
支持高并发访问的新型NVM存储系统
2019-08-01 01:35蔡涛陈志鹏牛德姣王杰詹毕晟
计算机应用 2019年1期
关键词:存储系统
蔡涛 陈志鹏 牛德姣 王杰 詹毕晟

摘 要:I/O系统软件栈是影响NVM存储系统性能的重要因素。针对NVM存储系统的读写速度不均衡、写寿命有限等问题,设计了同异步融合的访问请求管理策略;在使用异步策略管理数据量较大的写操作的同时,仍然使用同步策略管理读请求和少量数据的写请求。针对多核处理器环境下不同计算核心访问存储系统时地址转换开销大的问题,设计了面向多核处理器地址转换缓存策略,减少地址转换的时间开销。最后实现了支持高并发访问NVM存储系统(CNVMS)的原型,并使用通用测试工具进行了随机读写、顺序读写、混合读写和实际应用负载的测试。实验结果表明,与PMBD相比,所提策略能提高1%~22%的I/O性能读写速度三校人员提出的问题,此处是否应该为“读写速度”?若是的话,也请补充英文译文。回复:中文可以写成“读写速度”意思和I/O性能是相同的。和9%~15%的IOPS此处是否应该为“访问请求处理速度”?IOPS不是I/O性能的一个指标吗?这两个指标这样书写准确吗?请明确。回复:IOPS是每秒处理的访问请求数量。一般都用英文简写的。,验证了CNVMS策略能有效提高NVM存储系统的I/O性能和访问请求处理速度。
关键词:NVM;存储系统;I/O系统软件栈
中图分类号: TP316.4
文献标志码:A
Abstract: I/O system software stack is an important factor that affects the efficiency of NVM (Non-Volatile Memory) storage system. For NVM storage systems with unbalanced read/write speeds and limited writing lifetimes, new synchronous and asynchronous converged access management strategy was designed. While an asynchronous write cache was implemented by DRAM for the write access to large data, synchronous management strategy was still used for the read access and the write access to small data. Addressing large time overhead of address translation for NVM storage systems by conflict among cores in a computer with multi-core processor, a new address translation cache was designed for multi-core processor to reduce time overhead of address translation. Finally, a prototype of Concurrent NVM Storage system (CNVMS) was implemented, and the universal testing tools were used to test performance of random reads writes, sequential reads writes, mixed reads/writes and with actual application workload. The experimental results show that the proposed strategy increases I/O performanceread and write speed by 1%-22% and IOPS (Input/Output operations Per Second) by 9%-15% compared with PMBD (Persistent Memory Block Driver根據文献23,PMBD中的Driver,是否应该为Device?请明确), which verifies that CNVMS strategy can provide higher I/O performance and better access request processing speed.
