
基于轨迹时空词向量的用户年龄特征识别
2019-08-05 02:28张威强张朋柱
中文信息学报 2019年7期
吴 浩,张威强,张朋柱
(上海交通大学 安泰经济与管理学院,上海 200030)
0 引言
长期以来,用户特征的识别作为一个重要的研究领域,在语言学、心理学和社会学中得到了广泛研究。在移动互联网兴起之前,许多不同的研究都从众多的领域中搜集数据。比如从互联网浏览行为、网页文本、移动网络通信记录(电话和短信)以及心理学问卷测试中来预测各种各样的用户特征。例如,性别、年龄、收入和个性等。然而,作为能够反映用户行为重要数据之一的轨迹数据,在过去的许多用户特征推断的研究中分析较少。
近年来,随着智能手机、移动互联网和全球卫星导航系统(global navigation satellite system, GNSS)的普及,基于位置的服务(location based service, LBS)得到了极大发展。通过移动通讯网络获得用户的位置信息变得更加便捷,一段连续时间内,用户位置信息可以形成该用户在该段时间的轨迹数据。这些轨迹数据代表着用户某种活动的发生,周期性的活动反映了用户的生活习惯和行为模式,体现了用户的年龄、职业等特征。因此,轨迹分析是识别用户年龄特征的有效途径。现有对轨迹数据的研究仍存在以下不足。
(1) 对轨迹点的有效清洗不足。通过基站收集用户历史轨迹数据时,可能会存在一些错误。产生的原因有多种: 网络信号不稳定、硬件故障等。因此,在分析轨迹数据之前,必须先剪枝过滤这些明显错误的点。
(2) 对轨迹空间语义的考虑不足。不同的用户虽经过的具体地理位置(如经纬度)不同,但若这些地理位置具有相同的语义,则他们的轨迹在语义方面存在相似性(如1号小学与2号小学,虽所在经纬度不同,但功能语义均为小学)。因此,这些用户之间可能存在着身份特征或行为习惯的相似性。
(3) 对轨迹时间语义的考虑不足。即使是同一区域,不同对象在不同时间的访问,该位置的功语义可能不同。如在早上6:00~10:00出现在中餐馆的用户可能是服务人员,而中午11:00~13:00出现在中餐馆附近的用户可能是来就餐的周边上班族等。现有部分研究通过提取轨迹点周边一定范围内的兴趣点(point of interest,POI),直接采用TF-IDF提取该轨迹点的语义,没有对不同时间不同用户的轨迹语义加以区分。
针对上述问题,本文将从以下几个方面展开研究。
(1) 提出“速度—时空—角度”的轨迹剪枝方法(velocity-space-time-angle pruning, VSTA Pruning),从轨迹的速度、距离、运动与停留的时间、运动方向及其变化等方面,对原始轨迹数据进行有效剪枝和清洗,过滤存在明显错误的轨迹点。
(2) 提出带有时间标签的TF-IDF改进算法(term frequency-inverse document frequency with time label, TFT-IDFT),利用轨迹点周边的POI信息对不同用户不同时间不同轨迹点的时空语义进行了分析。该方法在考虑轨迹点的空间语义的同时,也将轨迹的时间语义纳入考虑。其中,空间语义是指轨迹点的区域功能类型(如学校、公司等),时间语义是指不同用户经过某类型区域的时间,以及其对用户身份特征和行为习惯识别的影响。
