
基于Android API调用的恶意软件行为检测方法研究∗
2019-03-26 08:44卢晓荣刘钊远
计算机与数字工程 2019年3期
卢晓荣 刘钊远
(西安邮电大学计算机学院 西安 710061)
1 引言
现今手持移动设备的运算能力日益增强,搭载智能系统的移动设备成为日常活动不可或缺的一部分。因此,手持移动设备大多都存储了大量涉及用户隐私的重要信息,如通讯录、短信、邮件、文件等,这些信息涵盖了用户生活和工作的各个方面。
互联网技术的发展给人们带来了好处,而风险也随之而来。据统计,2016年全年,360互联网安全中心累计截获Android平台新增恶意程序样本1403.3万个,平均每天新增3.8万恶意程序样本。从手机用户感染恶意程序情况看,360互联网安全中心累计监测到Android用户感染恶意程序2.53亿,平均每天恶意程序感染量约为70万人次[1],因此,手机安全问题亟待解决。
在众多类型的恶意应用中,绝大部分都是在用户不知情的情况下,通过在后台访问相关的设备资源如网络、短信、联系人、位置信息等并对这些资源进行操作,达到其恶意的行为[2]。Android恶意代码分析研究目前主要有两种方法,即静态分析和动态检测。静态分析是指通过分析程序代码来判断程序行为[3]。Enck 等[4]提出 ded反编译器,从 An-droid安装镜像中反编译出应用程序的Java源代码。Matsumotos等[5]提出一种静态隐私数据泄露分析工具,通过分析应用程序源代码找到读取隐私数据的API,然后分析隐私数据的传输流,从而得到该应用程序泄露隐私数据的可能性。动态分析是指在严格控制的环境下执行应用程序,尽可能地触发软件的全部行为并记录,以检测应用程序是否包含恶意行为[6]。Enck等[7]提出TaintDroid采用污点跟踪技术,将用户敏感数据进行“着色”,监视敏感数据流,分析应用程序的敏感数据泄露。Dietz等[8]提出Quire用于监控混淆代理人攻击(confused deputy attack),Quire通过跟踪IPC调用链来防止应用程序间权限的提升,并且对IPC和RPC通信数据做轻量级的加密。Rubin Xu等[9]提出了Aurasium,通过重打包应用程序,修改smali文件添加监控代码,hook关键系统API并修改应用程序入口,从而达到监控应用程序的目的。
此方法缺点是要修改应用程序,必须对应用程序重新签名,破坏了应用程序的完整性。虽然静态分析能够快速有效地查找已知的恶意样本代码,但是无法良好应对精良的代码混淆和重打包技术。而动态的分析是通过实际运行软件,捕捉行为进行分析,它可以有效地应对代码混淆技术,更真实地反映软件意图。
即使目前有大量的代码混淆技术,但是行为在一定程度上会暴露恶意软件的意图。而一个恶意软件实现自己的意图,需要通过调用现有的系统API,否则就需要自己再编写大量的代码,不只增加了代码复杂度,同时还会增加被检测的几率[5]。所以Android API调用是值得分析的软件行为之一,因此,文中设计基于动态检测的思想,结合Android API和参数及参数取值多特征提取实现恶意软件检测,弥补静态分析的恶意软件检测的不足和解决以Android API为特征检测率低的问题。
2 Android恶意软件动态检测
Android恶意软件检测目前主要有两种方法,即静态分析和动态检测。关于Android应用软件的静态检测研究[10~12],大多数都是通过反汇编技术得到Android应用程序的源码然后对源码进行分析研究。由于静态分析方法自身的局限性,使得许多学者从事Android应用程序的动态研究,动态研究主要是通过Android应用程序运行过程的行为及系统调用等方面进行研究[13~16]。
文中将采用动态检测的方法,通过对恶意软件行为的分析,实现恶意软件的检测。流程图如图1所示。

