
基于资源描述框架图切分与顶点选择性的高效子图匹配方法
2019-08-01 01:57关皓元朱斌李冠宇蔡永嘉
计算机应用 2019年2期
关皓元 朱斌 李冠宇 蔡永嘉


摘 要:在SPARQL查詢过程中,含有复杂结构的资源描述框架(RDF)图的查询效率低下。为此,通过分析几种RDF图的基本结构与RDF顶点的选择性,提出RDF三元组模式选择性(RTPS)——一种基于RDF顶点选择性的图结构切分规则,以提高面向RDF图的子图匹配效率。首先,根据谓词结构在数据图与查询图中的通性建立RDF相邻谓词路径(RAPP)索引,将数据图结构转化为传入传出双向谓词路径结构以确定查询顶点的搜索空间,并加快顶点的过滤;接着,通过整数线性规划(ILP)问题计算建模将复杂RDF查询图结构分解为若干结构简单的查询子图,通过分析RDF顶点在查询图中的相邻子图结构与特征,确立查询顶点的选择性以确定最优切分方式;然后,通过RDF顶点选择性与相邻子图的结构特征来缩小查询顶点的搜索空间范围,并在数据图中找到符合条件的RDF顶点;最后,遍历数据图以找到与查询子图结构相匹配的子图结构,将得到的子图进行连接并将其作为查询结果输出。实验采用控制变量法,比较了RTPS、RDF子图匹配(RSM)、RDF-3X、GraSS与R3F的查询响应时间。实验结果充分表明,与其他4种方法相比,当查询图复杂度高于9时,RTPS的查询响应时间更短,具有更高的查询效率。
关键词:SPARQL查询处理;资源描述框架;子图匹配;图结构切分;顶点选择性
中图分类号: TP181; TP311
文献标志码:A
Abstract: As the graph-based query in SPARQL query processing becames more and more inefficient due to the increasing structure complexity of Resource Description Framework (RDF) in the graph, by analyzing the basic structure of RDF graphs and the selectivity of the RDF vertices, RDF Triple Patterns Selectivity (RTPS) was proposed to improve the efficienccy of subgraph matching for graph with RDF, which is a graph structure segmentation rule based on selectivity of RDF vertices. Firstly, according the commonality of the predicate structure in the data graph and the query graph, an RDF Adjacent Predicate Path (RAPP) index was built, and the data graph structure was transformed into incoming-outgoing predicate path structure to determine the search space of query vertices and speed up the filtering of RDF vertices. Secondly, the model of Integer Linear Programming (ILP) problem was built to divide a RDF query graph with complicated structure into several query subgraphs with simple structure. By analyzing the structure characteristics of the RDF vertices in the adjacent subgraphs, the selectivity of the query vertices was established and the optimal segmentation method was determined. Thirdly, with the searching space narrowed down by the RDF vertex selectivity and structure characteristics of adjacent subgraphs, the matchable RDF vertices in the data graph were found. Finally, the RDF data graph was traversed to find the subgraphs whose structure matched the structure of query subgraphs. Then, the result graph was output by joining the subgraphs together. The controlling variable method was used in the experiment to compare the query response time of RTPS, RDF Subgraph Matiching (RSM), RDF-3X, GraSS and R3F. The experimental results show that, compared with the other four methods, when the number of triple patterns in a query graph is more than 9, RTPS has shorter query response time and higher query efficiency.
