
中国少数民族语言资源开发应用刍议
2019-06-25 03:59丁石庆
语言战略研究 2019年3期
提 要 “中国语言资源保护工程”以其空前规模及统一规范方法实施调研所采集的活态语料资源,兼具真实性、可靠性和科学性,并为语言资源的精准保护和合理开发应用提供了科学依据。语保工程实现了新时期对中国境内的少数民族语言及方言与土语情况较为全面的摸底与排查,调查数据和相关材料同时也提供了少数民族语言资源保护及开发应用的诸多信息。本文以5年来民语专项调研任务语料资源数据及任务进程中发音合作人遴选时透露的语言资源保持类型存在的层次差异等为问题导向,对中国少数民族语言资源的开发应用及相关论题进行初步探讨。本文认为,基于语保工程民语调研专项任务所获大量语料资源数据,中国少数民族语言资源的开发应用可实施整体统一开发应用与分类开发应用两种推进思路。整体统一开发应用思路包括大数据研究、语言服务、政策咨询等内容;分类开发应用思路则包括深度开发应用、深度规范性开发应用、深度保护性开发应用及深度典藏性开发应用等内容。
关键词 语保工程;少数民族语言资源;开发应用;统一;分类
中图分类号 H002 文献标识码 A 文章编号 2096-1014(2019)03-0038-07
Abstract The National Project of Chinese Language Resource Preservation (hereinafter Preservation Project) is an unprecedented megaproject with a unified standard and framework. The live linguistic resources it contains are featured as authentic, reliable and scientific, thus providing a scientific ground for precise preservation of minority language resource and controlled development and utilization. The implementation of the Preservation Project enables a thorough survey and rectification of minority languages, regionalects, and colloquialisms. The data collected provide abundant information for language resource preservation and utilization. Over the past five years, the Project team has obtained rich information form the native speakers of minority languages during special focused tasks. Guided by the hierarchical differences in need of protection as revealed by these minority languages, this study attempts to make a preliminary proposal on the development and utilization of the data from the project. I argue that, based on the big data, the development and utilization of