
分布式系统中失效检测器综述
2019-05-16 01:40刘家希吴智博温东新
智能计算机与应用 2019年2期
刘家希,吴智博,董 剑,温东新
(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)
0 引 言
分布式系统(Distributed System)是一个硬件或者软件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统[1]。目前,分布式系统可以说是无所不在,无论商业、学界、政府部门或者是家庭之中均能看到其身影。这些分布式系统提供共享资源、共享数据的技术手段,在这个信息化的时代是极其重要的[2]。然而,随着分布式系统规模的不断增长以及复杂性的不断增加,由于各种原因造成的软硬件失效已然不可避免,这就在相当程度上决定了分布式系统可用性的好坏。容错技术是分布式系统中保证高可用性的有效方法[3],可以使系统在有部分硬件或者软件发生失效的情况下,仍可作为整体能够正常运行并完成其设计功能。而失效检测器是容错技术实现的前提,通过周期性地探测系统中节点的状态,可以为系统容错提供良好的信息支持。因此,失效检测器的性能直接影响分布式系统的正常运行。
目前,失效检测器的研究主要集中在失效检测器理论模型与失效检测算法的实现两个方面。总地来说,在失效检测器理论模型方面,Chandra等人[4]首次提出了失效检测器的理论,并且根据完整性与准确性定义了8种类型的失效检测器,同时指出了解决分布式一致性问题最弱的失效检测器模型。在此基础上,陆续有学者针对不同的分布式系统模型提出不同能力的失效检测器模型。而在失效检测器的实现方面,针对失效检测所面临的检测准确性、速度以及负载的矛盾,自适应失效检测器和基于结果共享机制的失效检测器也屡获提出,并相继问世。这些失效检测器以不同的侧重点解决了实际分布式系统中对失效检测服务的需求设计问题。
本文以失效检测器的实现为重点分析对象,并将从如下方面展开论述:首先,提出失效检测器定义、实现以及服务质量评价指标。其次,研究了不同种类的失效检测器。最后,对分布式系统中失效检测器做出总结与展望。
1 失效检测器模型
1.1 失效检测器定义
Chandra等人[4]最早提出了失效检测器的理论。在该理论中,分布式系统中每个节点都有一个本地的失效检测器,用于检测系统中的部分节点并且维护一张怀疑节点发生失效的列表。失效检测器可能会错误地将正常运行的节点加入到怀疑列表中,但当发现错误怀疑时,又可以把该节点从怀疑列表中直接删除,这个过程可以重复进行。任意2个节点的失效检测器对相同的节点可能有不同的检测结果。
失效检测器形式化的定义可表述为:在一个由n个节点组成的分布式系统Π中,F被称为失效模式,F:T→2Π。其中,T是全局时钟到自然计数的一个映射。 对于Π中的节点p,则用crash(F)=Ut∈TF(t)定义发生失效的节点集合,correct(F)=Π-F(t) 定义被判断为正确的节点集合。
一个失效检测器(Failure Detector,FD)可视作为一组失效检测模块的集合,分布在系统的每一个节点上,而失效检测器的输出就是被怀疑发生失效的节点的集合,可以用H来表示,Π×T→2Π,H(p,t)则表示节点p在t时刻所认为发生失效的节点集合。
1.2 失效检测器的实现
当前失效检测方法的实现大多数都是基于心跳机制的。通过判断被检测节点发出的消息能否在规定时间内到达,从而判定被检测节点是否发生失效。按照实现方式的不同,可以分为 PUSH模型[5]和PULL模型[1],其它的失效检测方法都是建立在这2种失效检测方法之上。现对这2种方法将给出如下阐释与分析。
