
基于CNN 算法的深度学习研究及应用
2019-04-03 01:38肖璞黄海霞
现代计算机 2019年35期
肖璞,黄海霞
(三江学院计算机科学与工程学院,南京210012)
0 引言
随着谷歌AlphaGo 的成功问世,人工智能吸引了大众媒体的目光。之后关于人工智能的名词接踵而来,如机器学习和深度学习[1]等。如果说人工智能是目标,那么机器学习和深度学习就是手段。深度学习的产生可以说是受到了生物大脑的影响,但不能简单的把深度学习的研究归结于是去模拟大脑工作。深度学习的研究很多与应用与数学基础有关[2]。卷积神经网络(Convolutional Neural Networks,CNN)[3]是深度学习的一种架构,主要有输入层、卷积层、池化层和输出层,带有这种卷积结构的深度神经网络也被大量应用于机器学习之中。虽然传统的神经网络也能识别手写数字,但是基于CNN 模型的算法[4]更加通用。卷积神经网络可以像人类一样直接读取二维图像,结构上也更类似于人类的视觉神经系统,因而具有强大的特征提取能力[5]。之前一般都是采用人工来进行对数据的训练,这需要用到大量的人力进行特征提取,现在我们可以自动进行大批量数据的训练。
CNN 的基本原理和基础被视为机器学习的首选解决方案。基于CNN 算法的深度神经网络相对于其他一些学习技术以及设计出的特征提取计算有着明显的优越性。本文以CNN 模型为深度判别模型,在传统CNN 算法基础上研究了LeNet-5 网络结构,以及谷歌的Inception-v3 网络结构。这两种网络结构在手写数字识别和图像识别中都取得了非常好的效果。并且CNN 算法在文本分类上也有着不错的成果。本文在TensorFlow 框架下通过CNN 算法与回归模型的对比,识别MNIST 手写体,验证了CNN 算法的优越性,也验证了CNN 算法在图像识别、车牌识别和文本分类上的可行性。
1 深度学习类神经网络
1.1 神经网络
神经网络是人们把神经网络和大脑及生物学上的其他种类做了大量的类比。这里可以将它看做是与大脑无关的一组由简单函数所组成的一组函数,通过多阶段的分层计算形成更为复杂的非线性函数。可以堆积更多层来得到任意深度的神经网络,如线性评分函数、两层神经网络函数、三层深度神经网络函数等。其中三层深度神经网络函数的公式如下:
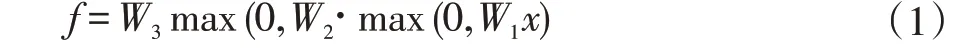
神经传导的原理可以用计算机来进行仿真,每个计算节点方法都是类似的。计算机图里节点的相互连接,我们需要输入或者是把信号x 传入神经元。所有x输入量,例如x0、x1、x2 等,采用如赋予权重w 的方法叠加汇合到一起。这样就是做了某种类型的运算。就像w 乘以x 加上b,再把所有结果整合起来,这就得到了激活函数。我们将激活函数应用在神经元的端部,所得到的值作为输出。最后将该值传输到与之相关联的神经元。
激活函数基本上接收了所有输入,然后再输出一个值。Sigmoid 激活函数以及其他的一些非线性函数,而这些非线性函数可以类比神经元的触发或者说是神经元的放电率。神经元通过采用离散尖峰将信号传递至相邻神经元。如果触发非常迅速,就会产生强信号。经过激活函数计算得到的值在某种意义上讲是放电率。
以一个矩阵运算公式模拟输出与接收神经元的工作方式,公式如下:
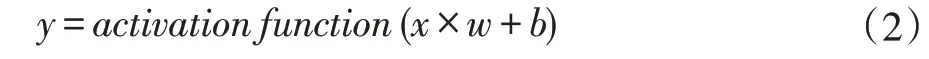
输入3 个神经元:x1、x2、x3,模拟接收神经元之后会输出两个神经元:y1 和y2,需要6 个轴突来完全连接输入和接收神经元。最后使用激活函数,得到的值传入下个神经元。
近年来,由于深度学习的成功,多层感知器模型作为一种比较受欢迎机器学习解决方案又重新受到了重视。多层感知器模型可分为三个层:输入层、隐藏层和输出层。若输入748 个神经元,即是一张28×28 像素的数字为7 的二维图像,那么这748 个神经元就会接收外界的传送信号。然后隐藏层模拟内部神经元,共有256 个隐藏神经元。轴突连接输入层和隐藏层。建立输入层与隐藏层的公式为:

