
基于安全策略的网络异常检测系统
2019-03-14 07:17陈敬涵
现代计算机 2019年4期
陈敬涵
(四川大学计算机学院,成都610065)
0 引言
1987年Denning[1]首次提出入侵检测的概念,在入侵检测中根据检测思路的不同,入侵检测可以分为误用检测和异常检测两类。误用检测假设入侵活动能够被按某种方式精确编码,通过分析攻击者的网络行为数据,建立起攻击模型库,在实际的网络环境中通过匹配攻击者的网络行为与攻击模型库来检测入侵者。由于其必须针对每一个特定攻击进行分析建模,已知的入侵模式必须手工编码到系统中,且系统需要不断地升级维护,导致其工作量大,人为参与度高,在应对不断更新的攻击过程中受到了极大的限制。针对误用检测的问题,异常检测从正常的网络行为入手进行分析,建立网络用户的正常行为模型,在检测过程中通过分析网络行为偏离正常行为的程度来判断异常。异常检测不依赖于具体行为是否出现,并且不需要系统及其安全性缺陷的专门知识,相较于误用检测,异常检测在应对未知攻击上具有更好的检测效果与更好适应性,但因为用户行为是经常改变的,对系统中的所有用户行为进行全面描述是不可能做到的,所以一定程度上有更高的误报率,并且在用户数量多、工作方式易变的环境中,配置和管理的复杂性较高。
异常检测方法可以分为静态检测方法和动态检测方法两类[2-4]。静态的检测方法基于设定好的阈值,监控当前网络的观测参数,如果参数值超出阈值,就认为当前监控的网络发生异常。动态方法在进行异常检测时,不仅要监控当前网络流量的情况,还要参考相邻时间内网络流量观测值的变化。动态检测方法主要有广义似然比(GLR)检测方法[5]、基于指数平滑技术的检测方法[6]和残差比异常检测方法[7]等。
1 Spark分布式计算框架
1.1 Spark框架概述
Spark是使用Scala开发的分布计算框架,由于分布式计算过程中会涉及大量的数据集重用。例如,在数据挖掘与机器学习的算法中就会涉及大量的数据集重用。对于此类问题,设计者提出了弹性分布式数据集(Resilient Distributed Dataset,RDD),数据在整个并行计算过程中以RDD的形式缓存于内存中并支持缓存与复用,最大可能的降低了框架I/O,提高了数据处理速度。RDD是一种在分布集群节点上进行分区的只读对象集合,在集群的分布计算中多节点可共享RDD,其具有局部计算、容错与可扩展等特性,并支持基于数据集的应用。基于RDD开发者在Spark中提出了内存计算的概念,极大的降低了磁盘的交互读写操作。现阶段,RDD缓存粒度较粗,仅支持全部缓存。当内存不足时,Spark调用LRU(Least Recently Used)算法将要替换的RDD缓存到磁盘,并在内存中缓存新的RDD。Spark的迭代分布式内存计算框架,在数据重用度高的应用场景中具有高效性,但由于RDD的不可修改性,在异步更新的应用场景如索引和爬虫中Spark有一定的局限性。为了提供不同场景下的Spark大数据处理,Spark除了提供MapReduce编程模型之外,还提供了一组工具集包括 SparkSQL、Spark Streaming、MLlib 和GraphX等子模块。
其中,SparkSQL是在Spark平台上处理结构化数据的工具。首先,SparkSQL针对多种数据源问题提供了统一的数据源访问接口,如JSON文件与Apache⁃Hive表等;其次SparkSQL兼容Hive,复用Hive的元数据,支持Hive的UDF、查询与数据等;最后SparkSQL提供了一套简化版的SQL查询语句提升了数据分析交互性与数据分析的效率。Spark Streaming是Spark平台上的流式计算工具。首先,Spark Streaming基于Spark API实现,其极大的简化了流式编程的复杂度,在进行流式编程时可以像普通的批处理程序一样进行编写。其次,Spark Streaming将流式计算、批处理、交互式查询进行了良好的结合,并提供了良好的自动化容错处理。MLlib是基于Spark编写的机器学习算法库,该机器学习库中包含了常用的聚类、分类、回归、协同过滤与统计分析等算法。MLlib性能是Hadoop的100倍[6-7]。自Spark0.8版本开始MLlib成为了Spark的一个子模块。随着Spark的不断开发Mllib也在进一步丰富与完善。GraphX是Spark平台上的图运算工具。用户可以通过GraphX在Spark平台上进行集合运算与图运算。GraphX相较于GraphLab和Giraph等图计算框架具有更优的计算性能。
1.2 Spark框架架构分析
Spark集群主要包含:驱动程序(Driver)与工作节点(Worker)。驱动程序是应用程序的起点,其负责协调集群间工作节点的并行化计算。工作节点主要负责并行化的计算由驱动程序所分配子任务,并将最终的计算结果返回给驱动程序。如图1所示是Spark运行时状态:

