
基于自编码网络和聚类的入侵检测技术
2019-05-17 02:51周康,万良
计算机技术与发展 2019年5期
周 康,万 良
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 软件与理论研究所,贵州 贵阳 550025)
0 引 言
随着网络安全问题的层出不穷,传统入侵检测方法已经不符合时代需要,好的入侵检测方法应满足准确性高、较好的适应性和检测的实时性要求。对于传统的入侵检测方法,前人做了较多研究。例如,Denatious等[1]提出了利用聚类、关联规则等联合数据挖掘方法进行入侵检测;Chitrakar等[2]组合应用邻近聚类算法和SVM算法来构建异常检测模型;Srinoy等[3]将隶属度综合运用粗糙模糊聚类方法实现数据容量的约简,实现特征降维等。这些方法都在入侵检测领域取得了突破性进展,而模糊C均值算法(fuzzy C-means,FCM)最早由Bezdek[4]于1984年提出,使用欧氏距离贴近的模糊隶属度矩阵方法表达分类。Wang[5]和Lee[6]等将FCM方法应用于IDS中,证明了FCM具有良好的分类性能。
特征空间维数过多是导致IDS检测速率低的主要原因。黄思慧[7]提出了一种PCA-ELM的入侵检测算法,在时间上和检测正确率上都有所改进;Kuang等[8]提出混合的KPCA方法与遗传算法(GA)、单独的KPCA方法对高维数据降维后代入分类器进行入侵识别;EDL Hoz[9]将主成分分析(PCA)降维和自组织映射(SOM)聚类进行入侵检测,是一种常规高效的做法。
前人的研究都在输入特征维度上进行降维,提高了检测时间,但在特征维度空间呈现非线性特征时,无法较大地提高检测速度。因此文中旨在保证高分类精度的条件下,最大限度地学习到低维特征空间的高维数据表示,以提高检测速度。
文中将自编码网络(autoencoder network,AN)[10]应用于入侵检测领域,使用遗传算法优化FCM算法聚类中心避免陷入局部最优,并将自编码网络降维和主成分分析降维进行比较,以及对比FCM和SVM,softmax分类算法,证明AN-GA-FCM入侵检测模型具有较高的检测速率和检测正确率。
1 深度学习模型
1.1 自编码网络

(1)
其中,f(X)为sigmoid激活函数函数。
该网络激活方式是隐藏层h1的输入由上一层h0的输出x和它的权重W乘积激活。h2的输入同样由h2的输出x'和它的权重W'乘积激活,直到所有的隐藏层都被激活。
1.2 RBM神经网络
自编码网络的核心组件之一是受限玻尔兹曼机网络(restricted Boltzmann machine,RBM),通过对自编码网络每两个隐藏层进行预训练得到高维空间映射到低维空间的矩阵表示。RBM包含两层,可见层(visible layer)和隐藏层(hidden layer)。神经元之间连接是层内无连接,层间全连接,其所有节点满足全概率分布p(v|h),即Boltzmann分布。通过使用更多的隐藏单元适应更复杂分布,增强其建模能力。RBM的能量函数定义如下:
E(v,h)=-b'v-c'h-h'Wv
(2)
其中,W表示连接隐藏单元和可见单元的权重;b,c分别表示可见层和隐藏层的偏移量。
由于RBM的性质,即当给定可见层神经元的状态时,各隐藏层神经元的激活条件独立;反之当给定隐藏层神经元的状态时,可见层神经元的激活也条件独立,即:
(3)
(4)
其中,Z为归一化因子。
训练的目的是使联合概率最大,能量函数值最小。给定可见层(或隐藏层)所有神经元状态,隐藏层(或可见层)上某个神经单元被激活(取值为1)的概率,计算P(hk=1|v)(或P(vk=1|h))推导得到:
(5)
(6)
通过参数调整,从隐藏层获得的可见层vk和原来的可见层v如果一样,那么所获得的隐藏层就是可见层的另一种表达。
由于可见单元和隐藏单元概率条件独立,样本p(x)可以通过马尔可夫链收敛。
1.3 Gibbs采样
在RBM中,使用Gibbs采样[12]作为转换算子,样本包含了可见单元和隐藏单元集合,但它们是条件独立的,因此样本p(x)可通过马尔可夫链收敛。在这个过程中,给定隐藏单元值同时对可见单元进行采样,同样给定可见单元值同时对隐藏单元采样。马尔可夫链中的一个步骤如下:
h(n+1)~sigm(W'v(n)+c)
(7)
v(n+1)~sigm(W'h(n)+b)
(8)
其中,h(n)为马尔可夫链第n步所有隐藏单元集合。当t→∞就可以得到样本最精确的概率值。
1.4 CD-k算法
利用Gibbs采样和马尔可夫链求概率分布最大值的方法,其迭代收敛次数无法保障,难以确定步长。对比分歧算法(contrastive divergence,CD)是Hinton提出的快速训练RBM的方法,并在实践中取得了很好的效果[13]。CD算法的目的是希望p(v)≈ptrain(v),即数据分布差异性最小。两个概率分布的差异性表示为Kullback-Leibler(KL),即:
(9)
(10)