轴突连接隐藏层和输入层。建立的隐藏层和输入层公式为:

最后输出层输出10 个神经元,可以使用Softmax损失函数来进行概率分布,然后把数字7 预测出来。
1.2 CNN算法
现代化的CNN 算法可以充分利用大量数据来获得网络图像和ImageNet 数据集来进行训练并测试,最后提高识别率。
把一张长和宽都是5 像素的图片用一个长和宽都是3 像素的卷积核进行采样,往纵向移动,卷积核不变,移动的步长为1。采样完后得到一张长和宽都是3像素的特征图。
卷积运算操作就是使用两个大小不同的矩阵进行的一种数学运算。卷积运算公式表示为:

把卷积核w 展开得到一个一维向量,排列一下使它能够进行点积。遍历所有的通道,使卷积核紧挨着图片的一个空间位置,然后将所有对应的元素分别相乘。
如果对一张图片进行CNN 算法处理需要四个步骤:
(1)图像输入:获取所输入的数据图像。
(2)卷积运算:用于搜索特定模式,对图像特征进行提取。
(3)池化操作:用来在特征提取过程中降低采样率。
(4)全连接层:用于对图像进行分类。
2 CNN算法与回归模型识别手写体数字应用
2.1 MNIST数据集
MNSIT 是一个手写数字数据库,有60000 个训练的样本集和10000 个测试的样本集。数据集的标签就是0 到9。在MNIST 图片集中,所有的图片长和宽都为28 像素。
要完成预测分类首先要对数据库进行获取,然后输入数据。MNIST 数据可以使用input_data 函数读取相关的数据集。接下来对数据进行读取,就是用图片的索引对图片进行提取,然后对图片进行特征标注[6]。
2.2 回归模型识别应用
Softmax 回归模型是一种将信号转换为概率的损失函数。针对类别去计算概率分布的训练公式如下:

采用先求出输入值与权值的乘积和,再添加一个偏置项的方式。偏置项不与训练的数据进行交互,而是给出数据独立的偏好值。当数据不平衡的时候,偏差值会增加,相当于增加了噪音。然后所求得的值将会转换成概率。
Softmax 也是模型函数定义的一种形式。数学公式如下:

我们将其指数化以便结果都是正数,再把结果值归一化处理。当经过Softmax 函数处理值后会得到概率分布,然后所有的对象就会有分配到相应的概率。每个概率值都在0 和1 之间,所有的概率和为1。Softmax 计算公式为:
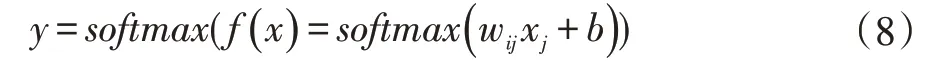
对于模型编写可以按上述公式进行。在模型训练中,可以使用梯度下降法对权重进行更新,并启动模型训练。通过21 次循环训练,模型最终结果是0.9139。如图1 所示。

图1 回归模型训练结果图
2.3 CNN算法识别应用
现在通过使用卷积神经网络重新对MNIST 数据集进行验证,我们将采用全新的CNN 算法来处理数据。
首先定义一个函数,函数的作用是进行初始化权值,生成一个截断的正态分布。之后在卷积层使用TensorFlow 中的一个库来进行二维的卷积操作。卷积层的代码如下所示。
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
这里的x 是指4 维的值,w 是滤波器,strides[1]表示x 方向上的步长,strides[2]表示y 方向上的步长。
在池化层,用的最大池化的方式,取所划分区域里最大的值。在第一个卷积层中对权值和偏置值进行初始化操作。定义的采样窗口是5×5,采样完后得到32个卷积核,也就是32 个特征平面。这里32 个卷积核用到了32 个偏置值。
之后进行ReLu 激活函数操作。把第一个卷积之后得到的结果传入pooling 层。然后定义第二个卷积层,输出64 个卷积核,也就是64 个特征平面。接下来定义第一个全连接层。第一个全连接层输出后,得出神经元的输出概率,然后对定义第二个全连接层。之后可以使用交叉熵代价函数和一些其他的优化方式。然后可以启动模型训练。
通过21 次的循环训练可以看到,模型最终的结果是0.9917,如图2 所示。

