
基于粗糙集和改进D-S证据理论的故障诊断方法∗
2019-03-26 08:43侯瑞春丁香乾
计算机与数字工程 2019年3期
丁 晗 侯瑞春 丁香乾
(中国海洋大学 青岛 266100)
1 引言
随着现代工业技术的快速发展,大型设备呈现结构复杂、维修成本高、自动化等发展趋势[1]。此类设备一旦发生故障,会严重影响企业的经济效益,并会在一定程度上威胁着人们的人身安全。据统计,我国每年投入约800多亿元用于设备维修,美国投入的资金高达2500亿元[2],因此对大型设备故障诊断的研究具有重要的意义。
目前故障诊断技术在国外的发展已经比较成熟,具备较完善的监测系统,并且诊断能力较强[3];国内对设备监测和故障诊断技术的研究较晚,但是发展速度比较快,尤其在大型设备领域,已经取得了较好的研究成果。设备故障诊断方法主要有小波变换法、专家系统法、支持向量机法、人工神经网络法等。曹晓莉等[4]提出了一种SOFM-SVM算法对设备进行诊断,在一定程度上避免了分类的盲目性。Robert X.Gao[5]等利用小波变换与神经网络结合的方法对轴承进行状态监测与诊断,将小波变换提取的特征向量输入到神经网络中进行训练实现轴承的状态自评估。但上述方法存在一定程度的局限性,诸如,小波变换取决于Fourier变换,不能有效地匹配信号;专家系统方法依赖于专家的经验,主观性较强;支持向量机中模型参数与核函数的选择会影响结果的准确性;人工神经网络需要训练大量的样本等[6]。为此,有关学者将数据融合技术引入到故障诊断系统中,它能够综合利用多传感器采集的数据提高状态监测的准确率,已经在设备故障诊断、状态监测、目标跟踪等领域得到了广泛的应用[7]。郭利等[8]将模糊数据融合算法应用于轴承状态监测与诊断方面,综合利用多传感器信息,提高了设备监测与诊断的准确率。Dong Yang等[9]使用数据融合的方法对风力发电机进行诊断,消除了白噪声和短期干扰噪声的影响。
为了解决不同领域数据的融合问题,许多学者提出了不同的数据融合方法,如Bayes理论、粗糙集理论、模糊集理论、D-S证据理论、神经网络等。虽然这些方法取得了一定的应用效果,但是在大型生产系统中,使用单一的数据融合方法往往不能对复杂的数据做出正确的融合[10]。因此,本文结合D-S证据理论在处理不确定性数据,以及粗糙集理论在属性约简方面的优势,提出了一种粗糙集和改进D-S证据理论相结合的数据融合故障诊断方法,解决大型设备传感器监测数据存在的冲突、模糊、不确定等问题,并通过对臭氧发生器进行故障诊断仿真实验,验证了该方法的有效性。
2 基于粗糙集和改进D-S证据理论的故障诊断方法
2.1 D-S证据理论基本概念
设变量X的所有互斥元素的集合为Θ,称Θ是X的识别框架。当集合Θ中元素个数为n时,集合 Θ 的 空 间 大 小 为2n。 对 于 ∀A⊂Θ ,若m:2Θ→[0,1],满足:

称m为Θ上的基本可信度分配函数(Basic Probability Assignment,BPA),m(A)为事件 A的基本可信度分配值。
设在同一识别框架Θ下,m1(Ai)和m2(Bj)是Θ上的基本可信度分配值,冲突因子则融合后的基本可信度分配值为

