
基于爬虫的银杏信息整合分析系统
2019-03-04 11:05苗哲
电脑知识与技术 2019年34期
摘要:基于网络的银杏信息整合分析系统旨在让银杏研究和普及更加方便快捷,从而带动对银杏这一隐藏的宝库的全民探索。本系统是利用python语言实现网页抓取和信息筛选的,可以按照选择的关键词在某网站部署爬虫,从而获取需要的信息。
关键词:网络;银杏;爬虫;信息整合
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)34-0087-03
1 概述
基于网络的银杏信息整合分析系统旨在让银杏研究和普及更加方便快捷,不仅对专业林学人士提供了另外一种更加现代化的研究道路,还对普通大众了解和普及银杏知识有较大的影响,从而带动对银杏这一隐藏的宝库的全民探索。网站内除了提供基本的银杏信息以及相关的增加、删除、更改和查询功能外还创新地在网内实现站内搜索功能,使得用户可以直观地看到全网或指定网站内关于银杏的全面信息。
2 爬虫技术
2.1 爬虫分类
網络爬虫是一种信息采集的技术,按照实现的技术可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深层网络爬虫。
通用网络爬虫也叫作全网爬虫,适用于搜索范围较广的情况。爬行方法又分为深度优先和广度优先。
深度优先策略是以根网址为开始页面,依次爬取下一级网页,直至爬取结束,再从上一级网页的其他下级网页开始爬取,直至根网页的所有子网页都被爬取结束。这种爬取方法会浪费爬取时间和空间,只适用于站内搜索。
广度优先爬取策略,是从根网页开始,爬取此页面上所有有用的链接,并存储于网址集合,然后从网址集合中依次爬取页面信息,每次爬取前遍历集合,若已经爬取过,则直接丢弃。这种方法爬行深度浅,但范围广,内存要求低。
以上几种爬虫技术各有优缺点,具体使用需要按照系统的需求来更改。由于本系统在当前阶段更注重简介程度且爬取是否方便,所以使用的是通用网络爬虫技术,此技术需要在程序中搭建一套框架,按照一定流程来完成对一个网站内信息的爬取。
2.2 爬虫在数据分析领域的应用
基于爬虫的银杏信息整合分析系统,大致上是通过爬虫爬取网络上的数据,再用BeaytifuISoup对数据进行细化分析,最后存入后台并输出于前端。爬虫在数据分析邻域,是分析数据的来源和基础,而数据分析又为爬虫提供了新的可爬取的源页面。数据采集和数据分析相辅相成,合作完成网络数据的整合于分析。
2.3 爬虫scrapy框架
Scrapy是一个专门用于实现爬虫的框架,内部具有对HT-ML和XML源数据筛选和处理的功能。它提供了许多过滤器,用于在spider之间实现共享,且支持多次使用。
Scrapy是一个框架,使用者可以根据框架的模块来编写爬虫。
1)具有对爬虫性能和状态的检测工具,尤其在有多个爬虫并行工作时,可以用来检测并上报爬虫的效率、是否成功。
2)提供了shell终端来与用户交互,自动检测XPath表达式,使得用户实现爬虫更加简单快捷。
3)提供了一系列工具,例如System service、Web service、Telnet终端、Logging,还可以支持Sitemaps爬取。
4)具有缓存的DNS解析器。
2.4 爬虫BeautifulSoup工具
在抓取到所有页面信息后,还需要将庞大的信息进行细化和分类,此时就需要BeautifuISoup工具。
Beautiful Soup是python的一个库,它提供了许多高效的函数,用来筛选和处理对用户有用的数据。Bs4是一个工具箱,处理刚爬取得到的网页数据文档,从而为用户提供数据,它实现起来比较简单,所以代码量还是比较小的。
Beautiful Soup在处理文档前,首先将输入的待处理文档转换为Unicode编码,再以utf-8编码转化并输出处理好的文档,所以一般情况下,无须开发人员考虑过多的编码问题,Beauti-ful Soup可以自动识别编码方式。
3 开发语言及软件
3.1Python语言