minority language resources in China should be implemented with a scheme of unified development and utilization and a scheme of categorized development and utilization. The former includes big-data study, language service, policy consultancy, and the latter contains in-depth development and utilization, in-depth standardized development and utilization, in-depth controlled development and utilization and in-depth archived development and utilization for individual languages. In short, more considerations should be given to post-project preservation and utilization.
Key words Preservation Project; minority language resource; development and utilization; unified scheme; categorized scheme
“中國语言资源保护工程”(以下简称语保工程)经5年的建设,已进入一期的攻坚收官阶段。目前,语保工程正面临如何开展在语言资源保护条件下的开发应用等后续任务。相较于汉语方言资源,中国少数民族语言资源的开发应用面临语种多、类型杂、差异大的形势,需解决的问题也极其特殊,难以一刀切。本文结合语保工程民语调研专项任务实施以来的实践,就中国少数民族语言资源及其开发应用的相关论题予以初步探讨,以期获得抛砖引玉之效。
一、论题缘起
语保工程兼具史无前例的开创性和重大的现实意义,其投入的经费、人力、持续的时间以及获得的语言资源容量,是空前的。尤其首次采用统一的规范标准所收集的国内汉语方言与少数民族语料资源兼具真实性、可靠性和科学性。调查所获相关数据提供了中国语言资源的分布地域、密度、类型,各语系、各语族、各语支、各语言及其方言土语资源等多种最新信息,也为我们进行语言资源保护与语言资源开发应用规划提供了科学依据。
(一)语保工程民语调研任务所获语料数据
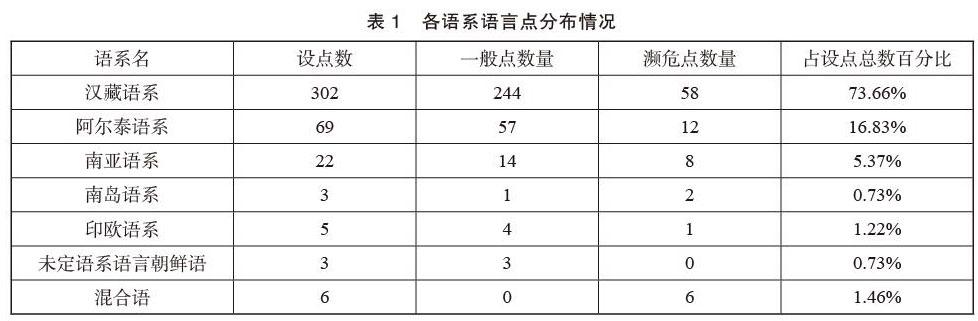
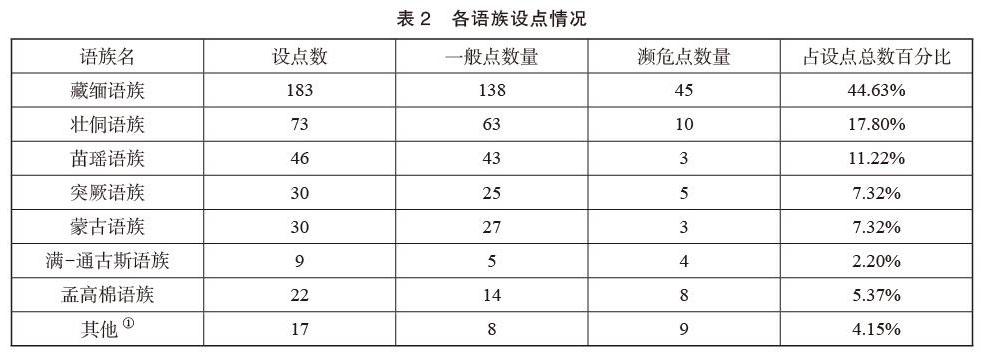
语保工程实现了新时期对中国境内的少数民族语言及方言与土语情况较为全面的摸底与排查。据语保工程民语调研专项任务相关数据统计,2015至2019年的5年内,共计立项410个点。其中,一般点立项323个,已结项255个;濒危点87个,已结项74个。立项与已完成任务的调研点涵盖了分布于中国大陆和台湾的56个民族使用的130余种语言及新发现的若干语言。各语系语言点分布情况如表1所示。各语族设点情况如表2所示。
以上数据中包括需待确认的若干种新发现语言,还包括30~50余种跨境语言(戴庆厦1993;黄行,许峰2013;周庆生2013;朱艳华2016)。
(二)民语“发音合作人”遴选中透露的相关信息
在语保工程实施过程中,每个调研点提供各种语料资源的发音合作人无疑是最重要的角色,而其中尤为关键的是主要发音合作人。语保工程民语调研专项任务实施进程中不同语言及方言调研点发音合作人遴选条件存在一定的差异,大致可分为以下几类情况:
A.发音合作人的遴选有较为充分的选择余地,甚至在某些调研点可海选;具体来说,除了少量借词和绝对缺失词汇外,可圆满完成词汇采集任务;尤其是口头文化语料采集方面的发音合作人的遴选可做到精选,提供的语料内容异常丰富,样式齐全且多样,音像摄录过程十分顺利。
B.有较多符合条件的发音合作人,也有一定的选择余地,但稍需花费一些时间与精力;上述几个环节的语料采集和音像摄录工作一般也较为顺利。
C.符合条件的主要发音合作人有限,且某些调研点需要适当放宽诸如年龄、性别或文化程度等条件;上述几个环节中,词汇部分有一部分抽象词汇缺失现象,口头文化部分提供的语料内容和形式都有一定局限性。有些调研点课题组与发音合作人的音像摄录磨合过程较长。
D.符合部分条件的发音合作人很有限,且单人无法承担主要发音合作人需完成的全部任务,需要数个人合作才能完成部分任务;因词汇缺失现象较为严重,口头文化材料内容和形式较为單一,无法采集到足量的语料;音像摄录也困难重重。
E.符合部分条件的发音合作人也很难觅,仅存的数量有限的自然母语人也或因年事已高、身体多病、发音器官患病及其他原因无法配合课题组的音像摄录工作,课题组不得已在部分“学得”母语人中寻找到符合部分条件的发音合作人,所提供的各类语料在各方面都存在一定局限性。
另外,诸如崩如、苏龙等数种濒危语言因无法寻觅到符合条件的发音合作人,无条件立项;台湾语群除阿美语和邹语外的10余种濒危语言也因各种原因未能列入语保工程一期调研计划。
上述发音人遴选过程中出现的情况分别涵盖了不同的语言:其中,A类一般可涵盖蒙古、藏、维吾尔、哈萨克、朝鲜、壮、傣等数个具有传统文字或布依、哈尼、白等几个新创文字且人口数量较多民族的语言;B类包括彝、苗、侗、拉祜、傈僳、黎、水等人口数量较多、方言分歧较大的民族语言;C类绝大多数是人口较少民族中仍保持一定活力的语言,其中仅有锡伯、柯尔克孜、景颇、土族等几种语言有文字,其余全部是无文字语言;D类大多是有一定濒危迹象的语言,如乌孜别克、塔塔尔、图瓦、东部裕固、西部裕固、保安、康加、鄂伦春、鄂温克、俄罗斯、门巴等民族的语言,也包括台湾绝大多数南岛语系的语言;E类则涵盖了满、土家、赫哲等语言,也包括一部分南岛语系台湾语群的羿、卡那卡那富、沙阿鲁阿、巴则海、邵等语言。
由于不同语言因各种情况存在的许多差异,以上归类具有一定相对性。因每一种语言甚至方言土语间内部也存在着各种不平衡现象,某些语言的下位分类还需参照相关条件有待进一步确认。
(三)相关分析
语保工程民语调研专项任务相关数据统计显示,汉藏语系约占设点总数的73.66%,是中国语言数量最多的语系。其次是阿尔泰语系,约占设点总数的16.83%。两个语系设点约占总数的90.49%。而各语族设点数据统计显示,各语族占比依序为:汉藏语系藏缅语族、壮侗语族、苗瑶语族,阿尔泰语系突厥语族与蒙古语族、南亚语系孟高棉语族、阿尔泰语系满-通古斯语族。以上统计数据同时也反映了中国少数民族语言分布的基本情况。从总体上看,北方民族语言中除了蒙古语、维吾尔语等个别语言外,其他语言基本完成了规划的布点任务。汉藏语系中,藏缅语族、苗瑶语族等因方言、次方言、土语间分歧较大,尤其是藏缅语族中彝缅语支的彝语分六大方言,数十种次方言,还有诸多土语,目前布点密度仍显不足。苗语和瑶语的情况则较为复杂,除了语言内部方言分歧大导致无法交流外,苗族与瑶族内部不同支系间甚至语言兼用,瑶族内部不同支系还使用不同的语言。尽管如此,语保工程民语调研专项任务所获语料资源已形成了庞大的数据信息,基于补充采集相关语料的基础上进行统一开发应用的条件业已成熟。