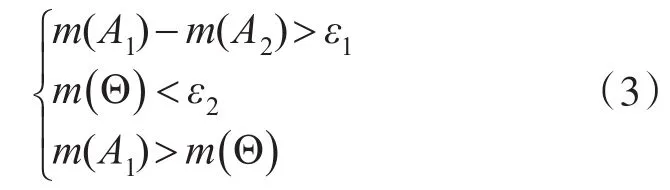
若满足式(3),则 A1为决策结果,其中 ε1,ε2是预先设定的门限值。
2.2 粗糙集理论基本概念
设 S=(U,A,V,f)是 一 个 决 策 表 ,其 中U={x1,x2,…, }xm是一个论域;A=C∪D,C为条件属性,D为决策属性,且是属性a的值域;f:U×A→V为信息函数。设矩阵M是大小为 ||U × ||U 的区分矩阵,a(x)表示属性a在x上的值,Mij表示能把对象i,j区分的属性集合,则M表示为
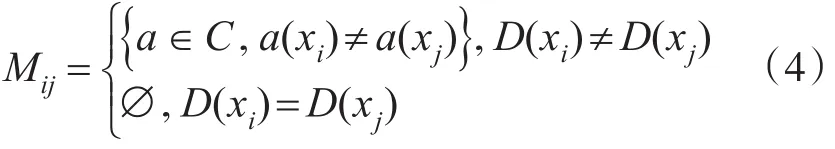
区分函数Δ=∏∑Mij,Δ的析取范式的合取式是对属性a的约简集合。
设 Xi,Yj为上的等价类,des(Xi),des(Yj)表 示 Xi,Yj对 于 集合 C 的特定 取值。决策规则为rij的规则强度为
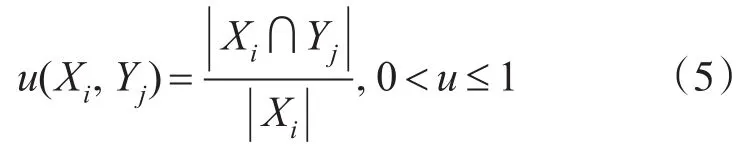
2.3 基于粗糙集和D-S证据理论的故障诊断方法
D-S证据理论最初由Dempster提出,Shafer在此基础上对其研究发展形成的一种不确定性推理方法[11~12],已经在故障诊断领域取得了一定的成果。但是D-S证据理论仍然存在基本可信度分配主观、证据冲突处理困难等问题[13]。针对此问题,国内外许多学者进行了研究,目前解决方案有两种,一种是通过重新确立基本概率分配函数对证据源进行修正,另一种是针对合成规则的修改[14~19]。本文针对D-S存在的弊端,结合粗糙集理论使用决策表计算属性的决策规则强度和扩充规则强度确定基本可信度分配值,并使用属性的决策重要度和证据的冲突度对证据理论的合成规则进行修改。
1)计算决策规则强度

若 R∈C ,x,y∈U ,存在 f(x,R)→f(x,D),f(y,R)→f(y,D),如果 f(x,R)=f(y,R),f(x,D)≠f(y,D),决 策 扩 充 规 则 为 f( )x,R →{f(x,D),f(y,D)}。决策扩充规则强度为
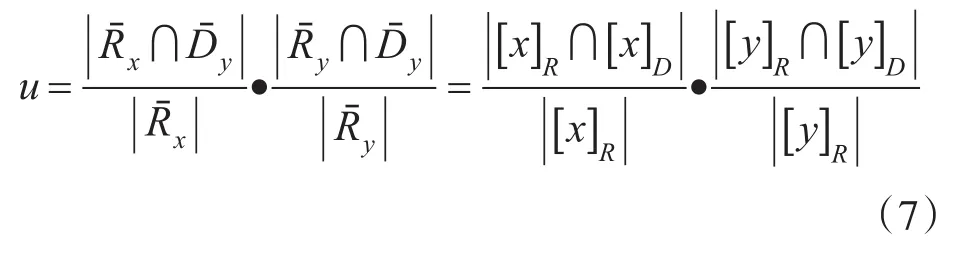
2)确定基本可信度分配值
设A为辨别框架Θ上的一个命题,在决策表S上 , E∈C,Q=U D={y1,y2,…,yn},Bi=计算Qi的决策规则强度ui,则命题A的基本可信度分配值为
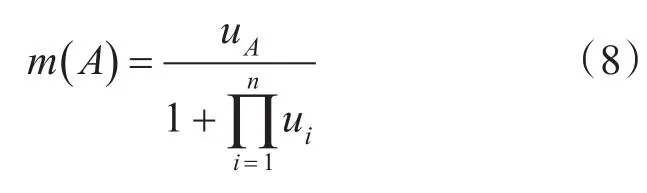
3)计算属性的决策重要度
在决策表S上,E∈C,则属性E的决策重要度为

