
基于介电特性的苹果内部品质预测方法研究
2019-05-27 08:47耿晗,蔡骋,刘斌
农机化研究 2019年10期
耿 晗,蔡 骋,刘 斌
(西北农林科技大学 信息工程学院,陕西 杨凌 712100)
0 引言
我国是世界上最大的水果产出国,种植面积和产量长期稳居世界第一,水果产业在国民经济发展中一直占有举足轻重的地位。但是,在国际市场上我国水果出口量仅占总产量的2%左右,远低于世界同期各国水果出口10%的平均水平[1],主要原因在于我国水果产业的粗放型经营模式,未能按照国际标准严格执行对水果品质的分级处理[2]。另一方面,随着人们生活水平和质量的大幅提升,对水平品质的追求也越来越高,开始逐步关注水果的口感指标。因此,如何快速无损检测水果的糖度、硬度及含水率等内部品质对确定水果的营养价值和分级销售有重要意义。
水果无损检测是基于在水果表面无任何损伤的情况下,对水果内部的成分和结构进行分析的技术。国内外相关研究人员利用水果的电学特性、声学特性、光学特性、太赫兹及机器视觉等技术对水果品质进行无损检测[3-6]。Reyer 等[7]基于计算机视觉检测了杏和桃的撞伤问题,该方法对伤果的检测准确率为65%左右,但该方法属于水果外部品质测定的范畴。近年来,水果内部品质检测及分类的研究逐渐成为研究热点。Sivakumar[8]对芒果的水分含量用高光谱成像技术进行检测与研究,结果表明采用人工神经网络预测芒果的水分相关系数为0.81。Kandala 等[9]使用近红外光谱法有效检测到了花生中的水分含量,结果表明预测花生的水分含量相关系数为0.97。王等[10]利用声波震动测量方法对库尔勒香梨的硬度进行了无损检测,识别率达到了86.7%。蔡骋等[11]基于介电特征的无损检测技术按照苹果失重率分别为0%、5%、10%、15%,以及果心病变果将苹果品质分为5个品质等级,其检测准确率达到了98.3%。
