
基于缴费行为轨迹追踪的渠道风险监控模型
2019-04-26 08:56李捞扒邹阳曾晓勤
微型电脑应用 2019年4期
李捞扒, 邹阳, 曾晓勤
(河海大学 计算机与信息学院,南京 211100)
0 引言
电费资金回收是电网企业的生命线,电费收取的风险不仅会影响电网企业的持续健康发展,也势必会影响整个国民经济的稳定性[1]。随着国家电网公司建设的一体化缴费管理平台逐渐开始支持电网企业、金融机构和非金融机构等多种缴费渠道的接入,为客户提供了便捷灵活的缴费方式,同时也增加了电费资金在从客户到第三方缴费渠道再到电网企业的流动过程中的收取风险。那么如何加强电费资金安全管理技术应用,系统性梳理电费流转各环节风险点,防范各环节资金安全风险,确保电费颗粒归仓,已成为电网企业营销管理部门的重要任务。
目前,关于电费资金安全风险监控的研究主要集中在防范客户层面上的拖、欠费风险,且通常采用的是基于数学和统计学的方法,少部分研究者已经开始尝试将机器学习方法引入到拖、欠费风险评估中。对于客户层面的风险监控研究已经取得了很多实质性的成果并有部分信用评价系统、风险评估系统和欠费预警系统进入实际上线运行阶段[2],但随着电力体制改革的不断深化,缴费渠道存在的风险被逐渐暴露出来,然而,目前对缴费渠道风险的研究屈指可数,且仍主要是套用客户风险研究方法。由于客户只是电费资金流转过程中的一个环节,而目前的电费风险监控系统又缺乏对缴费渠道存在的风险进行系统梳理、有效识别和精准防控,所以现有的风险监控策略不能形成辐射全过程的风险防范预案。
经过长期对电力客户缴费行为轨迹的跟踪观测研究,发现除电网企业本身缴费渠道外,其他缴费渠道均隐藏着潜在的资金流异常,主要表现为收取电费后携款外逃、使用充值卡套取多重手续费、不定时长截留电费、查缴比偏高、重复扣款和对账不及时等风险。本文在已明确第三方缴费渠道存在的风险类型、成因机理和表现形式的基础之上,提出了一个基于缴费行为轨迹追踪的渠道风险监控模型。首先对客户的缴费记录进行定性分析,通过分析客户的缴费记录追踪到其缴费行为轨迹,进而根据风险类型识别模型判断出该客户潜在的风险类型;然后确定各风险评估指标,建立渠道风险评估指标体系,定量统计渠道不同风险类型的各评估指标值;最后通过风险评估模型得到渠道各风险类型的风险指数和风险排名。该模型将机器学习方法引入到风险类别识别模型和风险评估模型中,同时将定性指标和定量指标分开考虑,解决了传统方法中鲁棒性较差和机器学习方法中解释性较差的问题,且获得了可信度较高的风险评估结果。
1 相关研究
我国电力行业于本世纪初开始引入风险监控研究,经过近些年对电费收取风险监控的研究与探索,相继从不同角度分别提出了一些值得借鉴的风险评估方法和思想。
