
深度变分贝叶斯投资组合理论
2019-05-18 11:38晁梦遥
大众投资指南 2019年12期
晁梦遥
(陕西省西安翻译学院,陕西 西安 710105)
一、引言
投资组合选择的选择是金融市场学中的一个关键问题。其基本思想在于回报和风险的均衡,即根据一个最优化准则选择最好的投资组合。Markowitz 的投资组合选择理论[1]为我们提供了如何推导出具有最小可能方差(最小风险)的投资组合和生成位于有效边界的投资组合的工具。基于这个理论框架,研究者们针对各种问题产生了大量的研究工作[2]-[10]。
这个方案及其变体理论使用统计模型进行建模,捕捉到了浅层因素,而在金融领域,随着事件复杂性的提升,即所有抽象级别可能看起来同样可行,主要的深层因素往往与输入数据呈非线性关系。这些需求激发了深层架构的通用性,即深度投资组合选择理论。深度学习工具具有极佳的使用价值[3],其极强的建模能力,其可以计算任何函数映射数据的最佳可用方法,以将可能回报以及风险数据,转化为价值。深度学习在金融市场领域有诸多研究[9]。
另外,组合投资学说的研究假设模型和漂移以及波动的参数是已知的且为常数,这使得参数需用以往数据估计且在此之后保持恒定。在实际变化的市场条件下,这个传统的解决方案存在一定的不足[4][6]。将贝叶斯学习应用到投资组合分析中能很好地解决这些问题。首先,贝叶斯方法将未知参数视作随机变量并可以设置先验信息,从而可以将量化已知信息引入到建模中为学习提供参照而非决策。其次,贝叶斯模型很好地解释了估计风险和模型不确定性[5]。本文中,我们将贝叶斯推断引入到深层次因素的学习中。这些使得贝叶斯理论广泛引用于金融领域[10][9]。
综合以上考量以及思路,我们设计的深度变分贝叶斯投资组合最优化方法分为学习和优化部分。在学习阶段中,(一)使用深度变分自编码器网络构建的市场映射算法,其用于捕捉输入数据的深层次表征;(二)基于深层次表征,使用深度神经网络实现多变量投资组合支出的监督模型;在优化部分,我们目的在于均衡学习阶段的误差。基于此,本文的贡献主要有三点,一是,针对投资配置中变量间复杂非线性关系进行建模,并捕捉到深层影响因素;二是,将完全由数据驱动的深度学习和贝叶斯理论引入到投资配置理论从而解决了传统方法中存在的参数估计误差以及模型依赖型算法在大数据情况下的不适定性;三是,设计了一个统一的学习框架,从而可以以监督学习的方式端到端优化投资配置模型。
本文的组织结构如下。第二章,我们对深度变分贝叶斯投资配置算法进行详细的描述。第三章中,我们利用实验对算法的有效性进行探讨。第四章我们简述本文所得到的一般性结论。
二、深度贝叶斯变分投资组合理论
在本文中,我们构建变分自编码和多变量投资组合输出模型。首先,根据深度学习中的数据集分类思想,我们将市场数据划分为训练集和验证集,表示为和,同时我们将目标变量设为。给定具体目标,我们设计智能化投资组合方法,其在投资组合选项中进行权衡以匹配目标函数。
我们的投资组合结构可以分为学习和权衡两部分,表述如下:
(一)学习部分
针对市场数据以及相应的目标期望,学习部分主要进行数据深层次因素的捕捉以及利用监督学习模式来得到投资组合到目标的映射函数。在深层次因素的捕捉中,我们使用变分自编码器,其依据贝叶斯理论,能以无监督的方式获取隐藏变量以作为的优化表征。公式如下:

此为变分自编码器的变分下界,运用重参数化技巧可得:
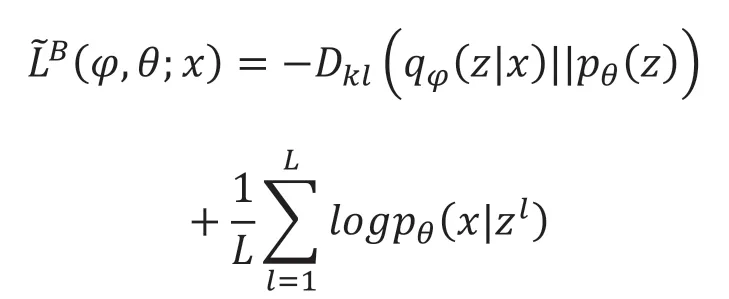
同时,需要得到投资到目标结果的映射函数,其优化公式如下:
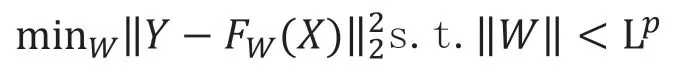
其依据目标,从输入信息创造一个非线性投资组合映射。
