
基于密度自适应聚类数的社区发现谱方法
2019-05-17 02:51王学军李有红李炽平
计算机技术与发展 2019年5期
王学军,李有红,李炽平
(广东工业大学华立学院,广东 广州 511325)
0 引 言
社区结构是现实复杂网络中最普遍和最重要的中观结构。研究发现[1-2],在社区结构中,属于同一社区内的节点往往处于同一簇内,并且簇内节点连接紧密,簇间节点连接稀疏,簇间的边介数远远大于簇内部的边介数。自2002年Girvan M和Newman M E J[1]提出社区结构概念以来,社区结构发现算法就被广泛应用在蛋白网络、社交网络、协作网络、疾病传播网络、语义网络、电网网络、万维网络等领域的结构和动力学分析中。经过社区挖掘分析,可以揭示潜在的隐形规律,预测事物演化,控制意外发生等[1-3]。近年来,也涌现出了许多关于社区发现的方法,按数理方法分类主要有[2]:基于分裂的方法、基于合并的方法、基于模块度的方法、基于谱二分的方法、基于网络动力学的方法、基于统计推理的方法。
寻找复杂网络社区结构的最优划分是一个NP问题[4-5]。提升划分精度和计算复杂度仍然是各项研究的重点。谱聚类划分方法最早应用在模式识别中,主要用来实现图像数字媒体的聚类,其在有限时空范围内的计算精度有目共睹。近年来,在复杂网络社区发现领域已有多项关于谱聚类方法的研究,基于谱聚类的社区发现算法在小规模情况下是一种有效的方法[2]。相比传统单一的聚类算法,如k-均值聚类、减法聚类、峰值聚类等[5-7],谱聚类方法[7]在遇到非凸边样本数据时不会陷入局部最优和鲁棒性相对较差的困局,在聚类精度、整体性上都有上佳表现。目前比较经典的谱聚类社区发现方法,如NG算法[1]、NJW算法[8]、Nyström算法[9]等,都是通过样本数据构建相似矩阵后,对其进行拉普拉斯矩阵分解,再对分解后得到的特征向量进行经典k值聚类,最终实现社区结划分。但上述方法都依赖于预先设定的k值,而现实计算中,k值往往是未知的。
针对上述问题,提出一种基于密度自适应聚类数的社区发现谱方法。基于局部节点密度构图,结合网络图的边介数值构造相似矩阵,规范化后进行谱聚类,求得最大特征维度k,k值即为社区个数,最后采用k-means算法对特征向量空间进行聚类,使得复杂网络社区得以呈现。利用Newman提出的社区模块度评价函数[10]和文献[11]提出的重叠社区评价函数,与经典的社区发现算法(NG算法[1]、FN算法[11]、COPRA算法[12]、NJW算法[13])进行实验对比发现,该算法能更精确地构造相似矩阵,得到的仿真社区结构更接近真实。对多类别属性、多关系的数据集实验发现,该算法更适合多领域的聚类社区检测。
1 相关背景
复杂网络样本数据可以用图表示为G=(V,E),其中节点集V=v1,v2,…,vn,网络所有节点的边集E={eij|0 L=D-A (1) 规范化拉普拉斯矩阵定义为: (2) νi∈NK (3) 其中 (4) 传统谱聚类算法[5-7,9]都是根据预先输入聚类参数k,进行谱分解后,再运用k-means或FCM等经典算法进行聚类。而在实际应用中聚类参数k是很难预先确定的。为此,丁世飞等[13]对样本随机抽样后,利用矩阵低秩逼近方法求解相似的特征向量和特征空间得到近似k值的Nyström采样算法,但是抽样的随机性会对最终的聚类效果产生影响[14]。在传统NJW算法基础上提出的基于k近邻的自适应谱聚类快速FA-S[14]算法,虽然对聚类运算速度提高了不少,但依然需要事先给出样本的聚类数目。蒋盛益等[15]针对动态社区发现提出一种增量式的谱聚类自适应算法,提出的LLC和ADCD模型在动态社区发现中具有较好的效果,但该算法只是局限于无线同构的网络。 复杂网络数据相似特性包括[16]:局部高度相似,即样本数据节点在邻近节点上的数据是具有较高相似度的;全局相似,即样本数据节点在同一网络簇中或者同一流行上是高度相似的。