Python是一种面向对象的解释型计算机程序设计语言,是纯粹的自由软件,已经广泛用于web编程和系统事务处理。“优雅”“明确”“简单”是Python的设计概念。Python语言具有较为强大的扩展性,可以融人多种语言中,也可以兼容各种语言制作的模块,只需将用其他语言完成的代码模块生成包,在Py-thon中导入该第三方包即可使用。
相对于java、c#、C++等静态编程语言,Python抓取网页更加简单明了,而相对于shell等其他动态脚本语言,python的url-lib包具有较为完整的访问网页的工具。除此之外,许多的网站都是不允许普通爬虫的,往往需要一些关键词段,例如登陆注册信息,这时就需要模拟用户的行为,而在Python中提供了Re-quests等第三方包,可以比较容易地实现网站的爬取。
3.2 开发软件PyCharm
PyCharm是一种基于python语言的开发工具,并附带有丰富的库。PyCharm主要功能:
1)代码自动补全:提供了代码补全功能,支持代码折叠和分割窗口的智能化操作,可配置的编辑器,可帮助用户更快更轻松地完成编程工作。
2)项目代码导航:可以帮助用户在一个文件中通过导航进入另一个文件中的对应函数,从一个方法可以跳至申明处或穿过类的层次。
3)代码检测:根据用户的输入自动检测语法错误,包括变量申明、类型、作用域等问题,还包括检测前推,后退和移动重构的功能。
4)支持Django:PyCharm有自带的css、html和JacaScript编辑器,使得用户可以更方便地使用Django框架。
5)支持诸多引擎:用户可以使用多种引擎进行css、html和JacaScript文件的調试,包括360极速、IE、火狐、Google等浏览器。
4 系统功能需求分析
系统需求分析是一个系统的开端,它规定了系统需要完成什么功能,完成至什么程度,如何完成此功能以及需要注意的问题,用户操作需要哪些细节考虑。
基于爬虫的银杏信息整合分析系统的客户功能模块需要的是一个人性化、操作方便且数据质量高的网站。此系统要求将网络中各大网站的银杏树相关信息提取在个人网页中,其中两部分最为重要,一是显示在页面上数据的质量,二是页面的美化和人性化。按照页面划分,系统可分为welcome页面和主页面;按照功能模块划分,主页面可分为三个模块,分别是导航栏模块、研究专题模块和银杏公园模块。
4.1 welcome页面功能需求分析
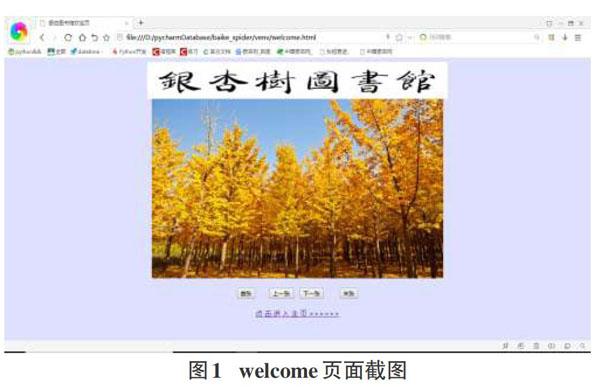
Welcome页面:作为网站给用户的第一印象,需要足够美观且简约,并能提供图片预览操作,以及相应的图片切换操作,页面下方安排一处链接,点击跳转到主页面,也就是主要信息的放置页面。如图1。
4.2 主页面导航栏功能需求分析
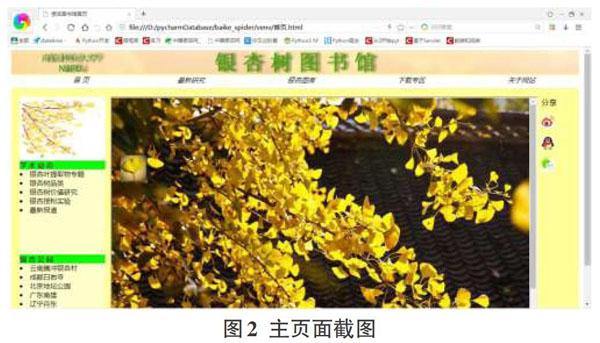
主页面是整个系统的核心页面,是主要数据的放置处。页面包含了三个板块。将主页分为多个板块,目的是使整个网站的外观更加美观,页面更加简洁清楚。
第一版块为导航栏,分为“首页”“最新研究”“银杏图库”“下载专区”“关于网站”五个栏目。
点击“首页”按钮,将会跳转至welcome页面。
点击“最新研究”按钮,将会在主页显示栏展示爬取的最新研究信息。
点击“银杏图库”按钮,将会在主页显示栏展示爬取的银杏相关图片,带有切换图片功能和下载图片功能。
点击“下载专区”按钮,将会提供“最新研究下载”,“最新报道下载”,“图片下载”和“研究专题下载”四个图形按钮,用户点击则下载对应的文件至本地。
点击“关于网站”按钮,则显示一个静态页面,包含网站的来源,名称,作者,指导和联系方式。
第二板块是左侧的两个模块,“学术动态”和“银杏公园”。
第三板块是显示板块,布置于网页的中间,用于根据用户操作展示相关的信息。
如图2所示:
4.3 学术动态页面功能需求分析
该页面是通过主页面中学术动态栏所选方向决定的,总共包含了五个方向,分别是“银杏叶提取物专题”“银杏数品类专题”“银杏树价值研究专题”“银杏树授粉实验专题”和“最新媒体报道专题”。这些信息均是从网络中爬取得到,并经过筛选后整合至页面中。该板块作用是搜索相关网站集,将银杏树相关研究方向的最新发展动态集合于“银杏图书馆”网站,使得用户可以在本网站内了解到最新的研究动态。