Key words: Non-Volatile Memory (NVM); storage system; I/O system software stack
0 引言
计算机系统中各部件的发展很不均衡,传统存储部件的读写速度远低于计算部件的处理能力,这导致了严重的存储墙问题[1]。由于存在机械部件,传统的磁盘很难有效提高读写速度。基于Flash的SSD(Solid State Drives)具有较高的I/O性能,但存在写寿命短和仅支持以块为单位的读写操作等问题。当前出现了一系列NVM(Non-Volatile Memory)存储器件,如PCM(Phase Change Memory)[2]、STT-RAM(Shared Transistor Technology Random Access Memory)[3]和FeRAM(Ferroelectric RAM)[4]等,具有支持以字节为单位的读写、较长的写寿命、低功耗和接近DRAM(Dynamic Random Access Memory)的读写速度等优势,成为解决存储墙问题的重要手段。虽然有部分NVM存储器件还存在写寿命不够高的问题,但随着技术的发展,NVM存储设备和所构建的存储系统已成为当前研究和开发的热点。
NVM存储系统具有较高的读写性能,这使得现有面向低速外存设备设计的I/O系统软件栈成为影响存储系统性能的重要因素,相关研究表明在用于NVM存储系统时I/O系统软件的开销占总开销的94%以上,因此减少I/O系统软件栈的时间开销是提高NVM存储系统性能的重要手段。当前已有一些新型的NVM文件系统,相比传统文件系统,能适应NVM存储系统的特性,有效地提高访问NVM存储系统的效率,但NVM存储系统内部的管理机制则没有太多的改变,仍然使用传统存储设备或基于Flash的SSD的管理方式,而这成为了影响NVM存储系统性能的重要因素。
由于NVM存储器件自身的特性限制,NVM存储系统不仅在读写性能存在很大区别,而且也存在写寿命较短的问题;但现有的存储系统访问请求管理策略仅仅使用单一的同步或异步策略管理所有访问请求,不能区分访问请求的不同类型以适应NVM存储系统的特性。由于NVM存储系统具有接近于DRAM的读写速度,使得NVM存储系统中逻辑和物理地址之间的转换也成为影响I/O性能的重要因素;在多核处理器环境中,虽然私有映射能降低减少不同计算核心访问NVM存储系统空间时的冲突,但也使得多个计算核心之间无法共享地址转换信息,从而影响了地址转换的效率,因此如何针对NVM存储系统的特性,研究具有高并发特性的新型访问机制是提高NVM存储系统性能需要解决的重要问题。
本文首先给出当前相关的研究,接着给出支持高并发访问NVM存储系统的结构,再设计同异步融合的访问请求管理策略和面向多核处理器的地址转换缓存策略,并在开源的NVM存储系统基础上实现原型系统,使用通用测试工具进行测试与对比分析。本文的主要贡献如下:
1)根据读写访问请求的不同特性,融合同步和异步访问请求管理策略,利用NVM存储系统中DRAM构建的缓存减少较大数据量写请求的响应时间;同时仍然使用同步策略完成读和少量数据写请求操作,在简化缓存管理和同时也避免冗余写操作对读和少量数据写请求性能的影响。
2)在多核处理器使用私有映射的基础上,构建了多个计算核心共享的地址转换缓存,实现了不同计算核心之间地址转换缓存项的共享,降低了不同计算核心进行逻辑地址和物理地址转换时冲突的几率,减少了地址转换的时间开销,提高了NVM存储系统的I/O性能。
3)实现了支持高并发访问NVM存储系统(Concurrent NVM Storage system, CNVMS)的原型,使用通用测试工具进行了随机读写、顺序读写、混合读写和实际应用负载的测试,验证了CNVMS相比现有NVM存储系统具有更高的I/O性能和IOPS(Input/Output operations Per Second)。
