
基于词向量的图书馆图书推荐模式研究
2019-02-20 14:26杨志明
现代商贸工业 2019年4期
杨志明

摘要:个性化推荐算法中,传统的协同过滤算法通常存在数据稀疏和计算复杂的问题,造成实际推荐效果不够理想。据此,针对图书馆图书推荐问题,提出了基于词向量的图书推荐算法,实验中通过和传统的协同过滤算法对比,基于词向量的方法不管是在计算图书相似性还是实际推荐效果均显著提升。
关键词:图书馆;推荐系统;词向量;word2vec;协同过滤
中图分类号:TB文獻标识码:Adoi:10.19311/j.cnki.16723198.2019.04.093
1引言
个性化推荐中,基于内容的推荐算法、基于协同过滤的推荐算法和混合推荐算法方法最为常用。而在数字图书馆图书推荐中,基于协同过滤和关联规则的推荐算法是最为常用推荐算法。但是由于大多数高校图书馆没有读者对图书的评分信息,导致传统的协同过滤算法面对数据稀疏和计算复杂的问题。而基于关联规则的推荐算法则存在关联规则不容易发现的问题,最终导致两种算法在实际的推荐中效果均不理想。因此本文提出基于词向量的方法计算学生与图书的相似度从而帮助优化推荐系统的推荐结果。
2传统协同过滤算法
传统的协同过滤算法通过对学生借阅记录的挖掘发现学生借书的偏好,基于不同的偏好按照相似性对学生或者图书进行划分从而推荐相似的图书。协同过滤算法又可分为基于邻居的协同过滤算法和基于模型的协同过滤算法,基于邻居的协同过滤又分为两类,分别是基于用户的协同过滤算法,和基于物品的协同过滤算法。
基于用户的协同过滤,通过挖掘学生借阅记录,来度量学生之间的相似性,找到“邻居”,基于学生之间的相似性做出推荐图书。基于物品的协同过滤的原理和基于用户的协同过滤类似,只是在计算邻居时采用物品本身,不是从用户的角度,即根据借阅记录找到相似的图书,然后根据学生的历史偏好,给该学生推荐相似的图书。在数字图书馆图书推荐中,由于用户特征数据、行为数据的缺失,导致传统的协同过滤算法面临数据稀疏等问题,最终导致推荐效果不理想。本文提出基于word2vec的方法计算学生与图书特的相似度从而帮助优化推荐系统的推荐结果的方法。
3词向量和Skip-gram模型
word2vec是 Google 的Mikolov 等人提出的一种分布式词向量模型,包括 Skip-gram 和 CBOW,模型结构如图1所示。
4.2实验设计和结果分析
4.2.1实验过程
传统的协同过滤算法依赖的读者图书评分数据,高校图书馆后台管理系统中并不存储产生读者对图书的评分数据,而生成读者图书评分数据可根据本文所采用的数据集中读者借阅信息表来生成,采用目标读者对目标图书的总借阅天数来代表读者对该图书的评分,其中0在矩阵中表示读者未借阅过该图书,并且对评分进行归一化处理。
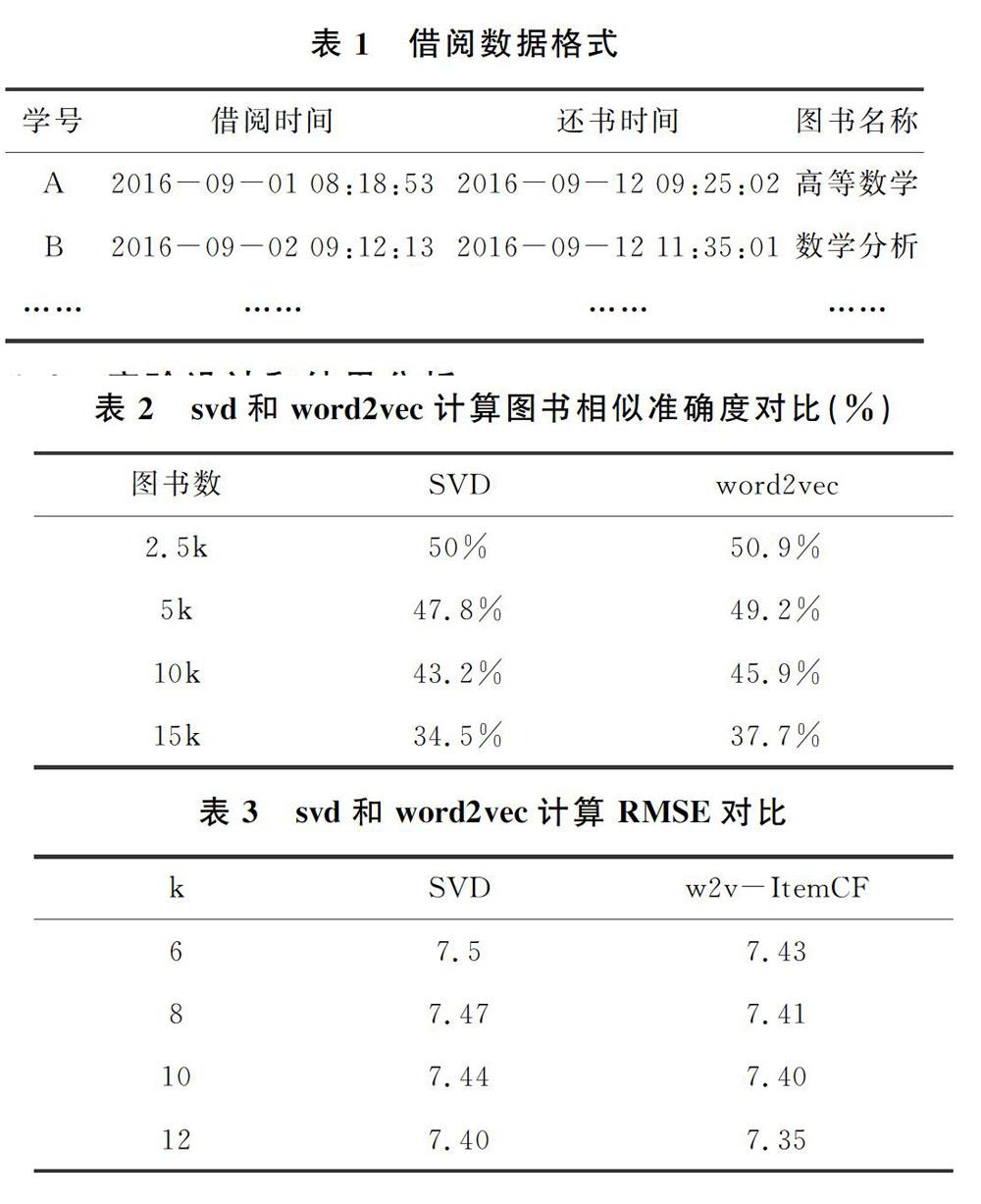
