,y,y,w,h和置信度(confi-dence)。其中,x、y是检测框的中心坐标,w、h是检测框的宽与高,每个格子预测c个假定类别的概率,最后输出特征图,其大小为SxSx(Bx5+C)。
5.2立体匹配
立体匹配建立介于两图像平面之间3D特征点的对应关系。由于泊车机器人障碍物视觉识别系统对实时性要求较高但对精度要求不高,故采用区域匹配算法完成立体匹配。基于OpenCV的区域匹配算法步骤如图3所示。
5.3深度计算
通过视差图和标定参数,将左右成像平面上的成像点转化到3D空间,可求得障碍物目标点的真实距离。重投影矩阵Q的表达式如下:
其中,(Cx,Cy)是左图像主点,厂是左目相机焦距,Cx是右图像上由Cx产生的坐标,三维坐标为(X/W,Y/W,Z/W),通过相机标定的参数和公式(6)可计算障碍物目标点的坐标值。
6实验结果与分析
为验证系统的实时性与准确性,对目标障碍物在同一车库环境不同距离情况下进行识别。首先对左右图像进行预处理,把处理后的左相机图像输入YOLO卷积神经网络,确定立体匹配区域,然后通过立体匹配计算视差,最后利用双目相机标定参数计算出目标区域中心点的实际距离。系统输出的障碍物识别及深度信息如图4所示。
通过9组实验得出的结果可知,该系统在2600mm距离处测距精度较高。随着实际距离的增大或减小,测距精度都呈现下降趋势;该系统通过GPU加速能够在100ms内完成对目标障碍物的快速识别,识别效率可满足泊车机器人障碍物识别要求,系统性能分析如表1所示。
7结语
随着汽车保有量的井喷式增长,泊车机器人应用前景将十分广阔。本文论述了基于双目视觉的泊车机器人障碍物识别系统。随着科研工作者对机器视觉与人工智能研究的不斷深入,搭载单一视觉传感器的泊车机器人有望研制成功。该机器人利用视觉传感器完成泊车路径规划、障碍物实时检测和自主避障,将硬件成本降到最低。但国内外相关研究不够深人,智能车库环境下的视觉识别算法不成熟,硬件成本较高。针对这些问题如何制造出低成本、高效率的泊车机器人将是未来研究的重点。
猜你喜欢
科技创新与应用(2018年17期)2018-06-28
现代电子技术(2018年1期)2018-01-20
测绘科学与工程(2017年3期)2017-08-16
测绘科学与工程(2017年1期)2017-05-04
哈尔滨理工大学学报(2016年4期)2016-11-10
浙江大学学报(工学版)(2016年11期)2016-06-05
应用科技(2015年5期)2015-12-09
现代电子技术(2015年18期)2015-09-16
电视技术(2014年19期)2014-03-11
