
基于查询分片用户协作的位置隐私保护方法
2019-05-10 02:00傅超仪
小型微型计算机系统 2019年5期
江 颉,傅超仪
(浙江工业大学 计算机科学与技术学院,杭州 310000)
1 引 言
随着移动设备和GPS定位技术的不断发展,基于位置服务(LocationBasedServices,LBS)的应用领域得到不断的扩展[1].从最初为用户提供社交、旅行以及一些综合生活服务等方面的增值业务到目前的智能交通、医疗定位和物流监控等,深入到社会的各个层面.然而,在享受位置服务带来的便利的同时,用户位置隐私保护问题也不容忽视[2,3].通常位置服务提供商(LocationServiceProvider,LSP)首先必须获取到用户的位置信息才能够提供服务,其中不仅包含用户的位置信息,还能够通过截取用户请求内容获知用户其他的隐私信息,如医疗信息、生活方式等[4-6].如果LSP并非完全可信或者被恶意者攻击,用户的隐私信息就面临着泄露的风险[7].同时一些恶意的用户通过加入匿名组[8]的方式来获取用户的位置信息和查询内容用于鉴别用户的身份,进而获得用户的隐私信息.因此,如何在享受基于位置服务的同时,避免隐私信息泄露是急需解决的问题.
针对上述在位置服务中用户隐私信息泄露的问题,本文采用用户协作的方式同时结合第三方服务器提出一种基于查询分片用户协作的位置隐私保护方法.该方法主要是通过对用户的查询请求进行分片的形式来保护用户的隐私信息.第三方服务器在查询过程中无法得知用户的相关信息.同时由于查询过程在用户端完成,在一定程度上降低了第三方服务器的开销.
2 相关工作
近年来,为了解决LBS中存在的隐私信息泄露的问题,研究者们提出许多相关的隐私保护方案.Gruteser等[9]最早提出位置k匿名的思想,即在用户发起查询的匿名区域内还至少包含k-1个其他用户,使得位置服务器无法准确地识别出具体用户.在此基础上,陆续地提出基于第三方服务器的模型用于解决用户隐私问题.Mokbel等[10]提出使用基于第三方服务器将用户精确的位置信息模糊化为匿名区域用于发送请求.Gedik等[11]提出一种个性化的k匿名模型,用户能够指定最低匿名级别并通过可信的第三方服务器来进行位置的匿名化处理.Zhang等[12]针对于第三方服务器在移动用户数量很大的情况下存在的性能问题,提出一种新型的混合框架用于平衡第三方服务器和移动用户之间的负载.
在无第三方服务器方式的位置隐私保护方法中,Yiu等[13]提出一种SpaceTwist方案,用户使用随机选取的锚点代替用户的真实位置向位置服务器发起查询,最后根据返回的查询结果与真实位置进行计算得到精确的查询结果.虽然该方案避免了第三方服务器的使用,但是由于缺少用户间的协作,无法达到k匿名的效果.黄毅等[14]在此基础上进行了改进,提出了Coprivacy方案.采用用户协作的方式形成匿名组并将匿名组的密度中心作为锚点代替用户的真实位置来发起查询.针对于锚点可信度的问题,Zhou等[15]提出一种基于敏感位置多样性的锚点生成方法.该方法根据用户的访问次数和时间来选择敏感位置形成多样性区域,通过将其质心作为锚点位置来增加用户位置的多样性.为了实现加密查询,Peng等[16]提出一种基于希尔伯特曲线变换的隐私保护方法,用户利用希尔伯特曲线将真实的位置进行转换,第三方服务器收集到足够的位置信息后形成匿名区域发送给LSP,LSP端采用维诺图进行近邻算法查询,最后将查询到的兴趣点再利用希尔伯特曲线进行转换返回给用户.沈楠等[17]提出一种基于保序加密的网格化位置隐私保护方案,该方案通过将用户的查询范围进行网格化处理,再结合保序加密技术实现用户位置信息透明的情况下完成查询.林少聪等[18]提出一种基于坐标变换的k匿名位置隐私保护方法,向服务器发送变换后的坐标,服务器在不知道用户真实坐标的情况下完成请求服务.
