
一种结合Bigram语义扩充的事件摘要方法
2019-07-09 11:43吴佳伟
小型微型计算机系统 2019年7期
吴佳伟,曹 斌,范 菁,黄 骅
1(浙江工业大学 计算机科学与技术学院,杭州 310023) 2(中国电信股份有限公司浙江分公司,杭州 310014)
1 引 言
近年来,以UGC(User Generated Content)为代表的短文本在各类社交媒体中成井喷式增长,同时,这一类短文本还出现在一些企业的客服系统中,这些客服系统与专业领域紧密结合,分析这些短文本,从中检测出一些用户投诉的热点事件,可以帮助企业有效改进他们的服务.而对热点事件进行事件摘要可以进一步帮助企业理解事件的主要内容,以便企业可以及时针对用户投诉的热点事件做出及时决策与相应的调整.在本文中,我们主要集中于从描述同一事件的短文本集合中提取一组关键词并扩展,从而达到提取出的事件摘要可读性强,能够帮助人理解的目的.在这里,我们假定描述同一事件的短文本集合已经事先知道,而在实际中,这一集合可以通过无监督的聚类方法或有监督的分类方法获得,这取决于实际的应用场景.
然而,传统的文本摘要方法并不能直接使用在我们的问题中.因为传统的方法一般应用于长文档,且大多数方法是基于句子做的[1,2],这种方法对文章中每个句子计算一个得分,最后选择得分较高的句子作为文本摘要反馈给用户.虽然这种方法提取出来的句子可读性较强,但是往往一个句子中不会包含许多的关键词,不能很好的概括整个事件;其次,一些基于关键词提取的事件摘要算法[3,4]虽然可以从事件短文本集合中提取出较多的关键词,但是这些关键词之间由于不存在词序,且关键词之间相对独立,因此借由这种方法提取的事件摘要的可读性并不是很好.
综上考虑,在本文中,我们提出了一种基于Bigram关键词语义扩充的文本摘要方法.我们的方法首先通过一种基于Single-Pass的IDF计算方法在短文本集合中提取关键词词组,然后根据事件短文本集合中每个关键词词对出现的频率对提取出来的关键词词组进行了排序,最后我们引入了Bigram语言模型对得到的关键词词组进行了语义扩充.实验证明,相较于一些现有方法,我们的方法在中文数据集的表现上具有较高的召回率与较好的用户可读性.
2 预备知识
为了能够帮助读者更容易理解我们的方法,在本章中,我们介绍了一些预备知识,具体分为如下几点.
2.1 TF-IDF
当我们需要抽取一篇文档或者多篇文档的关键词时,一个直观的想法就是直接统计所有词在文档中出现的次数,即词频.但是在实际操作中,通过上述方法得到的关键词往往都是一些类似“的”、“我”这样的噪声词.这些噪声词虽然具有很高的词频,但是它们并不能成为一篇或者多篇文档的关键词.因此,TF-IDF[5](Term Frequency-Inverse Document Frequency)的思想就应运而生了.
TF-IDF是一种用于衡量一个关键词在一篇或多篇文档中的重要性程度的一种指标.这种方法在现今的数据挖掘、文本处理、自然语言处理等领域都得到了较为广泛的应用.TF-IDF算法的主要思想是:如果一个词或者短语在一篇文章或者一个句子中出现的次数很高,但是这个词在其他文章或者句子中出现的次数很少,那么就认为这个词对于这篇文章或者这个句子来说就是一个关键词.TF-IDF实际上就是 TF*IDF,其中TF(Term Frequency),表示一个词在文档中出现的总次数,一般来说,因为不同的文档包含的词个数也不同,为了避免不同文档的长度对这个指标的影响,因此在最终计算中,会对这个指标进行归一化处理;IDF(Inverse Document Frequency),其主要作用是降低类似于“我”、“的”这种噪声词的权重,提高关键词的权重,从而达到突出关键词重要性的作用.IDF的计算公式如公式(1)所示:
(1)
其中,Textnumber代表语料库中文档的总条数,wtextTF代表包含词w的文本数.分母之所以要加1,是为了要避免分母为0的情况.TF-IDF值就是在此基础上将每个词的IDF值与其词频相乘得到的结果.
