
一种基于信息熵的关键词提取算法∗
2019-03-26 08:43孙伟晋
计算机与数字工程 2019年3期
吴 华 罗 顺 孙伟晋
(上海通用识别技术研究所 上海 201112)
1 引言
随着互联网信息的爆炸式增长,如何提高信息的访问效率、降低信息的阅读成本,已成为信息处理的关键技术之一。而关键词提取就是其中一种有效的应对手段,关键词作为信息的主要承载单元,其提取效果和性能直接决定了信息检索、自然语言处理、本体构建等技术和应用的效果[1]。
当前广泛使用的关键词提取算法大多是基于字典、语言规则、统计的经典算法[2~4]。这些经典算法在进行关键词提取之前大多需要先进行分词[5],这就意味无法对缺乏语法等背景知识的小语种语料进行分析处理,此外,经典算法对于特定领域的新概念、新术语、新话题的处理能力也较差。
本文在基于信息熵的方法,以词汇内部各字符的互信息作为词汇内部关联性特征,以词汇邻接字符的分布作为词汇外部独立性特征,以及词汇的频次、长度等统计特征,构建了一种无监督的关键词提取算法。该算法克服了经典算法对字典、分词等先验知识的依赖,同时,能较好地识别出未登录词和支持多语种混合的语料环境。
2 信息熵
根据Shannon的信息理论,熵(entropy)用来度量随机变量的不确定性[6]。一个离散随机变量X,其值域记为Sx,对Sx中状态值x∈Sx,其概率分布函数为则变量X的熵为

若一个离散随机变量Y,其值域记为Sy,对Sy中状态值 y∈Sy,其概率分布函数为与随机变量X的联合概率分布函数为则变量X、Y的联合熵为

当变量Y已知,则变量X的条件熵,即变量X中剩余的不确定性为
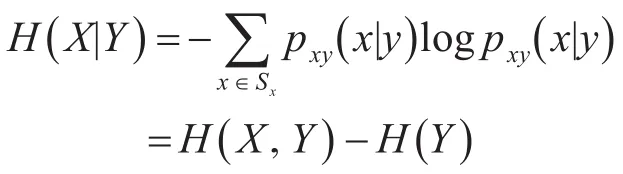
变量X和变量Y的互信息,即两者的统计依存关系为[7~8]

考虑到

即变量X和变量Y的互信息可由熵计算得到

3 基于信息熵的关键词提取
3.1 词边界识别
设样本字符串S=t1t2…tn,则称t1为t2的左邻接字符,t2为t1的右邻接字符。根据信息熵的方法,如果一个字符串是一个词汇,那么其左右邻接字符应具有较大的不确定性,即该字符串独立于左右邻接字符,而邻接字符的分布是较为分散的。
举例来说,“吃肯德基套餐”、“去肯德基门店”、“抢肯德基优惠券”、“上肯德基官网”等字符串中,子字符串“德基”的左邻接字符只有唯一确定的一个“肯”,而“肯德基”的左邻接字符却有“吃”、“去”、“抢”、“上”四种,不确定性较大,同样的,子字符串“肯德”的右邻接字符只有唯一确定的一个“基”,而“肯德基”的右邻接字符却有“套”、“门”、“优”、“官”四种,不确定性较大。
记字符串S左邻接字符分布集为αl,右邻接字符分布集为αr,计算字符串S左右邻接熵模型如下:
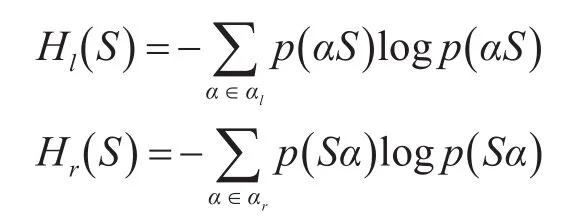


其中 f( )αiS 表示字符串在样本中出现的次数。
对于给定阈值h,若 Hl()S<h即认为字符t1为字符串S的左边界,若 Hr()S<h即认为字符tn为字符串S的右边界。
3.2 词汇完整性识别
在3.1节中,我们获得了字符串S的左右边界,在此基础上,根据信息熵的方法,如果一个字符串是一个完整词汇,那么其内部各字符间的相互关联应较为紧密,即该字符串内部各子字符串具有较高的互信息值。
举例来说,“中国工商银行”这一字符串在词边界识别的过程中,可能被识别成“中国”、“工商”、“银行”三个词汇,而事实上,当“中国”、“工商”、“银行”三个词汇连续出现时,我们更倾向将其作为一个完整词汇。
互信息有多种计算表达式,同样通过样本统计数据给出互信息计算表达式:

3.3 关键词提取
根据3.1节和3.2节、对于给定邻接熵阈值h、互信息阈值 m,若且 Hr()S <h,且MI()S>m,则将字符串S=t1t2…tn作为独立词汇召回。
选取词频、词长、词位置、词跨度四种统计特征[5],并通过权重配置实现归一化。
词频因子计算模型如下:

词长因子计算模型如下:
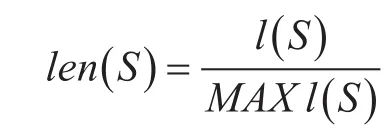
词位置因子计算模型如下:
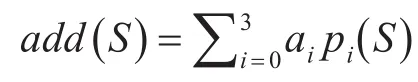
其中 p=( )p0,p1,p2,p3表示字符串S在语料中标题、首段、段首句、其他位置出现的频率,a=( )a0,a1,a2,a3表示在每一个位置上的权重。该词位置因子计算模型认为,词汇在不同的位置上对反映语料主题的重要性是不一致的,权重以标题、首段、段首句、其他位置依次递减,即a0≥a1≥a2≥a3。同样的,add()S也向1收敛。
词跨度因子计算模型如下:
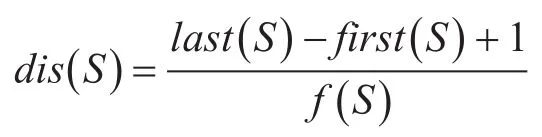
为词频、词长、词位置、词跨度四种统计特征配置权重w=( )w0,w1,w2,w3如下:

我们即得到字符串S作为语料主题的影响因子。
4 算法描述
step1:从当前位置pos=0开始读入预定长度的字符串(如2汉字长度);
step2:计算当前字符串的左右邻接熵;
step3:若左或右邻接熵小于指定阈值h,则字符串向左或右扩展一个字符长度(遇到标点或文章边界则停止),回到step2;
step4:若左和右邻接熵均大于指定阈值h,则计算当前字符串中个字符的互信息;
step5:若互信息大于指定阈值m,则将当前字符串作为独立完整词汇召回;
step6:当前位置pos右移一个字符长度,若语料剩余长度大于拟读入字符串的预定长度,则回到step1;
step7:计算所有被召回的词汇权重,并按权重排序,取出权重较大的词汇作为当前语料的关键词。
5 算例
以《环球时报》2015年3月30日报道的《“一带一路”点燃世界热情》为例。
配置邻接熵阈值h=1、互信息阈值m=0.05,配置词位置权重 a=(0.4,0.3,0.2,0.1)、配置词频、词长、词位置、词跨度权重 w=(0.4,0.2,0.2,0.2),利用第4节中算法,最终提取出的前十个关键词为“一带一路”、“丝绸之路”、“海上丝绸之路”、“中国”、“沿线国家”、“亚投行”、“经济”、“习近平”、“路线图”、“俄罗斯”。
实验结果表明,算法能识别“一带一路”、“亚投行”等新词和术语,能识别“海上丝绸之路”、“沿线国家”等复合词,能将“丝绸之路”、“海上丝绸之路”等具有重复字符的词汇作为两个独立词汇召回,关键词提取效果令人满意。
6 结语
本文提出的基于信息熵的关键词提取算法,是一种无监督的提取算法。由于该方法的处理对象为二进制字符,从而具有以下三方面特点,一是不需要字典等先验知识;二是不需要分词运算而直接进行关键词提取;三是能处理多语种混合的语料。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
数字技术与应用(2017年3期)2017-05-17
计算机应用(2016年10期)2017-05-12
中国水运(2016年11期)2017-01-04
科教导刊·电子版(2016年30期)2016-12-26
电脑知识与技术(2016年27期)2016-12-15
中国新通信(2016年17期)2016-11-17
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年1期)2016-03-22