起初,风险评估主要是采用基于数学和统计学的方法,其中,基于数据统计特征的熵权法(entropy weight method, EWM)[3],由于忽略了不同评估指标间存在的关系,所以通常作为评估指标的计量方法,而不适合作为风险评估方法;层次分析法(analytic hierarchy process, AHP)[4]是应用最广泛的风险评估方法,其本质是主观经验的客观标量转化,然而由于不同的应用场景对判断矩阵的一致性要求不同,直接使用CR<0.1缺乏科学依据[5],所以实际评估效果一般;改进了AHP中CR值不确定问题的模糊层次分析法(fuzzy analytic hierarchy process, FAHP)[6]是将模糊数学理论与AHP相结合,把判断矩阵改造成模糊一致矩阵,使用检验行间对应元素差是否为同一常数代替判断矩阵的一致性检验,但FAHP仍需要Delphi专家调研法和EM标度法的支持,计算复杂度较高。
后来,随着人工神经网络和机器学习的研究热潮再次掀起,这些方法也逐渐被应用到电力行业风险监控的相关预测研究中。文献[7]利用SVM和BP神经网络实现了对客户按风险程度分类,但由于风险评估指标体系中既有定性指标又有定量指标,而此类方法只能进行定量分析,所以导致其评估结果的解释性较差,限制了其工程应用;文献[8]尝试使用决策树算法预测客户欠费风险类型,但文中并未屏蔽与风险预测无关的指标,造成得出的决策树结构较复杂;文献[9-11]将机器学习中的K-Means聚类算法、Logistic回归分析法和遗传算法等应用到电费收取风险评估中,但对于数据量较少的渠道风险,预测的精度往往不是很理想。
为了解决上述方法中存在鲁棒性和解释性较差的问题,同时为了提高预测的准确率和降低模型的复杂度,应尽量选取与缴费行为相关且客观可统计的评估指标。根据所选的评估指标,先使用改进的决策树算法将客户按定性指标分类,然后定量统计渠道各风险类型的评估指标值,最后使用回归分析法(regression analysis)寻求风险评估指标与渠道风险指数间的关系。为了解决回归模型在求解输入向量与目标输出间的多元函数表达式组时可能出现异方差性问题,尝试使用加权最小二乘法(weighted least square method, WLS)[12]对原模型进行修正,使得到的参数估计量同时具有无偏性和有效性。
2 构建渠道风险监控模型
电费资金的流转过程可以简单地描述为:用户通过第三方渠道缴纳电费,第三方渠道定期将收到的电费转给电网企业。针对缴费渠道在收取电费过程中、收缴时间差内、与电网企业对账时存在的诸多风险点,现通过构建基于缴费行为轨迹追踪的渠道风险监控模型,以期及时发现潜在的风险类型并对其进行有效识别和精准预测,为制定相应的防范措施提供决策依据。