(1)在基于PUSH模型的失效检测方法中,被检测节点是主动的参与者,检测方法的基础工作方式如图1所示。由图1看到,被检测节点p周期性地发送“I am alive”消息到失效检测器,这种消息也称为心跳消息。失效检测器会设置一个超时值Δt,如果失效检测器在超时值Δt前没有收到被检测节点发送的消息,则怀疑被检测节点发生失效。由于PUSH模型在系统内是单方向的消息传输,使其可获得较高传输效率。同时如果被检测节点有多个检测者,可以使用硬件的多播机制来实现。但是,PUSH模型需要被检测节点维护本地时钟以便周期性地发送消息。
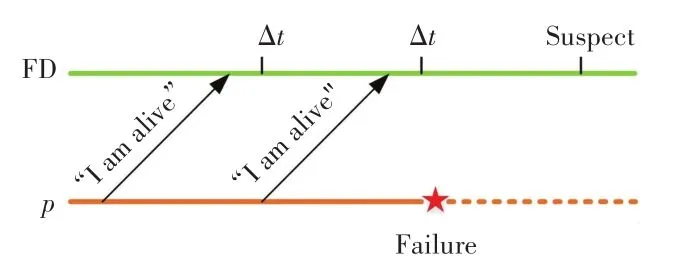
图1 PUSH模型Fig.1 PUSH model
(2)在基于PULL模型的失效检测方法中,被检测节点是被动的参与者,检测方法的基础工作方式如图2所示。失效检测器周期性地发送“Are you alive”查询消息到被检测节点,并且设置一个超时值Δt。 如果被检测节点在超时值Δt前回复应答消息“Yes”,则失效检测器判定其处于正常状态;否则,失效检测器怀疑其发生失效。由于被检测节点在PULL模型中是被动参与者,所以失效检测器更容易实现。而且,这些被检测节点只需要在有询问消息时做出反应,不需要为了定期发送消息而维护当地时钟,可以在异步计算环境下运行。但是,采用PULL模型的失效检测方法所需检测消息是PUSH模型的2倍。
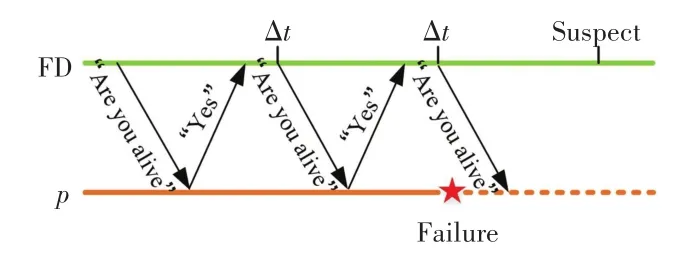
图2 PULL模型Fig.2 PULL model
1.3 失效检测器的服务质量
许多实际应用对失效检测器所提供的节点怀疑信息有诸多限制,而且也无法接受过慢的或者输出错误太多的失效检测服务。针对这个问题,Chen等人[6]在失效检测器理论模型的基础上,提出了一套失效检测器服务质量(Quality of Service,QoS)的评价指标体系,可以对失效检测器性能进行定量评价。这套指标体系主要描述失效检测器发现真实失效的速度以及避免错误怀疑的概率两个方面。
为了理解Chen所创建的定量评价指标体系,需要明晰一些QoS关键指标含义。其中,T表示失效检测器认为被检测节点处于正常状态,S表示失效检测器认为被检测节点处于失效状态。T-transition表示失效检测器的输出结果由S变成T,S-transition表示失效检测器的输出结果由T变成S。详情表述见如下。
(1)检测时间TD:从节点发生失效的时刻到该节点被失效检测器永久怀疑所持续的时间。也可以说,TD表示节点发生失效的时刻到最后一个S-transition发生的时刻(以后不会再发生transition)之间持续的时间,如图3所示。
(2)错误间隔时间TMR:失效检测器连续2次发生错误怀疑的间隔时间。也就是说,TMR表示从一个S-transition到下一个S-transition所经历的时间,如图3所示。

图3 QoS指标Fig.3 QoS metrics
(3)错误持续时间TM:失效检测器改正一次错误怀疑所经历的时间。也就是说,TM表示从一个S-transition到下一个T-transition所经历的时间,如图3所示。
2 失效检测器的分类
失效检测器不仅需要保证基本的失效检测能力,也需要能够保证失效检测能力在可接受的服务质量范围内。随着大规模分布式系统的发展,就需要检测大量的节点,较高概率的消息丢失、不断变换的系统拓扑以及消息延迟的不可预测性等问题不断涌现。这些情况对于研究开发高效的失效检测器提出了巨大的挑战,加剧了失效检测有效性(失效检测准确性和失效检测速度)和失效检测所需负载的矛盾。而自适应失效检测与结果共享机制是当前解决这一问题的主要途径。因而围绕这2个方面,针对当前大规模分布式系统失效检测技术的研究可做综合分析与详述如下。