(3) 通过将轨迹点的时空语义提取为一个个特征单词,利用Word2vec方法进行多组特征训练,获得每个单词的向量表达,以及轨迹点语义的相关性。在此基础上分析每个用户的轨迹规律,识别用户特征。
1 相关文献
1.1 用户特征识别
早期的用户特征识别主要通过用户的通话数据和文本数据分析用户的行为模式,从而判别用户的年龄、性别等特征。Eckert[1]等认为性别应被视为语言变异和标准及非标准形式使用的重要原因。因此,可以将语言作为判别性别的重要特征; Koppel[2]根据文本内容自动分类推断作者的性别特征。
随着互联网的兴起,基于用户上网行为及其浏览内容推断用户特征的研究开始逐渐增多。Hu[3]等利用贝叶斯理论对用户浏览的历史记录进行分析,较准确地预测了用户的年龄和性别;还有基于搜索习惯来挖掘用户特征的工作也取得不错的效果,如Lorigo[4]等和Bi[5]等的研究。王晶晶[6]等还通过微博用户名和微博文本构建基于贝叶斯融合的分类器,采用这两种文本信息同时对用户性别进行判别。
随着移动通讯对人们日常生活的逐步渗透,研究开始关注移动通讯带来的信息在推断用户特征中的应用。Ying[7]等通过用户移动手机端获取了用户每天的移动距离、app使用情况、通话短信以及无线和蓝牙使用情况的特征,应用多层次分类模型对用户的年龄、工作、婚姻状况和家庭人数等人口特征进行了分析;Sanja[8]等提取多维度的移动手机数据,主要包括应用使用情况、通话情况、联络人情况以及移动距离,测量了不同用户之间的相似度,并在此基础上对用户的人口特征建立了分类模型。还有研究主要基于移动设备带来的基于位置服务(LBS)的信息来分析用户的人口特征,Riederer[9]通过用户在不同位置的签到足迹,不仅使用了移动距离等研究广泛使用的特征,还使用了不同签到位置的地址特征来识别用户的人口特征。
但这些研究并没有充分利用用户在不同时间不同位置的信息所反映的活动规律和生活习惯,在这方面,李敏[10]等通过分析时空数据,认为用户签到的时间和地点存在一定的规律性;陈元娟等[11]也基于用户移动的时间顺序和位置顺序,向量化用户本身特征,从而学习不同用户之间的社交联系。李源昊[12]等基于移动社会网络的理论,利用位置网络拓扑结构和用户通话交互情况,建立了基于关系马尔科夫网络的用户特征识别模型。Jing[13]等通过建立用户在不同时间访问不同地质特征的词向量,探索用户之间的相似性,判别城市的功能区,并预测相邻地区之间的犯罪率。但这些研究主要是基于用户在一些特定网站的签到信息来定位用户位置,数据本身存在一定的偏差,也没有在分析中同时考虑位置信息和语义信息。此外,在用户时间、位置和活动等的关联方面也分析不足,未能用这些信息来反映用户本身的特征。
1.2 轨迹数据挖掘