但上述水果内部品质检测方法多基于水果的单个参数进行检测,难以准确地对水果进行有效分级。蔡骋等[11]虽然考虑了苹果的108个介电特征对水果内部品质进行分级,但未考虑水果糖度、硬度及含水率等重要的理化指标,未能实现对苹果口感的检测与分级。在苹果外观与理化品质对比中发现(见图1):苹果的外观与理化指标不一定成正比,外观较好但苹果的口感、理化品质不一定优,因此需要采用无损检测方法检测影响苹果口感的理化指标并实行有效口感分级。

图1 苹果外观
针对当前研究中尚未实现对苹果内部口感品质的有效分级,本文主要对苹果进行研究,借鉴图像标注方法[12],提出一种基于随机森林的苹果内部口感品质多语义分类方法。该方法使用苹果的介电参数作为指导生成随机森林,用TF-IDF算法选取输出类别,依据介电参数估计预测苹果的理化指标。实验结果表明:该方法分级后均方根误差为0.51,可有效实现对苹果内部品质的多语义分类,可为水果等农产品的无损检测及分级提供参考。
1 实验材料与相关处理
实验中用富士苹果,苹果成熟后(10月中下旬)采自西北农林科技大学白水苹果试验基地,采收后当天运回实验室,平衡24h后,选择成熟度一致、色泽相近、大小均匀、无病虫害及无机械损伤的果实500个。裸果于中室温(20±2)℃条件下贮藏;逐果编号并测定其在158、251、398、15 800、25 100、39 800、1 580 000、2 510 000、3 980 000Hz等9个频率点下的介电特征值。介电参数的测量采用如图2所示的3532-50所示系统,介电特征的测量方法与安等提出的方法[13]一致。在测量苹果的介电特征值时,沿着苹果最大横截面测量两次,然后将两次测量数据取平均值作为该果实的介电特征数值。