1 相关研究工作
当前为了提高NVM存储系统的性能和并发性,研究者主要针对NVM存储系统的特性,从如何优化I/O系统软件栈和优化基于写保护的地址转换策略展开研究。
优化I/O系统软件栈方面:文献[5]在访问PCM存储设备时,使用轮询方式的效率优于中断方式,同时存储软件栈中使用同步I/O机制的效率高于异步I/O机制。与传统的异步I/O相比,同步I/O可以减少I/O请求所需的CPU时钟周期,这种减少主要来自缩短的内核路径和中断处理的去除。异步I/O在处理具有较大传输大小数据量的I/O请求或处理导致较长等待时间的硬件延迟时会更好;而同步I/O适合较小传输大小数据量这两处的“大小”,是否应该改为“数据量”更为恰当些?请明确的I/O请求;同时针对高速的NVM存储设备,当存在大规模数据读写以及一定的硬件延迟时,异步I/O访问依然是高效的。文献[6]针对PCM读性能高的特性,对PCIe口的NVM存储设备,采用轮询的方法,消除PCI Express的封包和上下文切換,提高读性能。文献[7]设计了新型文件系统PMFS(Persistent Memory File System),使用存储级NVM作内存,直接通过load/store访问NVM,简化I/O系统软件栈,绕过页缓存,从而避免了双倍拷贝开销。研究者Ou等[8]设计了针对NVM主存的写缓存机制以及DRAM中索引与缓存行中位图相结合的读一致性机制,并构建了缓存贡献模型挑选NVM主存的写操作,实现了面向NVM主存的文件系统HINFS(High-Performance Non-Volatile File System请补充HINFS的英文全称)。Lu等[9]针对非易失内存设计了模糊持久性的事务机制,这模糊了易失持久性的边界来减少事务支撑的开销,并在多种负载的测试下提升了56.3%到143.7%的性能,而事务的开销主要包括日志的执行和易失检查点的批量持久化。文献[10]中针对PCM设计了基于页的高效管理方式,适应上层应用的访问方式,首先使用双向链表管理PCM中的页,再使用DRAM构建了PCM页的缓存并设计了基于进入时间的淘汰算法,最后综合页迁移和交换信息优化了PCM中页的分配。文献[11]修改了虚拟文件系统,并设计了非阻塞的写机制,消除了填充页缓存造成的阻塞,能快速释放写请求。Benchmark的测试结果显示吞吐量相比磁盘平均提高了7倍,相比SSD平均提高了4.2倍。文献[12-13]利用基于硬件的文件系统访问控制,分离元数据和数据的访问路径,使用用户空间与存储设备之间的直接I/O,避免修改元数据,减少了文件系统访问控制、数据访问等操作中存储软件栈的开销。文献[14]中针对SSD设计了Slacker,使用松耦合重排机制调整SSD内部的子访问请求,对写密集、读密集和读写均衡的应用分别能缩短12%、6.5%和8.5%的响应时间。文献[15-16]中针对SCM提出了一个灵活的文件接口Aerie,以运行时库的形式将SCM暴露给用户程序,使得在读写文件时无需与内核交互;并实现了一个POSIX(Portable Operating System Interface of UNIX)标准的文件系统PXFS(ProXy File System),获得了优于Ramdisk上的Ext4和接近于Ramfs的性能;还实现了一个用于存储key-value的文件系统FlatFS,相比现有的内核文件系统Ramfs和Ramdisk的上Ext4能提高20%~109%的性能。文献[10]中针对PCM设计了基于页的高效管理方式,适应上层应用的访问方式,首先使用双向链表管理PCM中的页,再使用DRAM构建了PCM页的缓存并设计了基于进入时间的淘汰算法,最后综合页迁移和交换信息优化了PCM中页的分配。文献[17]使用较小容量的DRAM和PCM混合构建内存系统,利用DRAM缓存PCM的部分数据,提高了混合内存系统读写速度,减少了PCM的写次数。