(11)
实验证明,在n次迭代后,通过梯度修正参数θ,CD值必将趋近于0。
2 自编码网络的入侵检测模型构建
2.1 自编码网络特征提取模型构建
文中设计的自编码网络结构由数据输入层、中间4层RBM隐藏层和输出层组成[15],实现过程如下:
(1)预训练过程。通过RBM预训练获得生成模型权值参数,计算W和b的残差,利用梯度下降法更新W和b,使得输出更好地表示输入。
(2)展开。在经过多层RBM网络预训练后,编码器和解码器使用得到的权值作为自编码网络的初始权值。将预训练得到的RBM网络连接起来并按照自编码网络结构展开。
(3)权值微调。按照重构误差最小化原则对自编码网络进行调整,依次经过解码器和编码器利用反向传播算法[16]对整个自编码网络进行权值微调。通过前向传播的方法,对每一层的神经元进行前向传导计算,利用前向传播公式得到各层的激活值。
2.2 自编码网络训练过程
训练阶段主要过程包括以下几个步骤:
(1)输入可见层变量H={h1,h2,…,hn}和隐藏层变量V={v1,v2,…,vn},输出模型参数θ={W,a,b};
(2)初始化RBM网络权值Wij=ai=bj=0(i,j∈Z+)和迭代次数k;
(3)将每个输入特征变量vi赋值给v0;
(4)对所有可见单元和隐藏单元,根据式7、式8求得初始状态和更新状态下的联合概率分布梯度,并代入式11来更新θ={W,a,b},即:
(二)医疗服务价格定价权限各省高度集中。定价权高度集中,全国各省的医疗服务定价权都在省一级,各省所属地市的经济发展水平不同、财政级次及补助比例不同、设备的档次不同,使用频次不同,各地群众的支付能力不同、医保的支付标准不同,用统一标准定价,各地的适应差异较大。医疗服务价格扭曲导致了医疗服务行为的偏移,医疗服务市场的价值取向出现问题,导致医疗市场混乱。所以,适应新的卫生体制改革需要,价格必须及时调整,才能保证医疗服务成本的补偿机制健全,医疗服务行为的偏移得到纠正;
(12)
(13)
(14)
如果k=t,保存模型参数,算法结束,如果k>t,则t=t+1,转向步骤2。
2.3 权值微调

(15)
最后,更新每个网络模型参数θij=θij+Δθij。如果k=t,则保存微调后的参数,算法结束,如果k>t,t=t+1,回到步骤2。
3 GA-FCM分类器构建
3.1 模糊C-均值聚类算法(FCM)
假设X={x1,x2,…,xn}为n维数据样本,c(2≤c≤n)为类别数,{L1,L2,…,Lc}为分类类别,U={U1,U2,…,Un}为n个样本隶属度矩阵。各类别的聚类中心v={v1,v2,…,vc},μk(xi)为第i个样本对于类别Lk的隶属度(简写为μik)。则目标函数Jb的表达式为:
(16)

计算隶属度μik和c个聚类中心{vi},分别对Jb求极值有:
(17)
(18)
其中每个样本对于各个聚类的隶属度和为1。使用式17、式18反复修改聚类中心和隶属度进行迭代,使目标函数Jb趋于稳定,完成各类聚类中心和各样本对每个类的隶属度。
3.2 遗传算法实现
遗传算法是一种全局寻优方式,具有强大的空间搜索能力[18],两者结合使用避免FCM算法陷入局部最优。过程如下:
(2)适应度函数:按优胜劣汰的机制,适应度函数值越小,繁衍几率越大。排序得到分配函数:FintV=ranking(Jb)
(3)选择算子:采用随机遍历抽样(SUS)。
(4)交叉算子:采用单点交叉算子。
(5)变异算子:以初始概率产生变异基因数,用随机方法选出变异基因。如果是变异基因,那么它将进行0,1互变。
3.3 GA-FCM算法流程
基于遗传算法优化的模糊C-均值聚类算法模型描述如下:
(1)初始化GA-FCM算法模型参数,包括模糊C-均值算法最大迭代次数N,目标函数的终止容限D,种群个体大小sizepop,最大进化次数MAXGEN,变异概率Pm。
(2)随机初始化c个聚类中心,并生成初始种群Chrom,对每个聚类中心用式17计算各样本隶属度,以及每个个体适应度fi,i=1,2,…,sizepop。
(3)设初始遗传代数循环计数变量gen=0。