2.1 自适应于网络环境的失效检测器
在早期的自适应失效检测器的研究中,通过调整心跳消息发送间隔η和超时值Δt来适应网络环境的变化,从而在一定检测速度的约束下,尽力提高检测准确性。例如,Sotoma等人[7]提出了一种基于MEAN超时值预测方法的自适应失效检测器,并且在CORBA系统中实现了这种自适应失效检测器。这种失效检测器使用心跳传输时间的平均值作为超时值Δt的预测值,可以周期性地调整超时值Δt,从而达到了自适应失效检测设计效果。Fetzer等人[8]提出了另一种基于MAX超时值预测方法的自适应失效检测协议,通过利用历史心跳消息的传输时间最大值作为超时值Δt的预测值,可以有效地改善失效检测准确性。Falai等人[9]对这些超时值预测方法进行了总结与归纳,选取出5种超时值预测方法:LAST、MEAN、 WINMEAN(N)、LPF(β) 以及 ARIMA(p,d,q),分别为其配以不同的安全边界(SMCI和SMJAC),并通过实验的方法对其性能进行评价。实验结果表明,ARIMA(p,d,q)方法具有较高的预测准确性,而具有较低算法复杂性的LAST方法结合SMJAC安全边界则获得了最快的检测时间以及较好的检测准确性。
上述这些方法对QoS的研究都停留在定性的阶段,并不能够精确地描述失效检测器所能满足的QoS,而且用户也不能对失效检测器提出定量的QoS需求。针对这一情况,Chen等人[6]提出了一整套失效检测器的QoS评价指标体系。这套QoS指标体系主要是对失效检测器的检测速度以及准确性的衡量,实现了对失效检测器的检测能力的定量的评价。同时,基于以上QoS指标,Chen等人提出的自适应失效检测器NFD-E可以根据用户或者应用给定的QoS需求,自动地调整检测参数,从而以最小的检测负载获得定量的QoS指标。针对NFD-E检测器检测速度的问题,Bertier等人[10]提出了一种基于动态安全边界的失效检测器。这种失效检测器利用Jacobson的往返时间(round-trip time,RTT)来对安全边界进行估计,使其可以随网络环境的变化进行动态改变,此方法明显地降低了Δt值,提高了检测速度。但是,这种改进后的NFD-E检测器在检测速度提高的同时带来了更多的错误检测。针对NFD-E检测器检测准确性的问题,Tomsic等人[11]提出了一种基于双窗口的失效检测器2W-FD。这种失效检测器使用2个不同尺寸的滑动窗口存储历史心跳消息,分别计算超时值,从结果中选取较大的值作为最终的超时值,这种方法可以捕获更多的心跳消息,从而提高检测准确性。实验结果表明,在不稳定的网络环境下,2W-FD检测器能够获得更高的检测准确性。
在大规模分布式系统中,尤其是部署大量不同类型分布式应用的系统,失效检测器仅提供单一的QoS已经不能满足应用的需求。Défago等人[12]提出的新的失效检测器模型—Accrual检测器,可以同时满足大规模分布式系统中多个应用不同的QoS需求。该次研究将传统失效检测器模型中的监测权与解释权相分离。Accrual检测器只负责对节点进行监测,与此同时还将输出一个代表被检测节点怀疑程度的连续值(也称为怀疑值,slqp(t)),而不再直接输出相信或者怀疑的二值性检测结果。不同的应用根据自身QoS需求对此怀疑值做出解释,从而决定被检测节点的状态。