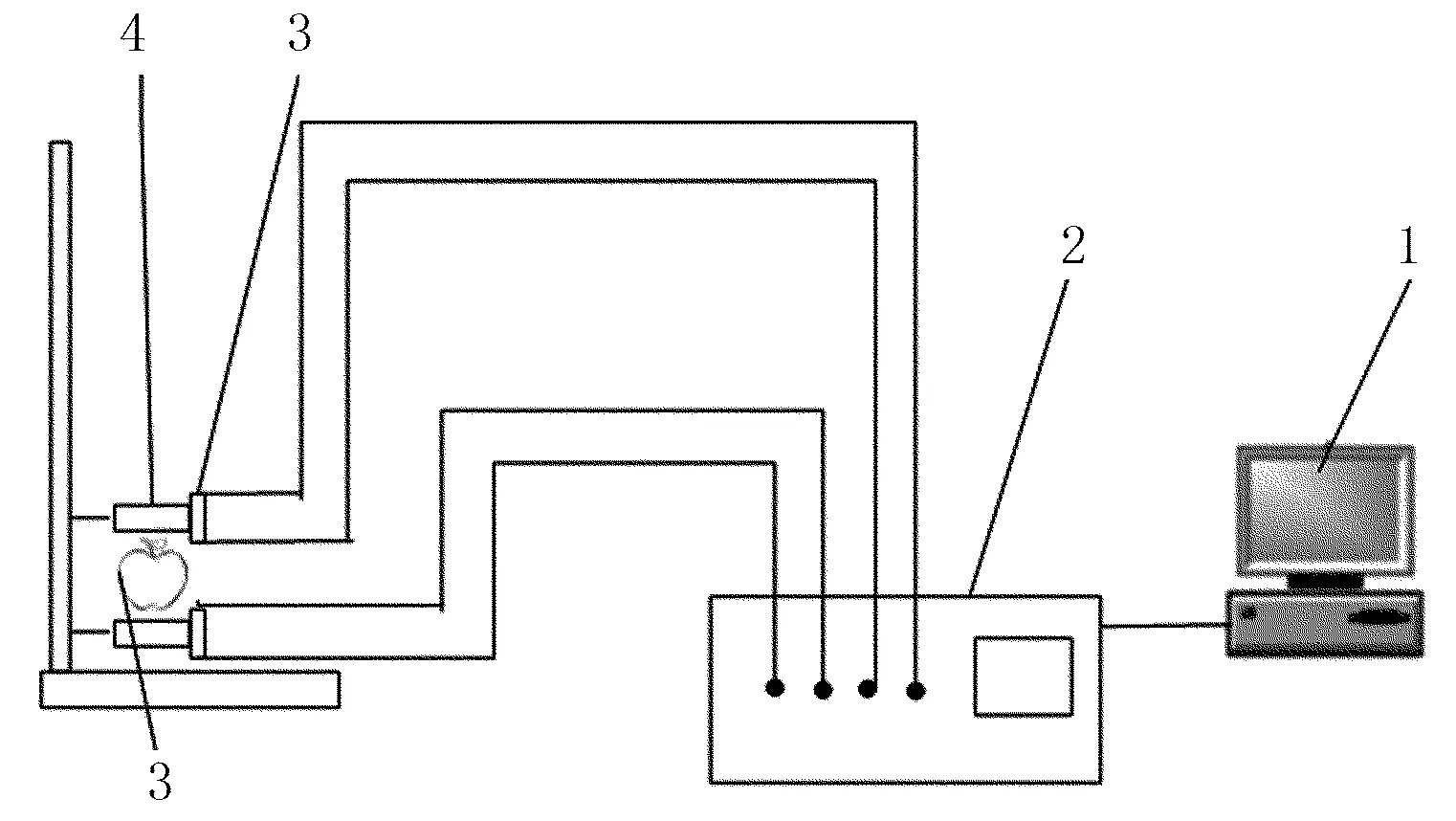
1.计算机 2.LCR测试仪 3.测试探头 4.平行电极板图2 介电参数测试系统
实验中共选取12个介电参数(见表1),每种介电参数在9个频率点(i=158~3 980 000Hz)范围内共测得12种介电特征,一共得到108种介电特征均值,并进行编号。各介电特征均值如表2所示。
对采摘的500个苹果,测量完介电特征数值后,立即开始测量理化特征值,实验过程中测量得到了8种常用品质评估理化特征数值,如表3所示。

表1 12种介电特征
i代表频率点,频率范围为 158 ~3 980 000Hz,共测12种介电特征。
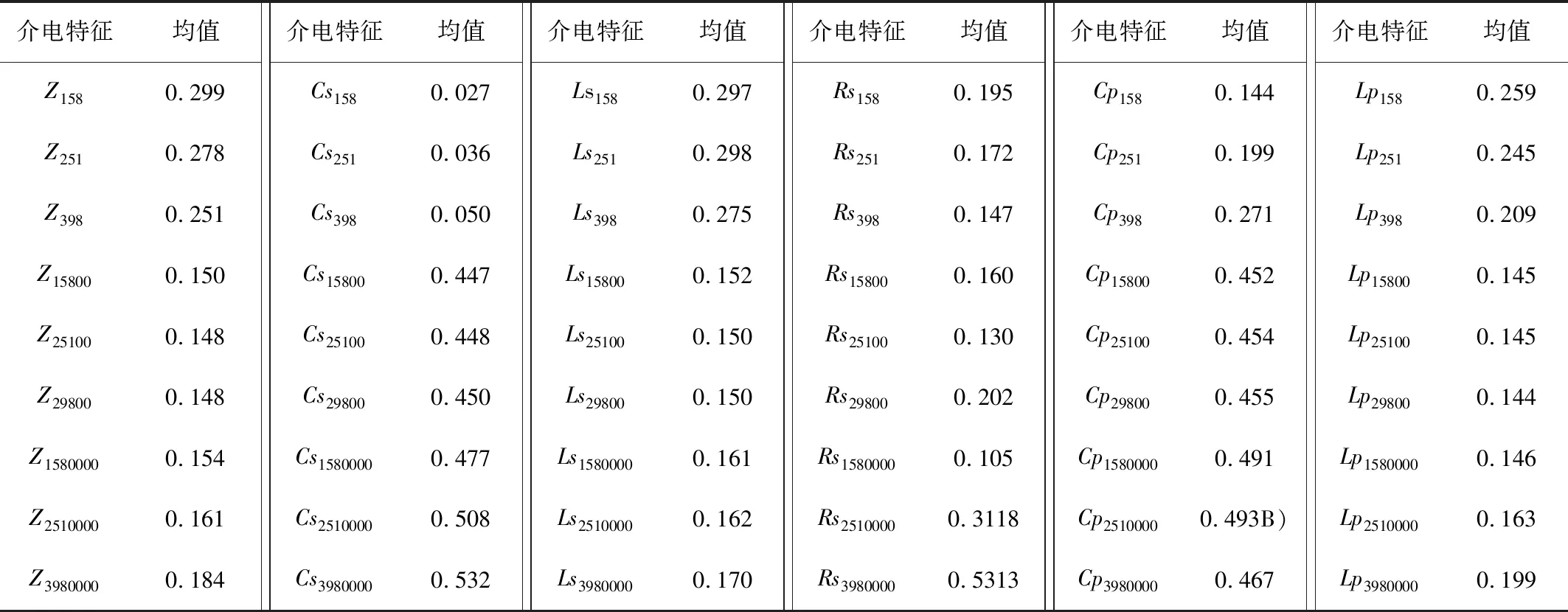
表2 各种介电特征均值
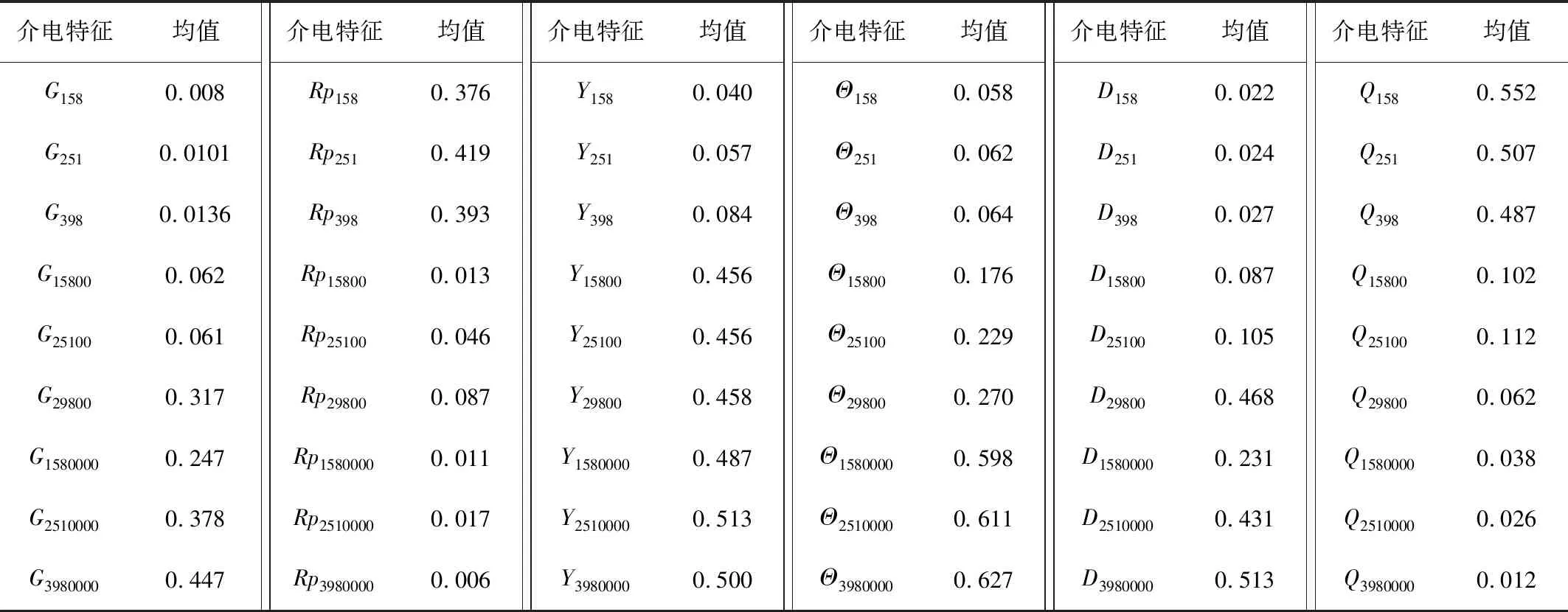
续表2
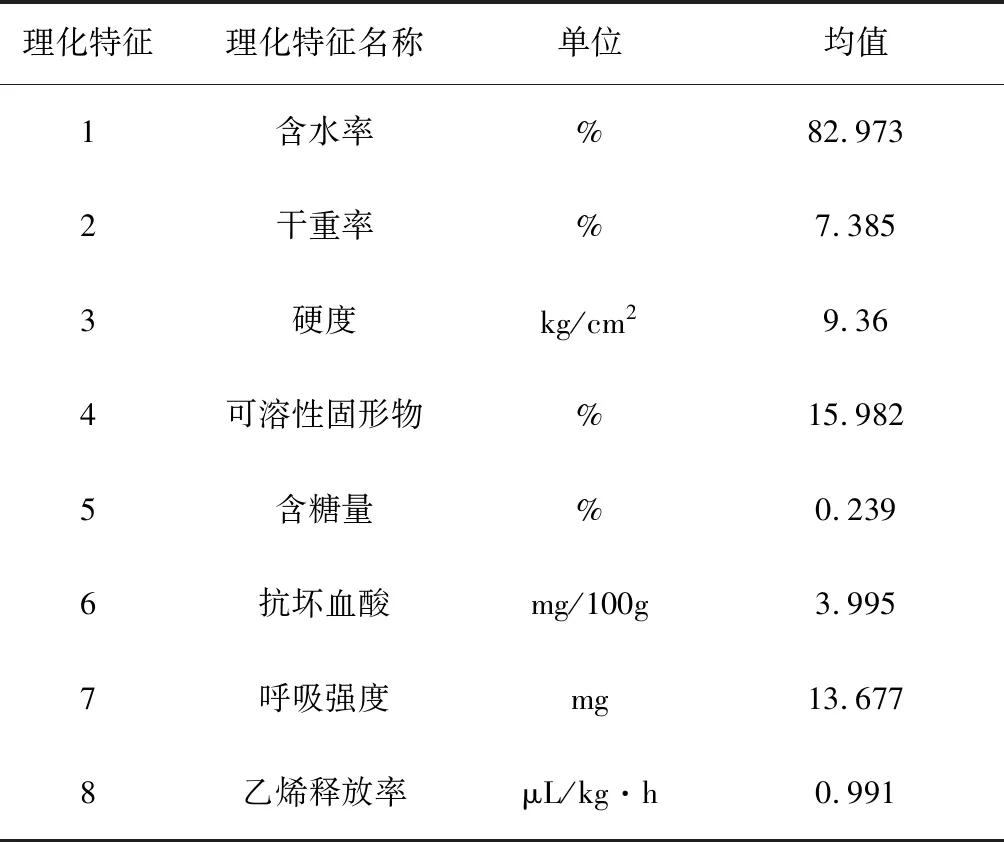
表3 8种理化特征
将每个苹果的介电特征数值与理化特征数值对应,为了训练苹果内部品质多语义分类模型,对比分级正确率,需知道500个样本的理化特征各属于哪种级别。由于果品行业对水果内部品质分级没有统一的标准,本实验将测得的苹果理化特征值从小到大分为5个等级,并将介电特征参数作为输入,训练随机森林。
2 分类模型设计
2.1 随机森林模型设计