针对于在查询过程中依赖第三方服务器来完成匿名处理以及在形成匿名组过程中无法保证协作用户可信度的问题,本文提出一种基于查询分片用户协作结合第三方服务器的位置隐私保护方法.通过将请求分片,处理结果由不同的匿名组用户发送给位置服务器,降低了匿名组中存在不可信协作用户时隐私信息泄露的风险.同时,第三方服务器在查询过程中负责生成用户查询所需的锚点信息,其本身不参与任何匿名处理,避免了在其受到恶意攻击时用户隐私信息泄露的风险.
3 基于切片加密的用户协作位置隐私保护方案
3.1 系统架构
本文在一定区域内用户自组织网络的基础上添加中心服务器,系统结构主要由用户(User)、中心服务器(CS)和位置服务器(LSP)三个部分组成,如图1所示.
User是一组具有定位功能的移动终端,包括通信协议模块、位置匿名模块、数据安全等级设置模块、请求处理模块和查询处理模块.其中通信协议模块用于在形成匿名组的过程中向近邻的用户发起请求以及向位置服务器发起查询请求Ql并获得查询结果.在通信协议模块中,用户支持P2P通信和无线互联网通信.其中P2P通信主要用来与其他移动用户进行自组织通信,无线互联网通信用来向位置服务器发起查询并取得查询结果.
在位置匿名模块中,User根据自己的隐私需求设置个性化隐私保护参数k和s.其中k表示匿名参数,即用户与其他k-1个协作用户无法准确区分.s表示用户匿名区域半径.位置匿名模块主要作用是根据用户设置隐私保护参数将通信协议模块中得到的用户组成匿名组.
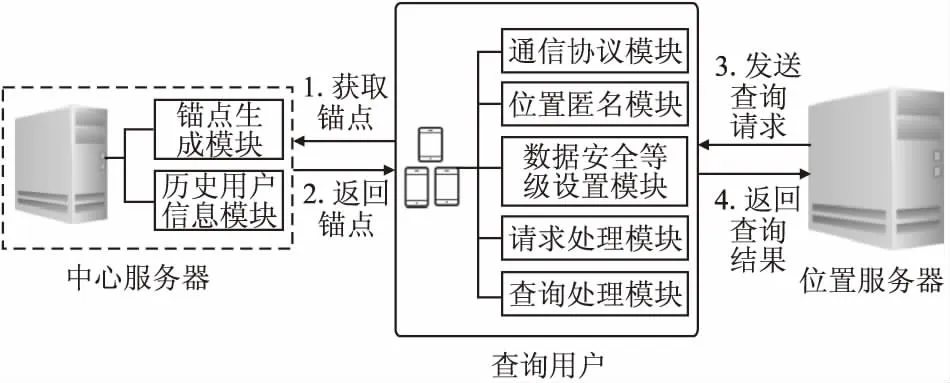
图1 位置隐私保护框架Fig.1 Framework of location privacy protection
在数据安全等级设置模块中,User可以根据安全等级定义同时结合自身的隐私保护需求对查询请求Ql的内容进行安全等级的设置.
在请求处理模块中,User通过将CS返回的锚点信息代替用户的真实位置信息,同时根据设置的安全等级以及分片规则对Ql进行分片处理.
查询处理模块主要用于向位置服务器发起位置近邻查询,同时对位置服务器返回的结果与自身的真实位置进行计算和过滤,得到精确的近邻查询结果.
CS主要由锚点生成模块和历史用户信息模块构成,其中锚点生成模块根据用户请求Qc中的密度中心及区域半径η计算得出最小匿名区域,在最小匿名区域内进行锚点生成算法得到最佳锚点信息返回给User.历史用户信息模块用于在锚点生成的过程中提供历史用户的信息.