φ检测器[13]是Accrual检测器的首款设计,如图4所示。通过设置滑动窗口存储来自被检测节点的心跳消息,然后假设这些心跳消息的到达时间间隔符合正态分布,从而根据累积分布函数F(t)计算怀疑值φ。应用程序可以在任意时刻tnow发起查询,会收到检测器返回一个φ值,最终通过φ值与应用程序设定的阈值的比较结果确定被检测节点状态。φ检测器的实现满足了应用程序对失效检测服务的多样化需求。
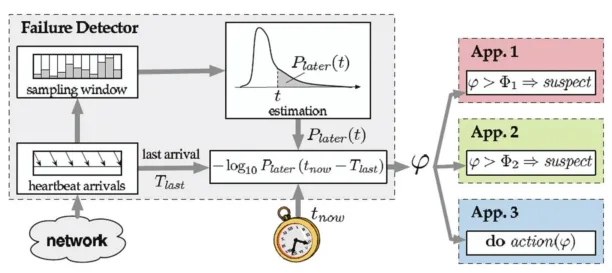
图4 φ检测器Fig.4 φ failure detector
Xiong等人[14]指出指数分布更加适合于描述心跳消息到达时间间隔,从而利用指数分布计算怀疑值。Lakshman等人[15]将这种基于指数分布的Accrual检测器应用于著名的社交网站Facebook的P2P存储系统Cassandra中,获得了良好的失效检测性能。
同时,也陆续推出了一些基于其它方法处理心跳消息的 Accrual检测器的研发实例。Satzger等人[16]提出了一种低开销的Accrual检测器的设计,利用直方统计图计算怀疑值,通过直接分析检测消息延迟的历史记录,计算延迟小于当前检测时间的消息所占的比例,以此为基础计算怀疑值。He等人[17]提出的Accrual检测器则引入了指数移动平均算法,利用心跳消息到达时间间隔与间隔预测值计算怀疑值。
2.2 检测结果共享机制
在节点检测层面,自适应失效检测可以解决检测有效性与检测负载之间的关系问题。然而从整个系统层面来看,如果每个节点都单独进行失效检测,那么在一个规模为n的系统中,至多需要产生n2个检测关系。这对于大规模的分布式系统而言,无疑会造成巨大的检测开销。因此,节点之间通过共享检测结果的方法降低检测开销,以期改善检测性能获得了广泛的研究。在众多方法中,基于层次式的检测方法和基于Gossip式的检测方法已成为学界瞩目焦点。对此内容详情可做研究评述如下。
(1)层次式方法。将系统中节点组织成树或森林的层次结构,然后依托这些特殊的结构建立失效检测关系,以达到降低系统检测负载,提高可扩展性的目的。一种典型的层次式结构即如图5所示。
Felber等人[18]提出了一种层次式的失效检测服务。在系统中,节点根据IP地址被划分到不同的子网中,每一个子网中的节点为一个分组,分组中选择一个主节点部署失效检测模块,负责对分组中其它节点进行检测。不同的分组之间可以通过主节点进行检测结果交换。这种方法易于管理,并且可以迅捷实现失效检测。但是,该方法却高度依赖系统拓扑结构,并不适合拓扑频繁改变的系统。
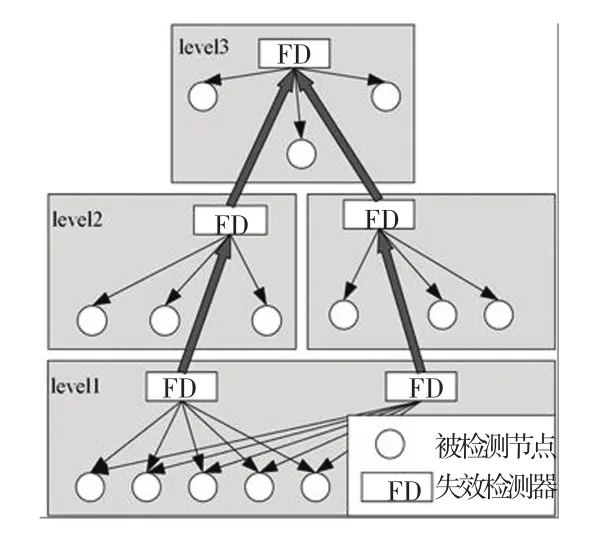
图5 层次式失效检测Fig.5 Hierarchical failure detector
Stelling等人[19]根据网格的架构特点,利用Globus toolkit工具包研发了一个类两层结构的检测协议。每台主机上安装一个本地检测模块,负责检测主机上运行的所有进程,不同主机上的检测模块会互相交换信息以获得检测结果的全面共享。这一协议适用于节点计算能力较强的系统,而且从节点层面看,这不是一种真正意义上的双层检测结构。而Bertier等人[20]提出了一种真正意义上的双层架构的检测协议。系统中所有节点被分配到不同分组中,每一个分组选择一个主节点部署失效检测器,负责检测组内的节点状态,而所有的主节点通过互相交换检测结果可形成全局检测信息。这种检测架构在整体设计上相对容易且效率较高,但是与多层结构相比,其对检测负载的改进没有多层结构明显。
