
基于FCN 的图像感兴趣区域提取与细粒度分类的研究
2019-03-05 01:37戴志鹏
现代计算机 2019年3期
戴志鹏
(广西师范学院软件工程系,南宁530000)
0 引言
细粒度分类是对大类进行类内的识别,例如分类不同的鸟类[1]、犬种[2]、花种[3]、飞机模型[4]等。一般细粒度识别可以分为两种,即基于强监督信息的方法和仅使用弱监督信息的方法。基于强监督信息的方法对于训练集的标注成本比较高,所以基于弱监督信息的方法的研究有很大的意义。在弱监督信息的细粒度分类的过程中最重要的是如何定位有用的主体。有利于细粒度分类的定位方法分法主要为两种:一个是对象整体的定位,一个是对象重要部分的定位。
在弱监督的细粒度分类中有几个比较经典的方法:Two Level Attention Model[5]、Constellations[6]、Bilinear CNN[7]等。
Two Level Attention Model:该模型主要分为三个阶段:①预处理模型:从输入图像中产生大量的候选区域,对这些区域进行过滤,保留包含前景物体的候选区域;②物体级模型:训练一个网络实现对对象级图像进行分类;③局部级模型。由于预处理模型选择出来的这些候选区域大小不一,有些可能包含了头部,有些可能只有脚。为了选出这些局部区域,首先利用物体级模型训练的网络来对每一个候选区域提取特征。接下来,对这些特征进行谱聚类,得到k 个不同的聚类簇。如此,则每个簇可视为代表一类局部信息,如头部、脚等。这样,每个簇都可以被看做一个区域检测器,从而达到对测试样本局部区域检测的目的。
Constellations:该方案是利用卷积网络特征本身产生一些关键点,再利用这些关键点来提取局部区域信息。对卷积特征进行可视化分析,发现一些响应比较强烈的区域恰好对应原图中一些潜在的局部区域点。因此,卷积特征还可以被视为一种检测分数,响应值高的区域代表着原图中检测到的局部区域。不过,特征输出的分辨率与原图相差较大,很难对原图中的区域进行精确定位。受到前人工作的启发,作者采用的方法是通过计算梯度图来产生区域位置。卷积层的输出共有P 维通道,可分别对应于P 个关键点位置。后续对这些关键点或通过随机选择或通过Ranking 来选择出重要的M 个。
Bilinear CNN:将原本分散的处理过程,如特征提取,模型训练等,整合进了一个完整的系统,进行端到端的整体优化训练。Bilinear 模型Β由一个四元组组成:Β=(fA,fB,Ρ,C)。其中,fA,fB代表特征提取函数,即网络A、B;P 是一个池化函数(Pooling Function);C 则是分类函数。特征提取函数f(∙)的作用可以看作一个函数映射,f:L×I →RK×D将输入图像I 与位置区域L映射为一个K×D 维的特征。而两个特征提取函数的输出,可以通过一个双线性操作进行汇聚,得到最终的Bilinear 特征。其中池化函数的作用是将所有位置的Bilinear 特征汇聚成一个特征。到此Bilinear 向量即可表示该细粒度图像,后续则为经典的全连接层进行图像分类。另一种对Bilinear CNN 模型的解释是,网络A的作用是对物体/部件进行定位,即完成物体与局部区域检测工作,而网络B 则是用来对网络A 检测到的物体位置进行特征提取。两个网络相互协调作用,完成了细粒度图像分类过程中两个最重要的任务:物体、局部区域的检测与特征提取。Bilinear 模型由于其优异的泛化性能,不仅在细粒度图像分类上取得了优异效果,还被用于其他图像分类任务,如行人重检测(Person Re-ID)。
1 准备工作
Two Level Attention Model 的方法是先利用大量的候选区域进行二分类,确定候选区域是否为前景得到object-level;再根据确定的前景区域进行聚类分到part-level。这个方法通过两个图像等级的提取(主体与部位),取代了昂贵的人工标注,使得图像分类研究能够有了脱离昂贵人工标记的可能从而提高了算法的处理效率。但是大量候选区域的判断运算也会使得计算时间较长。为了能减少候选区域的计算时间,本文考虑使用一种高效率的object-level 图像提取方法。通过对FCN(Fully Convolutional Networks)[8]学习和理解,将FCN 用于object-level 的提取工作。
Constellations 利用卷积网络的特性产生一些关键点,再利用这些关键来提取局部信息。基于这一思路的提示,卷积神经网络层的每一层输出都可以认为是对所有关键点的突出处理为下一层的处理提供重要信息。所以综合上述两个想法本文提出了一种方法:基于FCN 并结合卷积网络特性提取图像感兴趣区域作为细粒度分类的预处理。
Bilinear CNN 是一种端到端的整体优化训练方法,使用A、B 两个特征提取网络形成双线性CNN 模型,使得两个网络得到不同的特征,在进行biliner 操作得到biliner vector 使得两个不同特征融合有利于图像的提取。基于这一思想本文使用二级网络对图像进行分类:第一个网络进行感兴趣区域提取并将感兴趣区域分割提取作为第二个网络的输入,即将两个网络串联使用。
FCN 作为图像语义分割的先河,实现像素级别的分类(即end to end,pixel-wise),为后续使用CNN 作为基础的图像语义分割模型提供重要基础。CNN 对图片的conv 计算过程如图1 中绿色部分所示主要是由conv、poooling 层构成经过由conv、pooling 层组成的特征提取训练之后,conv 层和pooling 层的输出的多维特征图都可以看成对不同特征的突出表示,因此可以使用特征图经过融合来提取感兴趣区域。

