
基于回归的抽取式摘要模型
2019-05-16 01:40赵怀鹏车万翔
智能计算机与应用 2019年2期
赵怀鹏,车万翔,刘 挺
(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)
0 引 言
随着互联网的迅猛发展,信息量正以指数级别在积累和增长。而摘要则能以精炼的文字帮助人们在海量数据中快速获取自己需要的信息。但鉴于目前信息量潮涌般的生成态势,故而亟需研发一套自动摘要系统来为文本自动总结重要信息,从而快速获取想要的信息。
摘要算法大致可以分为2个类别:抽取式摘要和生成式摘要。近年来随着深度学习的日趋成熟,尤其是随着 sequence to sequence[1]的提出,生成式摘要方面涌现出数目可观的研究成果。而抽取式摘要却因其简单,低成本,能够生成逻辑连贯的摘要等优势,仍然具有重要的研究价值。本课题的目的即旨在设计构造一套抽取式摘要系统。
研究可知,传统的方法大多是利用无监督学习来得到文本的摘要。代表性的研究有:向量空间模型(the vector-space methods)[2-3]、基于图的模型(the graph-based methods)[4-5]、组合优化方法(the combinatorial optimization methods)[6-7]。 这些方法依赖大量手工设计的特征来建模句子或篇章,例如位置信息,TF-IDF等。
近些年,神经网络吸引了学界的高度关注,而Hinton等人[8]发表了优化深层网络的方法后,随却就陆续见到了许多基于神经网络的抽取式摘要工作。这些工作均是将抽取式摘要任务看作序列标注任务。分类的类别有两类:0代表不是摘要,1代表是摘要。具体来说,Cheng等人[9]提出了基于sequence to sequence框架来进行句子分类。Singh等人[10]对篇章表示层进行了优化。同时,基于分类的方法也呈现出一定的弊端与缺陷。Nallapati等人[11]就提出了基于循环神经网络(Recurrent Neural Networks)的分类模型。首先,在训练过程中,将该任务当成序列标注来建模,但在测试的时候是根据分类概率大小来选择最优的几个句子。这就导致了训练和测试存在不一致性的问题。其次,标注为1的句子间也不能区分各自的重要程度。综合前文分析可知,本文则有针对性地研发提出了基于神经网络的回归模型来解决上述问题。
1 基于回归的抽取式摘要模型
1.1 分类模型存在问题及分析
最近几年展开了基于序列标注的神经网络来建模抽取式摘要的研究。这种利用交叉熵来优化与标准答案的最大似然方式并没有在训练过程中考虑排序句子。摘要任务的本质是对句子进行排序,然后选择排序靠前的几个句子。基于分类的模型在训练目标中却忽略了这一点。而且,摘要的分类数据集常常是利用人工摘要通过一定规则得到句子的分类标签。这样就会导致正例的个数过多,模型容易过拟合,而且仅是利用模型也无法区分相同标签的不同句子间的重要程度。
1.2 回归模型概述
给定一篇文章D,其中包含句子序列{x1,x2,…,xn}。 抽取式摘要系统的目的就是要从D中选择m个句子组成摘要S(其中m<n)。对于每个句子si∈D,研究对其预测一个分数scorei。在训练时通过回归损失函数来优化网络。在测试时,对于每个句子si都会预测一个分数,即:
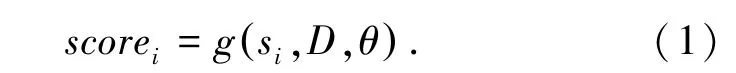
此后,将选出scorei最大的m个句子作为摘要。
基于回归的抽取式摘要模型的过程结构设计如图1所示。基于回归的抽取式摘要模型一般通过一定的规则来给每个句子打分。例如Ren等人[12]就利用当前句子与人工摘要的ROUGE值以及句子间的ROUGE值来为每个句子打分。在训练的过程中,该模型通过计算当前句子与篇章表示的相关程度和句子间的相关程度来为每个句子评判打分,通过网络训练让模型分数接近正确的分数。测试时,会给每个句子进行评分,然后选择分数最大的作为最终求得的摘要。基于回归模型的优势是分数能够更加精确刻画句子的重要程度,并以此作为依据来进行句子间的排序。另外,在构造分数的时候就考虑到了最终的评价指标ROUGE[13],因此会更加合理。