2.1 追踪缴费行为轨迹
客户缴费行为轨迹是分析电费资金流转各环节风险的最直接依据,也是本模型的研究出发点。如表1所示。

表1 原始格式的数据记录
在电费营销管理系统中,缴费记录包含渠道号、网点号、用户号、费用周期、账单编号、交易流水号、交易时间、收费类型、缴费方式、结算方式、收费金额、滞纳金等字段,所以可通过数据库中的缴费记录追踪到客户的缴费行为轨迹,进而判断其可能存在的风险类型。以下将以冲正套现风险点为例对模型进行描述,冲正套现是指第三方渠道以某种手段将客户缴纳电费的操作从电力公司的营销管理系统中撤回,电费资金将回流到第三方渠道账户。
2.1.1 数据格式转换
为方便追踪客户在一个费用周期内的缴费行为轨迹,需要将其在一个费用周期内的所有缴费操作归纳成一条记录,具体的做法是先将数据库中原始数据记录转换成单条数据格式,如表2所示。然后以客户为单位,按时间先后排序,最后将单条数据格式归并为单户数据格式,如表3所示。同时对收费类型、缴费方式和结算方式字段重新编码,其中,单条数据格式包括渠道号rcv_org_no、网点号branch、用户号cons_id、账单年月charge_ym、缴费时间charge_date、收费类型type_mode、缴费方式pay_mode、结算方式settle_mode和收费金额rcv_amt 9个属性;单户数据格式包括用户号cons_id、账单年月charge_ym、单条数据个数refer_id_num、单条数据集合refer_id_list 4个字段,其中的refer_id_list由单条数据标识refer_id顺序排列并以逗号分隔而成;编码策略是将以01开头的0101~0116分别映射到A~P,以02开头的0201~0216分别映射到a~p。

表2 单条数据格式的数据记录

表3 单户数据格式的数据记录
2.1.2 简化缴费行为轨迹序列
由2.1.1可知,每次缴费行为可用收费类型、缴费方式和结算方式3个字段组成的编码组表示。由于客户缴费行为具有较大的随意性,所以数据中反映出来的缴费轨迹复杂多样,因此有必要对缴费行为轨迹进行简化,提取出关键行为节点。经过对冲正套现业务的深入分析,得到如下简化规则:
1)与前一步相同的操作不再加入整体轨迹序列。
2)反复进行冲正和充值卡缴费的操作,合并后仅保留一组序列。
3)任意一种缴费操作和预收结转电费操作联合发生时,合并后保留其中一个编码组。
4)如果在冲正操作之后发生预收结转电费,则忽略该条转账记录。
经过上述两步处理后,可得到简化的某客户在指定费用周期内有时序特征的缴费行为轨迹序列。那么上例对应简化的缴费行为轨迹序列为:AAKIAKCAF。