图2 回归模型训练结果图
2.4 实验结果分析
上述两个模型我们都迭代21 次,循环所有的样本为1 个周期,每次训练一个周期后都会把测试数据的值输出。回归模型与CNN 算法测试准确率对比结果如图3 所示。
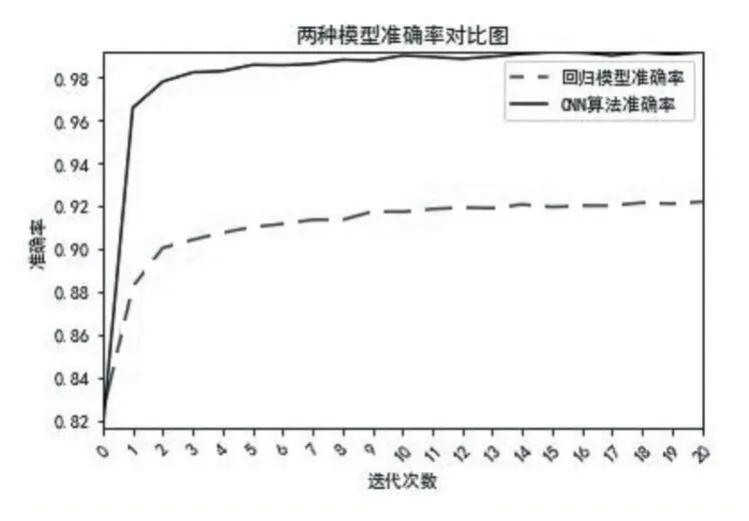
图3 两种模型准确率折线图
从最后的测试准确率上看,回归模型最后的准确率是91%,CNN 算法最后的准确率是99%。如果从收敛速度上来看,明显CNN 算法要比回归模型的收敛速度要快。因此使用卷积CNN 算法使实现分类功能的效果要好得多。
3 TensorFlow框架下的CNN算法应用
深度学习有很多框架,TensorFlow 支持包括手机在内的各种设备的运行,还支持各种语言的编写。下面的实验在TensorFlow 框架下进行。
3.1 LeNet模型识别车牌
首先,要对获取的车牌图片进行分割处理,可以采用OpenCV 来分割图像。分割完后获得图像是32×40像素的。这样就采集到了车牌的中文简称和26 个字母的图片数据集[7]。如图4 所示。

图4 图片数据集
先对车牌上的省份简称进行训练。训练中记录了读取图片所耗费的时间,总共读取了的训练图片数量。这里有个判断操作是,在每5 次迭代完成之后,准确度如果达到了100%,那么退出迭代循环。
启动省份简称的模型训练,运行结果如图5 所示。
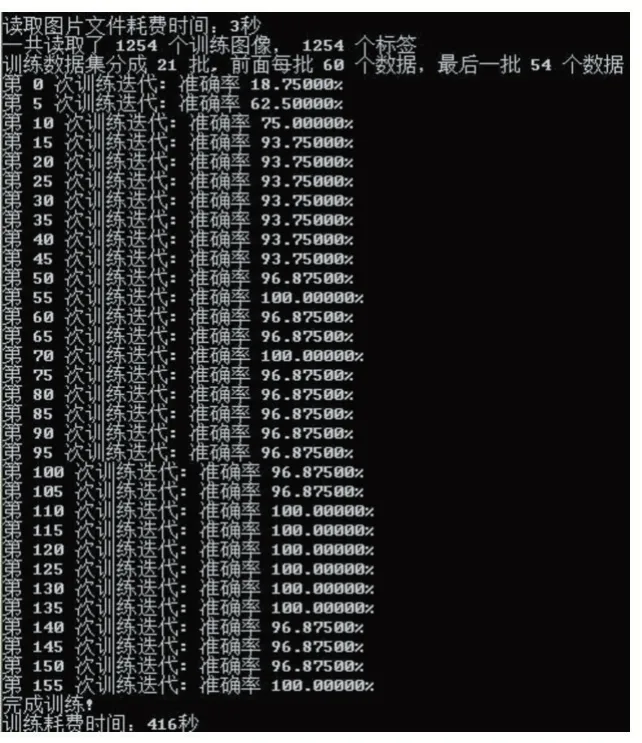
图5 车牌省份简称的训练结果图
之后对车牌上省份简称进行识别。识别结果如图6 所示。可以看到车牌上的省份简称被识别出来是“沪”。
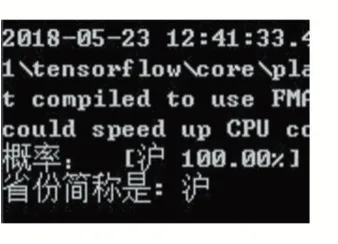
图6 省份简称的识别图
然后进行城市代号的训练。同样的,在每5 次迭代完成之后,准确度如果达到了100%,则退出迭代循环。训练结果如图7 所示。