2.2 N-Gram语言模型
统计语言模型[6](Statistical Language Model)它是今天所有自然语言处理的基础,并且广泛应用于机器翻译、语音识别、拼写纠错等方面.换句话说,统计语言模型中包含了训练语料库中所有文本单元可能的排列组合情况对应的出现概率.一个句子的出现概率就是通过几个条件概率相乘得到的.而如何去计算这些条件概率,就是统计语言模型所做的工作.举个例子,假设句子S是由词序列w1,w2,w3…wn组成:
S=w1w2w3…wn
则根据条件概率公式,S出现的概率可以表示为:
(2)
其中,p(wk|w1w2…wk-1)表示第1个词到第k-1个词出现的前提下,第k个词出现的概率.
但是,在实际应用中,当k越变越大时,统计w1w2…wk-1出现的条件下wk出现的概率往往不太符合实际情况.因此,N-Gram模型被提出.
N-Gram模型[7]也被称为n-1阶马尔科夫模型,它是统计语言模型的一种简化方式,它建立在如下的假设上:第n个词的出现概率仅仅与其前面的n-1个词相关.
因此,根据N-Gram的假设,则公式(1)可以表示成:
(3)
特别地,当N = 2时,即每个词仅与其前一个词有关,则更改公式(3)成:
p(S)=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
(4)
根据条件概率的定义,为了计算p(wn|wn-1),模型需要从大量的训练语料库中统计wn-1,wn这一词对前后相邻出现的次数以及wn-1这个词在同一语料库中单独出现的次数.即有:
(5)
其中,f(wn-1,wn)代表词对wn-1,wn在语料库中前后相邻出现的次数,f(wn-1)代表词wn-1在同一语料库中出现的次数.
另外,对于N-Gram模型,N可以取任意数字.特别地,当N分别取1、2、3时,得到的N-Gram模型分别称为Unigram、Bigram和Trigram.当然,N越大,可以刻画语言结构越准确,但是越大的N取值会造成更大的计算量与更稀疏的模型等问题,这将对算法的存储效率带来巨大的挑战[8].在实际应用中,一般取N=2或者N=3就可以达到较好的实际使用效果,且训练Bigram或者Trigram模型不需要消耗大量的时间.在本文的算法中,N取2,即,本文使用Bigram模型对关键词进行语义扩充.
3 相关工作
面向事件的自动摘要是指从短文本集合中抽取事件相关的信息并进行有效地组织[9].通过事件摘要,人们可以及时了解事件的大致信息.在本文中,每个事件由一定数量的短文本组成,因此对事件进行摘要的任务就转换成为对文本进行自动摘要的任务.
现有的自动文本摘要大致可以分为两类:抽取式(extractive)和生成式(abstractive).抽取式方法抽取原文本中的部分信息,但并不对其进行修改.生成式方法则需要系统去理解文章的内容,应用一系列自然语言处理的方法,生成与原文语义相近的摘要.显然,我们的方法属于前者,因此接下来我们将在本章简单介绍在自动文本摘要领域的相关工作.
做自动文本摘要的最简单易懂方法是基于统计的方法.除了基于词频的方法[10]与基于TF-IDF的方法[11]以外,基于词汇链(lexical chains)的自动摘要方法[12,13]也是一种比较简单可行的方法,该方法不再以单个词作为分析单元,而是利用WordNet、维基百科等对词汇的语义进行分析,把原文中与某个主题相关的词集合起来,构成词汇链.这一类方法虽然简单易用,但是提取出来的文本摘要的可读性并不是很好,通常仅凭少数且无序的关键词,人们往往不能很好的了解所发生的事件的真实情况.
