
融合多因素的TFIDF关键词提取算法研究
2019-07-23 09:37牛永洁田成龙
计算机技术与发展 2019年7期
牛永洁,田成龙
(延安大学 数学与计算机学院,陕西 延安 716000)
0 引 言
随着数据时代的到来,各行各业都积累了大量的数据,人们迫切希望从这些数据中发现有趣的知识。自然语言处理研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理融合了语言学、计算机科学、数学等学科,针对非结构化的文本信息进行处理,其中关键词的提取是自然语言处理中的基础与核心技术,在信息检索、文本分类、文本聚类、信息匹配、话题跟踪、自动摘要、人机对话等领域有广泛的应用[1-4]。
目前针对文本关键词的提取,为了取得良好的效果,大都采用专家标准的方法,但是面对日益增多的海量文本信息和迫切的应用需求,人工标注已经显得力不从心。于是借助计算机自动进行关键词提取的方法受到了越来越多的重视,已经成为自然语言处理领域的一个研究热点[5-7]。
关键词抽取方法按照是否进行监督学习分为监督性和非监督性两大类。通过训练数据构建学习模型,进而判断词语是归属于关键词类别还是非关键词类别,属于典型的有指导学习方法。有指导学习需要事先标注高质量的训练数据,人工预处理的代价较高。非监督学习因为无需对数据进行训练,实现快捷,仅需要文本自身的信息就能进行等优点被广泛采用,非监督关键词抽取的主流方法可归纳为三种:基于TFIDF统计特征的关键词抽取、基于主题模型的关键词抽取和基于词图模型的关键词抽取。这些方法都有自己的优缺点[8]。
文中主要针对TFIDF展开研究,综合考虑文本信息中词语的位置、词性、词语关联性、词长和词跨度5种影响因素,对每一种影响因素赋予一定的权重,最后加和得到最终的词语权重,获得权重最大的前5个词语作为文本的关键词。与经典的TFIDF方法及人工标注进行对比,发现文中算法在精确度、召回率和F1值都优于经典的方法,更加接近人工标注,值得推广应用。
1 相关技术
相关技术主要包含TFIDF、词语的位置、词性、词语关联性、词长和词跨度6个方面。设定一个文本集合D,集合中包含N个文本,每个文本T包含标题title和内容content两部分。content内容由若干段落segment组成,段落由换行回车键进行分割。每个段落包含若干句子sentence,句子由若干词语word组成。句子由标点符号“。”、“!”、“?”、“……”进行分割。
1.1 TFIDF算法
TFIDF算法处理的对象是文本的content部分[9-10],其中每个词语word的权重由式1进行计算。
Wtf(i)=tfi*idfi
(1)
其中,Wtf(i)表示第i个词语使用TFIDF方法得到的权重;tfi表示该词的词频,词频为该词在content中出现的次数与content中词语总数之比;idfi表示逆文档频率,计算方法为:
(2)
其中,N为文档总数;dfi为文档中出现词语i的文档数;β为一个经验常数,一般取0.01、0.1、1,文中取数值1。
TFIDF的计算表明,如果一个词语在文本content中出现的次数越多但是在集合D中包含该词语的其他文本数量越少,该词语成为文本关键词的权重越大,文中采用W_tfidf表示词语的权重。
1.2 词语的位置
根据文献[4,8],文本的标题title一般会尽可能包含文本的中心思想,所以出现在标题中的词语成为关键词的概率最大,另外一个文本的第一段往往是全文的初步概括,也能最大限度地体现文章的主旨,所以对出现在第一段中的词语也需要增加权重,末段往往是对全文的总结,因此也需要对出现在末段的词语增加权重。每段内容的首句往往是本段内容的纲领,所以出现在每段第一句中词语的权重也应该适当重视。词语位置的权重设置如表1所示。