Key words: SPARQL query processing; Resource Description Framework (RDF); subgraph matching; graph structure segmentation; vertex selectivity
0 引言
资源描述框架(Resource Description Framework, RDF)是一种描述语义Web中机器信息的标准数据模型,SPARQL是经W3C认证的面向RDF图的标准图查询语言[1],而模式匹配是SPARQL查询处理中的核心问题,其目的是在复杂的RDF图数据中快速地搜索符合查询请求的结果。基于SPARQL图查询语言的性质,其表达模式可由如下所示的基于三元组的关系模型转换为基于图的关系模型(如图1(a)),因此,面向RDF图的模式匹配可理解为在RDF数据图(图1(b))中搜索到同构与查询图的数据子图的遍历过程(图1),该问题也可以称为子图匹配问题[2]。近年来,随着知识图谱被广泛地认知,RDF数据量被大量发布,RDF数据模型对语义数据的表示也更加复杂,而以往的基于RDF三元组的连接处理已不再适用于处理复杂的SPARQL查询,复杂的图结构会导致RDF节点间的重复连接次数与三元组之间的连接次数大大增加;随着三元组之间连接次数的增加,产生大量中间结果冗余的情况也愈发严重,由于RDF查询图的复杂性以及数据海量性使得在SPARQL查询过程中的时间效率很难得到保证[3]。
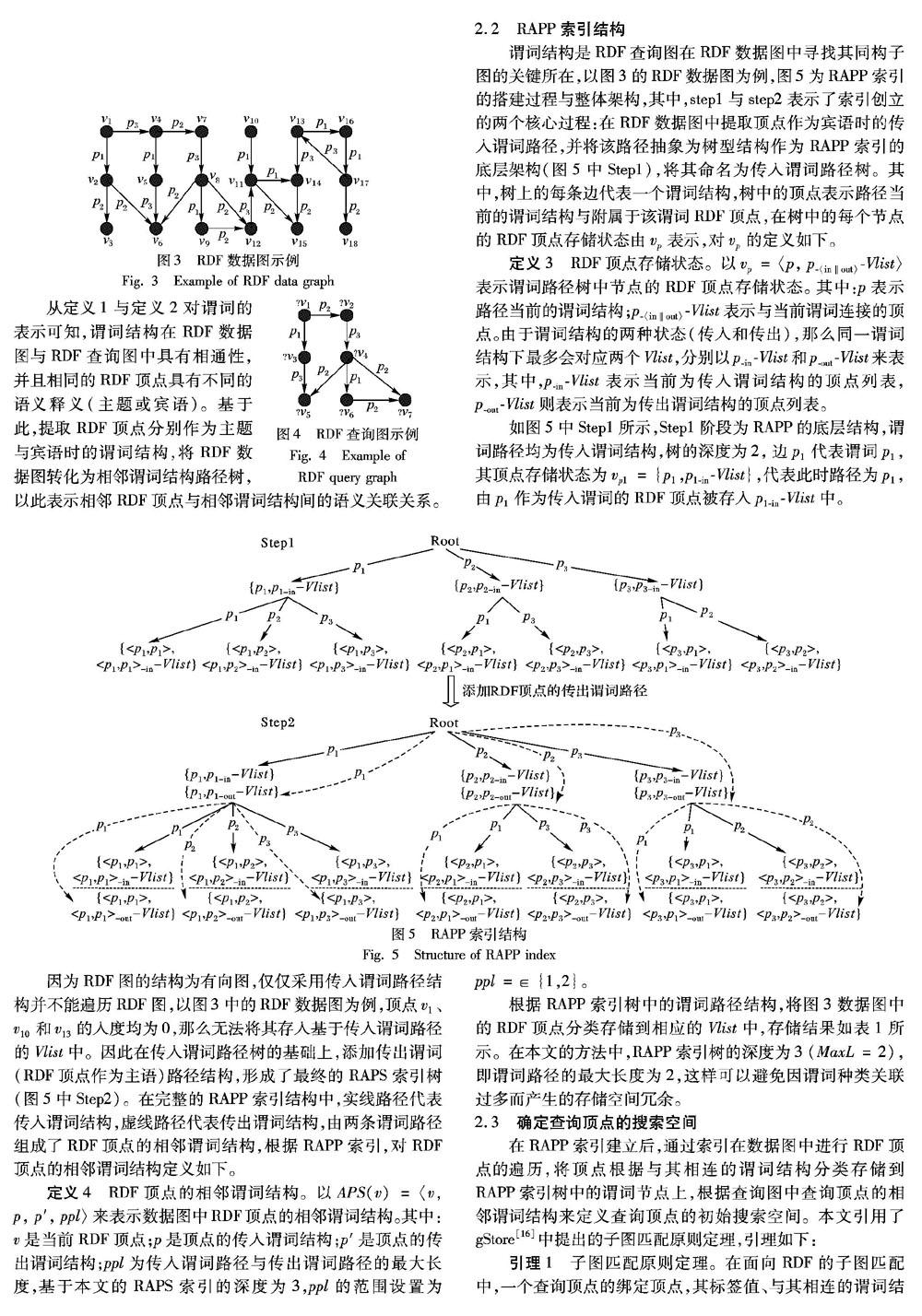
在子图匹配中,如何快速地在数据图中找到与查询图同构的子图是其核心问题,由于RDF图结构的复杂性与顶点的不同选择性(由查询图中顶点的搜索空间和相邻图结构决定)使得在处理复杂查询图时的顶点选择顺序成为了难题。出于对谓词在RDF数据图与查询图中的结构通性的考虑,目前一些解决方案选择了提取RDF图中的传入谓词路径的方法,将RDF图表示为基于顶点的传入谓词路径树,并将顶点分类存储到相应的谓词结构中,在传入谓词路径树中搜索与查询图谓词路径结构相匹配的谓词路径并在数据图中提取该谓词路经所在的子图结构作为查询结果,这种方法虽然缩减了元组模式的连接过程,但是由于有向图的特性,会存在入度为0的RDF顶点而导致该顶点不会被存入索引中,当数据图中某一传入谓词路径过长(路径包含4个或4个以上的谓词),根据排列组合的思想可知,谓词路径树中的谓词结构两两组合将导致其构建代价呈指数上升,并且,将顶点存入相应的谓词结构下,会导致严重的冗余现象从而浪费大量存储空间。