还有一种比较常见的方法是基于图排序的自动摘要方法.Ricard等人[14]指出,在基于图排序的自动摘要方法中,构成结点的往往是词、句子等文本单元,结点之间以句子相似性、词共现关系、语义相似性、句法关系等相连接以构成文本关系图,接下来再应用图排序算法来计算每个节点的重要性得分,最后再在此基础上生成文本摘要.TextRank[15]和LexRank[16]是这类方法的代表方法.在上述两种方法中,他们把每个句子作为图的顶点,句子之间的相似度作为边的权值.耿焕同等人[17]则是利用句子之间共有的一些词,提出了一种基于词共现图的文档自动摘要算法这类方法.但是在计算的时候需要得知全部的文本单元与每个文本单元之间的关系,这对算法的空间复杂性提出了较大的挑战.同时,上述方法并没有考虑关键词之间的顺序对文本摘要可读性的影响.
还有一种方法是基于主题模型的方法来进行自动摘要.这一类方法首先需要确定文档中有几个主题,然后选择对主题描述较好的词汇,之后按照一些语法规则组成句子、段落、篇章等[18].Hofmann[19]提出的PLSA模型认为:一篇文档可以由多个主题混合而成,而每个主题都是由一些词的概率分布组成.而LDA[20]在PLSA的基础上加入了Dirichlet先验分布,是PLSA的突破性的延伸.但是,直接使用传统的LDA或PLSA可能不能很好地用于短文本的主题建模.当然,之后也有许多学者在LDA主题模型上进行改进,例如Labeled-LDA[21],Twitter-LDA[22],MB-LDA[23]等.这些模型均是在社交媒体的大背景下被提出,应用于事件摘要,但是采用这类方法提取出的事件摘要不具备很好的可读性,在实际操作中往往效果不会很好.
4 基于Bigram关键词扩展的事件摘要技术
在本章中,我们将主要介绍我们的事件摘要方法.其主要流程如图1所示.可以看到,短文本流数据在经过数据预处理与事件检测步骤后,每个事件由一定数量的短文本组成.其次,为了生成可读性较强的事件摘要,每个事件需要经过如下两个组件:关键词提取与Bigram语义扩展.关键词提取组件通过计算每个事件中每个词的IDF值来从每个事件中提取出关键词;然而,仅仅只用几个关键词来做事件摘要是不够的,因为只通过少数且无序的关键词,人们往往无法明白事件的真正内容.因此通过Bigram语义扩充组件,我们将上述提取出的关键词进行排序和语义扩充,使每个事件摘要的可读性更强,包含的语义信息更多.接下来我们将详细介绍我们算法的每个组件.
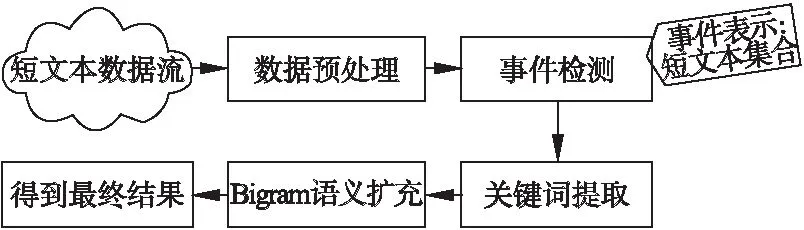
图1 事件摘要方法整体架构图Fig.1 Framework of event summarization algorithm
4.1 关键词提取组件
度量一个词对一个事件是否重要的一个简单方法是看这个词在这个事件对应的文本集合中的词频高低.从理论上来说,这是一种很直观的方法,如果在事件检测中检测到的事件大多描述同一件事,那么事件核心词的出现频率应该很高.然而在实际操作中,这种方法并不适用于短文本的关键词提取.在短文本集合构成的事件中,由于短文本本身短且噪声多的特点,许多事件的文本经词频统计后排在前几位的往往是一些噪声词而非事件的核心关键词.因此,在本组件中,我们使用IDF来对每个事件进行关键词的抽取.