其中γ表示属性依赖度。对sig进行归一化处理,用此来衡量属性的相对权重:

4)修改合成规则
在同一辨识框架 Θ 上,m1,m2,…,mn是基本可信度分配值,每个BPA对应的焦元分别为αi,i=1,2,…,n ,并 且 满 足结合属性的权重和冲突因子对合成规则进行修改,合成公式为

其中w(ai)用来衡量证据的相对权重,K表示证据间的冲突程度,则e-K反映证据的可信度,若证据间发生冲突的可能性变高,即K值变大,那么证据的可信度就会降低。因此,当证据间发生冲突时,融合结果是由证据的可信度和权重来确定的,表明即使当证据间发生冲突时,也能为融合结果提供有用的信息。
2.4 基于粗糙集和改进D-S证据理论的故障诊断模型
首先将臭氧发生器中传感器采集的数据使用离散化区间划分的方法进行处理得到决策表,并利用粗糙集知识约简的方法对其进行冗余处理;然后根据约简后的决策表计算属性的决策规则强度和扩充决策规则强度来确定基本可信度分配值;同时计算属性的决策重要度,并进行归一化处理来衡量证据的相对权重,结合证据冲突因子对证据理论的合成规则进行修改;最后采用基于基本可信度分配的方法进行决策,得到臭氧发生器的故障类型。基于粗糙集和改进D-S证据理论的故障诊断模型如图1所示。

图1 基于粗糙集和改进D-S证据理论的故障诊断模型
具体步骤如下:
Step1:采集臭氧发生器发生故障时传感器数据建立故障信息表,根据臭氧发生器正常工作情况下各指标的正常范围对数据进行离散化处理,建立决策表;
Step2:利用粗糙集中区分矩阵的方法计算决策表中的条件属性的核属性,得到约简后的决策表REDi;
Step3:在决策表REDi中根据式(6)、(7)计算条件属性的决策规则强度和决策扩充规则强度ui;
Step4:根据属性的决策规则强度和决策扩充规则强度使用式(8)确定属性的基本可信度分配值;
Step5:根据式(9)计算条件属性的决策重要度sig,并根据式(10)进行归一化处理得到条件属性的相对权重wi;
Step6:使用基于属性决策重要度和证据可信度的方法对合成规则进行修改,根据式(11)对证据进行组合重新确定属性的基本可信度分配值;
Step7:采用基于基本信度分配值的方法进行决策,门限值ε1越大,ε2越小表示诊断的准确率越高,本文选取 ε1=0.4,ε2=0.2 ;
Step8:根据决策结果判断故障的类型。
3 仿真实验结果
3.1 数据采集
为了验证该方法的有效性,本文使用青岛国林实业有限责任公司的50kg臭氧发生器进行故障诊断仿真实验。在实际生产过程中,臭氧发生器一旦发生故障,会直接降低臭氧产量和浓度。本文针对臭氧浓度低于预设值时对臭氧发生器进行故障分类:空压机故障、干燥器故障、冷却系统故障。涉及到的故障征兆包括出气流量、出气温度、工作压力、出水温度、功率。
选取20组臭氧发生器运行过程中传感器采集的数据进行仿真实验并建立故障信息表,如表1所示。其中3种故障类型的数据各6组,剩余2组为正常数据。设a为出气流量属性,b为出气温度属性,c为工作压力属性,d为出水温度属性,e为功率属性。划分条件属性集合C={a,b,c,d,e}。设D1为空压机故障,D2为干燥器故障,D3为冷却系统故障,D4为正常状态,即决策属性集合D={D1,D2,D3,D4}。随机选取4组故障数据作为测试样本数据对本文提出的方法进行验证,T={T1,T2,T3,T4}。