图1 VGG16简图
在融合特征图为感兴趣区域时需要融合不同尺寸的特征图,在FCN(Fully Convolutional Networks for Semantic Segmentation)[8]中能够很好地完成这个工作,主要是用到上采样的过程。反卷积就是一种较好的上采样,反卷积可以看为卷积的逆过程。卷积的过程如下:
input=4×4,Kernel size=3×3,padding=valid,stride=1,output=2×2。
对于卷积的计算需要将输入输出展开为一维向量下x、y,则卷积的过程为:

C 为与kernel 有关的稀疏矩阵。
由反卷积为卷积的反操作,使用转置卷积来实现:

在FCN[8]也是用到了标注框信息,所以本文提出一种无需标注框只需要图像级别的弱监督信息就可以分类图像的方法。
2 本文方法
本文分为两步:
(1)利用细粒度数据集(鸟、狗、花、车等)对CNN(VGG16)进行进一步训练,使得CNN 网络的卷积层能够更好地提取关键特征。
(2)对训练好的CNN 网络使用FCN 提取感兴趣区域,关键如何确定阈值。
2.1 CNN网络训练
本文主要使用VGG16(ImageNet)进行进一步训练,VGG16 网络已经能够很好地将大类与其他大类很好的分类出来,但是对于类内的关键提取比较模糊不能很好的体现出来,所以需要使用细粒度分类的数据集进行进一步的训练。
本文在使用VGG16 进一步训练是基于ImageNet的,将全连接层进行修改。修改如下:
(1)将前两个全连接层输出维度由2048 改为1024,降低参数量有助于提高训练效率。
(3)使用全部数据集经过图片预处理使用实时数据提升,以20000 张图片为一个epoch 分别进行不同epochs(5、10 等)的训练。
2.2 FCN与特征融合
2.1 小节中通过对VGG16 模型的进一步训练,新的VGG16 模型有70%以上的正确识别率(以CUB200-2011 数据集为例),因此新的VGG16 模型对birds 的主体的注意力[5]已经能正确的指向识别主体(birds 的整体或者包含整个头部),模型的注意力有助于分类的正确率的提高。所以下面将通过FCN 融合的方法来将模型形成的注意力应用与图像感兴趣区域的提取工作。
在文献[8]中,作者使用单个pool 层的输出来做语义分割,在识别物体所占图片面积不固定时将会使用同一个pool 层来做分割可能结果不是最好,因此,本文使用多个pool 层来做分割。有助于提高准确率。FCN的训练需要对原始数据集进行处理对每个像素所属的类进行划分(即是背景还是前景),所以FCN 的标注成本也是昂贵的,同时训练时间也是比较长的。针对也上问题本文提出了一种针对单个对象的固定权值的FCN 特征融合模型,这种模型有以下特性:
(1)反卷积部分的权值是无需训练,根据卷积核的尺寸确定,卷积核尺寸需要根据步长来确定。为了便于融合不同pool 层的特征上采样设定步长为2(即deconv 的步长为2),当需要提取区域为一个对象时(本文以鸟类为例),区域一般为一个连通的整体。为了尽可能去除噪声(背景)的影响,本文使用size=4 的卷积核进行反卷积,有利于将提取对象相应位置像素高亮处理,为下一步多特征进一步融合提供基础,FCN 结构如图2 所示。

图2 FCN
(2)得到上一步所得的224×224 的多维特征图需要将多个特征融合到一个类似于标签图的224×224×1灰色图中,基于上一步得到的时高亮区域可以采用像素均值的方法来实现这一过程:

m[i ,j] 为融合后对应位置像素的值,Dinput为(i)中生成的多特征的维度,f[n,i,j]为多特征第n 个特征图中位置的像素值。
B.最佳绿叶说的就是你啦!虽然只是配角,但你也是离主角最近的配角。你需要做的是坦白真诚地面对他人,这样才能赢得观众的心。