图1 Spark运行时状态
如上图1所示,当一个任务被提交给Driver时,Driver负责协调启动多个Worker,Worker将会从本地文件系统或HDFS中读取数据在集群中进行分区并创建RDD,然后将RDD缓存在内存中。在程序运行过程中Driver将操执行程序传递给Worker,协调Worker进行数据处理,当Worker的相应子任务处理结束后,Worker将最后的处理结果返回给Driver完成整个运行过程。
2 异常行为分析系统设计
本文提出的异常行为分析系统支持基于安全规则定义的知识库的导入,支持基于快速多模式匹配技术的大流量网络环境下的网络行为特征匹配,实现网络异常行为监测。异常行为检测的总体流程如下图2所示,主要包括数据源、数据缓存与分发、异常行为检测、结果存储与展示四个部分。

图2 异常检测架构图
3 异常行为分析系统实现
异常行为检测的数据源为TCP/UDP会话流,将TCP/UDP会话流统称为Session数据,Session数据来源于Session流量还原程序,由于流量规模较大,系统对实时性要求较高,因此本项目基于Kafka实现数据缓存与分发。为了便于将数据对象作为字节流在不同组件间传输,Session对象采用AVRO序列化方式进行处理,Kafka接收端解析AVRO字节流,并将数据传送给Spark Streaming进行处理。具体实现方式为:Session还原程序作为Kafka系统的producer,通过push模式将消息发布到broker,异常行为检测模块作为Kafka系统的 consumer,通过 pull模式从 broker获取 Session数据。
本文所采用的多数据流聚合的方式如下:stream⁃ing程序在每个时间间隔内读取该时间段内的session集合,将session按照上面提到的3个维度进行聚合操作,针对每个聚合操作,提取出对应的统计特征,然后将统计特征与规则列表逐个进行匹配,一旦匹配成功,则认为该会话里违反了规则,根据规则的action进行异常处理,包括 info、warn、error。
异常行为检测系统主要基于安全策略实现异常行为的检测。具体地,一条安全策略规则如下所示:

其中,target字段的值只能为“srcip”、“srcip_dstip”、“srcip_dstip_dstport”,filed中的name也是有限制的,基本上充分考虑了所有的统计字段,如果规则不合法,将不会起作用。
4 实验
4.1 安全策略配置
本文主要制定了端口扫描、主机扫描、SYN Flood、各类应用暴力破解共四类异常检测规则,相关代码为:
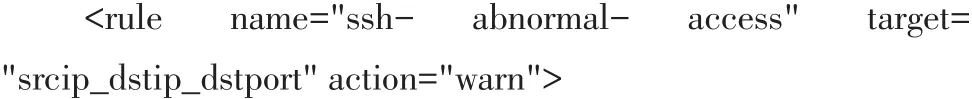

4.2 各类攻击检测结果
本文通过将安全策略导入攻击检测模块,利用相关工具分别模拟了端口扫描、主机探测、SYN Flood以及异常应用访问,进行了仿真实验。实验结果表明,本文提出的基于快速多模式匹配技术的大流量网络环境下的网络异常行为监测方法可有效检测上述异常。
通过基于源IP及目的IP的数据流聚合方式,有效检测出端口扫描,检测结果图3所示。

图3 端口扫描检测结果
通过基于源IP及目的IP的数据流聚合,有效进行的主机探测攻击检测,检测结果中包含network-probe的异常告警,以及针对44网段存活主机的端口扫描告警,检测结果如图4所示。
通过基于源IP及目的IP的数据流聚合方式,有效检测出SYN Flood攻击,检测结果中包含针对目标主机的syn-flood及port-scan类型告警,因为此次攻击同时满足两类攻击的规则,检测结果如图5所示。
通过基于源IP、目的IP及目的端口的数据流聚合方式,有效检测出异常应用攻击检测,检测结果中包含针对目标主机的ssh-abnormal-acces、mysql-abnormalaccess、smtp-abnormal-access类型告警,检测结果如图6所示。
5 结语
针对网络中绕过安全设备安全策略的异常网络行为检测问题,本文对异常行为分析与检测进行了深入研究,提出一种基于安全策略的网络异常检测方法。通过该方法可实现对网络中不符合安全策略的网络数据流的实时检测,提高网络安全实时监测和态势感知能力。

图4 主机探测检测结果

图5 SYN Flood检测结果
猜你喜欢
电脑爱好者(2021年1期)2021-01-13
中国信息化(2020年7期)2020-08-13
电脑报(2019年10期)2019-09-10
新教育时代·教师版(2019年16期)2019-06-17
电脑爱好者(2018年14期)2018-08-05
网络空间安全(2017年10期)2017-12-21
现代商贸工业(2016年28期)2016-12-27
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