2.1.3 风险类别识别
风险类型识别是根据简化的客户缴费行为轨迹序列判断其潜在的风险类型,是定性分析的核心内容。在创建风险类型识别模型之前,需要明确的是冲正套现风险点包含了三种风险类型,如表4所示。

表4 风险类型
创建风险类型识别模型,首先需要构造数据集。从某省2017年6月到10月的每个月份中抽取5000个典型用户的所有缴费记录,将其轨迹序列作为特征属性,使用Delphi专家调研法标注对应的风险类型。为了保证样本占用的存储空间相等,文中采用稀疏矩阵存储样本特征,并使用0来填充空缺位置,同时设置最后一列为目标分类结果。假设稀疏矩阵的长度为10,那么上例转化为样本时对应的数据格式如表5所示。

表5 数据集中的样本
由于缴费行为轨迹序列具有较强的时序性,所以选择机器学习方法中基于信息熵增益的ID3决策树算法对轨迹序列进行分类,每次划分子树前,先计算下一个编码组的信息增益,然后选择信息增益最大的编码组进行分裂,直到遍历完所有编码组,其中,信息增益如式(1)。
(1)
式中:H表示信息熵,S表示全部样本,value(i)是第i组样本的所有取值集合,v是第i组样本的一个取值,Sv表示S中第i组值为v的全部样本,|Sv|表示Sv中包含的样本数。
由于无法预知客户未来缴费行为轨迹序列的最大长度,所以为了提高识别模型的精度和决策树的泛化能力,使用正则表达式对决策树进行模式匹配和逻辑补充。从数据集的每个月份中随机选取4 000条数据作为训练集,训练得到如图1所示的风险类型识别模型,其中:“0”代表是否存在后续操作,即缴费行为轨迹是否到此终止;“01”、“02”、“03”、“04”分别对应表4中的风险类型编号。
2.2 建立风险评估指标体系
风险评估指标体系是定量统计的依据,也是风险评估的前提,将直接影响评估结果的合理性。如图1所示。
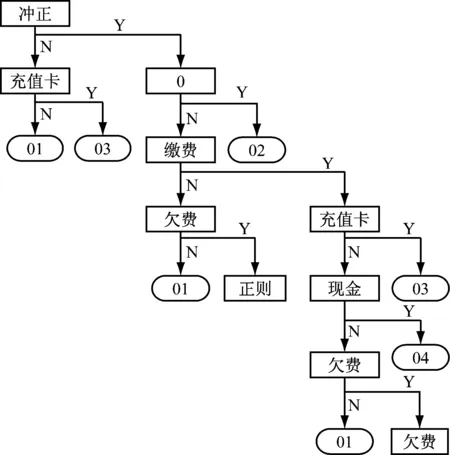
图1 风险类型识别模型
在选取风险评估指标时,应遵循精简可靠、满足需求、纵向可比性高且客观统计特征强等原则。如前所述,为降低风险类型识别模型的结构复杂度、提高定性识别的准确率,应尽量选取与缴费行为相关度较高的特征属性,通过追踪客户的缴费行为轨迹可判断出其潜在的风险类型,进而可得到某渠道下存在每种风险的风险次数、风险金额、风险次数比、风险金额比、风险总时长、平均风险时长和风险高峰时段等统计指标。
参考目前在企业信用管理中广泛使用的5C理论和AHP中关于指标体系的讨论,结合电力行业特点及渠道风险评估需要,本文建立了一套基于风险类型的、多层次递阶的渠道风险评估指标体系,如图2所示。
2.3 渠道风险评估
