
基于随机森林的语音情感特征选择与分类∗
2019-03-26 08:43刘立龙
计算机与数字工程 2019年3期
邢 尹 刘立龙
(桂林理工大学测绘地理信息学院 桂林 541004)
1 引言
随着电子技术的广泛发展,各种电子终端在人们生活中扮演着日益重要的角色,语音技术正逐步成为人机接口的关键技术。近年来,如何有效识别语音中的情感状态已经成为人们关注的热点。对操作者的情感分析,可使得人机交互过程更加生动、交互界面更加友好[1]。
目前,语音情感特征处理手段主要有主成分分析(Principal Component Analysis,PCA)特征降维法[2~4]和 Fisher准则特征选择法[5~7]。主成分分析法通过对多元统计观测数据的协方差结构进行分析,以期求出能简约地表达这些数据依赖关系的主分量,在去除冗余特征方面有着特有的性能[8];Fisher准则依据特征之间的类内、类间距离剔除弱相关的特征。但由于这两种特征处理方法对于语音情感识别率的提升能力有限,本文提出了一种融合Fisher准则和随机森林算法中平均下降Gini指数的特征选择法,以语音情感为研究对象,随机森林为分类模型,深入探讨影响语音情感识别的重要特征。
2 语音情感的特征提取
语音情感特征是情感变化的内在体现,直接关系着最终情感的识别。经过研究者对心理学以及语音语言学的大量研究,目前语音情感特征主要关注在韵律特征和音质特征[9~11]。本文选取短时能量、基音频率、共振峰、梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)四类特征及其它的衍生参数共构成140维语音情感特征[12]。各维的特征对应如下:
1~4:短时能量的最大值、最小值、均值和方差;
5~7:短时能量的抖动、线性回归系数和线性回归系数的均方误差;
8:0Hz~250Hz频段能量占总能量的百分比;
9~14:基音频率的最大值、最小值、均值、方差和一阶抖动、二阶抖动;
15~18:浊音帧差分基音的最大值、最小值、均值和方差;
19~33:第一、二、三共振峰频率的最大值、最小值、均值、方差和一阶抖动;
34~36:第二共振峰频率比率的最大值、最小值和均值;
37~140:0~12阶MFCC及其一阶差分的最大值、最小值、均值和方差。
3 基于随机森林的特征选择
3.1 随机森林
随机森林是一种由多棵分类回归树(Classification And Regression Tree,CART)构成的机器学习算法[13]。首先,采用Bootstrap抽样技术从原始样本中抽取N个训练集;其次,为每个训练集构造CART决策树,产生由N棵CART决策树组成的森林;再次,从全部M个特征变量中随机抽取m个(m<<M),依据Gini指数最小原则选出最好划分训练集的特征,进行内部节点分支;最后,集合N棵决策树的输出进行投票,以得票最多的类作为随机森林的决策结果。
3.2 特征选择
3.2.1 Fisher准则
Fisher准则从均值和方差角度来对特征进行评价。对d个维度,Fisher判别准则可以用式(1)来表示:


式中:m为类别总数。
3.2.2 Gini指数
随机森林算法中,在进行节点分割时,采用Gini指数衡量特征分割的效果[14]。假设样本D中有K个类,那么它的Gini指数为

式中:Ck是D中属于第k类的样本子集,K是类的个数。如果在一次分割之后,样本集合D被分成m部分:那么这次分割的Gini指数为

Gini指数的大小与分割效果呈反比关系。通过计算平均下降Gini指数值可以对所有特征的重要性进行排名,其值越大表示该特征越重要。
3.2.3 融合Fisher准则和平均下降Gini指数的特征选择
设依据Fisher准则和平均下降Gini指数分别选择了FT和GT个特征,其中T为所选择特征数。那么同时满足Fisher准则和平均下降Gini指数准则的新特征记为R'。依据平均下降Gini指数中重要特征的排列顺序,对R'重新排列得到最终的新特征R,计算公式如下:

式中:DescendG表示以G特征顺序进行排列。融合的特征选择法给出了平均下降Gini指数基础上特征重要性排名的深度优化,并依据最终分类识别率确定最佳的特征维度。
4 实验结果与分析
本文的实验数据来自于柏林情感语音库[15]。柏林情感语音库是柏林工业大学通过10名(5男5女)非专业演员的演绎所得到,共录制了800条语音,包括生气、开心、平静、伤心、害怕、厌恶以及无聊7种情感。经过20名志愿者辨认试听,保留了535条语音。本文选取前5种情感,剔除其中无法进行特征提取的语音,得到最终的实验样本,具体为:生气126条,开心68条,平静78条,伤心62条以及害怕66条,各种情感按1∶1随机划分为训练样本和测试样本。
采用Fisher准则对原始140维特征数据进行分析,如图1(上)所示。图1(上)横坐标表示特征编号,纵坐标表示 f(d)值,其中 f(d)值越大,表示特征的区分度越好。对所有 f(d)值降序排列,取对应的前25个特征编号如下:
F25={17,36,123,10,119,95,103,127,57,91,111,20,31,99,108,124,87,125,29,73,13,23,25,26,32}
采用随机森林算法进行语音情感分类,其中需要控制的参数主要有树数目Ntree以及每个分裂点特征数Mtry。实验设定Mtry= d,Ntree=500可以达到较好的效果,得到的平均下降Gini指数对特征重要度评价如图1(下)所示。图1(下)中横坐标表示特征编号,纵坐标表示平均下降Gini指数值,值越大表示特征在分类中所起的作用越大。对平均下降Gini指数值降序排列,取对应的前25个特征编号如下:
G25={36,17,35,34,91,95,123,119,111,127,20,10,87,103,99,15,69,115,19,108,135,57,25,79,22}
按照式(5),融合的特征选择法所确定的特征编号为
R=DescendG(F25∩G25)={36,17,91,95,123,119,111,127,20,10,87,103,99,108,57,25}

图1 Fisher准则和平均下降Gini指数特征分析结果

图2 不同特征维度的语音情感平均识别率
对于特征集合R,我们认为排名越靠前的特征对最终的语音情感分类贡献越大。R中不同特征数所对应的平均识别率如图2所示。从图2可以看出,起始阶段,平均识别率随着特征维度的增加而增加,之后平均识别率波动。在第10维时,平均识别率达到了最大,为96.5%,说明采用融合的特征选择法将原始特征降至10维是最佳的维度,具体为:第二共振峰频率比率均值(36)、浊音帧差分基音均值(17)、0阶MFCC一阶差分均值(91)、1阶MFCC一阶差分均值(95)、8阶MFCC一阶差分均值(123)、7阶MFCC一阶差分均值(119)、5阶MFCC一阶差分均值(111)、9阶MFCC一阶差分均值(127)、第一共振峰频率的最小值(20)以及基音频率的最小值(10)。为了说明融合的特征选择法优越性,分别选取Fisher准则和平均下降Gini指数特征选择下的最佳10维特征,基于随机森林算法,识别结果见表1~3。

表1 Fisher准则下5种情感识别结果

表2 平均下降Gini指数下5种情感识别结果
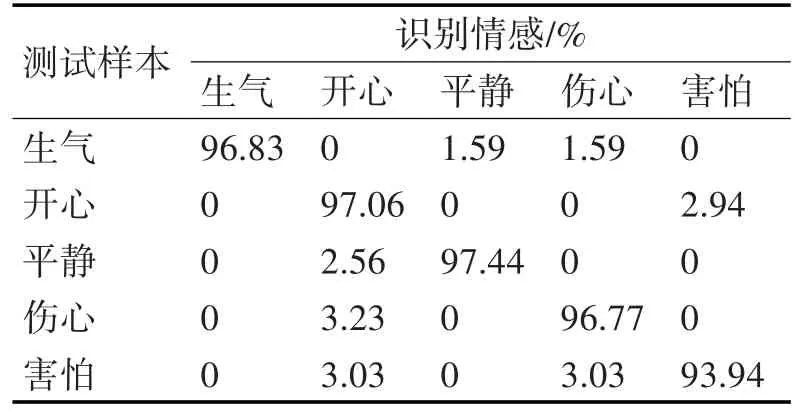
表3 融合特征选择法下5种情感识别结果
从表1中可以看出开心与平静、害怕与开心易混淆,表2中开心与平静易混淆,而表3中采用融合特征选择法,改善了前两种特征选择法下情感识别易混淆情况。综合表1~3,可以发现采用融合特性选择法对5种情感的识别率均高于或等于另外两种特征选择法的识别率,尤其是,融合特性选择法下对开心的识别率达到了97.06%,各提高了另外两种特征选择法的2.94%识别率;对伤心的识别率达到了96.77%,分别提高了另外两种特征选择法的6.54%和3.22%识别率。三种特征选择法下平均识别率分别为95.00%、95.50%以及96.5%,说明采用融合的特性选择法进行特征选择是有效的,并取得了较好的识别效果。
5 结语
本文提取了柏林情感语音库中的生气、开心、平静、伤心和害怕的情感特征,并采用融合Fisher准则和平均下降Gini指数特征选择法选择语音情感特征。基于随机森林分类算法,在与Fisher准则和Gini平均下降指数特征选择法的比较中,证明了融合特征选择法在特征选择上具备良好的性能,有效地提升了语音情感识别率。考虑到优质情感特征贡献了大部分的识别率,下一步工作将研究从语音信号中提取新的更加优质的情感特征。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
扬州大学学报(自然科学版)(2021年6期)2021-02-14
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
计算机应用(2016年10期)2017-05-12
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年24期)2016-11-14