目前对轨迹数据的挖掘主要分为基于地理信息和语义信息两类。前者基于诸如经纬度等地理位置信息,认为频繁出现在相同或相邻地理位置的用户具有相似性。因此,Xue[14]等和Zheng[15]等通过挖掘用户频繁出现的位置经纬度来判断不同用户之间轨迹的相似性,进而实现对用户的分类。但该类方法具有一定的局限性,得到的同类用户基本在地理位置相近的范围内活动。而实际上即使两个用户的地理位置轨迹并不相似,但二者的轨迹具有相同或相似的功能语义(如学校),他们的活动轨迹也具有相似性。
近年来,出现了较多工作尝试挖掘轨迹数据中丰富的语义信息,即地理位置隐含功能特征的提取。Yuan[16]等先通过利用城市干道对地理位置进行划分,再基于用户轨迹和行为语义挖掘潜在地区的功能特征。但该方法对区域划分的要求较高,若直接按照高速公路进行划分,会产生功能区域较大的问题。Toole[17]从用户的手机使用行为出发,认为某一地点的语义特征和用户在此地点的行为有着密切关系,故而利用移动用户在该地的手机行为数据推断该地点的功能语义。邱运芬[18]等从轨迹的功能语义和访问的不确定性出发,从具体的地理位置坐标抽象出轨迹点语义,并计算访问不同轨迹点语义的概率,将其作为特征进行人群分类。
此外,基于神经网络的word2vec模型对发现单词序列的语义关系有效性也使该模型开始被应用到轨迹数据分析中。Al-Dohuki[19]等通过将轨迹数据转化为文档模型,利用文本搜索方法对出租车轨迹数据进行了挖掘和分析。Feng[20]等提出POI2vec模型,将每个POI映射为一个实数向量,POI之间的相似性则用向量余弦表示。与此类似,Liu[21]等使用Skip-gram模型,根据轨迹信息的上下文来分析用户潜在的兴趣点。Yu[22]等利用Word2vec模型计算交通工具轨迹的相似性,并对道路交通流量进行预测。
本文工作与上述研究有所不同: 本文从用户的原始轨迹出发。先从速度、距离、时间、运动方向及其变化等方面,对原始轨迹数据进行有效剪枝和清洗(VSTA Pruning)。再通过在传统TF-IDF算法中添加时间标签,利用带时间标签的TFT-IDFT方法提取轨迹点周边的POI语义。然后,在提取出的语义轨迹上利用word2vec方法建立与有效轨迹点一一对应的实数向量。最后,通过分类预测方法识别用户年龄段特征。具体分析流程如图1所示。

图1 分析流程图
2 研究方法
2.1 轨迹数据预处理
通过基站收集用户历史轨迹数据时可能会存在一些错误。产生原因有多种: 网络信号不稳定、硬件故障等。同时,轨迹数据中还可能包括用户在高速移动中采集到的数据。例如,某用户乘坐地铁等高速交通工具,这些高速移动的轨迹点在本研究中并无意义。因此,也需要过滤。
轨迹数据预处理主要是针对原始轨迹数据进行无效点剪枝,剪枝条件主要有以下几点。
(1) 速度剪枝: 过滤速度大于速度阈值δv的轨迹点,以剪除干扰研究的高速轨迹点。
(2) 时空剪枝: 过滤距离小于给定的最小距离阈值δd且时间差小于给定的最小时间阈值δt1,以剪除同一地点短时间内重复采集的轨迹点。
(3) 角度剪枝: 在规律的轨迹上,某些轨迹点突然异常偏离,跳到远处又迅速跳回的轨迹点。具体剪除步骤如下:
① 按时间顺序遍历轨迹,取每相邻3个点记为Trajk={Pk-1,Pk,Pk+1};