在定性分析确定客户风险类型和定量统计得到渠道各风险评估指标值的基础之上,可使用机器学习方法对渠道风险进行评估预测,这样就可以解决由直接对原始数据使用机器学习方法造成的评估结果解释性较差的问题,实现分类评估。由渠道风险评估指标体系可知,对于目标层1、2、3、4、5和6,其决策层之间是相互独立的,所以可使用回归分析法构建自动化的风险评估模型,计算各风险类型的风险指数值,进而可得到统计推断下的渠道各风险排名。由于不同的风险类型对应着不同的风险评估模型,但其创建过程大同小异,所以以下将以截留电费风险为例,对风险评估模型的创建过程进行描述。
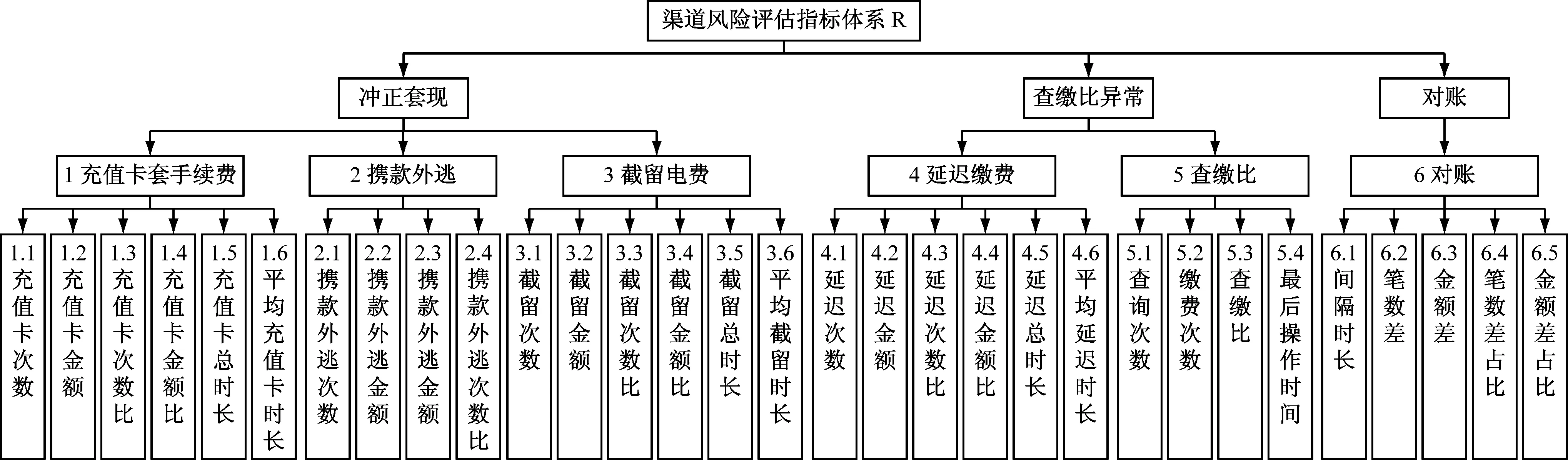
图2 渠道风险评估指标体系
由于Delphi专家调研法得到的评估结果最直接、最具有参考意义,所以通常将其作为回归分析的参考依据。本文选取连续3个费用周期内的500个存在截留电费风险的典型渠道作为回归样本,为了弱化主观经验对回归结果的影响,使用具有相对关系的排名代替具体的风险指数值。设样本P=[p1,…,p500],权重向量X=[x1,…,x6],风险指数Y=[y1,…,y500],且yi已按从大到小排序,根据回归分析的思想,yi=X·pi,那么yi-yi+1≥0恒成立,故存在多元回归函数不等式组成立式(2)。
(2)
解出该多元不等式方程组即可得出权重向量X。
由于直接求解不等式组难度较大,所以可将上述不等式转化为形式上的等式,即yi-yi+1=ξi,其中ξi为常数。那么式(2)可写成式(3)。
(3)
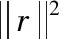

用D-1对原模型进行加权,得到式(4)。
D-1·Y=D-1·X·A+D-1·B
(4)
通过变量替换,令Y*=D-1·Y,X*=D-1·X,B*=D-1·B,式(4)可写成式(5)。
Y*=X*·A+B*
(5)
此时(5)的协方差
Cov(B*,B*)=E(D-1·B·B·(D-1)T)=
所以新模型不存在异方差性,再对新模型使用LSM得到参数估计量XWLS=(AT·W-1·A)-1·AT·W-1·Y,此时的XWLS同时具有无偏性和有效性。
如何求解参数估计量XWLS,可以归结为如何确定加权矩阵W的值。首先对原模型X·A=b运用最小二乘法得到误差项的近似估计量ei,然后由ei组成加权矩阵W,那么基于WLS的回归分析基本流程如下:
1)求出原模型的最小二乘解(AT·A)-1·AT·b,并计算误差项的近似估计量ei。
2)利用ei构造合适的加权矩阵W=D·DT。
3)将D-1左乘原模型的两边得到新模型,再求出新模型的最小二乘解(AT·W-1·A)-1·AT·W-1·b。