另外,从发音合作人遴选过程中透露的语言资源保持类型的差异给我们提供了少数民族语言资源进行开发应用的重要依据。我们将各调研点发音合作人遴选的具体情况和各类语言资源的情况综合分析如下:A类语言因人口数量较大,普遍具有悠久的传统文字或新创文字,积累了大量的历史文献,有较早的母语教育史或双语教育体系,加之国家长期的推进和整体的建设,其本体规范化程度已达到很高的水平。B类语言多为新创文字语言,部分因其内部方言或土语差异较大,各语言间规范化程度不一,无法对同一种语言甚至不同方言实施统一的开发应用方案。C类包括大部分人口较少民族的语言,因人口数量少、居住分散、多数没有文字等多种原因,尤其是内部民族内部母语实际使用人数较少,各语言保护及本体化程度差强人意,有一定母语资源开发应用的潜力及空间,但需考虑人口居住分散等情况应实施先保护、后开发应用的方案。D类和E类包括了所有濒危语言,因普遍处于严重的衰变状态,当务之急是语言资源的抢救性保护。从以上相关数据和材料来推断,A类语言资源具备深度开发应用的基本条件,且极具产业化的潜力。B类语言资源中有一部分也具有深度开发应用的条件,但可能还存在不足,如方言间需进一步深度规范化。另一部分语言则需要解决方言间无法沟通交流的问题后实施不同的开发应用方案。C类语言资源开发基础较为薄弱,还需要继续打造和夯实基础之后再将开发应用的问题提到议事日程上。对此类中有文字的数种语言则可以采取边积累边开发的办法。D、E类语言资源则亟待深度典藏性保护。由此,我们认为,在中国少数民族资源的统一开发的基础上,针对不同语言资源保持类型的少数民族语言的开发应用还应同时实施分类梯次开发方案。
二、关于整体统一开发应用的问题
(一)大数据研发及应用
语保工程民语语料资源具有大数据研究的多元可比性、应用开发性、可持续性(丁石庆2018),这将成为少数民族语言资源开发应用最核心的,也是极具潜力的挖掘重点。虽然目前的语料资源在大数据的学术研究方面还存在一定的局限性,如纵向性的历史比较对比方面条件还不甚成熟,但横向的共时比较或对比研究还是有很大空间的。如1200条通用词可开展同语系的词汇比较研究或不同语系间的对比研究;以语族为单位的1800条扩展词加上1200条通用词共计3000条词汇可为同语族少数民族语言之间的初步比较研究提供可能。此外,经过扩展后的语料资源也可为在线词典、在线教材、语言地图集的编制提供基础。经长期建设的语保工程民语语料资源还可持续地为语言学及相关专业的本科生、硕士生、博士生撰写学位论文提供选题,并同时为少数民族语言资源的深度开发和应用贡献力量。
中国少数民族语言的识别和方言、土语的划分等虽然经过近百年数代人的努力,取得了目前的成就,但仍存在一些遗留问题,甚至还因语言的系属定位、语言身份定性等方面在国内外语言学界始终存在着较大分歧(孙宏开2005,2013;黄行2018)。少数民族语言资源的深度开发应用将为此提供大数据支持,也将有极大的可能通过大量有力的佐证而达成国内外语言学界的共识。极具特殊的学术研究价值的混合语一直也是国内外语言学界长期争论的焦点,主要涉及其概念、性质、特征等内容。民语语料资源中的6种混合语样本将为此提供个案及对比样本,也将为学界进行充分甄别、定性、定位等研究提供相关数据和语料支持。
(二)智能化软件与文创产品研发及应用
少数民族语言资源的开发应用是一项极其繁重的工作,仅语料的标音、翻译、标注等工作,就需要耗费大量时间、精力。由于语保工程一期相关软件开发应用的滞后,许多语保人在模板整理的工作中耗费了大量时间和精力,苦不堪言。虽然目前情况有很大改善,但某些软件仍存在各种不太适合民语语料资源的整理和开发应用的问题,还需进行改进和磨合。因此,语保工程尤其是“后语保”时期,少数民族语言资源的保护及开发应用迫切需要相关的各种软件,以节省大量的人力与時间。