② 提取Trajk={Pk-1,Pk,Pk+1}三点的经纬度,计算以Pk为顶点的夹角∠Pk-1PkPk+1和Pk-1和Pk+1的时间差Δtk;
③ 如果夹角∠Pk-1PkPk+1小于给定最小角度阈值δa,时间差Δtk小于给定最小时间阈值δt2,删除中间点Pk。

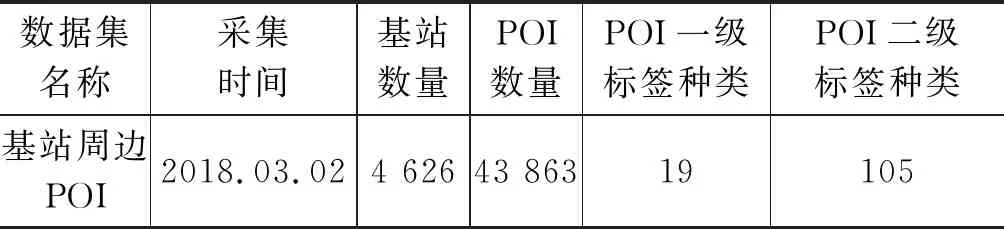
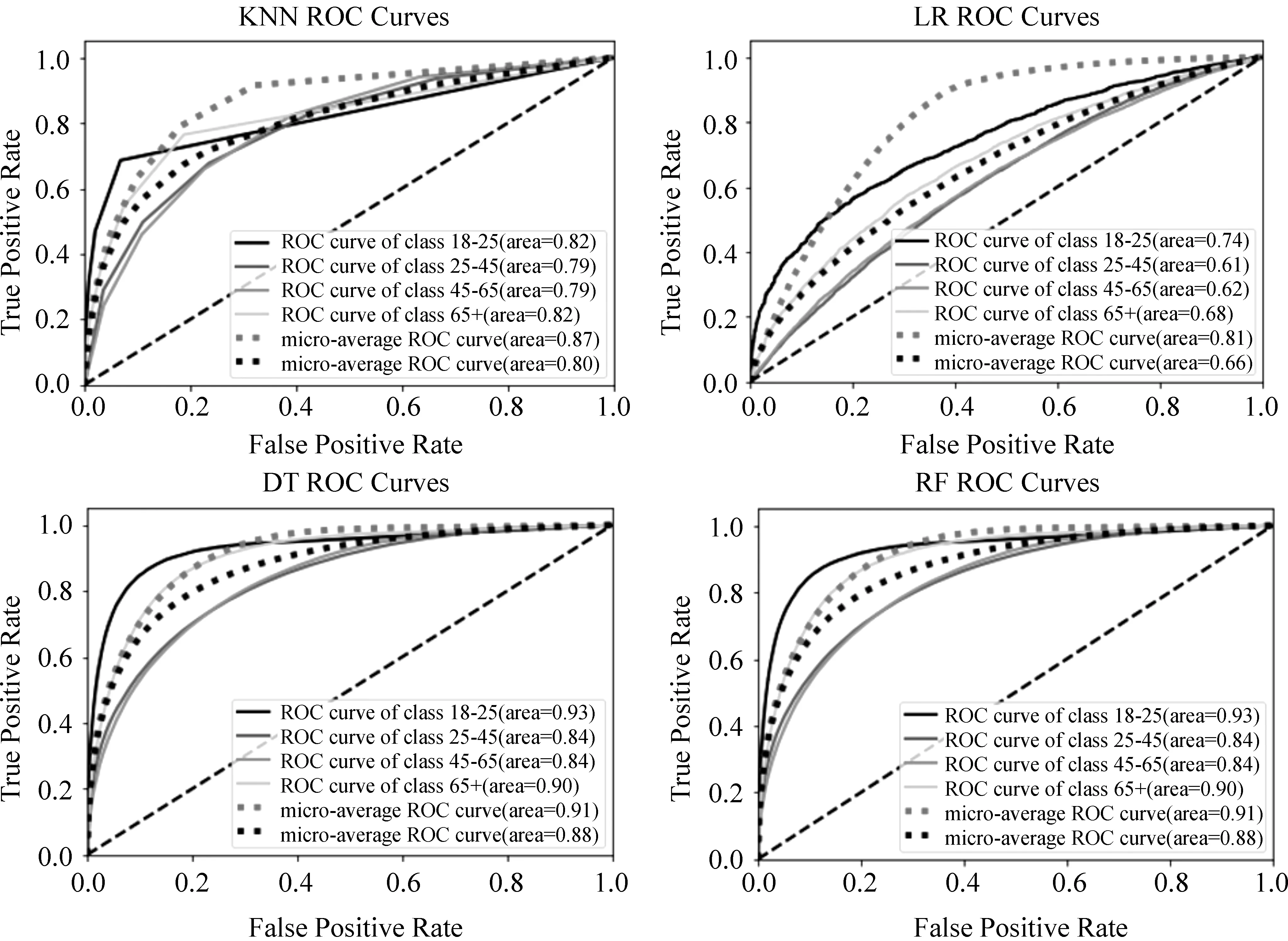
算法 轨迹数据预处理算法VSTA-Pruning输入:原始轨迹序列Traj,速度阈值δv,距离阈值δd,时间阈值δt1和δt2,角度阈值δa输出:保留有效点的轨迹序列Traj'1 k=1,pointNum=length[Traj],Traj'=[];2whilek 根据实际经验,普通公路上的速度上限一般在60km/h~120km/h,人的步行速度一般在15km/h,同时一般而言,用户不可能在3秒内以任何交通工具方式形成锋利锐角的轨迹夹角。因此,在本文中,速度阈值δv=15km/h,距离阈值δd=200m,时间阈值δt1=60s,δt2=3s,角度阈值δa=15°。 根据上述方法和阈值,图2左图是某用户某段时间的原始轨迹,图2右图是过滤无效轨迹点后的剪枝轨迹,可以看出剪枝轨迹更加清晰,可用作进一步的研究分析。 图2 剪枝无效点前后的轨迹对比图 关于移动轨迹的分析方法主要有两类: 基于地理信息和基于语义信息。前者主要关注轨迹的具体位置特征,如经纬度、移动方向和移动距离等;后者主要关注与轨迹紧密相关的语义特征。二者的关系和不同如图3所示。 图3 轨迹地理图和轨迹语义图 由图3可知,从轨迹的形状来看,A与C更加相似。但从轨迹的语义来看,A与B的相似程度高于A与C的相似程度。 本文根据用户移动端上网时所访问基站的经纬度,从国内某知名互联网地图服务商获取每个基站周边的POI数据,从中分析提取该轨迹点的语义代表。 兴趣点POI(point of interest)是地理信息系统中的一个术语。泛指一切可以抽象为点的地理对象,尤其是一些与人们生活密切相关的地理实体,如学校、银行、餐馆、加油站、医院、超市等。POI的主要用途是对事物或事件的地址进行描述。能在很大程度上增强对事物或事件位置的描述能力和查询能力,提高地理定位的精度和速度。本文中使用的POI的一级标签共有19个。分别为: 房地产、公司企业、教育培训、酒店、交通设施、休闲娱乐、政府机构、行政地标、购物、美食、金融、汽车服务、医疗、内部楼号、运动健身、旅游景点、生活服务、文化传媒、自然地物。二级分类共有103种有效标签。包括: 宿舍、公司、培训机构、厂矿、写字楼、剧院、福利机构、村庄、商铺、各级政府、中餐厅、超市、住宅区、银行、中学、健身中心等。 通常一个基站周边的POI会有多个,故可以利用语义分析的词频-逆文档频率(TF-IDF)方法来找出对每个基站词义贡献最大的标签。因在后面的分析中,希望尽可能细分每次访问基站的语义类型,故本文采用POI二级标签来分析轨迹的语义特征。 TF-IDF是一种用于信息检索与数据挖掘的常用统计方法。