传统的IDF计算方法是针对每个词来说的,即针对每一个词w,统计这个词在当前文本集合中出现的文本条数Textw.可以注意到的是,Textw并不一定和w的词频是完全相等的,因为我们不排除一条文本内可能出现多次词w的情况.这种方法虽然在计算上比较直观,但是在集合中文本数量较大的情况下,这种方法是极其耗时的.因此在本文中,我们提出了一种基于Single-Pass的IDF计算算法.其伪代码如算法1所示.
该算法的主要步骤介绍如下:
1)按顺序遍历输入的文本分词列表Lists,针对每条文本分词s,对其进行词去重.(line 2-3)例如现有一条文本分词s为:w1,w2,w1,w3,则去完重复的词后s为:w1,w2,w3.这么做的原因是,根据公式(1)中IDF值的计算方法,为了计算一个词的IDF值,我们需要计算在当前语料库中包含该词的文档数.因此在去完重复的词后,再对剩下的词进行词频统计,得到的结果即为语料库中包含各个词的文档数.
2)完成单条文本去重后,统计剩下的文本分词结果中每个词的词频.(line 4)
3)接下去针对每个词,我们得到包含该词的文本条数以及当前语料库中总文本条数,再应用公式(1)计算每个词的IDF值后存入Mapidf.(line 6-10)
4)当所有词的IDF值都计算完毕后,返回Mapidf.(line 11)
最后,关键词提取组件将从上述列表中提取IDF值最高的top-K个词作为事件关键词.
算法1.基于Single-Pass的IDF计算算法
输入:一个事件对应的文本分词列表Lists
输出:该事件中对应的每个词的IDF值列表Mapidf
1. 初始化Map:MapTextTF用于存放词w在当前文本集合中出现的文本条数Textw.
2. FOR EACHs∈ListsDO
3. s = Distinct(s);
4. 统计s中每个词的出现次数存入MapTextTF
5. END FOR
6. FOR EACHw∈MapTextTFDO
7.wTextTF=MapTextTF.get(w);
8.wIDF=Cal_idf(wTextTF,Lists.size());
9. Mapidf.put(w,wIDF);
10. END FOR
11. RETURN Mapidf
4.2 基于Bigram的关键词扩展组件
在关键词提取组件获得一个事件的关键词后,为了让提取出的关键词具备更强的可读性,在本小节中,我们提出了一种基于Bigram的关键词扩展方法.算法流程图如图2所示.
从流程图中我们可以得知,本组件的输入是需要进行事件摘要的文本集合、关键词提取组件提取的关键词词组和事件特征词列表.
首先,组件需要加载Bigram模型.这个模型是事先通过大量语料进行训练的,根据Bigram的定义,这个模型中存储的是在大量语料库中每个词与其他词前后相邻出现的次数以及每个词单独出现的次数的统计值.之所以采用这种方式进行存储,目的是当新的语料到来时,我们可以方便的进行增量训练.若模型文件中存储的是每个词对出现的概率,当新的语料到来时,这种方法必须将新语料和旧语料进行合并再次进行模型训练,这是相当费时的.因此我们采用了直接存储词频的方式.当新的语料到来时,我们只需要将新语料中每个词对和词出现的频率统计出来累加到模型中,这样既减小了训练时间,又实现了模型的增量训练.