简言之,语言资源的开发利用应“与时俱进”地共享现代科技和互联网经济带来的各种便利条件和先进手段,如通过各种新媒体形式、网络、手机APP应用软件等助力语言资源的开发利用。编撰各种音像同步,图文声并茂的教材、数字词典、APP词典等,词典也应努力开发为多种语言对照,并附上音频或视频例句,也可在新媒体平台上将目标语言的数字化信息及音视频资料予以开放,为需求方提供各种服务。构建内容涵盖民族学、人类学、语言学、宗教学、教育学、文化学、旅游学等多行业的领域知识图谱,实现多领域多学科知识的多维度关联与信息共享,满足相关领域的不同需求。开展诸如自然语言理解、人工智能、智慧系统建设等特定语言服务产品的研发,其成果也将反哺少数民族语言资源的开发应用事业。
另外,中国少数民族语言资源复杂多样的特征决定了少数民族语言资源开发后的应用也具有多元性。其中,少数民族语言资源开发应用的语言服务领域十分广阔,也极具发展前景,同时兼具社会效益与经济效益,最易形成语言产业。而最具潜力的是民族语言资源的翻译,这也是目前在开发上取得初步规模并在应用上已初见成效的一个领域。此外,面向国家和社会安全领域,国家安全需求的公安刑侦语言系统、语言特征鉴别系统的少数民族语言资源的应用也具有极大空间,并将在维护国家和社会安全等方面做出应有的贡献。
少数民族语言资源的开发应用还可为国家民族语文政策、中国语言国情、国家语言安全等多个领域提供咨询服务。如对近年来国家的语言政策发生的变化予以大力宣传和科学解读,尤其是通用语与少数民族的关系问题和民族地区的双语教育问题等,亟待基于少数民族语言资源保护及开发应用的成果提供更多的科学依据。
三、关于分类开发应用的问题
(一) A类语言
语言翻译层面上的开发应用在A类及部分B类少数民族语言资源中可谓独占鳌头。尤其是数种具有传统通用文字的民族语言,因已有雄厚的资源积累及开发基础,极具广阔的深度开发应用前景。其中,“中国民族语文翻译局(中心)”作为国家级民族语文翻译机构,一直致力于民族语文软件的研发与推广应用工作,已陆续完成了蒙古文、藏文、维吾尔文、哈萨克文、朝鲜文、彝文、壮文(新创文字)等7种民族语文电子词典及辅助翻译软件。目前,蒙古、藏、维吾尔、哈萨克、朝鲜、彝、傣、壮等数种具有文字传统的民族语言资源已经在标准化、规范化、信息化等“三化”方面取得了较好的业绩,并在翻译、编辑、出版等方面积累了大量的资源,有的已经出现了大量相关的语言资源衍生品。民族语文智能翻译,特别是智能语音翻译的深入研发,也已列入“十三五”期间国家语言文字工作、民族工作、信息化工作的重点内容。近期,已有蒙古、藏、维吾尔、哈萨克、朝鲜、彝、壮等7种民族语文近40款机器翻译软件相继研发成功并推广应用,受到社会各界广泛好评(江白2018)。近期,中国民族语文翻译中心与内蒙古蒙科立蒙古文化股份有限公司举行了战略合作签约仪式,蒙古语文人工智能技术也已经提到议事日程上来。其中涉及蒙古语文人工智能技术合作及产品研制推广等相关内容。语言翻译的产业化过程也将带动诸如民族语言教育、民族语言出版、民族语言测试等领域资源的开发和应用。
(二) B类语言
B类语言中包括部分人口数量较多的民族,也包括了部分人口数量不多但有新创文字的民族,如布依族、苗族、侗族、哈尼族、傈僳族等使用的是中华人民共和国成立后新创制的拉丁字母文字。另外,因考虑到某些语言的内部方言甚至土语间分歧较大,根据不同的语言的情况还创制了多种文字,如苗族有黔东苗文、湘西苗文、川黔滇苗文、滇东北苗文共4种文字。新创文字为上述民族的语言资源传承和保护起到了重要作用。但鉴于上述情况,该类语言适宜以不同方言为单位实施个性化开发应用方案。
(三) C类语言
此类语言中,包括了部分有传统文字的民族,如柯尔克孜族、锡伯族、俄罗斯族;也包括部分拥有新创文字的民族,如土族、景颇族。也有部分不属于人口较少民族的东乡族、仡佬族、拉祜族、佤族、水族、纳西族等。这几个民族的人口数量在31万至70万之间,整体仍显人口偏少。其语言因使用人口较少,大多数都主要在家庭语言环境中使用,缺少社区这样的语言强化群体氛围,导致传承进程中出现各种缺失或磨蚀现象。母语个体仅在家庭环境中熏陶和成长,可能会获得并巩固其母语能力,但从语言能力发展来说还需要一个重要环节,就是母语能力的强化过程。母语的强化有多种途径,包括社区母语环境、母语的书面形式——文字、学校母语文教育、使用母语的各種媒体形式等。就个体成长的单一的家庭母语环境来说,社区环境无疑是母语个体更大的语言操练课堂。在这个更大的母语环境中,母语个体的口语能力会得到进一步的实质性提升和拓展。一般来说,享有一定社会地位且母语个体数量占优势的社区环境里,母语的使用密度相对较大,使用频度也高。这样,无形中就营造了一个良好的社区母语环境,个体在家庭氛围内获得的母语在更大的语言交往环境中得到了进一步巩固和强化。