基于此,提出基于密度自适应聚类数的重叠社区发现谱方法,思路如下: Step1:对样本数据节点进行密度计算,根据节点邻近局部密度的定义对样本进行排序,依次对节点进行连接完成样本的构图。 Step2:将构图中的边介数作为节点间的权值,构造相似矩阵,并找出第一个极大特征间隙的位置来确定类的个数。 Step3:利用k-means经典聚类算法对特征向量空间进行聚类。 定义:若样本数据中某节点νi与其所有的邻近节点的距离之和比其他节点都小,则该节点处于节点密集区。记节点νi与其邻近节点距离之和为Di。 Di=di1+di2+…+dij+…+dik (5) 其中,k为节点νi的邻近节点总数;dij为节点νi与节点νj的距离,按照距离的大小来排序为:di1≤di2≤…≤dik。 由定义可知Di的大小表示节点局部的稀疏层度,即Di越大,其周围分布的节点越多。 根据上述节点局部邻近密度的定义设计建模步骤如下: Step1:计算每个节点νi所有的邻近节点欧氏距离之和Di。 Step2:节点νi与k邻近节点连接所对应的邻接矩阵用P表示,如果节点νi与节点νj连接则Pij=Pji=1,否则为0,初始的值即顶点自身值设为-1,则邻接矩阵P可表示为: (6) Step3:求出最小的Di,即D(n)=min{Di,i=1,2,…,n},记num=1。 Step4:找到剩下的D(n-num)。 D(n-num)=min{Di,i=1,2,…,n-num} (7) D(n-num)对应的节点记为νx,统计其邻接矩阵中对应行中1的总个数m,然后将其与k-m个邻近节点相连,νx的邻近节点集合为{νxl,l=1,2,…,k},νxl为距离节点νx第l近的节点,记l=1,count=0。 Step5:若l≤k,做如下选择: (1)若νxl与已知νx连接,则l=l+1,循环执行Step5直到度值达到k为止,νxl与已知νx不连接,即对应邻接矩阵置0,否则对应邻接矩阵置1,且count=count+1,l=l+1。 (2)若count>k-m,则进入Step6,否则继续Step5。 Step6:如果num 上述样本构建的只是无向图,这里仍需对图的边赋予权值,使之变为加权网络。由于各领域样本数据的多样性,可能会出构建出多个联通子图,子图间的边介数较少就容易求解,但是难以求解子图内部的边介数。研究表明两个节点或子图之间的相似性具有传递性,即若Va≃Vb,Vb≃Vc→Va≃Vc,否则节点或子图不相似。为此给出定义: (8) 其中,Wuv表示任意两个节点u和v之间的值;min(eu→v)表示两点间最短路径的边数;∑Bu→v表示节点u和v之间最短路径上边介数之和。规定,两点间无连接,则权值为±∞,用来表示孤立节点或子图,若两个节点间的权值无穷大,则在接下来的相似矩阵中赋值为0,因为权值矩阵的对角线值为0,所以在相似矩阵中对角线的值为1。 根据式8得到权值矩阵后,再利用倒数的方式构建样本数据图的相似矩阵,公式为: (9) 从中可以看出,两个节点越是属于同一社区越相似,则相似矩阵中值越大。 Input:领域样本数据点V={v1,v2,…,vi,…,vn}和相关参数。 Output:社区划分结果C1,C2,…,Ck。 Step1:利用上述领域样本数据图的建模方法构建领域的相似图G。 Step2:对图G基于边介数先求出权值矩阵W,并利用式9构造出相似矩阵S。 Step5:将k个最大特征值所对应的特征向量构造矩阵V∈N×N,对每一行进行单位化处理,处理公式如下: (10) Step6:把R上每一特征行看成k维空间上的节点,利用k-means经典聚类算法对特征向量空间进行聚类,最后得到逼近真实的社区划分C1,C2,…,Ck。 为了能直观地检测文中算法,分别从聚类算法的精度和社区模块度以及真实仿真三个方面设计实验。数据集采用UCI数据集(加州大学欧文分校提出的用于机器学习的数据库)中的Iris、Wine、Image样本,多关系网络Southern Women Data数据集[17]。