4.4 银杏公园页面功能需求分析
银杏公园页面也是由主页面中相关板块选项决定的,用于静态展示全国几个著名的银杏树旅游景点的相关信息,包含图片、简介和旅行社链接。简介包括景点地址和具体介绍。用户可以在此网站点击链接直接进入旅行社的对应旅行线路信息,这样可以拓展网站的范围,使得覆盖面更加广泛,网站的延展性更强。
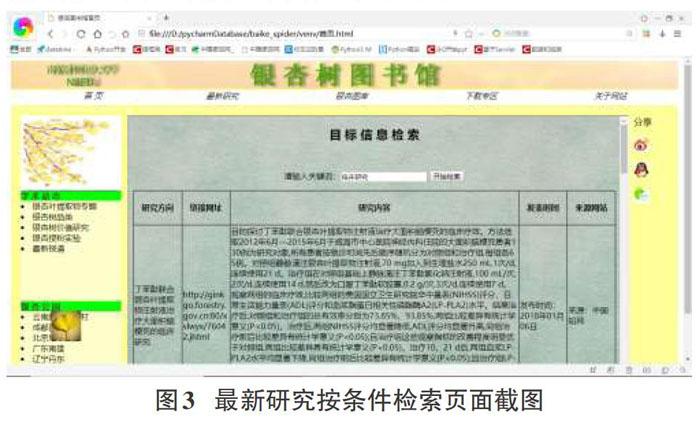
4.5 信息检索功能需求分析
信息检索功能设置在信息展示的相关页面上,若不使用此功能,即不在文本框中输入任何内容,则会在页面上显示所有的完整数据。若用户输入关键词,则系统按关键词搜索文件中所有文章的标题,若含有关键词,则符合筛选条件,最后将对应的文章集合输出到页面上,这样将会大大降低用户自己搜寻的精力,使得用户操作更简单,更舒适。如图3所示。
4.6 网站分享功能需求分析
现如今众多的网站都配备有网站分享功能,为了更加现代化、跟上潮流并提高用户体验,使得网站更加人性化,特添加了网站分享功能。
按钮组共包含了三个图片按钮,分别为微博、微信和QQ分享链接。点击微博或QQ按钮,会跳出微博和QQ空间自带的发布页面,然而微信并没有这样的功能页面,且其为暂时用户最多的软件之一,所以还需要设置微信分享功能:点击微信按钮后,会跳出微信网页版的登录界面,即扫二维码登录微信,登录后由用户自行分享。
5 爬取网站的考量
基于爬虫的银杏信息整合分析系统,最重要的部分便是爬取的信息源是否具有足够高的专业度、准确度。在选择爬取网站时,需要考虑到如下几个因素:
权威性:一个系统的信息源是否可靠,决定了该系统的发展和命运,不纯净、不准确,甚至是错误的信息源会影响一个系统呈现给用户的数据精度。
针对性:一个数据源若是缺乏针对性,就会造成数据模糊,精度不足,从而呈现于自己系统上的数据文不对题,同样造成用户体验差。
格式清晰:分为数据格式和HTML网页格式。网站的数据格式指文字内容中是否掺杂一些无用的空格、乱码、标点符号,是否有正常的分段。HTML网页格式指的是爬取对象的HTML格式网页是否规范,是否有足够的标识来标记所需要爬取的标签,
是否反爬虫:爬取一个网站的前提是该网站是否允许爬虫爬取网页内容。若存在反爬虫程序或是防火墙之类的阻挠,则此网站不可选为“银杏树图书馆”爬取对象。
数据量:是指一个待爬取网站的相关数据是否完善和足够,当一个网站的数据量太小时,也失去了爬取的意义。
重复度:若是该待爬取网站有较多的内容是重复于一爬取网站的,则该页面也是不宜爬取的。
综合考量,本系统爬取了如下几个网站:
百度百科网、中国林业网一银杏网、中国银杏网(非官方网站)、中国植物志、全景网、知乎网。
6 总结
本系统旨在将网络中错综繁杂的银杏树信息有条理的显示在网页中,供用户浏览和下载,之后会增添数据量,爬取更多网站的信息,并添加更多方便用户的功能。
参考文献:
[1]曹福亮.银杏[M].北京:中国林业出版社,2007.
[2]胡松涛.PYTHON网络爬虫实战[M].北京:清华大学出版社,2016:13-18.
[3]范传辉.Python爬虫开发与项目实战[M].北京:机械工业出版社,2017:47-76.
[4]埃里克·马瑟斯.Python编程从入门到实践[M].北京:人民邮电出版社,2016:123 -126.
【通联编辑:王力】
收稿日期:2019-09-16
作者简介:苗哲(1971-),男,江苏南京人,南京林业大学信息学院,高级实验师,硕士,主要研究方向为计算机应用
猜你喜欢
房地产导刊(2022年10期)2022-10-18
时代邮刊·下半月(2021年10期)2021-10-23
现代信息科技(2021年21期)2021-05-07
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
现代园艺(2018年2期)2018-03-15
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
电子测试(2015年18期)2016-01-14
计算机与网络(2014年7期)2014-03-25