随机森林是一种集合学习方法,可用作分类、回归、半监督学习等领域[14],是一系列决策树的集合。
对于分类问题,随机森林能够快速且准确地处理多种分类任务。通过随机选择特征子集和样本子集训练得到决策树,随机森林中为了选定测试样本输出类别,将所有决策树对其预测类别分布采用投票策略选定,如图3所示。
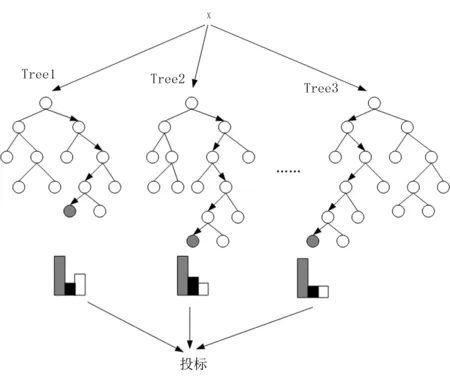
图3 随机森林运行示意图(图中方块表示标签信息量的传递)
1)划分点选取。Ta表示在在样本集上属性为a的分裂值,即
(1)
其中,a表示样本集上的连续属性。a在样本集上有n个不同的取值,将这些值从大到小排序,记为a1,a2,...,an。基于划分点t∈T可将子集分为大于t和小于t的样本,对连续属性a考察n-1个划分点候选集合。
2)训练目标函数选取。随机森林训练的关键是如何选择最优划分属性。一般而言,随着划分过程不断进行,希望每棵树的分支节点所包含的样本尽可能属于同一类,即结点的“纯度”越来越高。将信息论和信息增益应用于树中分裂结点的目标函数,能得到3种函数,分别是信息增益、信息增益率、基尼系数。本实验中,将信息增益率作为目标函数,原因是使用信息增益率来选择属性能够完成对连续属性的离散化处理,能够对不完整数据进行处理。I定义为信息增益率,即
(2)
其中,S为分裂结点的属性数据集,将S分为左子集SL和右子集SR;H表示信息熵;|S|、|Si|分别表示样本总数。H(S)定义为香农信息熵,即
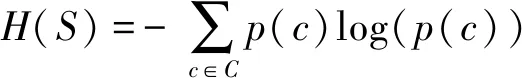
(3)
其中,c为类别标签;C为所有的类别标签集,p(c)为集合S中的样本属于c类的概率。信息增益率目标函数选择信息增益值最大的属性作为分裂属性。