LSP是为用户提供各种LBS服务的大型位置服务数据库.它通过接收User发送过来的请求信息,根据请求的内容在其数据库中搜索到相应的兴趣点信息,并将查询结果处理后,返回给User.
3.2 数据安全等级设置
用户可以根据安全等级定义[19],即根据信息价值来定义其重要程度.并结合自身的隐私保护需求来对查询请求Ql进行安全等级设置.例如用户的位置信息L和身份信息ID′属于个人的敏感信息,如果泄露,会直接暴露用户的隐私,可以将其设置为高安全等级.用户的查询内容Content属于关联信息,如果泄露,攻击者可能通过查询内容来推测出用户的生活习惯等,可以将其设置为中安全等级.查询Ql中的匿名参数k和匿名组标识符gid为公共信息,可以将其设置为低安全等级.如表1所示.

表1 安全等级定义Table 1 Definition of security level
3.3 查询请求分片
客户端在用户设置数据安全等级后对查询请求进行分片.在分片的过程中,高安全等级的内容包含用户的敏感信息,如果与中安全等级的关联信息切分在一起会大大增加用户隐私泄露的概率.所以可以将敏感信息与关联信息分别与公共信息切分在一起.同时将用户通过散列函数产生的唯一识别码ID添加到每一个分片后的请求片段中用于在位置服务器端请求重组.
针对本文中的查询请求Ql={ID,L′,Content,k,s,gid},其中ID为用户的唯一标识码,L′为锚点信息,Content为查询内容,k为匿名参数,s为匿名区域半径,gid为该匿名组的标识符.根据3.2节进行安全等级设置后,一种可行的分片方式为Ql1={ID,L′,k},Ql2={ID,s},Ql3={ID,Content,gid}.
3.4 基于历史用户的锚点生成算法
在选取锚点的过程中,通常采用随机选取或者使用匿名组密度中心的方式.为了保证锚点信息的安全性和可信度,本文采用基于历史用户的锚点生成算法来计算得到锚点信息.通过聚类算法得到历史用户分布密集的区域,对聚类结果的位置进行权重的计算,选择权重高的位置信息作为候选结果返回给用户.
定义 1.ε邻域 对于xi∈D,D为样本集(x1,x2,…,xm),则xi的邻域Nε(xi)为样本集中与xi距离不大于ε的样本子集,即
Nε(xi)={xi∈D|distance(xi,xj)≤ε}
(1)
定义 2.核心点与边界点 对于任一对象xi∈D,给定一个整数MinPts,若在其ε邻域中至少有MinPts个对象,即|Nε(xi)|≥MinPts,则称xi为核心点.若一个对象不是核心点但在某个核心点的ε邻域中,则称该对象为边界点.
定义 3.簇与噪声点 将距离在MinPts内的所有核心点连接,这些核心点与隶属于其ε邻域内的边界点构成一个簇.不在任何簇内的对象为噪声点.
当CS接收到用户的请求信息Qc={Ldc,η,ε,MinPts},其中Ldc为匿名组密度中心的位置信息,η为区域半径,ε为邻域半径,MinPts为邻域密度阈值,通过调用锚点生成模块产生用户所需的锚点信息.在具体的实现中,CS采用DBSCAN算法[20]对匿名组的最小匿名区域进行基于历史用户位置信息的聚类处理.首先,CS根据用户请求中的Ldc及η计算出匿名组的最小匿名区域MinArea.根据ε以及MinPts在最小匿名区域MinArea进行基于历史用户位置信息的聚类.对最小匿名区域内的历史用户位置数据点进行遍历分类,得到核心点,边界点和噪声点.在删除噪声点后,将距离在MinPts内的核心点连接形成一个簇,将每个边界点指派到一个与之关联的核心点的簇中.