图1 基于Android API调用的恶意软件检测流程图
首先在国内外软件分享网站及论坛,收集恶意和正常软件样本。其次在虚拟机中,运行收集到的正常和恶意软件样本,收集软件API调用日志。最后,日志文件作为分析对象,将恶意软件动态行为分析转换为对文本的分析。使用文本分析的方法,从收集到的日志文文中件中提取特征,进行数据预处理。文中将会提取两组特征进行研究:API和API+参数+参数取值。通过扩大对Android API调用监测范围,探究参数和参数取值对实验的影响。结合文档频率和信息增益进行特征选取。对两组特征分别设定不同的阈值,选择不同数量的特征进行实验。同时选用多种分类算法[17]进行实验,对比分类效果,选定一种比较好的分类算法实现恶意软件检测。
3 恶意软件动态检测方法实现
基于Android API和参数及参数取值多特征提取的恶意软件检测。本节内容主要包括数据采集和预处理,特征选择和分类。
3.1 数据采集
由于知名的官方应用网站会对所有发布的应用软件进行严格的审查与测试,所以要想通过官方应用市场获取大量的恶意软件样本,几乎是不可能的。因此只能在部分专门的网站取得,并且取得的样本数量是有限的。
文中收集的恶意软件样本,全部是从在线恶意软件仓库VirusShare中下载得到,均是较新的样本,且带有专业的测试报告,包括病毒、木马、蠕虫、广告软件、勒索软件等,而正常软件样本则全部来自于华为应用市场。为确保所获取到的样本不会影响到最终的实验结果,通过VirusTotal网站对所获取到的软件样本进行检测与分类,并最终选定250个恶意软件样本和250个正常软件样本作为本次实验的样本,其中训练样本包括:130个恶意软件样本和120个正常软件样本,测试样本包括:120个恶意软件样本和130个正常软件样本。
在动态恶意软件检测的过程当中,数据收集是十分困难的部分。静态的分析可以使用现有已经形成的数据集,而动态检测需要实际运行软件,相对于静态的分析耗时更多。
文中将使用APIMonitor进行自动分析,APIMonitor是一款监视和控制应用程序和服务的工具,该工具可以自动取得应用程序的Android API调用信息,所得到的结果默认放入config日志文件下。
按照上述方法,使用脚本遍历所有软件样本,提取本实验所需的特征,即软件运行中的API序列,将这些特征放入一个.arff文件中,作为分类器的输入。
3.2 数据预处理
实验中考虑的因素主要是API、参数和参数的取值,因此在进行数据预处理的时候,目标就是提取出日志中的API、参数和参数取值。
3.2.1 API字符串提取
在实验的过程中首先提取了API,再使用字符串处理提取参数和参数的取值。
我们可以将一个软件的Android API调用日志中相关的API调用格式抽象为File{API1(arguments1:value,arguments 2:value,……),API2(arguments3:value,arguments4:value,……),……}。
把每个文件中的API按种类统计出来形成数据集,然后再对数据集进行处理形成API字符串数据库,这里不考虑API在每个日志中出现的次数,只计算它是否出现在文件中,文中提取出的API特征库形式如下所示:
API={API1 3,API2 6,API3 8,API4 5,…},API名字后边的数字代表此API一共出现在多少个日志文件中。最后每个API为一行写入TXT文档中。API字符串提取流程如图2所示。
3.2.2 API参数及参数取值字符串提取
API数据提取较为简单,在处理API+参数+参数取值时,处理会更加的复杂。原始的数据集中,每个日志文件都会出现杂乱的字符,要使用多次的字符串处理,分割,连接才形成相应字符串,不能从原始的日志文件中获取。对同一个日志文件,API+参数+参数的取值可能会多次出现,但是文中不考虑在单个文档中的频率,只考虑在该文档中是否出现。文中提取出的API+参数+参数的取值特征库形式如下所示:
APIAv={API1A1value14,API1A1value27,API2A2value1 5,API2A3value1 3,…},同样的,API+参数+参数的取值名字后边的数字代表此API+参数+参数值一共出现在多少个日志文件中。最终统计形成TXT文档。API参数及参数取值字符串提取流程如图3所示。

图2 API字符串提取流程图

图3 API参数及参数取值字符串提取流程图
3.3 特征选择
在数据预处理的步骤中,己经从原始的日志文件中提取出了初步的API,API+参数+参数取值等字符串数据。而如果直接使用这些特征进行实验,特征的数目会很大,増加了分类的复杂度,会降低分类算法的效果。同时,在特征当中,很多的特征对分类没有贡献,反而会对分类造成干扰。所以特征的选择在文本分类当中是十分重要的步骤,特征的选择好坏会直接影响到分类效果的优劣。文档频率是最简单的特征选择方法,但是选择出来的特征,只看出现在数据集文档中的频率是不全面的。而信息增益特征选择的方法,可以反映特征所带来的信息量,但是如果对所有的候选特征都进行信息增益的计算,会增加计算的复杂度,降低算法效率。
文中计划在特征选择中,将两个方法进行结合,首先使用文档频率对特征进行初步筛选。对第一步处理得到的特征集,再进行信息增益的计算,进行第二步特征筛选。
3.3.1 文本频率特征选择
数据预处理阶段生成的TXT文件一共是三列,第一列为API,第二列和第三列分别为该API特征出现在恶意软件和非恶意软件中的次数。如果出现在恶意软件和非恶意软件中的次数之和大于输入的文档频率阈值,则保留该特征,否则舍弃该特征,形成新的文档频率特征库。实现第一步特征筛选,初步减少了频率没有达到阈值的特征,减少了下一步的计算量,提高了算法的时间效率。
3.3.2 信息增益特征选择
信息增益来自于香农的信息论,使用信息熵进行评估。在信息增益中,主要是衡量特征给分类带来的信息量,带来信息量越多的特征越重要[18]。计算信息增益,首先要计算信息熵。假设一共有m个事件{X1,X2…Xm},每个事件出现的概率是{P,且有则有单个事件的信息熵计算公式为
所有事件的信息熵为