图7 城市代号的训练结果图
进行城市代号的识别,其结果如图8 所示。可以看到车牌上的城市代号是“O”。
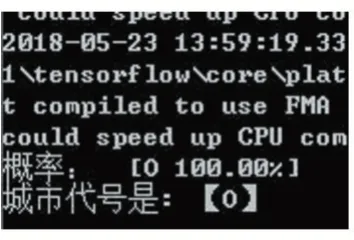
图8 城市代号的识别结果图
最后进行车牌编号训练[8]。我国的车牌编号中是没有字母I 和字母O 的,所以这里只要对24 个字母和10 个数字进行训练。训练结果如图9 所示。

图9 车牌编号的训练结果图
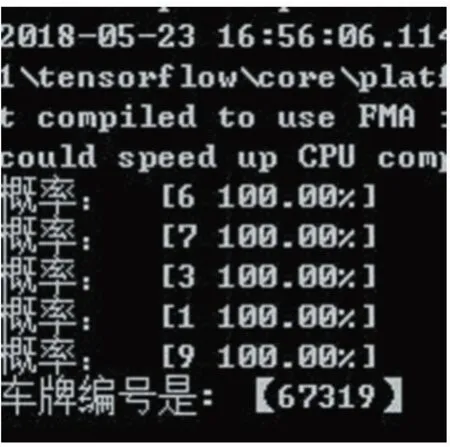
图10 车牌编号的识别结果图
在训练结束之后,我们进行车牌编号的识别。结果如图10 所示。车牌编号的识别结果是“67319”,最终车牌上的字符结果为“沪O67319”。可以看出,CNN 算法在车牌识别上是可行的。
3.2 CNN算法在自然语言处理中的应用
LeNet-5 的网络模型以及谷歌的Inception-v3 模型都用到了CNN 算法。大部分的CNN 算法都运用到计算机视觉之中[9]。而近年来,CNN 算法也逐渐应用到了自然语言处理中[10]。
CNN 算法应用于NLP 任务中,处理的都是以矩阵形式表达的文本或句子。例如,有10 个单词,每个单词都用128 维向量来表示,之后所得到的10×128 的这个矩阵就相当于一副“图像”[11]。
词向量的维度是128,那么右边的6 个卷积核的列数都是128 列。六个卷积核分别对矩阵进行卷积操作,得到6 个feature maps。与图像非常类似,对它们进行最大池化操作,把分割的区域里的最大值连接起来形成6 个神经元。然后进行一个全连接层操作,输出两个神经元。
可以使用自然语言处理来对电影评论进行分类。而在电影评论的数据集中有两个样本:正样本和负样本。正样本是对电影好的评价,负样本是对电影不好的评价。在负样本中,每一行一个句子,总共有5000多行。正样本中也是5000 多行,每一行一个句子。这里迭代20 个周期,每100 次保存一次模型。最多保存5 个模型。然后打印参数,如图11 所示。
图11 参数打印图
处理数据,对矩阵做卷积运算。建立词典,把数据变成词典中的编号。对数据进行切分,10%的数据作为用户集,90%的数据及进行训练[12]。训练结果如图12 所示。

图12 文本分类训练结果图
若不分类,则准确率只有50%,后面准确率逐渐提升。在运行3000 次后,训练层的准确率达到了98%,验证集的准确率达到了73%。因为正样本和负样本加起来总共只有10000 条数据,样本比较小,所以有过拟合现象。但总体来说,电影评论的分类是成功的。
4 结语
本文基于CNN 算法进行了深度学习的研究与应用,所采用的算法在深度学习TensorFlow 框架上进行了实现。
(1)可以直观地看到模型的具体构造以及更深层的结构。通过研究结果可以验证CNN 算法确实比一般的神经网络在训练与验证准确率上要高。
(2)在研究过程中,同时也发现某些参数的设置会影响准确率的变化,例如增加一个全连接层会使得准确率上升缓慢,并且波动幅度变得更大。
当然,本文在自然语言处理方面的研究还是缺少的,例如声音识别,特别是CNN 算法应用在声音识别中还需要进一步研究。
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子产品世界(2021年8期)2021-01-16
健康体检与管理(2021年10期)2021-01-03
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