针对于实际路况的聚类结果,对簇中的道路进行选择,如果该道路只有唯一通路,则不做改变;若存在其他的通路则选取其中唯一通路的一段使其满足泊松分布.对选取的道路上的位置进行用户停留数X大于XT的概率P(X>XT)计算,计算公式如(2)所示,
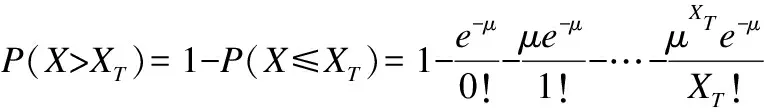
(2)
所以某个位置Pi的权重值I(Pi)如公式(3)所示,
I(Pi)=U·P(X>XT)
(3)
其中U为Pi所在的道路所具有的权重,如公式(4)所示,
(4)
其中R(vi)为道路顶点vi的访问频率权值,degout(vi)为输出度.
最后CS将权重值高的位置信息返回给用户作为其锚点信息.
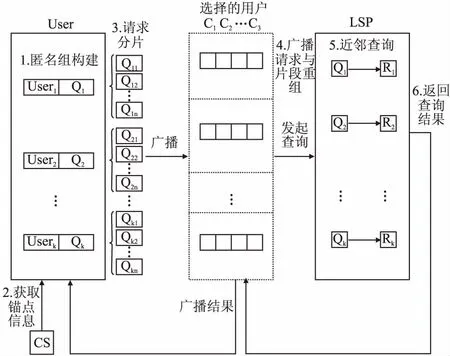
在用户接收到CS返回的结果之前,用户需要设定一个安全距离SD用于表示锚点距离用户真实位置的最短距离.在接收到CS返回结果后,分别计算这些锚点与用户真实位置的距离dis,选取其中dis>SD且距离用户真实位置最近的锚点信息.如果所有的dis 基于查询分片用户协作的位置隐私保护方法处理主要分为6个步骤:匿名组构建、获取锚点信息、请求分片、广播请求与片段重组、位置近邻查询以及返回结果和过滤,如图2所示. 图2 基于查询分片用户协作的位置隐私保护方法流程图Fig.2 Flow chart of location privacy protection method based on query fragment and user collaboration 步骤1.匿名组构建 首先,不在任何匿名组内的移动用户rq发起成立匿名组的请求广播,然后通过广播FROM_GROUP消息来发现邻居节点,其中FROM_GROUP为 步骤2.获取锚点信息 当用户rq完成匿名组的建立后,向CS发送一个获取锚点的请求Qc,CS接收到请求后通过锚点生成模块生成用户所需的锚点信息返回给用户. 步骤3.请求分片 首先用户rq在返回的锚点信息中选取合适的锚点后确定分片数N,然后在返回的邻居节点集合中随机选取与分片数N相同数量的邻居节点{p1,p2,…,pN}用于发送消息片段集合.然后将这些信息及锚点信息一起广播给匿名组内的其他用户.接着根据3.2中设置的数据安全等级以及分片规则将用户的查询请求Ql进行分片,处理流程如算法1所示. 算法1.数据切片与加密 输入:用户的查询请求 输出:加密后的请求片段 1.//请求用户rq 2.Determine(N) // 确定分片数N 3.广播分片数N与随机选取的用户{p1,p2,…,pN} 4.自定义切片规则ShardRules() 5.For(i=0;i 6. SLD(Qli) //设置请求内容的安全等级 7. {Qli1,Qli2,…,QliN}←ShardRules(SLD(Qli)) //对查询请求进行分片 8.Endfor 步骤4.广播请求与片段重组 当用户完成查询请求内容的分片加密以后,将分片后的请求片段分别发送给随机选中的邻居节点.待选中的邻居节点收集完所有用户的请求片段后,就将这些消息片段集FS={q1′,q2′,…,qk′}连同切片数量N一同发送给位置服务器.LSP需要设置一个等待时间wait_time,如果在该时间段内收集到全部的请求片段,则根据每个用户的唯一标识ID进行请求片段的重组.如果在该时间段内没有收集到全部的请求片段,则丢弃所有收集的请求片段并发送消息请求用户重新发送.处理流程如算法2所示. 算法2.广播请求与消息重组 输入:用户的消息片段 输出:用户的完整查询请求 1.