图1 回归模型结构图Fig.1 The structure of regression model
1.3 基于神经网络的抽取式摘要模型
本文中的句子和篇章的表示层利用了Yang等人[14]提出的 Hierarchical attention networks。 如图2所示,该结构分为3层:输入层、句子表示层和篇章表示层。该模型的设计初衷是用于篇章分类(document classification),而本次研究则将其用于抽取式摘要系统的表示层。
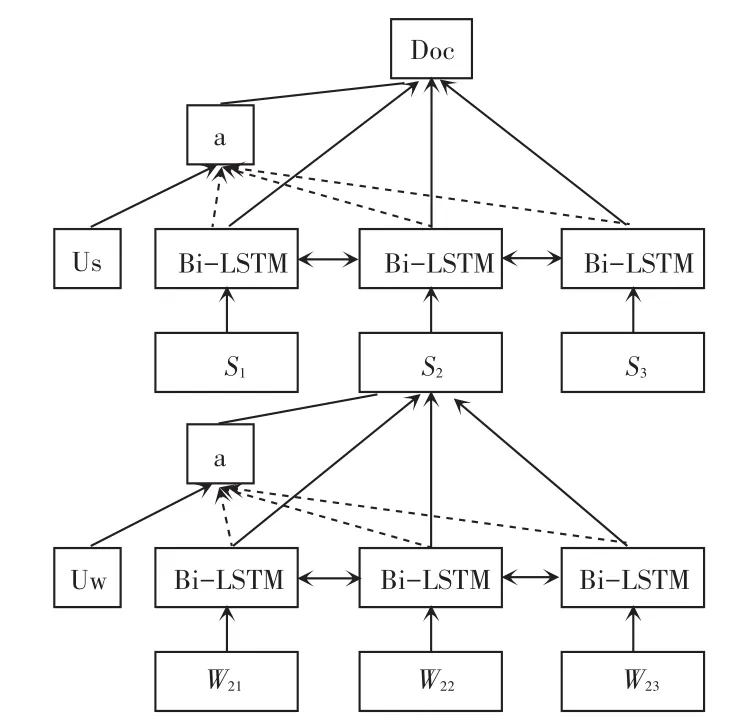
图2 层次化注意力网络Fig.2 Hierarchical attention networks
本次研究的输入层采用了100维的词向量,而选择了训练词向量的工具是word2vec[15],过程中训练词向量用到的训练数据是 CNN/DailyMail[16]数据集里面所有的文本。继而,文中设置的最小词频阈值为8,这样就可得到154 K的词汇。Skip窗口大小设置为5,hierarchical softmax的层数也是1。
同时,对于句子表示层和篇章表示层,研究采用了Bi-LSTM。LSTM中包含3个门:输入门(input gate)、输出门(output gate)和遗忘门(forget gate),如图3所示。
在得到LSTM的隐层输出之后,研究利用Attention[17]机制得到每个词或者句子的权重。设计时,计算Attention的向量是随机初始化,并通过网络学习进行更新。以篇章表示层为例,假设ht为第t个句子的表示,Us是计算Attention的向量。那么两者分数计算方式可表述如下:
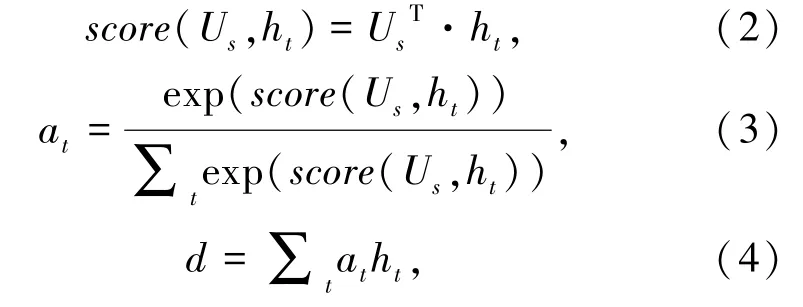
其中,d就是研究中最终的篇章表示,ht就是求得的句子表示。