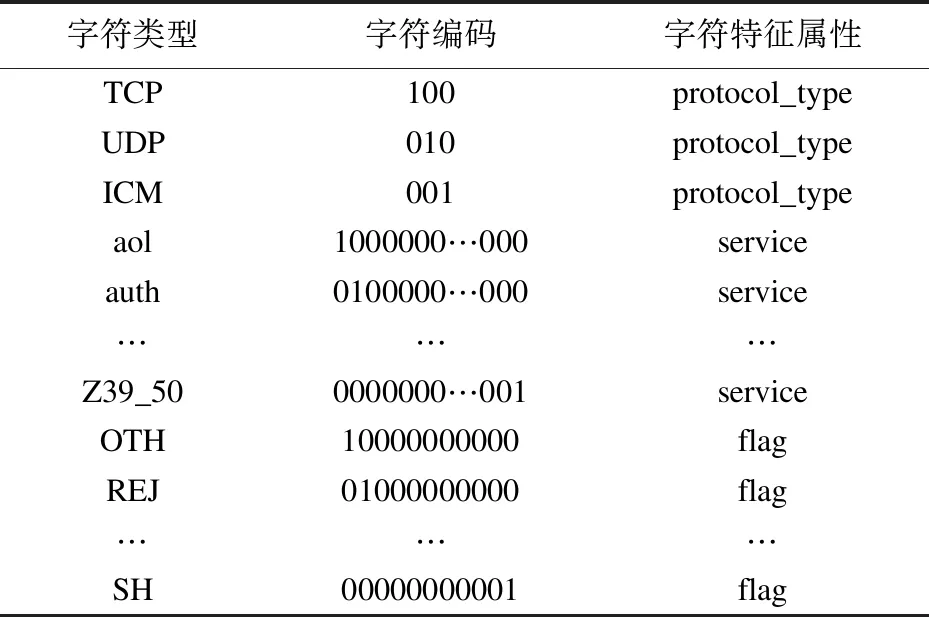
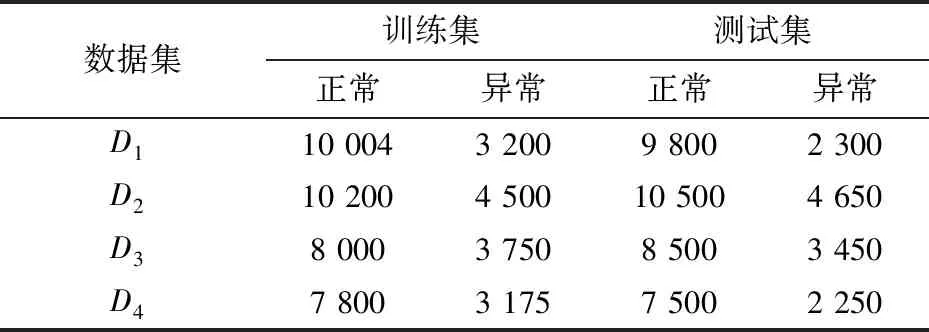
(5)若Gen 对KDD’99数据集[19]进行预处理作为自编码网络输入数据,主要包括数值化和归一化过程。 (1)数值化和归一化。原始KDD’99数据集中包含了41个特征属性,其中3个为字符型特征属性,分别为protocol_type(网络协议类型)、service(目标主机网络服务类型)、flag(连接正常或错误的状态)。protocol_type包含3种协议类型,service包含70种服务类型,flag包含11种状态。文中分别对这3种字符型数值进行二进制数值化编码处理,最后将数据集进行区间[0,1]归一化操作,得到处理后的数据集。 具体过程见表1。 表1 数据集编码 (2)数据集选择。每个数据集随机抽取,包含正常连接数据样本和入侵数据样本,如表2所示。 表2 数据集组成 自编码网络的深度对特征降维有着重要影响,直接影响数据集维度和分类效果。Hinton的研究指出3层RBM网络已能提取有效的特征用于分类任务[20]。 实验设置5种不同AN-GAFCM网络结构进行性能对比分析。设置AN2-GAFCM、AN3-GAFCM、AN4-GAFCM、AN5-GAFCM、AN6-GAFCM的RBM网络结构为122-60-5、122-80-40-5、122-110-70-40-5、122-110-80-50-25-5和122-110-80-60-40-20-5。结果表明使用5层自编码网络结构性能最佳。 将AN5-GA-FCM模型与传统入侵检测模型做实验对比,通过常用PCA降维算法、SVM分类算法,以及神经网络中的Softmax分类算法进行实验,AC(%)表示准确率,TD(s)表示检测时间,比较如表3、图1和图2所示。 表3 不同分类器的检测性能对比 续表3 图1 不同算法的正确率 图2 不同算法的检测时间 结果表明,文中提出的自编码网络结合遗传算法优化的模糊C-均值算法模型具有较高的检测率和较低的检测时间。应用自编码网络降维效果优于传统PCA降维算法,使用GA-FCM算法分类在检测时间和检测率上优于Softmax、SVM、FCM。 检测入侵异常行为,需要检测庞大复杂的数据流量,特征选择的好坏直接影响检测效果。针对网络数据流量的稀疏多样性等特点,将自编码网络特征降维深度学习方法用于处理入侵检测数据方面,并提出一种改进缩短检测时间的优化模糊聚类算法GA-FCM。通过分类算法和降维算法的对比,证明AN-GA-FCM算法模型具有较高的检测率和较短的运行时间。4 实验结果及分析
4.1 数据预处理
4.2 模型参数选择实验分析
4.3 不同分类器检测性能对比




5 结束语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
现代计算机(2018年27期)2018-10-25