随机森林训练过程中起到关键作用的参数有:
1)树的最大深度。树的深度越小,计算量越小,速度越快;深度越大,计算量越大,速度越慢。过大或过小会影响分类的准确性[14]。
2)森林中树的总数。树的总数越大,分类性能越好,树总数的选择取决于计算机的硬件资源。
2.2 标签预测
在随机森林训练后,使用投票策略选定测试样本的输出类别,然而在苹果内部口感品质多语义分类研究中,分级标签为8个,仅采用随机森林模型无法统计输出类别。因此,本研究中将测试样本用理化指标标注标签,通过随机森林中的每棵随机树,从根节点到叶子节点按照分割函数不断进行深度优先搜索完成。
TF-IDF(词频-逆文档频率)算法[15]是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。其中,TF指的是某一个给定的标签在该样本集出现的次数,IDF是一个标签普遍重要性的度量。该算法具有快速选取输出类别、算法复杂度低的优势,在本研究中采用TF-IDF算法过滤掉普通标签,保留重要的有分类意义的标签。使用该算法进行理化特征标签预测的主要思想是:如果某一理化特征标签在某个测试集中出现的频率越高,在其他测试集中很少出现,则该标签就能较好地对测试集进行分类。用于预测测试集对应的8个标签qj表示为
(4)
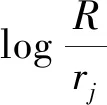
3 结果与分析
实验中,按照9:1随机的将苹果分为训练集和测试集,采用十轮交叉验证的方法取均值。
随机森林模型的训练过程中,使用信息增益率作为目标函数。实验中使用了平行的8个标签(见图4),且标签是连续的,在分类预测中预测出的标签级别分布较为一致,采用的评价指标为均方根误差(RootMeanSquareError,RMSE),即