优化基于写保护的地址转换策略方面:NVM存储设备可以使用与DRAM相同的方式接入计算机,并作为存储器提供给操作系统,现有针对DRAM的基于页表保护机制无法解决内核代码野指针等给NVM存储系统中数据造成永久损坏的问题,同时在多核处理器中不同计算核心之间在地址转换时存在大量冲突严重影响了I/O性能。NOVA(Non-Volatile Memory Accelerated)[18]和PMFS[7]选择在挂载期间将整个NVM映射为只读状态。通过禁用处理器的写保护控制(CR0.WP)来打开一个写入窗口(NVM代码段)[19]。当CR0.WP清除时,在0其上这个表述对吗?是数字0吗?请明确运行的内核软件可以写入内核地址空间中标记为只读的页面。NVM写入完成后,系统会复位CR0.WP并关闭写入窗口。CR0.WP不会跨中断保存,所以本地中断会被写入窗口中并被禁用。文献[20]中提出了面向NVM的事务接口NVTM(Non-Volatile Transaction MemoriesNVTM的英文全称是“non-volatile memories”吗?请明确),将非易失存储器直接映射到应用程序的地址空间,允许易失和非易失数据结构在程序中的无缝交互,从而在读写操作中避免操作系统的介入,提高了数据访问性能。文献[21]在虚拟内存空间设计了新型文件系统SCMFS(Storage Class Memory File System),使用MMU(Memory Management Unit)和TLB(Translation Lookaside Buffer)实现虚拟地址和物理地址的转换,简化了文件操作,减少了CPU开销。HSCC(Hardware/Software Cooperative Caching请补充HSCC的英文全称)[22]通过软硬件协同管理的DRAM/NVM层次化异构内存系统;通过Utility-based数据缓存机制仅缓存NVM热页缓存,提高了DRAM利用率;同时在页表和TLB中建立虚拟页到DRAM缓存页的映射,并与Utility-based数据缓存机制一起在软件层次实现,降低了系统的硬件复杂度和存储开销。PMBD(Persistent Memory Block Driver)[23]将NVM映射到内核虚拟地址空间,不同计算核心在访问时使用对应的私有映射,减少了TLB刷新和页表项修改,避免了大容量NVM存储设备对应的大页表所消耗的大量存储器空间和管理时间开销。
综上所述,目前在针对NVM构建存储系统方面,主要考虑的是如何减少I/O系统软件栈的时间开销,发挥NVM设备高速读写特性,因此针对NVM设备的特性,有效地混合异步和同步I/O是提高NVM存储系统I/O性能的有效途径;同时多核环境中,内核的私有映射可以确保NVM中数据免受意外的永久性破坏,但NVM存储系统容量较大时,TLB的命中率会受到较大影响,所以如何在确保解决多处理器映射冲突的情况下提高映射效率、降低软件开销值得本文作进一步的研究。
2 支持高并发访问NVM存储系统的结构
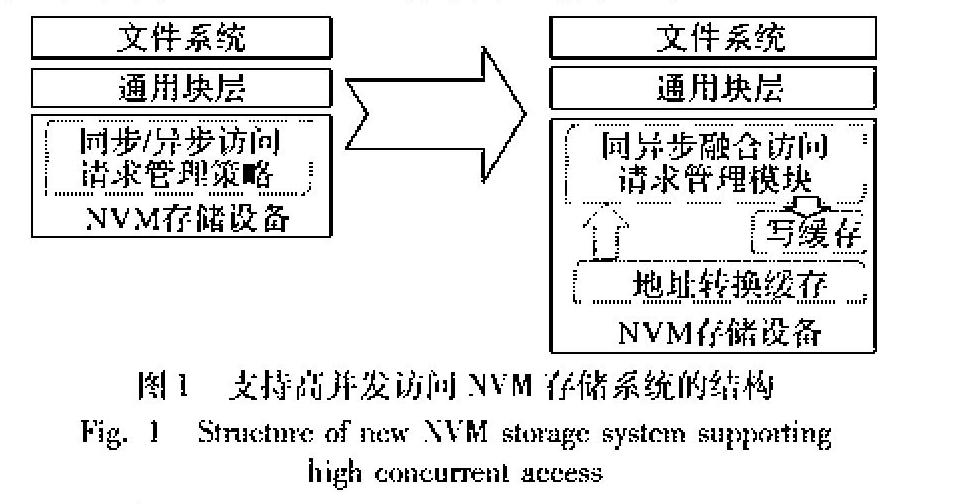
NVM存储器件的读性能接近DRAM,但其写速度与DRAM相比还有数量级的差距;同时另外NVM存储器件还存在写寿命的问题,因此当前的NVM存储系统中仍然包含一定容量的DRAM,但现有的存储系统使用单一的同步或异步策略管理所有访问请求,难以适应NVM存储系统中读写性能差异和写寿命的限制;同时NVM存储系统的高I/O性能,使得处理器在访问NVM存储系统时完成逻辑和物理地址转换的时间开销也成为影响I/O性能的重要因素,特别是在多核处理器环境中,在使用冲突较少的私有映射时多个计算核心之间无法共享地址转换信息,影响了地址转换的效率,因此本文设计支持高并发访问的NVM存储系统,其结构如图1所示。
支持高并发的NVM存储系统中,主要包含同异步融合访问请求管理模块、写缓存和地址转换缓存。其中:同异步融合访问请求管理模块主要负责管理访问NVM存储系统的读写操作,根据NVM存储系统的特性和访问请求的特点,提高访问NVM存储系统的I/O性能,减少访问请求的响应时间;写缓存用于保存部分写操作需要写入NVM存储系统的数据;地址转换缓存保存部分NVM存储系统中逻辑地址和物理地址的转换表,用于在多核环境中提高查找NVM存储系统物理地址的速度。
3 同异步融合的访问请求管理策略