基于此,本文通过挖掘RDF数据图与查询图的结构与语义信息,建立一种高效处理子图匹配问题的方法——RDF三元组模式选择性(RDF Triple Patterns Selectivity, RTPS)。为了保证RDF信息的完整性,在该方法中提出了基于分类思想学方法与RDF顶点选择性的RDF图结构切分规则,并按照该规则将复杂查询图切分为多个结构简单的查询子图,以降低整个执行过程的计算复杂度,减少由于过多的顶点连接而产生的中间结果冗余情况。谓词是RDF数据语义关系的表示形式,在基于图的查询处理中,谓词结构在RDF数据图与查询图中是相通的,通过对该语义信息的分析,提出了基于RDF相邻谓词结构(RDF Adjacent Predicate Structure, RAPS)的倒排索引,索引整体为树型结构,对比以往的单向谓词路径索引,同时考虑了数据图中的顶点作为主题与宾语的不同谓词结构,通过该索引将数据图中的顶点按照不同的谓词结构分类存储以确定查询顶点的初始搜索空间。该索引加快了顶点过滤,而且因为倒排索引的方便性与高效性,不会因为数据图结构复杂而产生巨大搭建代价的后果。在查询图切分之后,通过任意两个相邻的查询子图结构来缩小搜索空间的范围,在最终确定的搜索空间中寻找顶点所在的子图结构并作为查询子图的绑定子图。最后,将几个绑定子图进行连接并作为最终结果图输出。
本文的主要工作如下:
1)提出并建立了RDF相邻谓词路径(RDF Adjacent Predicate Path, RAPP)索引结构。分别提取RDF数据图中顶点作为主题与宾语时的谓词结构,将该结构组成传入传出谓词路径树,树中的节点代表谓词结构。数据图中的顶点按照其谓词结构分类存储至每个谓词结构下的顶点列表V-list中,以便确立查询顶点的搜索空间,加快RDF顶点的过滤。
2)提出了基于整数线性规划(Integer Linear Programming, ILP)建模与RDF顶点选择性的查询图切分规则。将搜索最小子图结构的处理过程抽象为ILP问题的建模,通过顶点的搜索空间与图中的度确立RDF顶点选择性,在得到的多种切分方案下加入对RDF顶点选择性的考虑,最终确定最优切分方案将复杂查询图进行切分以得到若干结构简单的查询子图。
3)给出了基于贪心思想与顶点相邻结构的子图匹配处理过程。在查询图切分之后,将RDF顶点选择性与贪心算法思想相结合,并设计相关算法来表示子图匹配与子图连接的处理过程。
4)与相关方法进行对比以验证本文方法的有效性。分别采用真实世界数据集与合成数据集进行广泛的实验来评估RTPS方法的适用性与高效性,实验过程采用控制变量法,综合实验结果表明RTPS的综合查询处理性能要优于RDF子图匹配(RDF SubgraphMatching, RSM)[5]、RDF-3X[6]、R3F[7]与Grass[8]。
1 相关工作
子图匹配也被称为子图同构,是基于图的查询处理中的核心问题,对该问题的研究已经成为热点[9-10]。本文将目前的一些查询优化方法按照处理模型分为基于RDF三元组的优化方法与基于RDF图特征的优化方法来分别介绍。
1)基于RDF三元组的优化方法。Kalayci等[11]提出了基于蚁群优化(Ant Colony Optimization, ACO)算法的RDF三元组模式重排序方法,其核心在于将三元组模式抽象为权重矩阵,以三元组的选择性作为矩阵的权重,通过蚂蚁自由选择道路所留下的信息素密度,将三元组模式的输入顺序打乱并重新排序。该方法的缺陷在于权重矩阵的构建对于包含环的查询会产生路径冗余的情况,使得蚂蚁信息素的重复产生从而导致权重计算的偏差,最终得到的三元組模式的基数值会高于实际值;而且当输入的三元组模式数量庞大时,ACO算法给出的可行解会在一定程度上偏离最优解。