//邻居节点 2.Collection(FS) //收集其他节点发送过来的请求片段 3.If(FS.num==k) 4.send(FS) //将收集到的请求片段发送给LSP 5.Endif 6.//LSP 7.If(CollectionTime 8.For(i=0;i 9.If(FS.gid==gid) //请求片段是否来自同一个组 10. {Ql1,Ql2,…,Qlk}←Restruct(FS) //进行请求片段的重组 11.Endif 12.Endfor 13.Else 14.get_FS_again() 15.Endif 步骤5.位置近邻查询 当LSP完成用户请求片段重组后,根据用户的锚点信息以及请求内容采用位置近邻查询处理算法在数据库中将最近的n个兴趣点按距离锚点位置大小进行排序后加入到数组W[n]中,然后将用户唯一标识对应兴趣点返回给用户端.如果用户收到的数组中没有满足条件的,那么就扩大搜索范围,在原来的基础上继续搜索最近的m个兴趣点返回,直到用户找到离真实位置最近的兴趣点[21]. 步骤6.返回结果和过滤 当发送请求的用户接收到位置服务器返回的结果集后,将对应的结果集返回给具体的用户.用户对数组中的兴趣点进行比较,当满足dist(pi,wi)+dist(pi,q)≤dist(q,wi+1)条件时,表明在该数组中第i个兴趣点是离用户真实位置最近的.处理流程如算法3所示. 算法3.返回结果与过滤 输入:LSP返回的查询结果 输出:距离用户最近的兴趣点 1.//移动用户rq 2.根据用户的唯一标识广播兴趣点 3.get(W[n]) //获取返回的兴趣点 4.For(i=0;i 5.If(dist(pi,wi))+dist(pi,q)≤dist(q,wi+1) 6.W[i]为离用户真实位置最近的兴趣点 7.Else 8.get_again(W[n]) //重新获取W[n] 9.Endif 10.Endfor 本节主要从用户、CS和LSP三部分来分析基于查询分片用户协作的位置隐私保护方案的安全性. 情况3.用户与CS之间的安全性.在本文的模型中,CS主要用于构建用户查询过程中的锚点信息.用户发送给CS的请求中只包含匿名组密度中心的位置信息、区域半径η、邻域半径ε和邻域密度阈值MinPts,请求内容不涉及到用户的具体隐私信息.即使CS受到攻击,攻击者也无法获取到用户的隐私. 本文的算法采用Java实现,在i7 3.60GHz处理器、8G内存Windows7的平台上运行.实验的数据集采用Thomas Brinkhoff路网数据生成器[22]生成,它以城市Oldenburg的交通路网作为输入,生成模拟移动用户数据.实验中使用数据的默认参数值如表2所示. 表2 默认参数Table 2 Default parameters 4.2.1 基于匿名参数k变化的性能比较 本实验使用Oldenburg数据集评估匿名成功率、平均响应时间和近邻查询结果集3个参数随匿名参数k增加的变化情况,并与Coprivacy[14]系统中的各个结果进行了对比. 图3 匿名参数k的影响Fig.3 Effect of anonymous parameter k 在其他参数保持一致的情况下,将本文中的系统与Coprivacy中的方法在匿名参数k变化的情况下进行比较,k数值范围为5至25之间.由图3(a)可知,本文系统和Coprivacy的匿名成功率都随着k值的增加而有所降低,因为在移动用户人数保持不变的情况下匿名需求k的值增加导致匿名成功率下降.本文模型的匿名成功率高于Coprivacy模型,原因是本文对最小匿名区域进行了调节.由图3(b)可知随着k值的增加,两个系统的平均响应时间都在变大且本文系统的平均响应时间略高于Coprivacy,因为在本文的系统中需要将请求进行分片和重组处理.