由于NVM存储器件的特性,使得NVM存储系统的读写性能存在很大差异,这给如何管理NVM存储系统中的访问请求带来了很大困难。本文设计了同异步融合的访问请求管理策略。
首先使用DRAM构建写数据缓冲区、并用WBuffer表示,定义α表示判断写访问请求的阈值,其处理访问请求主要步骤的伪代码如下。
此外使用LRU(Least Recently Used)策略管理写数据缓冲区,并使用一个独立的线程定期将WBuffer中的数据写入到NVM存储系统中。
由此将NVM存储系统的读写请求进行了分离,使用同步机制完成读操作,能利用NVM存储系统读速度接近DRAM的特性。同样使用同步机制完成少量数据的写请求,避免使用写缓存存在的两次写操作;对数据量较大的写请求,则运用异步机制,使用DRAM构建写数据缓存,利用相比NVM存储器件写速度更高的DRAM快速完成数据写操作,从而提高NVM存储系统的写性能;同时使用异步写机制还能增强NVM存储系统处理写操作的并行性,提高写操作的吞吐率。
4 面向多核处理器的地址转换缓存策略
处理器在访问NVM存储系统时,需要进行NVM存储空间逻辑地址和物理地址的转换。由于NVM存储系统的读写速度已经接近于DRAM,使得NVM存储系统中地址转换所需时间开销对其I/O性能的影响很大,特别是在使用多核处理器时,为了保证NVM存儲系统上数据的一致性,多个计算核心在访问NVM存储系统时需要进行加锁,这严重影响了NVM存储系统的I/O性能。NVM存储系统空间私有映射为每个计算核心建立一个独立的地址映射表,能降低不同计算核心访问NVM存储系统空间时的冲突,是当前提高NVM存储系统地址转换效率的有效方式,但会造成NVM存储系统所对应逻辑地址空间的急剧膨胀,也使得多个计算核心之间无法共享地址转换信息,从而影响了地址转换的效率。
使用私有映射时,多核处理器中不同核心所对应NVM存储系统的逻辑地址各不相同,但其与NVM存储系统空间大小存在关联;NVM存储系统中同一物理地址所对应不同计算核心的逻辑地址之间互相可转换,这为共享NVM存储系统中地址转换信息提供了可能。本文设计面向多核处理器的地址转换缓存策略,利用NVM存储系统的逻辑与物理地址转换信息可共享特性,构建面向多核处理器的可共享地址转换缓存。使用Nsize表示NVM存储系统的存储空间大小,Lbegin表示某个计算核心逻辑地址空间的起始地址,Laddress表示NVM存储系统内部的逻辑地址,Paddress表示NVM存储系统中内部的物理地址,Lid表示多核处理器中某个计算核心的标识,Tcache表示面向多核处理器的地址转换缓存。
面向多核处理器的地址转换缓存使用键值对形式保存Laddress和Paddress之间的对应,并使用LRU策略进行管理。在将地址转换信息调入Tcache前,使用式(1)计算其逻辑地址logical_address所对应的Laddress:
使用面向多核处理器地址转换缓存策略后,处理器访问NVM存储系统时地址转换的主要过程如下所示。
使用面向多核处理器地址转换缓存策略,能避免在进行私有映射后,多核处理器中不同计算核心之间无法共享NVM存储系统逻辑地址的问题,通过共享逻辑地址和物理地址之间的转换信息,实现多个计算核心之间在获得物理地址信息时的共享:一方面避免每个计算核心均需处理物理地址相同的地址转换;另一方面通过可共享的面向多核处理器地址转换缓存进一步减少了访问NVM存储系统时多个计算核心之间的冲突,从而能有效提高NVM存储系统处理访问请求的并行性,提高I/O性能,缩短响应访问请求的时间。相比TLB,本文所设计的面向多核处理器地址转换缓存中地址转换缓存键值对能被不同的计算核心所共享,在通过不同计算核心的简单计算即可获得对应的逻辑地址,从而避免TLB中多个计算核心无法共享缓存项的问题。
5 原型系统的实现
本文在64位的Linux平台上构建支持高并发访问NVM存储系统的原型,实现同异步融合访问请求管理策略和面向多核处理器地址转换缓存策略,并使用存储系统通用测试工具Fio和能模拟应用访问特性的Filebench进行测试,并与现有NVM存储系统进行比较。