综上,可得到基于缴费行为轨迹追踪的渠道风险监控模型的算法,伪代码描述如下:
算法1:基于缴费行为轨迹追踪的渠道风险监控算法
Algorithm1: ChannelMonitor()
Input: 费用周期区间[t1,t2],截留和延迟时长阈值x1
Output: Map
RiskRank包含风险类型t,风险指数i和风险排名r 3个属性
1)List
2)foreachpmonthinmonthListdo
3) String info=getOriRecord(pmonth.getStartDate(),
pmonth.getEndDate());//获取原始数据
4) Map
5)foreach(id,user)inuserMapdo
6) String paySeq=getPaySeq(user);//追踪缴费行为
轨迹序列
7) String keyPaySeq=simplePaySeq(paySeq);//简化
轨迹序列,提取出关键行为节点
8) user.setRiskType(cognRiskType(keyPaySeq,x1));
//根据简化的轨迹序列识别潜在的风险类型
9) userMap.put(id,user);
10)endforeach
11) Map
12)foreachXRiskinRISKTYPELISTdo
13) XRiskTable channelXRiskData = getXRiskData
(channelStatsMap);//获取渠道某风险的数据
14) Map
15) Map
16) Map
17)returnchannelXRiskRank;
18)endforeach
19)endforeach
3 实验结果及分析
本部分将对上述文中提出的基于缴费行为轨迹追踪的渠道风险监控模型进行实验验证,对比分析风险类型识别模型的准确率和风险评估模型的合理性,并进一步探讨其工程实用性。
由于精确地预测客户潜在的风险类型是实现渠道风险监控的前提和必要条件,所以为了验证使用ID3决策树算法与正则表达式结合的方法创建的风险类型识别模型的准确率,分别使用ID3决策树算法、正则表达式和ID3决策树算法与正则表达式相结合的方法创建冲正套现风险类型识别模型和查缴比异常风险类型识别模型,将数据集中每个月份剩下的1000条数据作为测试集,对比不同方法创建的风险类型识别模型的准确率,得到每组实验的准确率如表6所示。
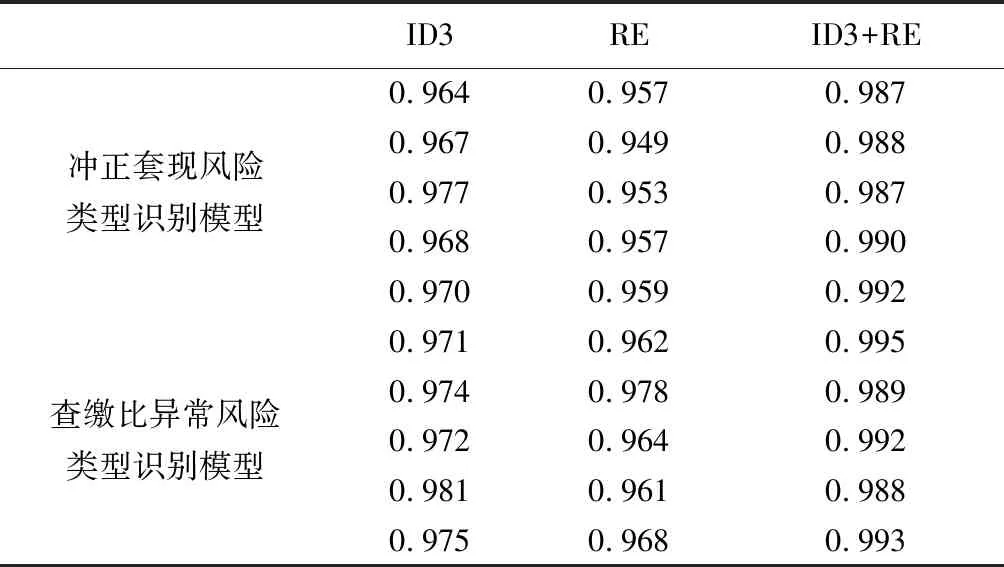
表6 风险类型识别模型的准确率