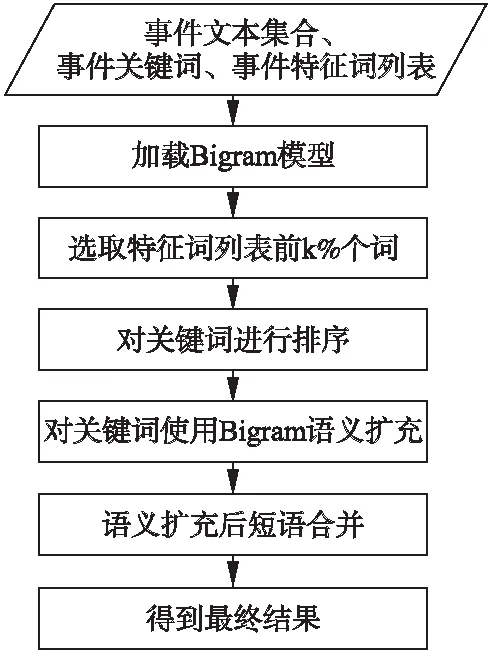
图2 基于Bigram的关键词扩展组件流程图Fig.2 Flow chart of Bigram-based keyword expansion component
其次,组件会在事件特征词列表中选择排名前k%的词.由于事件特征词列表是根据每个词的TF-IDF值进行排序的,因此排名越是靠后的词对事件的贡献程度越不突出.为了避免这些词对算法的干扰,我们在这里仅选择事件特征词列表中选择排名前k%的词,其中,k为一个可调整的参数.
由于关键词之间不同的顺序会造成完全不同的含义,例如“计算机 学会”和“学会 计算机”.这两种情况所表达的意思完全不同.前者可能表示的是一个组织,而后者则是表示某人学会使用计算机的某种程序.因此,为了还原关键词之间本来的顺序,消除歧义,我们需要对输入的关键词词组进行排序.首先,为了确定两个关键词w1,w2之间的前后关系,我们引入了事件原文本作为排序依据,分别在事件原文本中统计词对
当所有的关键词词组依据事件文本排好序后,下一步就是对每个关键词进行Bigram语义扩展.针对每一个关键词,本文需要将其进行前后扩充,直到扩充后的词个数为m.在本文中,m取3,即把一个关键词扩充为3个词的组合.根据Bigram的定义,我们需要将关键词与特征词集合中的每个词组合计算概率,最后选择出现概率最高的词作为该关键词的扩展词.可以注意到的是,在这一过程中我们设定了一个概率阈值τ,当最后选择的出现概率最高的词的概率都不大于该阈值时,我们就放弃该词的扩展.
最后,当我们把所有词进行扩展后,假设关键词w1,w2,w3已经被扩展为waw1wb,wbw2wC,w3,可以观察到,w1,w2扩展后的词对间wb是相同的.根据Bigram的定义,若将wb继续向后扩展,得到的词一定是w2.因此,我们在最后一步中将两个扩展后的词合并,即当第一个词向后扩充的词与第二个词向前扩充的词相同时,通过删除重复的词将这两个扩展结果合并,因此就能得到最后结果waw1wbw2wC,w3.
5 实 验
5.1 数据集与数据标注
本文实验中采用的数据集是来自某电信公司业务部门提供的 2017 年 11月的投诉工单,一共包含2256条文本数据,其中囊括了该电信公司真实发生的24个事件,而且投诉工单的平均文本长度大约在140个字符左右.
在数据标注方面,我们请该电信公司的业务人员逐一看过每个事件的文本后,再根据他们平日的业务经验对每个事件进行归类、标注.
对于Bigram模型的训练,本文同样采用了该电信公司业务部门提供的投诉工单,共300000条文本记录.另外,电信公司的业务人员还提供了一个适用于电信领域的专业名词词库,通过该词库我们可以降低在关键词提取的过程中噪声的影响.
当然,在数据集选择上,本文亦可采用英文数据集,在使用时仅需提供相应语料即可.