当前没有商用的NVM存储设备,在文献[21]所实现的虚拟NVM存储设备PMBD基础上实现CNVMS的原型。其中的PMBD采用缺省配置,并关闭DRAM上的数据缓存,同时设置cache为write through模式,并在每次写操作后插入一个写屏障指令,保证NVM存储系统中数据的强一致性,同时额外增加85ns的读延迟和500ns的写延迟模拟NVM的读写性能;使用多核处理器中每个计算核心私有映射的方式实现PMBD中逻辑地址与物理地址的映射,并在读写PMBD时采用使用逻辑块号直接读写裸设备的方式缩短I/O系统软件栈。此外修改Linux内核,在内核地址尾部预留20GB的内核空间并挂载PMBD来模拟NVM存储设备。
在此基础上,修改PBMD的源代码,增加同异步融合访问请求管理模块、写缓存和地址转换缓存构建CNVMS,设置α的值为4KB,实现访问NVM存储系统读写访问请求的分类管理,利用写缓存缩短较大写操作的完成时间开销,利用地址转换缓存进一步压缩I/O系统软件栈的时间开销,从而提高CNMVS的I/O性能和处理访问请求的效率。
6 测试与分析
使用1台服务器构建了CNVMS的测试环境,其配置为: CPU为Four Intel Xeon E7-4830V2 2.2GHz,Memory为256GB,Disk为600GB SAS Disk+120GB SAS SSD,OS为Red Hat Enterprise 6.5。首先使用文件系统性能的通用测试工具Fio进行测试,再使用能模拟不同应用访问特性的通用测试工具Filebench进行测试,并将CNVMS的读写速度和IOPS与PMBD进行比较。
6.1 顺序读写时的测试与分析
将Fio设置为直接覆盖式读写方式,设置线程数为8,访问块大小为4KB,使用同步(sync)和异步(libaio)两种引擎,异步读写时I/O队列深度分别设置为1和32,读写文件数分别为5000、10000、20000和30000,读写文件的大小分别为1KB、4KB和256KB。
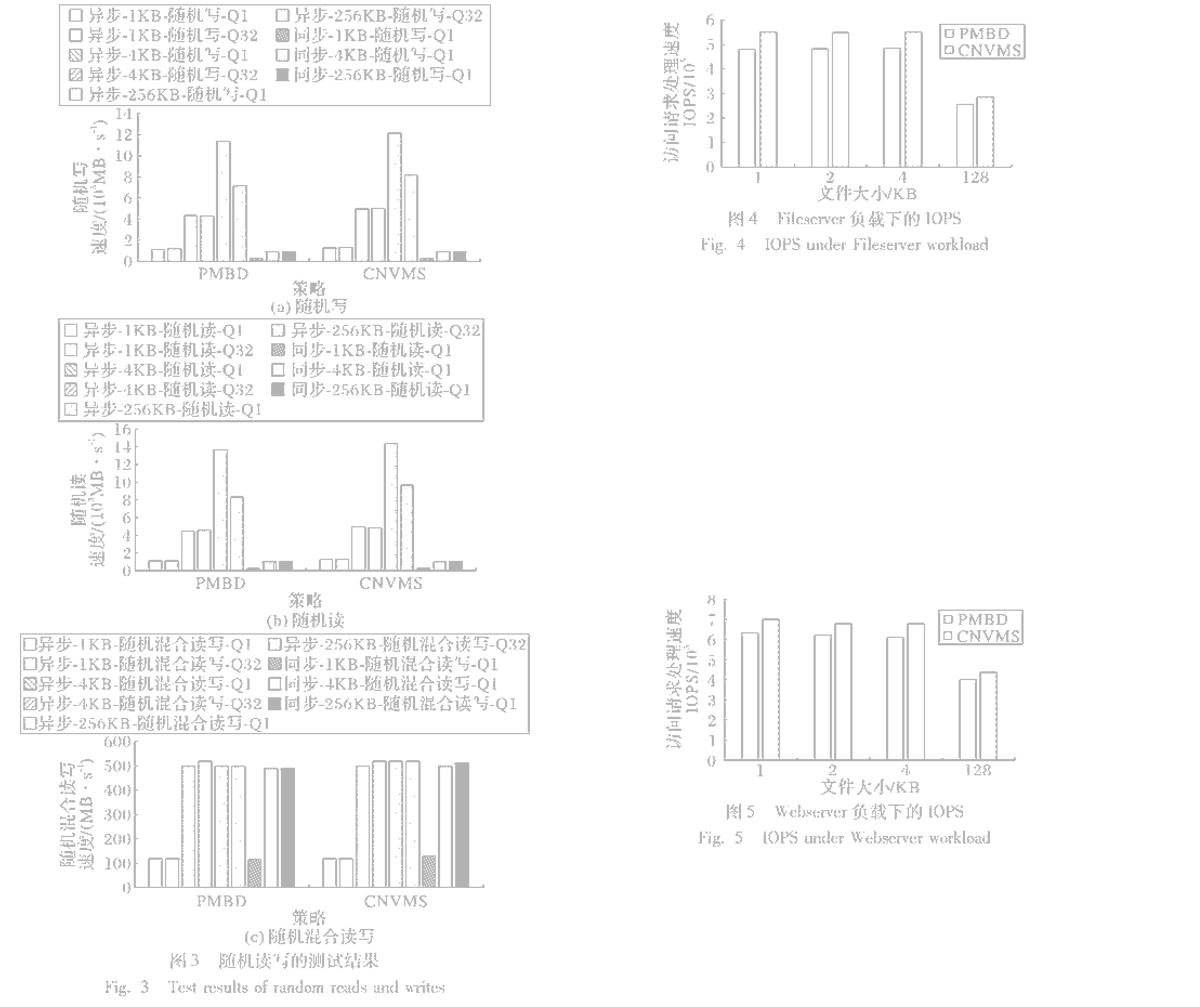
首先测试顺序写时的I/O性能,测试结果如图2(a)所示。从中可以发现,CNVMS的顺序写速度始终高于相同情况下的PMBD。在同步顺序写时,CNVMS相比PMBD能提高2%左右的I/O性能;在异步顺序写时,CNVMS能提高11%~22%的写性能。相比同步顺序写,异步顺序写能更好地发挥CNVMS的性能,这是因为同步写时PMBD本身的I/O性能就较低,同步机制制约了CNVMS的完成写操作的效率,影响了写缓存作用的发挥,同时多个计算核心转换地址时的冲突也很少。在异步模式下,顺序写4KB文件、I/O队列深度为32时,CNVMS相比PMBD所提高的写性能最高,达到了22%,这表明CNVMS相比PMBD能提高完成大量并发顺序写的速度,但相比I/O队列深度为1时,CNVMS和PMBD在I/O队列深度为32时的顺序写性能始终较低,这说明在处理顺序写任务时现有NVM存储系统中并发性还有待提高。
使用相同的配置,测试PMBD和CNVMS的顺序读速度,结果如图32(b)所示。从中可以发现,与顺序写的测试结果类似,CNVMS相比PMBD始终具有更高的顺序读速度。同步顺序读的速度,CNVMS相比PMBD能提高2%~7%;异步顺序读的速度,CNVMS能提高10%~17%。這表明CNVMS相比PMBD具有顺序读性能的优势。
使用相同的配置,测试PMBD和CNVMS的顺序混合读写速度,读写混合比例是各50%,结果如图42(c)所示。从中可以发现,其结果基本与顺序写或读类似,但在使用异步模式时CNMVS相比PMBD所提高的I/O性能比例有所下降;而在使用同步模式时CNMVS相比PMBD所提高的I/O性能比例则有所提高。
6.2 隨机读写时的测试与分析
采用与6.1节中相同的配置,测试PMBD和CNVMS随机写性能,结果如图53(a)所示。从中可以发现,CNVMS相比PMBD能有效地提高随机写性能。在使用异步随机写模式时,CNVMS相比PMBD提高了6%~17%;使用同步随机写模式时,CNVMS相比PMBD提高了1%~4%。相比顺序写性能的提高比例,随机写性能的提高略低,这与一般采用缓存机制所取得的效果一致。
采用相同的配置,测试PMBD和CNVMS随机读性能,结果如图63(b)所示。从中可以发现,CNVMS相比PMBD能有效地提高随机读性能。在使用异步随机读模式时,CNVMS相比PMBD提高了5%~16%;使用同步随机读模式时,CNVMS相比PMBD提高了1%~18%。同样相比顺序读性能的提高比例,随机读性能的提高略低。