在理论上,深度学习可以捕捉变量间复杂和非线性的关系,以构建性能极佳的回归模型,这在大部分场景中均优于传统金融经济学的简单线性因子模型以及统计套利和其他定量投资管理技术。同时,我们所提出的变分自编码器将总信息减少到适用于大量输入的信息子集,即隐层的编码,并以编码后信息与其自动编码版本的接近度作为衡量标准,对投资组合进行评判。
(二)权衡部分
构建数据到深层次因素(即隐层)以及从数据到投资组合目标的映射网络后,需要权衡上述误差以平衡模型在深层次因素学习和目标近似上的能力。则需要寻找最佳Lm和Lp:
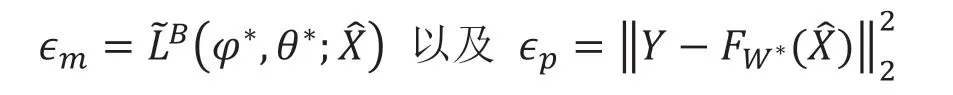
从而我们需要找到φ,θ以及FW以确保上述条件的成立。为此,我们将检查隐含的深层投资组合边界以获得感兴趣的目标作为正则化量的函数,以提供可量化可训练优化的度量函数。
三、实验
我们的实验配置如下所述。
数据设置:本章实验部分所用的数据来自生物技术IBB指数的成分股,数据周期为2012年一月到2016年4月并按周计算回报数据。我们希望找到最优策略从而可以击败由(see Merton,1971)给出的生物技术IBB指数。
数据划分:对于本文所提出的学习和权衡两个阶段,我们采用2012年1月到2013年12月的数据用于学习,用2014年1月到2016年5月的数据作为权衡阶段的输入。
实验设置:在网络设置中,我们采用单隐层结构,即变分自编码器中输入通过一个10个神经元的中间层和隐藏层相连,最终编码层包含5个神经元。而对于学习阶段的目标映射函数,我们同样采用包含10个神经元的中间隐藏。以变分自编码器的中间层编码作为对股票的编码,并考虑每个股票与其自动编码版本间的2范数差异,然后以此接近程度作为度量标准对股票进行排名。我们将10个最多的公共股票和非大多数股票相加来增加深度投资组合中的股票数量。各模块的训练batch size大小为10,而epoch 为500。
我们的实验结果如图1所示:

Fig1.我们的深度变分贝叶斯投资组合理论在实验各阶段的实验结果。其中(a)为深层次因素学习阶段,即变分编码阶段,(b)为数据校准阶段,而(c)和(d)为优化阶段。
在学习阶段,我们捕捉到了深层次因素即图(a),在图(b)的校准阶段,我们将所有小于□5%的回报替换为5%,这旨在创建一个在大幅度下降时具有反相关性的指标跟踪器,而修改后的目标视为图3(b)中的红色曲线。在(c)(d)中,我们看到了学习的深层投资组合在优化过程中如何实现卓越绩效。验证表明,对于当前模型,应采用至少40种库存的深度投资组合进行可靠预测。
四、结论
本文中所提出方法建立在传统的Markowitz基础上,即投资选择问题。然而,不同于传统方法,我们的理论基于对市场信息的变分编码,从而校准数据以形成一个针对其后获取最优投资组合的有效数据。深度变分贝叶斯投资组合理论将深度学习引入以学习数据从而在自动编码步骤中发现深层功能,同时对数据进行校准。在之后,我们同步优化二者进行权衡,从而展示如何查找投资组合来实现预先指定的目标。这两个程序都涉及优化,需要选择正规化量的问题。为此,我们使用了一个样本验证步骤。具体而言,我们避免使用可能受模型风险影响的统计模型,并且,我们直接将目标建模到正规化中以直接优化,而不是事前的有效边界。实验表明,我们所提出的理论在实际应用中有很好的性能,且以直观的网络设计规避了可能受模型风险影响的统计模型。
猜你喜欢
数学杂志(2020年3期)2020-07-25
数学物理学报(2019年6期)2020-01-13
成都信息工程大学学报(2018年3期)2018-08-29
数学物理学报(2017年6期)2018-01-22
数理化解题研究(2017年4期)2017-05-04
电子设计工程(2017年20期)2017-02-10
数学物理学报(2016年3期)2016-12-01
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
电子器件(2015年5期)2015-12-29