图3 LSTM Cell结构图Fig.3 The structure of LSTM Cell
在此基础上,研究推得的最终回归模型的打分函数将可写作如下形式:

接下来,通过计算当前句子si与人工摘要Sref的ROUGE-2F1值就可得到标准分数,其数学公式可表示为:

在得到了篇章表示后,就可以定义损失函数如式(7)所示:

2 实验结果与分析
2.1 基本设置
词向量维度为100维,句子表示层和篇章表示层Bi-LSTM的维度为200维。训练采用的优化器为 Adam,初始学习率为 0.001。 Batch size为 20,随机种子设为1,训练迭代了10轮。
研究对每篇文章进行了预处理,去除了文章日期,作者信息等。同时对所有单词做了小写化处理。为了降低时间和计算资源开销,同时还设置每篇文章最多100个句子,每个句子最多50个词,如果超过就进行截断。而在研究句子级别表示层时,选取一个batch中所有篇章词数最多的句子(超过50的按照50计算)作为padding的基准,词数未达此标准的句子增补若干个100维的0向量。在篇章表示层中,选取一个batch中篇章句子数最多的篇章(超过100的按照100计算)作为padding基准,句子数不够的予以补0向量处理。
2.2 数据集
实验用到的数据集是CNN/Daily Mail数据集。数据的内容是CNN和Daily Mail发布的新闻数据,每篇文章包含标题名称、正文和人工摘要三个部分,样本示例见表1。该数据集最初是由Hermann用于完成阅读理解任务。后来Cheng等人[9]将其作为抽取式摘要的数据集。由于数据集的规模较大,在近段时间内已被广泛应用到文本摘要任务中。数据集的规模统计参见表2。

表1 数据集样本示例Tab.1 Sample of the dataset

表2 数据集规模统计Tab.2 The statistics of dataset
实验中,重点选用了Daily Mail数据集,因为近年来的大部分工作都在Daily Mail数据集上提交了结果,因而有利于后续的实验结果对比。Daily Mail数据集中每篇文章的平均句子数为25.6,人工摘要的平均长度在3~4句的范围内。
2.3 评价指标
早期,传统的摘要评价方式一般都包含人工的评分函数,包括语法、可读性、内容、一致性等。这些简单的人工评价规则能够较好反映摘要的质量,但是需要消耗大量的人力去进行评估。Lin[13]提出ROUGE(Recall-Oriented Understudy for Gisting Evaluation)用来评价摘要的质量,并和人工评价有着很强的一致性,目前即将其作为一种常用的摘要评价指标。分析可知,常用的评价指标有ROUGE-1、ROUGE-2和ROUGE-L。 前两者分别计算了uni-gram和bi-gram的覆盖度,表示了涵盖的信息量,后者计算了最长公共子序列(longest common subsequence)的覆盖度,描述了生成摘要的流畅程度。ROUGE-N和ROUGE-L可由如下公式计算得出:
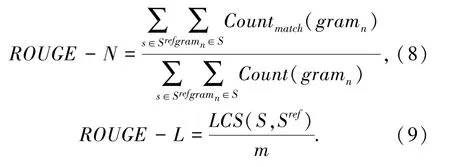
2.4 实验结果
本次研究中的baseline模型是Lead-3,且只取文章中前3句话作为摘要。另外,研究中还对比了文献[9]和文献[11]中的仿真结果。这里,即研究给出了不同长度限制下的实验结果详见表3、表4。

表3 DailyMail测试集75 bytes下ROUGE RecallTab.3 75 bytes ROUGE Recall of DailyMail test set

表4 DailyMail测试集275 bytes下ROUGE RecallTab.4 275 bytes ROUGE Recall of DailyMail test set
由表3、表4的实验结果来看,本文的模型在生成短摘要时,效果上要明显优于其它的抽取式摘要模型。在生成长摘要时,效果也能和SOTA相当。
3 结束语
本文分析了利用分类来做抽取式摘要的问题,并设计提出了一个基于神经网络的回归模型。结果表明,本文研发的模型不依赖任何手工设计的特征。而且,在DailyMail数据集上,研究提出的模型在不同长度限制下都取得了不错的效果。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年24期)2019-02-23
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