RDF-3X[6]是一种基于三元组关系表的SPARQL查询引擎,它使用B+树作为底层索引结构,以三元组〈s, p, o〉分别作为索引基准与排序关键Key设计了6种索引属性表来分类存储RDF数据。每个属性表中设置一个查询优化器,它将属性表中的RDF顶点统计信息转换为基于B+树的连接树,连接树决定了查询性能,但是表中的元素在连接过程中产生的自我连接与表间元素的跨表连接会产生较高的查询代价,因此,随着RDF数据量增大,其查询代价呈指数性增长。Jena[12]和Sesame[13]通过建立大型三元组属性倒排列表,以谓词为排序关键Key来将连接同一谓词属性的RDF顶点进行分类存储,在表中可根据谓词同时访问几个RDF属性值并将其进行聚类以提高顶点过滤速度并减少三元组的连接次数,这种基于三元组属性值的倒排列表虽然提高了过滤速度,并以倒排列表的优势减少了存储空间的浪费,但是它需要用户提供聚类决策并保留先前的查询日志,所以并不具有普适性;而且由于表的建立非规范化,很容易导致连接过程中的空值与属性值重复,从而存在查询返回结果为空值的情况,因此降低了查准率。
2)基于RDF图特征的优化方法。该类优化方法普遍通过在RDF三元组的基础上添加对图结构特征的考虑。GRIN[14]使用图分割技术并参考RDF图中顶点距离的信息来建立基于图查询的索引,索引结构为平衡二叉树,其中,树的节点代表一个RDF三元组,这种结构间的转换形式可大大节省数据的存储空间;但是索引结构存储在内存中,当数据量较大时,索引的运行将产生高昂的代价。在g-index[15]中,提出了“子图辨别比率”这一因素,通过一些方法计算子图的“辨别力”,当数据图中某一子图结构“辨别力”很强时,便以该子图作为索引特征项,这使得g-index具有很好的子图过滤性能;但是这种以图结构特征为过滤核心的索引要求RDF数据图必须含有特征鲜明的子图结构,当一个数据图中子图结构的选择性较差时,索引的优势并不能完全体现。
GraSS[8]则是把处理的核心放在星型结构上,以两个星型子图的公共顶点作为索引项并提取其谓词结构和与该谓词相邻的属性值作为索引项,并采取了基于hash函数的模式编码来消减RDF属性值的多样性以增强图结构特征的选择性,通过在含有星型结构的查询图中搜索符合特征项的边界顶点来进行子图匹配,以此来看,GraSS对于星查询的SPARQL查询是十分高效的,但是对于链查询以及环查询则没有好的应对方法。RSM[5]采用了图形切分的方式处理复杂查询图,但是其采用的NP-hard切分模型为了节省时间会把第一个满足条件的切分方式作为最优方式而没有相关的最优验证,因此在图结构十分复杂的情况下,计算得出的切分方式会在一定程度上偏离最优解;并且RSM的连接计划采用了基于元组模式的成本模型,是在处理查询图的同时进行连接,因此会产生少量中间连接结果冗余的情况。