为了评估词向量方法在计算图书相似性的有效性,本章采取计算目标图书A与其紧邻的K本图书在图书类别上的一致性的方法来评估,其中每本图书的类别按照《中图法》的标准确定。如O212.6/23的分类为O21,通过word2vec方法计算的该书最相近的4本图书为O211.64/15,O212.4,O212.1/94,O241.6/48-1,几本书的分类分别为O21,O21,O21,O24,采取投票法确定这几本书的最终分类为O21,和目标图书的分类一致。实验中我们采取word2vec以及基于SVD的协同过滤两种方法计算相近图书,在不同近邻数k(k=6,8,10,12)下对不同数目的图书进行实验。
本文基于词向量的协同过滤方法主要思路把图书名称看作单词,以学生借阅的图书看作句子,利用 word2vec 模型构建图书的向量空间。具体地,把学生的记录按照7:3的比例随机的分训练集和测试集两部分,分别构建基于word2vec的物品协同过滤模型(w2v-ItemCF)、基于SVD的协同过滤模型(SVD),在测试集上根据学生的历史借阅图书推荐相似的图书从不同方面评估推荐效果。
评估推荐算法推荐效果的方法有很多,主要分为离线实验、线上测试对比、用户调查等几种方式。线上测试通常是采取线上A/B测试的方式对效果进行评估,而用户调查则是通过科学的调查方法,比如问卷、访谈等形式去估计评估效果,本文采用离线测试的方法对推荐效果进行对比。具体地,如文献[1],评估推荐效果的常用指标有用户满意度、预测准确度、覆盖率、多样性、新颖度、惊奇度、信任度、健壮性等。本文由于是采取离线实验的方式,主要从评分预测RMSE来评估推荐系统。
4.2.2实验结果
表2是在近邻数为10下分别利用word2vec以及SVD计算目标图书和近邻图书类别一致性的对比结果,结果显示基于word2vec的方法在不同数量图书下计算的准确度均比SVD的方法高。 表3是两种方法在训练集上的误差情况,可以看出基于word2vec的方法在预测误差也明显小于SVD的方法。
5结论
本文针对数字图书馆图书推荐问题,针对只有借阅记录的数字图书馆,传统的协同过滤算法存在数据稀疏问题,针对此问题提出了基于词向量的物品推荐算法。经过实验对比显示基于词向量的方法在图书相似性计算以及实际推荐的效果均好于传统的SVD方法。
参考文献
[1]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2]王飞,杨国林.高校图书馆个性化推荐服务算法研究[J].内蒙古师大学报(自然汉文版),2015,44(6):802807.
[3]宋楚平.一种改进的协同过滤方法在高校图书馆图书推荐中的应用[J].图书情报工作,2016,60(24):8691.
[4]Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013.
[5]Ozsoy M G.From Word Embeddings to Item Recommendation[Z].2016.