随着匿名参数k值的增加,近邻查询结果集的大小呈现增长的趋势,且本文查询结果集相比Coprivacy更小,因为本文采用的方法不需要将查询结果与所有结果进行比较,可以就前面的节点尽快找到最近的节点,所以查询效率更高,如图3(c)所示. 4.2.2 基于移动用户数量变化的性能比较 在其他参数保持一致的情况下,将本文中的系统与Coprivacy中的方法在移动用户数量变化的情况下进行比较,移动用户数量范围为1000至9000之间.由图4(a)和图4(b)可知,本文系统和Coprivacy的平均响应时间和平均通信量都随着移动用户的数量的增加而减少且趋于相近,因为随着移动用户数数量的增加,单位区域内的密度增加,形成匿名组的速度提高以及形成匿名组过程中所需要的通信量不断减少. 图4 移动用户数量的影响Fig.4 Effect of the number of mobile users 4.2.3 查询半径和切片数量对于系统性能的影响 实验观察查询半径r以及用户分片数量N对于本文系统平均响应时间以及整个过程中的平均通信数量的影响.由图5(a)和图5(b)可知,平均响应时间以及平均通信消息数量都随着r和N的增加而增大.这是因为随着查询半径的增加,形成的查询范围也就越大,其所需的时间开销以及通信开销也就越大.而随着分片数N的增大,用户将请求信息切分成的消息片段也就越多,需要发送的用户也就越多,所以系统所需要处理的时间开销和通信开销也随之增加. 图5 查询半径的影响Fig.5 Effect of query radius 4.2.4 移动用户数量和切片数量对于系统性能的影响 实验通过观察移动用户数量以及用户分片数量对于本文系统平均响应时间以及整个过程中的平均通信数量的影响.由图6(a)和图6(b)可知,随着系统中移动用户数量的不断增加,用户查询的平均响应时间和平均通信量都逐渐减少,这是因为随着移动用户数量增加,单位区域内的用户密度增大,系统形成匿名组的时间不断减少,用户在形成匿名组过程中所需要的通信量不断减少. 图6 移动用户数量的影响Fig.6 Effect of users 本文提出一种基于查询分片的用户协作位置隐私保护方法,该方法在分布式移动点对点(P2P)的基础上,通过将完整的请求信息分片处理,将请求信息根据用户设置的安全等级划分为一系列的请求片段,将请求片段随机发送给匿名组内的其他用户,待收集到匿名组内全部用户的请求片段以后再发送给LSP服务器.服务器端在k匿名的保护下无法准确区分具体用户的请求信息,从而起到保护了用户的隐私安全的目的.但该方案也存在不足之处,由于需要将用户的完整的请求信息进行分片和重组处理,增加了该系统的时间开销以及通信开销.所以在未来的工作中我们将在保护用户隐私信息的前提下,降低系统的整体开销方面进行深入的研究.3.5 方案流程
3.6 安全性分析
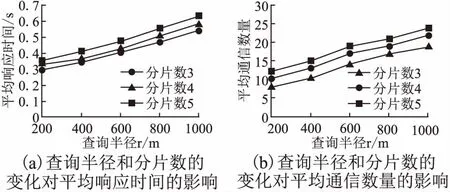
4 实验及结果分析
4.1 实验环境

4.2 实验结果分析



5 结束语
猜你喜欢
词学(2022年1期)2022-10-27农业工程学报(2022年14期)2022-10-19
——《艺术史导论》评介美育学刊(2022年5期)2022-10-18电子科技大学学报(2022年3期)2022-05-28数字技术与应用(2020年12期)2021-01-22移动通信(2020年5期)2020-06-08计算机技术与发展(2020年3期)2020-04-09中国计算机报(2018年12期)2018-10-08卷宗(2015年12期)2015-01-07网络与信息(2009年4期)2009-04-26