(2)Gossip[21]。 本身是一种概率多播协议[22],可采用类似蠕虫病毒(rumor)的快速传播方式,通过多轮的消息交换以较低的代价实现消息的高效广播。Renesse等人[23]将Gossip这种协议引入到失效检测领域中,提出了2种基于Gossip式的失效检测器:基本Gossip检测器以及多层Gossip检测器。对于基本Gossip检测器而言,每轮检测中节点随机选择邻居节点进行检测并交换检测结果,通过数轮的交换可以获得系统中其它节点的状态。在这种检测器中,其检测负载与系统的规模以及拓扑结构无关,而其检测时间受算法随机性的影响,随着系统规模的增大,检测时间会呈现线性增长。针对这种情况,多层Gossip检测器也随即得以提出。借鉴层次式的检测思想,根据节点IP信息将系统中节点划分到不同的子网,大多数的Gossip消息在子网内传播,只有少数的消息可以跨越子网传播,实现全局的检测需求。在这种检测器中,其检测负载只和系统子网的数量相关,而与具体节点数量无关,拥有良好的可扩展性。然而,针对某一确定节点的检测时间至少需要O(logn)Tfail。其中,Tfail是对某一节点所允许的失效检测延迟。
虽然基于Gossip式检测方法在降低检测负载以及提高可扩展性方面具有优势,但是其所需检测时间仍然较长。为此,大量的研究集中在对检测时间的改进上。例如,Gupta等人[24]利用“再检测”机制实现的组成员协议SWIM。在SWIM协议中,节点q随机选择一个节点p进行检测,如果在规定时间内没有收到回复消息,那么节点q会随机选取k个节点再对节点p进行检测,最后根据这k个节点返回的检测结果对节点p的状态做出判断,以上设计过程如图6所示。这种方法可以有效地提高检测准确性,并且通过调整检测周期与协议参数改进检测时间。Snyder等人[25]将SWIM协议应用到大规模HPC存储系统,通过选取适当的协议参数以及检测周期,可以获得良好的检测性能。Horita等人[26]提出了类似方法,同样需要另外k个节点进行辅助检测,只是这种辅助检测是静态配置的,不需要动态发起过程,在提高检测准确性的同时进一步改善了检测时间。Ward等人[27]针对大规模云计算系统提出了一种多层的gossip协议。根据云计算系统架构,可将系统分为3层:云、分组以及虚拟机,在每个检测周期内,虚拟机选择同分组内其它虚拟机进行消息交换,其中一定比例的虚拟机会跨越分组、以及跨越云进行消息交换。这种方法可以利用实际系统不同层次所具有的不同通信延迟,实现快速的失效检测。
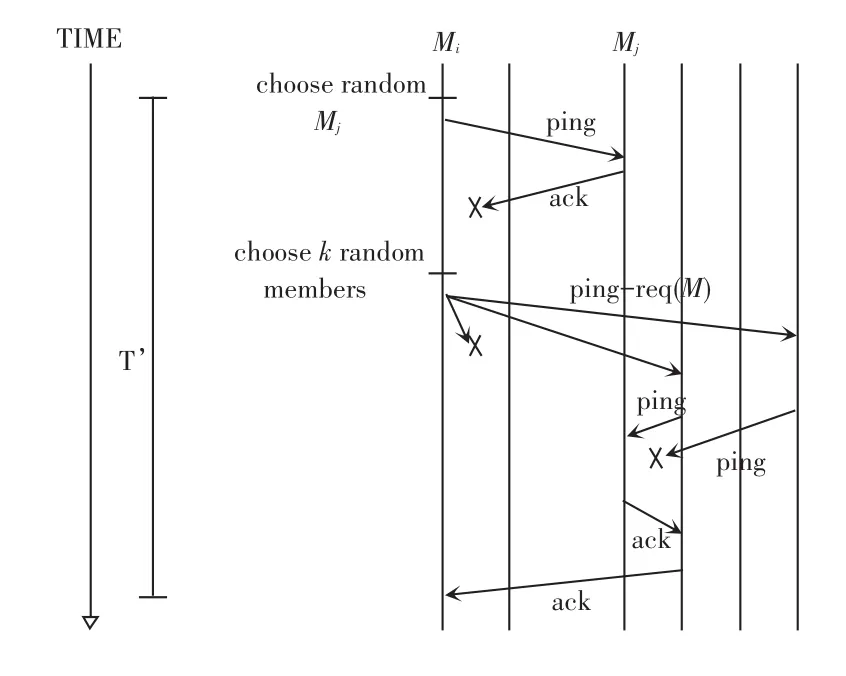
图6 SWIM失效检测器检测过程Fig.6 Process of failure detector in SWIM
3 结束语
失效检测器已经是构建高可用分布式系统的基础组件之一。失效检测器通过周期性地探测系统中节点的状态,不仅能够解决分布式系统中一些基础问题(例如,一致性问题,原子广播等),还能够为路由选择、负载均衡以及任务调度等发挥有益的支持作用。因此,失效检测器所提供的服务对分布式系统的性能有着重要的影响。自适应失效检测和检测结果共享机制是分布式系统中失效检测实现的主要方法,未来将深入研究如何降低检测负载,提高检测准确性以及检测时间。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
中国典型病例大全(2022年12期)2022-05-13
测控技术(2022年4期)2022-04-27
雷达科学与技术(2021年5期)2021-11-29
音乐研究(2021年3期)2021-08-04
建材发展导向(2021年10期)2021-07-16
西安电子科技大学学报(2021年2期)2021-04-30
东坡赤壁诗词(2021年1期)2021-03-24
文艺生活·下旬刊(2020年1期)2020-04-19
科技风(2018年15期)2018-05-14