表1 臭氧发生器的故障信息表
3.2 臭氧发生器故障诊断仿真
1)连续数据离散化处理并建立决策表
在正常工作情况下50kg臭氧发生器的出气流量为40nm3/h左右;出气温度为26℃±2℃;冷却水出水温度为28℃±2℃;工作压力为0.095Mpa,上下波动不超过5%;功率为实际功率值,维持在53kW左右。根据正常情况下各属性值的范围划分离散区间,如表2所示。
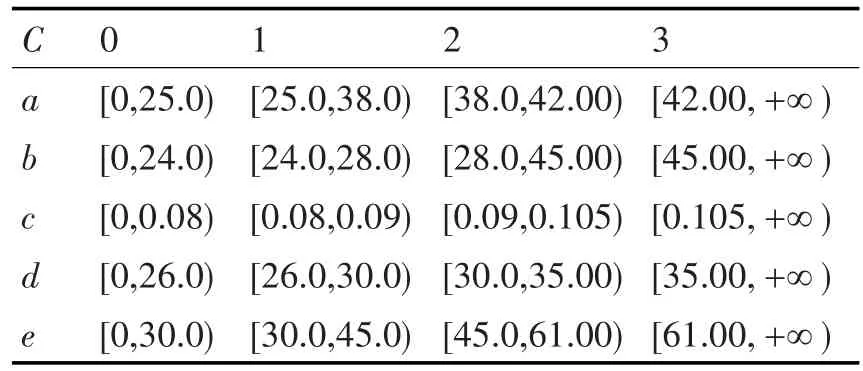
表2 离散化期间划分
根据离散化区间得到初始决策表,如表3所示。

表3 初始决策表
2)属性约简
观察表3,样本19和样本20经过离散化后的数值是一样的,对其进行值约简,然后计算决策表的区分矩阵。通过计算区分矩阵可以得出决策表的核属性为{b,d},区分矩阵核属性出现的集合中属性a,e出现的次数达到70次以上,得到相对约简集合为{a,b,d}和{b,d,e},说明该决策类别与{出气流量,出气温度,出水温度}或{出气温度,出水温度,功率}存在的关联较大,与其工作压力的关联较小。用RED1,RED2表示约简后的决策表,即RED1={a,b,d},RED2={b,d,e},如表4所示。
3)确定基本信度分配值
将决策属性Di作为辨识框架,计算不同决策属性在不同的证据下的基本信度分配值,以决策表RED1证据a为例。
属性a的等价集:U/(a,D)={(1,2,3,4),(5,6),(7,8,9,12),(10,11),(13,15,16),(14,17,18),(19)}。
取属性a的值为2,划分等价集为F={(7,8,9,12),(14,17,18),(19)}。
计算决策D2的规则强度:u2=(D2∩ F)/F=4/8。

表4 约简后的决策表
同理,D1,D3,D4的规则强度:u1=0,u3=3/8,u4=1/8。
由式(6)计算D2,D3,D4的扩充规则强度:u234=4/8×3/8×1/8=3/32。
根据式(7)计算基本可信度分配值:ma(D2)=u1/(1+u2⋅u3⋅u4)=0.4571。
同 理 ,ma(D1)=0,ma(D3)=0.3471,ma(D4)=0.1143,ma(D2,D3,D4)=0.08577。
根据以上方法,计算子决策表RED1,RED2的基本可信度分配值,如表5所示(以RED2为例)。
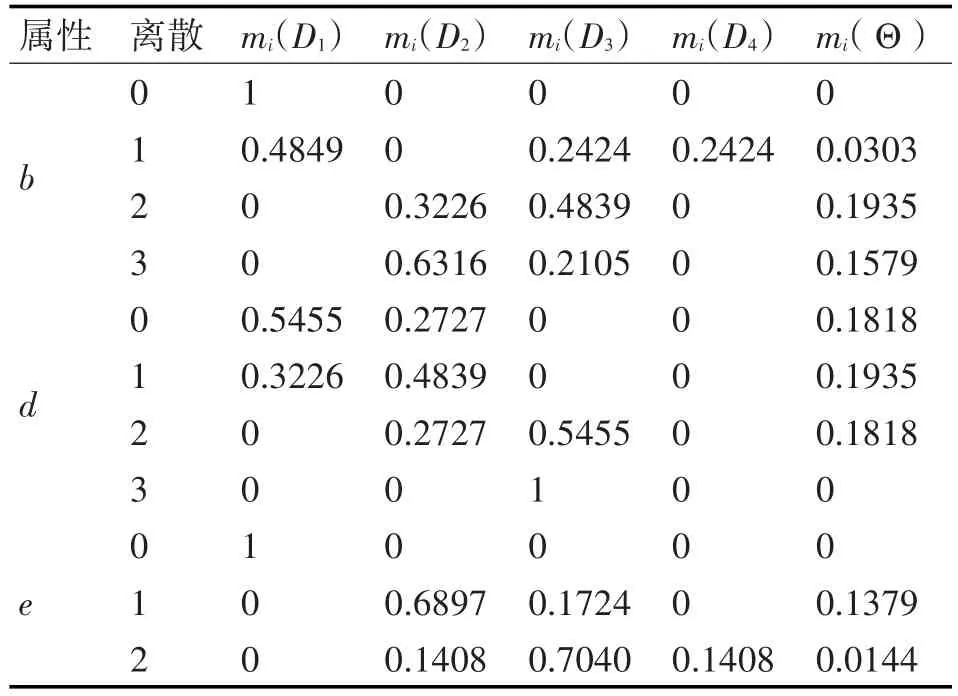
表5 基本可信度分配值
4)计算属性的决策重要度
根据属性的决策重要度计算式(9)计算每个条件属性作为证据时在子决策表中的决策重要度SGF(Ci),并根据式(10)得到归一化结果用来衡量每个证据的相对权重w(Ci),如表6所示。