由表6可知,将ID3决策树算法与正则表达式相结合创建的风险类型识别模型的准确率超过0.987,比单独使用ID3决策树算法提高了约1.9%,且当分类模型越复杂,准确率提升越明显,同时,引入正则表达式还可以降低风险类型识别模型的结构复杂度。

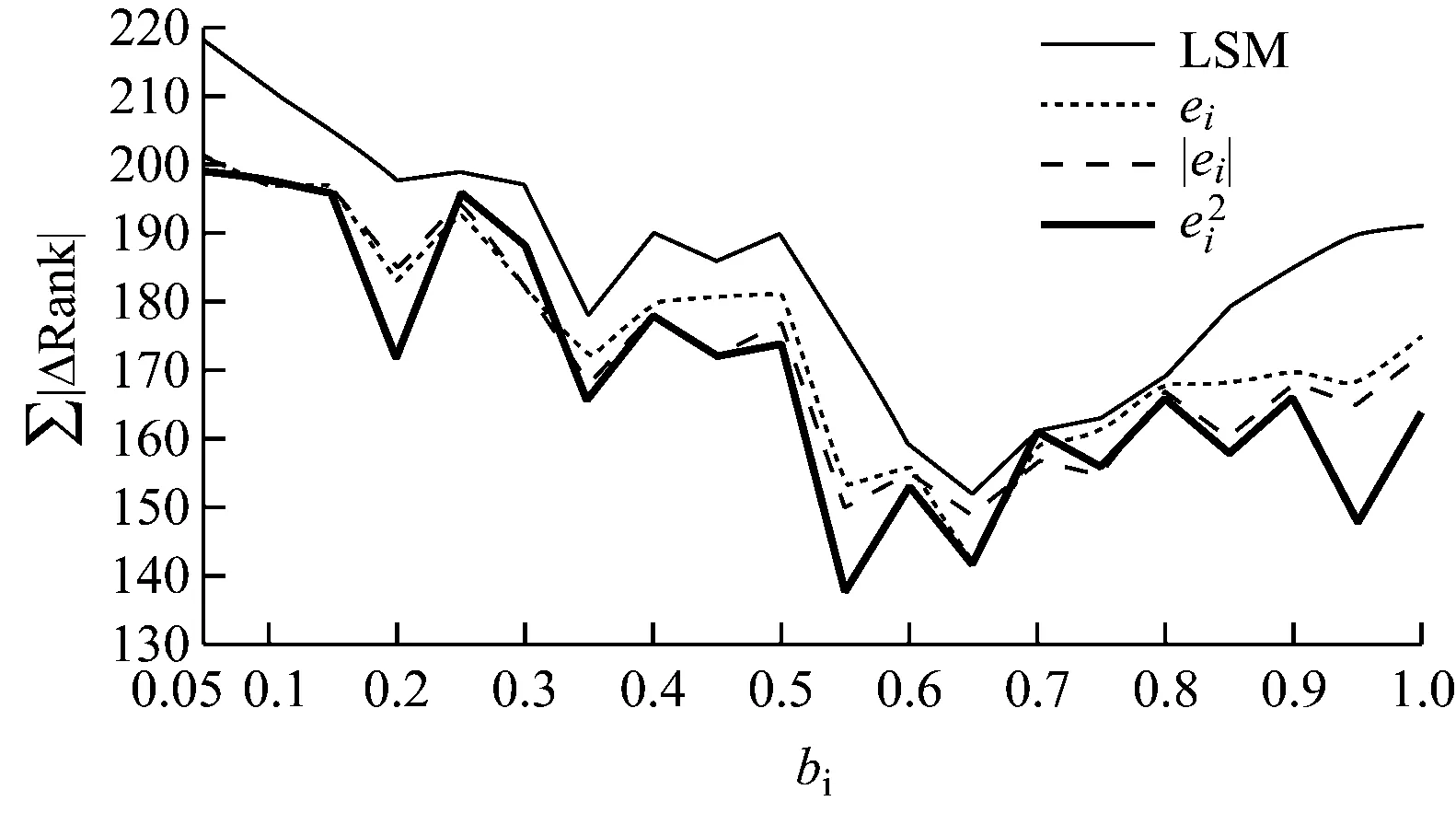
图3 渠道排名误差的绝对值之和
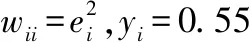

表7 渠道排名误差统计表
由表7可知,约96.72%的样本排名误差在3个名次之内,仅有约0.33%的样本排名误差超过10个名次,评估精确度能够满足实际需求,所以引入加权最小二乘法不仅可以解决回归模型的异方差性问题,还可以提升模型的可信度与合理性。
为进一步探讨基于缴费行为轨迹追踪的渠道风险监控模型的实用性,分析在不同费用周期内同一渠道的某风险类型排名变化情况。通过本模型获得某省所有第三方渠道在2017年6月到10月连续5个费用周期内的截留电费风险相对排名,然后使用滑动窗口法[14]计算每个渠道的排名变化,经分析发现,渠道的截留电费风险排名变化情况整体上符合较为规则的统计分布,如图4所示。
由图4可知,大部分渠道的风险排名变化较小,只有少数渠道的排名变化超过了20个名次,这一结果说明部分渠道确实存在潜在的电费收取风险,所以构建渠道风险监控模型是非常有必要的,同时也说明本模型具有一定的实用性。
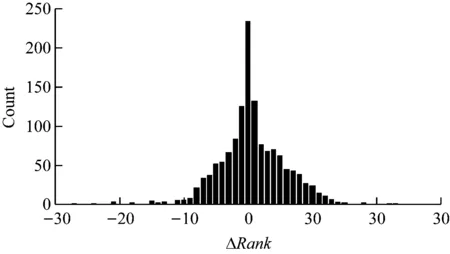
图4 渠道排名变化分布情况
4 总结
针对目前电费资金流转过程中的第三方缴费渠道仍存在风险监控漏洞问题,文中提出了一个基于缴费行为轨迹追踪的渠道风险监控模型,并以冲正套现风险点和截留电费风险类型为例,对模型的追踪缴费行为轨迹、构建风险评估指标体系和渠道风险评估三大核心步骤进行了讨论。实验验证了使用决策树算法与正则表达式相结合的方法创建风险类型识别模型可以获得更高的准确率,以及回归分析时引入WLS可以提高风险评估模型的合理性。模型将定性分析与定量统计分离,实现了分类评估,取得了可靠性较高的风险评估结果。
将来随着研究的进一步深入和模型的不断完善,会有更多机器学习、神经网络和数据挖掘方法与技术被用于风险类型识别和风险评估方面,可进一步提升电网企业风险监控水平。
猜你喜欢
吉林电力(2022年1期)2022-11-10
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
现代营销·理论(2019年5期)2019-09-10
科学与财富(2016年32期)2017-03-04
科学与财富(2016年32期)2017-03-04
共产党员·上(2014年11期)2014-11-26