当某一个因素出现之后,会对事件的发生概率产生影响,即事件的不确定性发生了改变,信息増益就表示事件的这种不确定性的变化程度。计算信息增益,还需要计算划分熵。划分熵的计算公式如下:
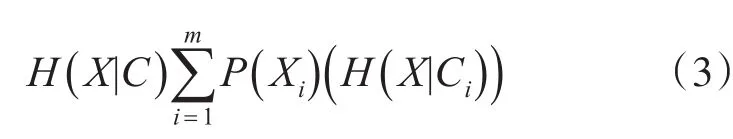
信息增益计算如下:

根据每个特征的信息增益值进行选择,设定阈值,选择信息增益值满足该阈值的特征。
3.4 分类
在文本分类算法中,评价标准也是十分重要的部分。目前常用的分类算法评价指标有识别率、误判率、精确率、准确率等。
文中在进行文本分类的过程当中主要涉及恶意软件和非恶意软件两类,对于二元分类问题,预测可能会产生四种相异的结果,TP(True Positive)表示将非恶意软件正确分类为真的个数,TN(Ture Negative)表示将恶意软件正确分类为真的个数,FP(False Positive)表示将非恶意软件分类为假的个数,FN(False Negative)表示将恶意软件分类为假的个数。下面详细介绍各个评价标准。
识别率,就是正确将恶意软件分类成恶意软件的比率和正确将非恶意软件分类成非恶意软件的比率。比如恶意软件识别率(真阳性率):

误判率,就是对于其他类别的样本,有多少的概率可以将其分类为本类别的样本。比如恶意软件误判率(假阴性率):

精准率,即所有分类为该类的样本数量中真正属于该类的比率。例如恶意软件的精确率:

总的准确率,即所有分类准确的样本数量占总的样本数量的比率。计算如下:

文中将利用上述评价指标对测试结果进行评估验证。
4 实验结果分析
文中采用动态检测分析的方法,构建恶意软件检测模型。以API作为特征,根据3.4节介绍的评价指标,利用相关公式进行分类评估,结果如表1、表2所示。
以API+参数+参数的值为特征,利用相关公式进行分类评价,结果如表3、表4所示。

表1 API为特征的分类结果
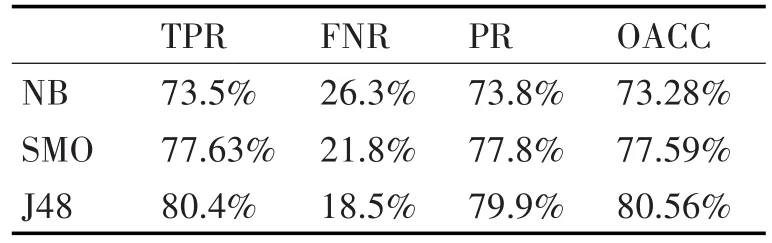
表2 API为特征的评估结果

表3 API+参数+参数的值为特征的分类结果

表4 API+参数+参数的值为特征的评估结果
通过对比表1和表3发现,以API+参数+参数的值作为特征比以API作为特征分类的结果要好,而且通过对比三种分类算法发现J48的分类结果最好。
通过对比表2和表4发现,以API+参数+参数的值作为特征的检测识别率、准确率等均比以API为特征的要高,并且在选定的三种算法中,J48的分类准确率最高,说明该分类算法对文本所构造特征的分类效果最优。
通过实验对比结果可知,API+参数+参数的值作为特征的分类效果和检测准确率等均比API作为特征的好,表明文中所提出的方案能够有效地提高恶意软件检测的准确率。
5 结语
文中采用动态检测的方法,分别以API和API+参数+参数值为特征,使用机器学习及数据挖掘技术,对250个恶意样本和250个正常样本进行仿真实验,实验结果表明,API+参数+参数值这一特征能够有效地提高恶意软件检测的准确率。
文中所提出的方案虽然具备一定的检测效果,但是由于实验条件限制,实验数据相对不是很多,不能够很好地检测所有的恶意软件类别,因此,提出一种可针对任意类别恶意软件的检测方案至关重要。
猜你喜欢
心理学报(2022年10期)2022-10-12
华人时刊(2021年13期)2021-11-27
湖北大学学报(自然科学版)(2021年5期)2021-08-20
北京航空航天大学学报(2021年6期)2021-07-20
诗选刊(2020年12期)2020-12-03
电脑报(2019年12期)2019-09-10
思维与智慧·上半月(2018年10期)2018-11-30
中国计算机报(2018年30期)2018-11-12
思维与智慧·上半月(2018年9期)2018-09-22
西江文艺(2017年15期)2017-09-10