5.2 评估方法
针对本文提出的算法得到的摘要结果,我们采用了几个广泛使用的评价指标来评估我们的算法的有效性.例如准确率、召回率、F值等.准确率和召回率是信息检索领域中两个较为重要的指标,准确率反映算法对不同主题的区分能力,准确率越高,每个类中的内容就越集中;召回率主要用来衡量算法结果与人工标注的吻合程度,召回率越高,则算法结果越符合实际情况;F值是综合准确率和召回率的评价指标,其值介于 0 到 1 之间,反映了算法的综合性能.本文采用的准确率与召回率的公式如下:

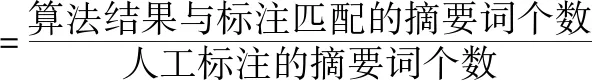
5.3 IDF与专有名词词库的有效性
在本节中,我们将通过实验证明IDF与专有名词词库在短文本关键词选择中的有效性.由于在短文本数据集中,TF-IDF是公认的效果较好的方法,因此在本节中,我们选择TF-IDF作为我们的对比方法.相关实验结果如表1所示.
表1 采用TF-IDF、IDF与专有名词词库进行关键词提取的效果对比
Table 1 Comparisons of keyword extraction results using TF-IDF 、IDF and jargon dictionary

方法召回率(%)准确率(%)F值(%)TF-IDF43.402834.166737.6172IDF52.847241.666745.9043TF-IDF+专有名词词库68.263953.333358.7762IDF+专有名词词库83.055664.166771.1373
从表1中我们可以看出,使用TF-IDF值做关键词提取与仅使用IDF值做关键词提取的结果大不相同.仅使用IDF做关键词提取的结果在召回率、准确率与F值上均高于使用TF-IDF值做关键词提取的结果.而且,通过在分词过程中加入专有名词词库过滤后再采用两种特征值进行关键词提取,其结果也是明显高于不使用专业名词词库进行关键词提取的结果.这是因为通过专业名词词库对分词结果进行过滤,可以减少噪音的影响,从而提升了效果.
5.4 算法参数选择
在上一小节中,我们可以得出,在进行关键词提取中使用IDF值作为特征值以及使用专业名词词库对实验结果的有效性.在本节中,我们将具体讨论在算法中的两个参数“k”(选择前k%的关键词进行语义扩展)与“τ”(低于该阈值将不再扩展)对我们算法准确率、召回率以及F值的影响.实验结果如图3所示.
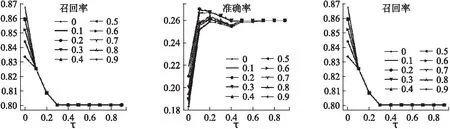
图3 不同的k值与τ值对算法召回率、准确率与F值的影响Fig.3 Influence of different k values and τ values on algorithm recall,precision and F value
其中,横坐标表示不同的τ值,不同的折线代表不同的k值,纵坐标表示在不同的τ值和k值影响下的算法召回率、准确率和F值的结果.从图中可以看出,当k值与τ值在不断变化的时候,算法的召回率在下降,而准确率和F值在提升,最后趋于平稳.这是因为当τ值不断变大时,Bigram不再在当前关键词的基础上再加以扩展,因此结果也就接近于仅使用IDF与专业名词词库提取出的关键词摘要的结果.此外,k值则影响着算法选择多少候选词汇对关键词进行扩展,当k值过大时,候选词汇过多,带来的噪声也会较大,但会提升摘要的可读性(准确率),反之亦然.
5.5 方法对比与实验分析
为了展示本文方法的有效性,我们将本文的方法与如下的一些现有方法进行对比:
·选择事件特征词列表中词频最高的top-K个词.
·选择事件特征词列表中TF-IDF值最高的top-K个词.
·TextRank是一种基于图排序的文本摘要方法,我们选取由TextRank计算后得到的top-K个词作为事件摘要.