对比算法包括典型的NG算法[1]、FN算法[11]、COPRA[12]算法,以及经典谱方法,如NJW算法[8]、Nyström采样算法[9]。评价指标为模块度Q函数[10]、重叠社区的评价模型EQ函数[11]、聚类评价的FM(Fowlkes-mallows)指数[17]。仿真对象为Southern Women Data数据集。 Newman等[10]提出的模块度函数是评价网络社区发现效果常用的指标,评价函数也叫Q函数,公式如下: (11) 其中,Aij表示节点i和节点j的边权值;κi表示节点i的度;κj表示节点j的度;Ci表示节点i归属的社区;m表示整个网络的边权值之和。当Ci≠Cj时,δ(Ci,Cj)=0,否则δ(Ci,Cj)=1。 研究表明[5],模块度Q函数在重叠社区网络社区划分时,会存在重叠问题和极端退化现象。为使在重叠社区检测效果不失真,采用文献[11]提供的EQ函数: 其中,ki和kj分别表示节点i和节点j的度;X为网络节点总数;Aij表示网络邻接矩阵;Oi为节点i所属社区数;Ct表示第t个子社区。 UCI中的Iris、Wine、Image真实数据集的数据属性如表1所示。将文中算法和几种经典算法的聚类结果利用一致性的FM(Fowlkes-mallows)评价指标[18]进行比较。FM取值[0,1],其值越逼近1,表明聚类结果越接近真实网络。 表1 实验真实数据集的数据属性 由表2可以看出,在上述3个数据集上,文中算法除了在Image数据中比Nyström算法FM指标略低外,其他均高于其他算法。Nyström算法在大规模模糊数据上会略具优势,在层次结构比较清晰的Iris和Wine数据上,文中算法还是更逼近真实值。 表2 UCI中算法的FM值 与另一种自适应谱聚类算法Nyström以及经典的NG算法、FN算法、COPRA算法、NJW算法在QLSP数据集上进行实验,各算法的Q和EQ值如表3所示。可以看出,文中算法在重叠社区的领域检测时,EQ指标明显高于其他算法。 表3 算法的Q和EQ值 Southern Women Data数据集中,如果某位妇女参与某项活动,妇女与活动间就会有边连接。将文中算法应用在多关系网络Southern Women Data数据集上,可以明显划分为4个社区,如图1所示,其中方框表示活动节点,圆点表示妇女。 社区发现是复杂网络研究中重要的课题,多数谱聚类社区发现算法都存在着需要提前预知聚类个数k值的问题,基于样本采样近似计算k值或基于k邻近的近似求解相似矩阵的部分改进算法虽然能够得到逼近的k值,但仍局限于给出的特定样本数据。文中提出的基于密度自适应聚类数的社区发现谱方法,能对样本数据构图后的局部节点密度和边介数进行相似计算,自动识别聚类个数的k值。能更精确构造相似矩阵,得到的仿真社区结构更逼近真实,能更适应各种领域样本数据。虽然该算法的聚类精度和仿真效果较好,但算法复杂度与传统的聚类算法一样为O(n3),这方面尚需进一步的研究改进。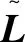
2 基于领域的自适应谱聚类社区发现
2.1 算法思想
2.2 基于节点局部密度的构图
2.3 基于边介数的相似矩阵构造
2.4 算法步骤


3 实验分析
3.1 评价指标

3.2 UCI数据集实验


3.3 模块度实验

3.4 仿真实验
4 结束语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31现代计算机(2018年27期)2018-10-25舰船电子对抗(2017年6期)2018-01-11读与写·教育教学版(2017年10期)2017-11-10互联网天地(2016年1期)2016-05-04电脑知识与技术(2015年17期)2015-09-11南都周刊(2015年4期)2015-09-10南都周刊(2015年3期)2015-09-10南都周刊(2015年1期)2015-09-10湖南师范大学学报·自然科学版(2014年3期)2014-10-24