表6 证据的决策重要度与权重
5)证据合成
对故障测试样本 T1,T2,T3,T4进行诊断,从表 5中获取 T1,T2,T3,T4中条件属性在子决策表 RED2中证据的基本可信度分配值。使用本文提出的基于相对权重的合成规则进行融合,根据融合的结果采用基于基本可信度分配的方法进行决策,判断故障的类型,如表7所示。

表7 融合结果
观察表7可以看出,本文方法都能够正确的对4组样本做出诊断。采用D-S证据理论的决策公式(3)进行决策,例如样本T1,证据 b⊕d 组合后,m(D1)-m(D3)> ε1=0.4,m(Θ)< ε2=0.2,且 m(D1)>m(Θ),则判断为D1;同理,对样本 T2,T3,T4进行证据组合后,根据ε1,ε2的值做出判断。从整体上得出,使用b⊕d两组证据能够正确地做出决策,使用b⊕d⊕e三组证据决策结果的不确定明显下降;并且经过组合后的基本可信度分配值相对于组合具有更好的峰值性,提高了故障诊断的准确性。
6)对比分析
为了验证本文提出方法的准确性,选取样本数目为10~80的故障样本集进行仿真实验,并与D-S方法、SVM方法(基于径向基核函数)进行对比,得到三种故障诊断方法的准确率如图2所示。
从图2可以得出,随着故障样本数量的增加,三种方法的准确率都存在下降趋势,但是本文提出方法的准确率高于D-S方法和SVM方法,并且本文方法的下降速度低于其它两种方法。当故障样本数量达到80时,D-S证据理论的诊断率为66.3%,SVM的诊断率为80%,本文方法的诊断率为91.3%,由此得出,使用本文提出的方法进行故障诊断具有较高的准确性。

图2 三种方法的准确率比较
4 结语
本文提出了一种粗糙集和改进D-S证据理论相结合的数据融合故障诊断方法,该方法采用粗糙集属性约简的方法对决策表进行约简,在一定程度上降低了计算复杂度;使用属性的决策规则强度来确定基本可信度分配值,有效地避免了人为因素的影响,使决策结果更具客观性;同时用属性决策重要度来衡量证据的相对权重,并结合证据的支持度对合成规则进行修改,提高了高权重属性的影响度。本文以臭氧发生器作为故障诊断的实验对象,并与D-S、SVM方法进行对比实验。仿真结果表明,本文提出方法的准确率高于其它两种方法,并且随着组合证据的增加,诊断结果的不确定性明显下降,对臭氧发生器故障诊断具有一定的实用价值。
猜你喜欢
聊城大学学报(自然科学版)(2022年5期)2022-10-29
汽车实用技术(2022年16期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
汽车实用技术(2022年9期)2022-05-20
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
计算机应用(2022年2期)2022-03-01
计算机与生活(2021年8期)2021-08-07
计算机应用(2021年4期)2021-04-20
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
海峡科技与产业(2016年11期)2016-12-26