R3F[7]通过提取RDF图中的传入谓词路径结构来建立谓词路径索引,其目的是在数据图中寻找与查询图谓词路径相同的子图结构并将其作为查询结果输出;但是仅仅依靠传入谓词路径无法遍历到数据图中所有的RDF顶点,因为有向图的边具有指向性,会存在入度或出度为0的顶点(图1(b)中的RDF顶点”John Davis”),这类顶点无法被遍历,因此导致了查詢过程中产生遗漏现象。
基于上述研究现状的优缺点分析,提出了基于ILP建模与RDF顶点选择性的RDF图切分规则(RTPS),将复杂RDF查询图结构分解为多个结构简单的查询子图,以解决因RDF图结构复杂导致查询图的顶点选择性变弱而在查询中产生大量中间结果冗余的问题。为了体现图切分规则的优势,本文不考虑RDF顶点与谓词的标签值带来的影响(以通配符代替)。在图结构切分之前,首先建立了RAPP索引以确定查询顶点的搜索空间,关于RDF图、SPARQL元组模式的定义与索引结构的建立将在第2章详细阐述。
5 结语
为了提高基于复杂查询图结构的SPARQL查询处理效率,本文提出了基于RDF图切分与顶点选择性的子图匹配方法——RTPS,并设计了相邻谓词路径索引(RAPP)对数据进行预处理以加快RDF顶点的过滤,最后根据顶点选择性与相邻顶点结构进行了子图搜索与连接。本文为整体处理过程提供了相关的问题建模计算与详细实例。在实验评估部分,采用了控制变量法,在真实世界数据集YAGO2、虚拟合成数据集LUBM和SNIB上与主流查询方法RDF-3X、R3F、GraSS及最新子图匹配方法RSM进行的实验验证了RTPS的普适性与高效性。综合实验结果表明,在进行基于复杂查询图结构的SPARQL查询时,RTPS的查询响应时间较短,具有更高的查询效率。在未来的工作中,将对RTPS的可扩展性进行充分研究,使其与Hadoop、Spark等分布式框架相结合,将RTPS应用在RDF动态流数据平台上。
参考文献:
[1] 黄映辉,李冠宇.语义物联网:物联网内在矛盾之对策[J]. 计算机应用研究,2010,27(11):4087-4090. (HUANG Y H, LI G Y. Semantic Web of things: strategy for Internet of things intrinsic contradiction [J]. Application Research of Computers, 2010, 27(11): 4087-4090.)
[2] GROBE M. RDF, Jena, SparQL and the ‘Semantic Web[C]// SIGUCCS 09Proceedings of the 37th Annual ACM SIGUCCS Fall Conference on User Services. New York: ACM, 2009: 131-138.