图3
图3(a)为感兴趣区域提取网络的输入(即原图);图3(b)为特征融合产生高亮图;图3(c)为经过二值化处理过的图3(b)的二值图并恢复原有尺寸;图3(d)为使用图3(c)切割原图的效果。
为了将图3(b)的高亮特征图转化成图3(c)的二值图像,需要选取合适的阈值,如何设定阈值将在2.3小节介绍。
2.3 阈值
在2.2 小节中特征融合产生的224×224 高亮图输出需要二值化成为标签图,这一过程需要确定阈值。阈值过大或者过小都会导致标签图的不准确,会使得重要的特征消失或者有过多的背景加入,这样提取的区域就会与预期相差较大。因此阈值的确定是相当的重要的,同是为了体现本文的方法的准确度,需要将本文所获取的标注框与真实人工标注的标注框进行比较。
(1)判断标准
为了比较本文标注框与真实人工标注框的准确度,本文使用IOU(Intersection Over Union)[9]。IOU 是一种测量在特定数据集中检测相应物体准确度的一个标准。IOU 是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxes)的任务都可以用IOU来进行测量。IOU 分数是对象类别分割问题的标准性能度量[9]。给定一组图像,IOU 测量给出了在该组图像中存在的对象的预测区域和地面实况区域之间的相似性,并且由以下等式定义:

其中TP、FP 和FN 分别表示真阳性,假阳性和假阴性计数。本文使用将计数用面积代替计数。作为对IOU 的补充,本文同时使用公式(5)、(6)作为性能评价标准:

K1:表示真实标记框有K1 大小的比例属于预测标记框。K2:表示前景占预测标记框K2 比例。
(2)阈值的选取与调整
本小节通过对特征融合产生的高亮进行分析来提取标签图。同过图3(a)与图3(b)大体可知:高亮图的高亮区域几乎是鸟的主体为位置。因此需要根据高亮图的亮度(即像素值的大小)来判断一个像素是否属于鸟,一个像素的像数值越大(即越亮)属于鸟的区域的概率越大,所以概率与像素值成同方向变换关系。由于原图的不规则性:①图像中鸟整体占图像的比例不一致,且相差较大;②鸟的形状的不确定性:有的张开翅膀、有的站着、有的卧着等;③图像背景的不确定性:有的是海、有的是树、有的是人等。通过2.1 小节的训练VGG16 网络能够有效地减少原图的不规则性对有效区域提取的影响。

偏移量M 的确定过程:
步骤1:对特征融合图生成直方图p;
步骤2:偏移量M 是针对鸟主体占图像面积太大或太小提出的。设iPL为偏移因子通过直方图p 得到,每一张特征融合图iPL的计算算法如下:
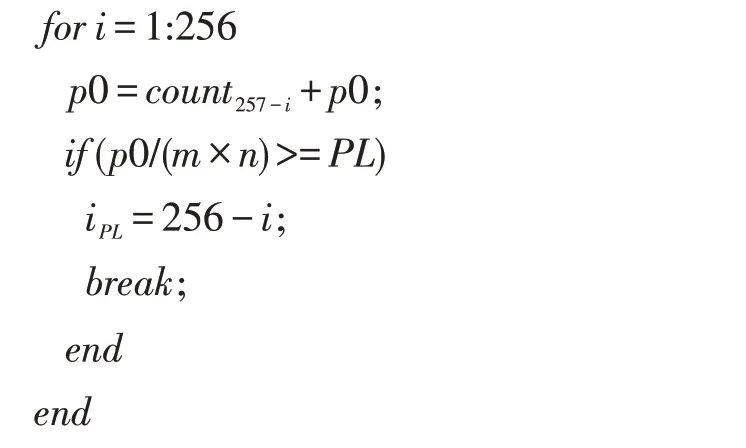
已知PL=0.3,p0 为计数,当鸟占面积太大时直方图像素值iPL应该偏右(即靠近像数值最大的地方)如图4;当鸟占面积太小时直方图像素值iPL应该偏左(即靠近像数值最小的地方)如图5。
偏移量M 可能偏左也可能偏右,且往左偏需要增大阈值,往右偏需要减小阈值,因此令:

通过选取a 的不同的值进行试验比较得到a=3 比较合适。利用阈值对图像进行切割生成新的训练数据集,用于网络的第二次训练。

图4

图5
2.4 本文整体架构
本文的主要目的是使用FCN 对只有图像级别标签的数据集进行感兴趣区域提取,并来提高细粒度分类的真确率,整个结构的实现如图6 所示。

图6 本文整体架构
使用上述结构和CUB200-2011 数据集在第二次训练时正确率达到88%,使用裁剪的CUB200-2011 数据集不做数据提升(只将图片进行90 度旋转,不做平移、缩放等)作为测试集正确率达到90%。使用原数据集(未经裁剪CUB200-2011 数据集)测试正确率为70%,使用裁剪数据集(经FCN 裁剪的CUB200-2011数据集)经过旋转测试正确率为83%左右,对比其他方法有一定优势如表1 所示。

表1
3 结语
本文是利用反卷积与FCN 的特性并在VGG16 的基础上进行图像感兴趣区域的提取,再将提取的图像生成新的训练集对VGG16 进行再次训练来提高网络的分类的正确率。本文对图像提取的方法存在一定的缺陷:一是本文的提取方法只适合只有一个分类对象,当出现多个分类对象时,本文方法也只会标注成一个框;二是对感兴趣区域的提取不够完整,但是足够用来提高分类的正确率。希望在以后的工作中能改善这两点,并进一步提高正确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
红领巾·萌芽(2019年8期)2019-08-27
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
科技资讯(2017年7期)2017-05-06