使用相同的配置,测试PMBD和CNVMS的随机混合读写速度,读写混合比例各50%,结果如图73(c)所示。从中可以发现,其结果基本与随机写或读类似,但在使用异步模式时CNMVS相比PMBD所提高的I/O性能比例有所下降;在使用同步模式时CNMVS相比PMBD所提高的I/O性能比例则有所提高,这也与顺序混合读写模式时的测试结果趋势类似。
6.3 使用应用负载时的测试与分析
应用Filebench来模拟应用对NVM存储系统的访问。首先使用Fileserver负载,模拟文件服务器中文件的共享、读写操作等情况,设置读写文件数为50000,目录宽度为20,读写的线程数为50;同时为了更好地进行比较与分析,将文件的大小分别设置为1KB、2KB、4KB和128KB,所有测试结果均是测试三次的平均值而得,降低测试过程中可能存在的误差,测试结果如图84所示。从中可以发现,CNVMS的IOPS始终高于PMBD,提高了13%~15%,这是由于Fileserver负载中包含了较多的写操作,从而使得CNVMS能较好地发挥写缓存和地址转换缓存的作用,有效提高处理访问请求的速度。
再使用Filebench中的Webserver负载,用户访问Web服务器的情况;设置读写文件数为50000,目录宽度为20,读写的线程数为100;同时为了更好地进行比较与分析,将文件的大小分别设置为1KB、2KB、4KB和128KB,所有测试结果均是测试三次的平均值而得,降低测试过程中可能存在的误差,测试结果如图95所示。从中可以发现,CNVMS相比PMBD同样具有IOPS较高的优势,能提高9%~11%的IOPS,这表明CNVMS能利用写缓存和地址转换缓存有效提高存储系统处理访问请求的速度,但相比Fileserver负载所提高IOPS的比例有所下降,这是由于Webserver负载主要模拟的Web文件的读操作,写操作的比例较少,降低了CNVMS中写缓存的作用。
7 结语
NVM存储系统具有较高的读写性能,这使得现有面向低速外存设备设计的I/O系统软件栈成为影响存储系统的重要瓶颈。针对NVM存储系统存在的读写速度不均衡、写寿命受限等问题,本文设计了同异步融合的访问请求管理策略,在不影响读和少量写请求性能的同时,使用DRAM构建写缓存提高数据量较大写请求的执行速度;设计了面向多核处理器地址转换缓存策略,减少多核处理器环境下不同计算核心访问NVM存储系统时地址转换的时间开销,提高NVM存储系统的I/O性能。最后实现了支持高并发访问NVM存储系统(CNVMS)的原型,使用Fio和Filebench进行了随机读写、顺序读写、混合读写和实际应用负载的测试,相比PMBD能提高1%~22%的I/O性能和9%~15%的IOPS,验证了算法的有效性。
当前在管理写缓存和地址转换缓存时,还是使用通用的LRU算法,下一步拟根据NVM存储系统的特性,优化写缓存和地址转换缓存的管理算法。
参考文献 (References)
[1] 陈祥,肖侬,刘芳.新型非易失存储I/O栈综述[J].计算机研究与发展,2014,51(S1):18-24.(CHEN X, XIAO N, LIU F. Survey on I/O stack for new non-volatile memory [J]. Journal of Computer Research and Development, 2014,51(S1):18-24.)
CARVALHO C. The gap between processor and memory speeds[C]// Proceedings of the 2002 IEEE International Conference on Control and Automation. Piscataway, NJ: IEEE, 2002: 51-58.
[2] Micron. Mobile LPDDR2-PCM. [EB/OL]. [2018-01-08]. http://www.micron.com/products/multichip-packages/pcm-based-mcp.