[3] LIU C, WANG H, YU Y, et al. Towards efficient SPARQL query processing on RDF data [J]. Tsinghua Science and Technology, 2010, 15(6): 613-622.
[4] VILLAZON-TERRAZAS B, GARCIA-SANTA N, REN Y, et al. Knowledge graph foundations [M]// Exploiting Linked Data and Knowledge Graphs in Large Organisations. Cham: Springer, 2017: 17-55.
[5] 關皓元, 朱斌, 李冠宇, 等. 基于RDF图结构切分的高效子图匹配方法[J].计算机应用,2018,38(7):1898-1904,1909. (GUAN H Y, ZHU B, LI GUAN Y, et al. Eifficient subgraph matching method based on structure segmentation of RDF graph) [J]. Journal of Computer Applications, 2018, 38(7): 1898-1904, 1909.)
[6] NEUMANN T, WEIKUM G. RDF-3X: a RISC-style engine for RDF [J]. Proceedings of the VLDB Endowment, 2008, 1(1): 647-659.
[7] KIM K, MOON B, KIM H-J. R3F: RDF triple filtering method for efficient SPARQL query processing [J]. World Wide Web — Internet & Web Information Systems, 2015, 18(2): 317-357.
[8] LYU X, WANG X, LI Y-F, et al. GraSS: an efficient method for RDF subgraph matching [C]// WISE 2015Proceedings of the 16th International Conference on Web Information Systems Engineering, Part I, LNCS 9418. Berlin: Springer, 2015: 108-122.
[9] BUNKE H. Graph matching: theoretical foundations, algorithms, and applications [C]// Proceedings of the 2000 Vision Interface. Montreal: [s.n.], 2000: 82-88.
http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=9256E5E770F37544CDEE0501AD87D2DA?doi=10.1.1.492.1637&rep=rep1&type=pdf
[10] CONTE D, FOGGIA P, SANSONE C, et al. Thirty years of graph matching in pattern recognition[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2008, 18(3): 265-298.
[11] KALAYCI E G, KALAYCI T E, BIRANT D. An ant colony optimisation approach for optimising SPARQL queries by reordering triple patterns [J]. Information Systems, 2015, 50:51-68.
[12] HE H, WANG H, YANG J, et al. BLINKS:ranked keyword searches on graphs [C]// SIGMOD 07 Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2007: 305-316.
[13] BROEKSTRA J, KAMPMAN A, van HARMELEN F. Sesame: a generic architecture for storing and querying RDF and RDF schema[C]// ISWC 2002Proceedings of the 2002 First International Semantic Web Conference, LNCS 2342. Berlin: Springer, 2002: 54-68.
[14] UDREA O, PUGLIESE A, SUBRAHMANIAN V S. GRIN: a graph based RDF index [C]// AAAI07Proceedings of the 2007 National Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2007: 1465-1470.
[15] YAN X, YU P S, HAN J. Graph indexing:a frequent structure-based approach [C]// SIGMOD 04Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2004: 335-346.
[16] ZOU L, ZSU M T, CHEN L, et al. gStore: a graph-based SPARQL query engine[J]. The VLDB Journal, 2014, 23(4): 565-590.
[17] RIVERO C R, JAMIL H M. Efficient and scalable labeled subgraph matching using SGMatch [J]. Knowledge and Information Systems, 2017, 51(1): 61-87.
[18] HE H, SINGH A K. Graphs-at-a-time:query language and access methods for graph databases [C]// SIGMOD 2008Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 405-417.
[19] HOFFART J, SUCHANEK F M, BERBERICH K, et al. YAGO2: a spatially and temporally enhanced knowledge base from Wikipedia [J]. Artificial Intelligence, 2013, 194: 28-61.
[20] GUO Y, PAN Z, HEFLIN J. LUBM: A benchmark for OWL knowledge base systems [J]. Journal of Web Semantics: Science, Services and Agents on the World Wide Web, 2005,3(2/3):158-182.