表1 词语位置权重设置
1.3 词 性
汉语词性可以分为实词和虚词。实词包含:名词、动词、形容词、数词、量词和代词。虚词包括:副词、介词、连词、助词、叹词、拟声词。关键词词性分布一般是名词或名词性短语为主,其次是动词,最后是数词、副词和其他修饰词等[11]。考虑词性特征可以有效避免传统采用语言学方法的缺陷[12-15],词性的权重设置如表2所示。
1.4 词语关联性
汉语语言的词语之间的关联度在全局上显示出高度的连接性,同时在局部具有高度的聚集性。根据自然语言具有的关联特性,可以作为基本特征进行关键词提取。因为在实践中TFIDF算法的固有缺陷表现为数据集偏斜,类间、类内分布偏差等。在词语关联度算法方面,由于复杂网络仅仅依靠词语之间的相互关系作为基本特征,忽略了单词的频率特征,容易造成关键词提取的聚集特征不明显,从而引起关键词提取的误差[16-17]。将二者相结合可以互相补充,能够更加全面地描述一个词语的权重。
设V={v1,v2,…,vn}为节点集合,(vi,vj)表示节点vi∈V与vj∈V之间的边。设G(V,E)是以V为节点集合,以E⊂{(vi,vj):vi,vj∈V}为边集合的图,则节点vi的度Di为:
Di=|{vi,vj}:(vi,vj)∈E,vi,vj∈V|
(3)
节点vi的聚集度Ki为:
Ki=|{vj,vk}:(vi,vj)∈E,
(vi,vk)∈E,vi,vj,vk∈V|
(4)
节点vi的聚集系数Ci为:
(5)
对于节点vi计算网络综合特征值CFi:
(6)
其中,N表示网络中的节点个数,0<α<1,文中取α为0.5。
对于文本中的每一个句子sentence,将句子sentence中的词语作为节点集合,将各个句子所组成的网络连接,合并相同的节点和连边,就形成一个语言网络。根据文献[13]的研究成果,只考虑词关联跨度为1和2,计算每个词语的度D,聚集度K和综合特征值CF。使用CF值作为词语word的词关联性权重 W_cf。
1.5 词 长
经过研究发现,一个文本的关键词的词长一般大于2,所以可以将词长小于2的词语过滤掉。关键词词长越长,包含的信息越大,但是关键词词长一般不超过6,因此也可以将词长大于6的词语过滤掉。可以使用式7作为词长的权重。
(7)
1.6 词跨度
一个词的跨段落情况说明这个词是描述局部的还是表达全文的。跨段数越多,说明该词越重要,全局性越强。显然,局部关键词不是需要提取的目标,然而在传统TFIDF算法中,局部关键词往往会因为其高频优势成为整个文档的关键词,降低了提取关键词的准确率[18]。在提取关键词的过程中,为了体现词语的全局性,利用式8来衡量词语的跨度权重。
(8)
2 算法步骤
融合多因素的TFIDF的算法步骤为:
(1)数据清洗:将文本中的噪声数据清除,比如文本中多余的空格、 、#、*、[、』、【、】等字符。
(2)标记:对文本进行段落识别,标记首段、末段,对文本进行语句识别,标记句子的开始和结束和每段的首句。
(3)分词:对文本进行带有词性的分词,分词结果分为两个集合,分别是标题的分词结果和内容的分词结果。文中采用了北京理工大学海量语言信息处理与云计算工程研究中心的NLPIR汉语分词系统进行分词。
(4)停用词过滤:停用词在文本分析中属于一种冗余数据,对文本的主题不具备表达能力,往往具有高频、无意义等特点。例如,“的”、“啊”、“但是”等词语以及标点符号通过去除停用词,能消除对关键词提取的干扰。
(5)词性过滤:将文本中经过分词且词性被标记为介词、连词、助词、叹词、拟声词、语气词等词语过滤掉,这些词通常不可能是关键词,同时会增加后续计算的工作量,所以将这些词过滤掉。
(6)词长过滤:将词长长度小于2大于6的词语过滤掉。
(7)采用TFIDF算法计算每个词语的W_tfidf。
(8)根据词语的位置计算每个词语的位置权重。
(9)根据词性分别计算每个词的权重。
(10)计算词语的词关联性权重W_cf。
(11)计算词语的词跨度权重W_seg。
(12)计算词语的词长权重W_len。
(13)根据式9计算词语的最终权重W_all。
W_all=(αW_tfidf+βW_cf+γW_seg+
δW_len)*位置权重*词性权重
(9)
其中,α、β、γ、δ为各种不同权重的加权系数,文中取α为1.5,β为1.1,γ为0.8,δ为0.5。
将计算得到的词语的最终权重按照降序排列,取前5个作为一篇文本的关键词。
3 测试及结论
为了衡量关键词提取算法的优劣,往往采用3个指标作为衡量的标准,分别是准确率、召回率和F1值,其中准确率和召回率是一对相互矛盾的指标,也就是说准确率如果比较高,但是召回率要低一些,综合这两个指标提出了F1值的概念,如果F1值比较高,则说明算法的效果比较好。
准确率通过式10进行计算。
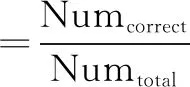
(10)
其中,Numcorrect表示正确提出的关键词数量;Numtotal为总共提出的关键词数量。
召回率通过式11进行计算。

(11)
其中,Numactual为文本实际的关键词数量。
F1值综合考虑了准确率和召回率两个指标,通过式12进行计算。
(12)
本校图书馆对《红色中华》报刊进行了收集和整理,共得到从1931年到1937年6年间的8 045篇新闻文章,其中每篇文章都由标题和正文组成,其中部分文章已经通过红色文献研究专家进行了关键词提取和标注工作。8 045篇文章作为文本的全体样本,每篇文章作为一个文本,按照文中提出的算法进行了关键词提取。通过准确率、召回率和F1值对文中算法、经典的TFIDF算法和专家标注进行了对比,结果如表3所示。
表3 算法对比

%
通过表3可以看出,融合多种因素的文中算法在三个指标上都明显优于经典的TFIDF算法,值得推广应用。但是该算法也有不完善的地方,主要表现在计算工作量大,运行时间长,但是如果作为已经整理好的离线数据源,为了提高关键词提取的效果仍然是一种比较好的方法。通过对文中算法和专家标注的结果进行对比,发现该算法仍然有一些缺陷,主要表现为词语组合问题,比如:专家标注的关键词“满洲傀儡政府”,在文中算法中被分为两个词“满洲”和“傀儡政府”,可以看出文中算法的结果一方面受到分词系统的影响,另一方面应该根据词语的关联度进行词语的组合,但是汉语的语法比较灵活,词语组合规则还很难提取和总结,所以词语组合问题还有待于进一步研究。
4 结束语
通过综合考虑词语的位置、词性、词长、词跨度和词语关联度等多种因素对经典的TFIDF算法进行了改进,对每个因素的权重进行了加权相加或者相乘的运算,得到一个最终的词语权重,然后取权重值最大的5个词语作为文本的关键词,以专家手工标注的关键词为标准,对两种算法进行了对比,发现文中算法效果良好,值得推广应用,同时在研究的过程中也发现了一些不足和缺陷。总而言之,文中算法比较全面地考虑了影响关键词提取的各种因素,具有一定的通用性,能够为其他类似的研究提供思路和参考,具有一定的推广性和借鉴性,同时也为下一步研究指明了方向。
猜你喜欢
心理学报(2022年5期)2022-05-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
校园英语·月末(2021年13期)2021-03-15
健康体检与管理(2021年10期)2021-01-03
当代陕西(2020年17期)2020-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
人大建设(2018年5期)2018-08-16