[3] CAULFIELD A M, COBURN J, MOLLOV T, et al. Understanding the impact of emerging non-volatile memories on high-performance, IO-intensive computing[C]// SC10: Proceedings of the 2010 ACM/IEEE High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2010: 1-11.
[4] JO S H, KUMAR T, NARAYANAN S, et al. 3D-stackable crossbar resistive memory based on Field Assisted Superlinear Threshold (FAST) selector[C]// Proceedings of the 2014 International Electron Devices Meeting. Piscataway, NJ: IEEE, 2014:6.7.1-6.7.4.
[5] YANG J, MINTURN D B, HADY F. When poll is better than interrupt[C]// Proceedings of the 2010 USENIX Conference on File and Storage Technologies. Berkeley: USENIX Association, 2012:3-3.
[6] DEJAN V, WANG Q B, CYRIL G, et al. DC express: shortest latency protocol for reading phase change memory over PCI express[C]// Proceedings of the 2014 USENIX Conference on File and Storage Technologies. Berkeley: USENIX Association, 2014: 17-20.
[7] DULLOOR S R, KUMAR S, KESHAVAMURTHY A, et al. System software for persistent memory[C]// EuroSys 2015: Proceedings of the 10th European Conference on Computer Systems. New York: ACM, 2014: Article No. 15.
[8] OU J X, SHU J W, LU Y Y. A high performance file system for non-volatile main memory[C]// EuroSys 2016: Proceedings of the 11th European Conference on Computer Systems. New York: ACM, 2016: 18-21.
[9] LU Y Y, SHU J W, SUN L. Blurred persistence in transactional persistent memory[C]// Proceedings of the 2015 Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2015: 1-13.
[10] JIN P Q, WU Z L, WANG X L, et al. A page-based storage framework for phase change memory[C]// Proceedings of the 2017 International Conference on Massive Storage Systems and Technology. Piscataway, NJ: IEEE, 2017: 152-164.
[11] CAMPELLO D, LOPEZ H, USECHE L, et al. Non-blocking writes to files[C]// Proceedings of the 2015 USENIX Conference on File and Storage Technologies. Berkeley: USENIX Association, 2015: 151-165.
[12] CAULFIELD A, MOLLOV T, EISNER L, et al. Providing safe, user space access to fast, solid state disks[J]. ACM SIGARCH Computer Architecture News, 2012, 40(1): 387-400.
[13] EISNER L A, MOLLOV T, SWANSON S J. Quill: exploiting fast non-volatile memory by transparently bypassing the file system: #CS2013-0991 [R]. San Diego: University of California, 2013: 127-134.
[14] NIMA E, MOHAMMAD A, ANAND S, et al. Exploiting intra-request slack to improve SSD performance[C]// Proceedings of the 2017 International Conference on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2017: 375-388.
[15] HARIS V, SANKARALINGAM P, SANKETH N, et al. Storage-class memory needs flexible interfaces[C]// Proceedings of the 4th Asia-Pacific Workshop on Systems. New York: ACM, 2013: Article No. 11.
[16] HARIS V, SANKETH N, SANKARLINGAM P, et al. Aerie: flexible file-system interfaces to storage-class memory[C]// Proceedings of the 2014 European Conference on Computer Systems. New York: ACM, 2014: Article No. 14.
[17] QURESHI M K, SRINIVASAN V, RIVERS J A. Scalable high performance main memory system using phase-change memory technology[J]. ACM SIGARCH Computer Architecture News, 2009, 37(3): 24-33.
[18] XU J, SWANSON S. NOVA: a log-structured file system for hybrid volatile/non-volatile main memories[C]// Proceedings of the 2016 USENIX Conference on File and Storage Technologies. Berkeley: USENIX Association, 2016: 22-25.
[19] Intel. Intel 64 and IA-32 architectures software developers manual [EB/OL]. [2018-01-11]. https://software.intel.com/en-us/articles/intel-sdm.
[20] COBURN J, CAULFIELD A, GRUPP L, et al. NVTM: a transactional interface for next-generation non-volatile memories[R]. San Diego: University of California, 2009.
[21] WU X, REDDY A L N. SCMFS: a file system for storage class memory[C]// Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2011: 12-18.
[22] LIU H, CHEN Y, LIAO X, et al. Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures[C]// Proceedings of the 2017 International Conference on High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2017: Article No. 26.
[23] CHEN F, MESNIER M P, HAHN S. A protected block device for persistent memory[C]// Proceedings of the 2014 Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2014: 1-12.
猜你喜欢
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
现代电子技术(2017年23期)2017-12-20
现代情报(2017年2期)2017-02-27
电脑知识与技术(2016年25期)2016-11-16