表2 现有方法与本文方法的对比
Table 2 Comparisons of the state-of-art algorithms
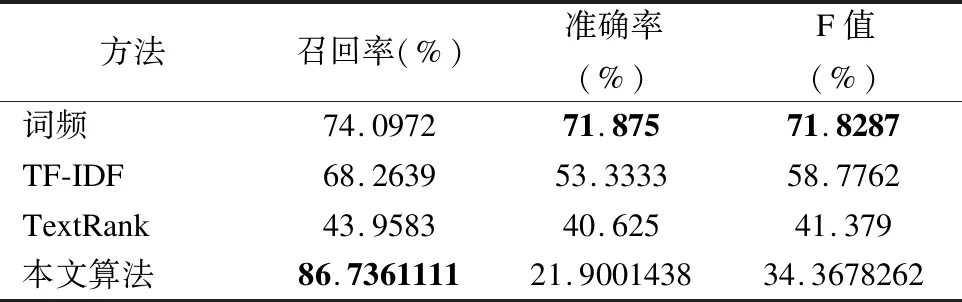
方法召回率(%)准确率(%)F值(%)词频74.097271.87571.8287TF-IDF68.263953.333358.7762TextRank43.958340.62541.379本文算法86.736111121.900143834.3678262
针对上述所有方法,我们采用了同一份数据集,进行相同的数据预处理以及人工标注进行实验.因为上述四种方法中均采用了选取top-K个词进行文本摘要,在我们的实验中,考虑到人工标注的词长度均在4个词左右,因此我们选择K=4.实验结果如表2和表3所示.
表3 现有方法与本文方法的结果对比(关键词间有顺序)
Table 3 Examples of the state-of-art algorithms and our algorithm(Orders between keywords are contained)

人工标注本文算法词频(top-4)TF-IDF(top-4)TextRank(top-4)手机 无法主被叫 信号不稳定 要求核实手机 无法主被叫 信号 不稳定 提示故障 信号 手机 不稳定信号 手机 无法被主叫 提示故障 手机 信号 提示宽带 包年到期转包月收费 不认可宽带 包年到期 转包月 收费不认可 金额 费用不认可 收费 包年到期 宽带费宽带 认可 到期 金额包年到期 不认可 收费 金额积分商城 积分兑换地址 错误省内 积分商城 积分 客户 兑换 地址 客服地址 积分商城 兑换 积分地址 兑换 积分商城 省内积分 地址 兑换 商城增值业务 计费 订购爱游戏 费用 退费增值业务 计费 订购 爱游戏 费用订购 增值业务 计费 费用增值业务 费用 爱游戏 计费增值业务 订购 计费
从表中我们可以看出,基于词频的方法得到了较高的准确率与F值,而我们的方法得到了较高的召回率.因为在文本分词结果经过专业名词词库过滤后,分词结果中仅剩下专业名词.而在电信公司的投诉工单中发生的相关事件经业务人员标注后,人工标注的摘要中大多为电信领域的专有词.所以仅通过统计词频的方法获得了较高的准确率.而本文算法则获得了较低的准确率,这是因为本文算法是基于IDF关键词提取的基础上将关键词进行扩展,因此得到的事件摘要包含的词个数较多,因此准确率较低.但是经过了关键词排序与Bigram语义扩充后的事件摘要可读性更强,用户可以更清楚的明白事件的主要内容.
6 总 结
在本文中,我们提出了一种基于Bigram关键词语义扩充的事件摘要方法.实验结果表明,本文算法在召回率与用户可读性方面取得了较好的结果.如何提升算法效率和算法的准确率,使之能够采用更精炼的关键词个数来描述事件,是我们的下一步工作.实际上,本文的事件摘要算法已经应用于一个真实的客服数据分析系统中,其有效性得到了该系统的服务对象的认可.
猜你喜欢
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
时代英语·高二(2018年7期)2018-12-03
亚太教育(2018年5期)2018-12-01
时代英语·高二(2018年3期)2018-06-06
长江丛刊(2017年27期)2017-12-01
电脑爱好者(2017年5期)2017-05-04
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
阅读与作文(英语高中版)(2013年12期)2013-12-11