(5)
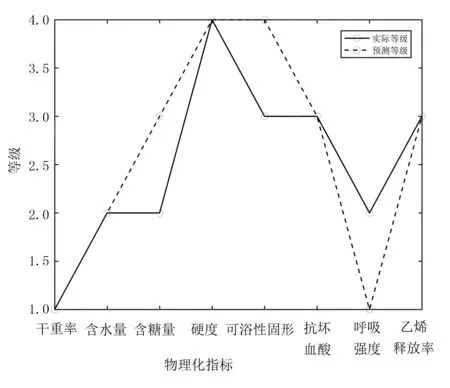
图4 标签对应分布图
实验结果表明:将随机森林应用于苹果内部口感品质多语义分类中可行。由图4可看出:8个理化指标的实际等级和预测等级分布较为一致,最多3个标签的实际等级和预测等级有差值,差值相差一级。
实验结果表明:将随机森林应用于苹果内部口感品质多语义分类中可行。由图4可看出:8个理化指标的实际等级和预测等级分布较为一致,最多3个标签的实际等级和预测等级有差值,差值相差一级。
基于森林规模的RMSE和时间的关系如表3和图5所示。由表3和图5可以看出:随机森林规模对实验结果有较大影响;森林规模影响分类的准确性及训练时间,随着森林规模的增加,RMSE值逐渐降低,准确性逐渐提高;训练时间越长,森林规模越大,RMSE值变化越明显。
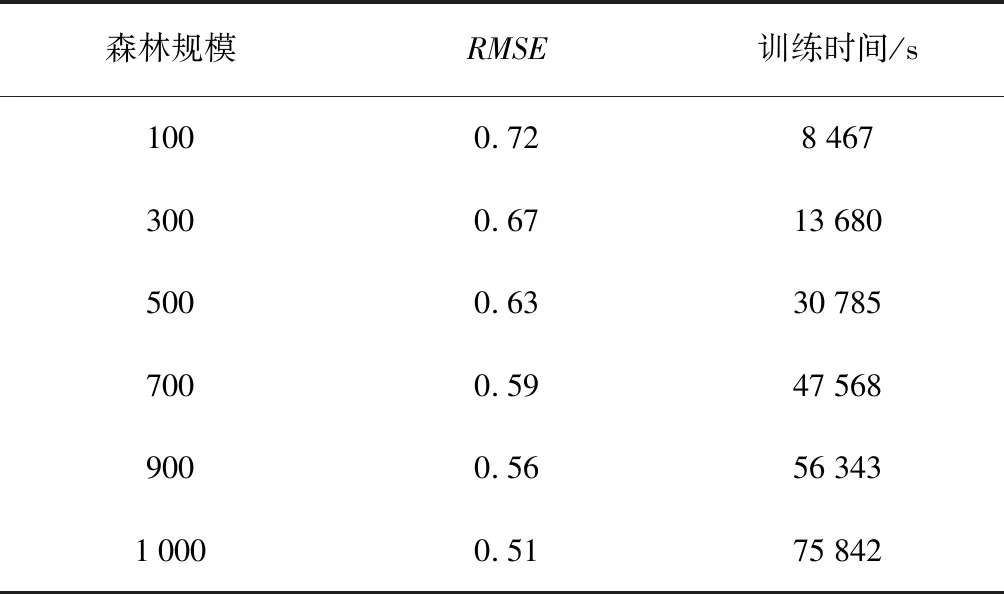
表3 基于森林规模的RMSE和时间的关系
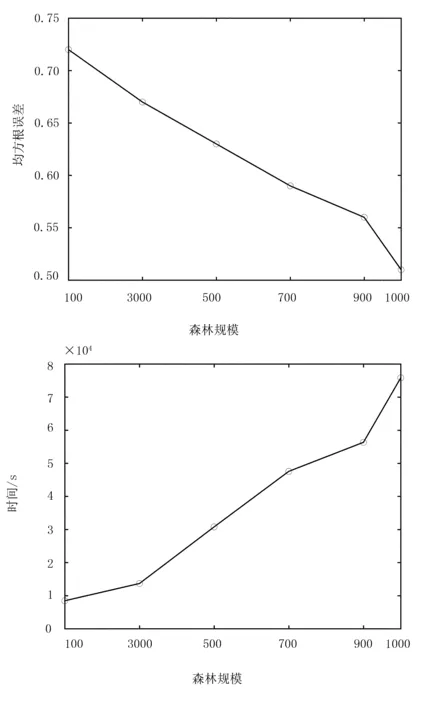
图5 基于森林规模的RMSE和时间的关系
基于树深度的RMSE和时间的关系如表4和图6所示。由表4和图6可看出:树的深度也会影响分类的准确率及训练时间,树的深度过小时,容易造成低度拟合,会降低分类准确性;过大时,容易造成过拟合,会降低分类准确性。随着树的深度的增加,RMSE值逐渐降低; 但降到一定值后,又逐渐增加,而训练时间逐渐增长。实验中选取森林的规模1 000,树的深度为25时,RMSE为0.51,分类准确率较好。