(四) D、E类语言
这两类语言中除了人口数量较多但趋于衰亡的满族和土家族这两种语言外,绝大多数是5万以下的人口较少民族,除俄罗斯族以外均无文字,总数上超过了30种。整体特征表现为母语使用人口稀少,绝大多数母语人普遍年龄老化,家庭和社区母语环境缺失而导致代际传承出现严重危机。这两类语言的当务之急是抢救性保护现存的活态语料,并加速完成语言文化典藏的语料采集和濒危语言志的撰写任务。
四、结 语
(一)语保工程一期民语调研专项任务所获巨量少数民族语料资源数据,反映了中国少数民族语言资源的分布上以汉藏语系和阿尔泰语系语言为主,从各调研点发音合作人遴选过程中透露的信息体现了不同类别的语言间语言资源保持类型上存在着显著差异,这些数据及相关信息为我们进行后续工作推进提供了可靠信息和科学依据。
(二)基于相关调研数据所提供的信息,并根据实际情况,中国少数民族语言资源的开发应用可采用整体统一开发和分类开发两种思路。统一开发主要聚焦于大数据研发及服务、智能化软件及文创产品的研发应用等方面。分类开发则应着眼于语言资源保持类型的不同特点,实施深度开发应用、深度规范性的开发应用、深度保护性开发应用及深度典藏性开发应用等。
(三)中国少数民族语言资源的开发应用的长远规划和具体实施方案必须秉持实事求是的态度,依据相关数据和信息,力求做到精准、科学、可行,避免一刀切或削足适履的做法。
(四)语言资源开发应用是一个系统工程,也是一项长期的人文关怀工程。需要参与各方秉持工匠精神,拥有人文情怀,齐心协力,同舟共济。在夯实语言资源保护与开发应用基础之上,统一认识,更新理念,整合资源,科学规划,积极探索可持续发展的新路径。
参考文献
戴庆厦 1993 《跨境语言研究》,北京:中央民族学院出版社。
丁石庆 2018 《中国语言资源保护工程民语语料资源的质量、价值和效用——以少数民族语言为例》,《暨南学报》第5期。
黄 行 2018 《中国民族语言识别:分歧及成因》,《语言战略研究》第2期。
黄 行,许 峰 2013 《我国与周边国家跨境语言的基本情况与问题》,《中国语情》第3期。
江 白 2018 《中国民族语文翻译局藏文智能翻译软件发布会在成都举行》,http://www.tibet.cn/cn/news/yc/201806/t20180606_5916359.html。
孙宏开 2005 《用科学的眼光看待我国的语言识别问题》,《语言文字应用》第3期。
孙宏开 2013 《关于语言身份的识别问题》,《语言科学》第5期。
周庆生 2013 《中国跨境少数民族语言类型及人口状况》,《中国语情》第3期。
朱艳华 2016 《论跨境语言资源保护》,《贵州民族研究》第3期。
责任编辑:魏晓明
猜你喜欢
科教新报(2022年13期)2022-05-23
儿童故事画报(2020年10期)2020-10-30
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
科学家(2016年3期)2016-12-30
新高考·高一数学(2016年3期)2016-05-19
小学教学参考(综合)(2016年5期)2016-05-06
考试周刊(2016年14期)2016-03-25
新高考·高一物理(2015年11期)2015-12-24