表4 基于树深度的RMSE和时间的关系
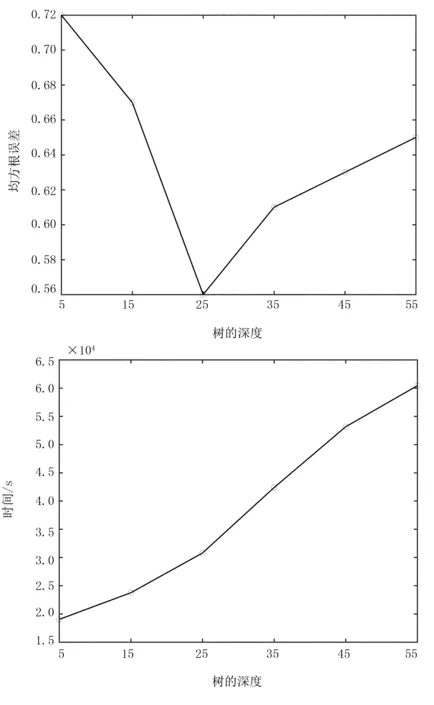
图6 基于树深度的RMSE和时间的关系
为对苹果内部口感品质进行有效的多语义分类,验证随机森林的可行性,本研究测试了支持向量机分类模型(SVM)[16]。实验结果表明:SVM分类RMSE值为0.69,在随机森林模型中使用信息增益率作为目标函数,每棵树的最大深度为25,森林规模为1 000,RMSE值为0.51。因此,使用本文提出的随机森林作为苹果内部口感品质分类器效果更好。
4 结论
在本实验中,使用随机森林为基础进行苹果内部多品质语义分类,使用介电特征参数指导随机森林的生成,标签信息为理化特征,采用TF-IDF算法选取输出类别。实验测试表明:基于随机森林的苹果内部口感品质进行多标签分类的RMSE值为0.51,对比SVM,准确率更高;随机森林模型对苹果内部口感品质多标签分类,相比以往苹果整体等级分类,能够较准确地在无损情况下确定苹果内部口感品质。
猜你喜欢
饮食科学(2019年5期)2019-11-21
饮食科学(2019年5期)2019-06-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
军事文摘·科学少年(2017年4期)2017-06-20
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
小天使·五年级语数英综合(2015年8期)2015-07-06
小学生·多元智能大王(2014年9期)2014-08-28
饮食科学(2014年8期)2014-08-22