其中,TF(term frequency)表示词条在文档中出现的频率。但只考虑词条出现的频率会对高频词条产生过大的依赖,且有可能会忽略部分仅在某类中出现的低频词条。只考虑词频不足以表示一个词条对样本类别的有用程度,故而需要计算IDF值。 IDF(inverse document frequency)是用包含特定词条的样本数来计算该词条的权重。即包含某个词条的样本越多,说明该特征项出现在大部分样本中,其代表类别的能力就越弱。也就是说若包含某个词条的文档越少,则这个词条的语义贡献度就越大。即IDF越大。 传统TF-IDF算法如式(1)~式(3)所示。 然而,即使是轨迹语义相似,不同时间的轨迹语义仍然有不同的代表意义。如在早上6:00~10:00出现在中餐馆的用户可能是服务人员,而中午11:00~13:00出现在中餐馆附近的用户可能是来就餐的周边上班族。因此,本文在通过提取轨迹点周边一定范围内的POI,直接采用TF-IDF提取轨迹点的语义的基础上,提出包含访问时间信息的带时间标签TF-IDF(term frequency-inverse document frequency with time label, 后文称为TFT-IDFT)方法,对不同时间的轨迹语义加以区分。计算如式(4)所示。 (4) IDFT是指时间段ti中包含POI标签aj的样本数与除时间段ti之外的其他时间段包含POI标签aj的样本数的比值。如果某个POI标签在某个时间段中的IDFT越高,说明该POI标签在不同时间段出现得越不均匀,其代表意义也越强,即该POI标签在该时间段越重要。IDFT计算如式(5)所示。 (5) 其中,ns(j|i)表示时间段ti中包含POI特征aj的样本数,ns(j) 表示样本集中出现POI特征aj的样本数总数;为了避免IDFT不可求(分母为0),令λ=1。 IDF算法的核心思想在于只在少量样本中出现的标签比在大量样本中都出现的标签重要,即IDF主要用于增强在少量样本中出现的标签的代表性,减弱在大量样本中出现的标签的代表性。不同访问时间的轨迹点语义提取概率如式(6)所示。 TFT-IDFT=TFT(aj|ti)×IDFT(aj|ti) (6) 为了反映人们普遍的行程规律和日常生活习惯,本文将访问的原始时间划分为以下10档,如表1所示。 表1 访问基站的时间段标签划分 在此基础上,将提取出的特定时间段特定轨迹点周边TFT-IDFT最大的POI二级标签作为该时间段该轨迹点的语义代表。 2.3.1 模型概念 词向量技术的核心思想是将一个单词表示为一个N维的实数向量,两个向量的相似度可以用来描述其对应单词的语义相似度。 Word2vec有两类模型: CBOW(Contious Bag-of-Words)模型和Skip-gram模型。其区别在于CBOW利用上下文预测目标词,Skip-gram模型通过目标词来预测上下文,如图4所示。 图4 CBOW和Skip-gram模型构架图 本文采用Skip-gram模型,对于给定的一系列单词w1,w2,…,wT,其目标函数如式(7)所示。 (7) 其中,k为训练窗口大小,代表目标词前后各k个单词作为目标词的相邻词;p(wt+j|wt)表示根据目标词wt正确预测相邻词wt+j的概率;T表示语料库的词总数。 模型中每个词都有一个输入向量和输出向量,分别为记为uw和vw。对于给定词wj正确预测wi的概率如式(8)所示。 (8) 其中,V表示词典中的词总数。 2.3.2 本文应用 在本文中,选择Skip-gram模型的主要原因是传统的轨迹识别和推荐方法并不能捕捉到某一位置访问的上下文信息。若将某一用户连续访问的位置作为能够反映其访问规律的轨迹,这就与其写一个句子来表达他的语义是类似的。这就使得利用自然语言处理方法对用户移动模式进行建模分析具有合理性[13,20-21]。此外,和其他诸如主题分析等自然语言处理方法不同,Skip-gram模型在上下文(即前后词语)分析上更加适用。 本文首先对每个用户的访问数据按时间顺序进行排序,将每次访问的位置视为用户整个访问“句子”的组成“词语”,得到的所有访问位置就可以作为位置词库。在此基础上,应用Skip-gram模型去学习每个词语(即每个位置)的向量表达。需要注意的是,每个位置的向量表达与其上下文密切相关,即每次访问前后访问的一串位置对此次访问位置的语义向量表达也有着重要的影响。由于每个用户的访问轨迹通过时间顺序组织,故连续访问的位置之间的隐含关系已经被包含在内。尽管,每次访问后的位置在当时并不可知。但是,在用户特征识别过程中,可以先通过历史轨迹进行建模,在有新的轨迹访问点加入后继续进行调整。因此,通过将基站访问序列视为虚拟句子,每次访问位置及其上下文位置的关联性可以得到更好的模拟。 每一个用户的轨迹由两个平行的序列按时间顺序组成: 1)基于时间段和语义特征的语义序列。2)访问基站的地理位置序列。序列中的点按时间顺序一一对应,如图5所示。 图5 轨迹语义序列和位置序列 如果将每个用户的轨迹作为一个文档,其中的每个轨迹点就是文档中的单词。因每个轨迹点同时包含语义信息和位置信息,故每个轨迹点相当于同时对应了两个单词。即按照时间顺序,每个用户的轨迹对应了语义序列和位置序列两个文档。通过Word2vec分别对这两个文档的单词进行训练,得到轨迹语义词向量和位置词向量后,再将二者用元素相加的方式结合在一起。即可以得到不同时间段轨迹点的向量表达,并在此基础上对每个用户的轨迹进行算数平均,得到每个用户的向量代表,如图6所示[13]。 图6 通过Word2vec方法从轨迹语义和位置信息得到用户轨迹特征的流程图 本文中采用的轨迹数据来自于某通讯运营商。随机抽样1 163位用户,提取2017年1月1日至2017年8月16日的所有基站访问数据和含用户年龄特征的用户基本信息数据,共计4 257 754条有效记录。利用基站数据中的经纬度,通过国内某知名地图服务商API服务,得到基站相关POI记录43 863条。在用户ID匹配和基站经纬度匹配的基础上(图7),通过VSDA Pruning剪枝过滤,最终整理出有效数据2 385 094条。具体说明如表2至表4所示。 图7 数据之间的匹配 表2 用户信息表 用户信息的字段包括: 用户ID和用户年龄段。 表3 基站访问数据表 基站访问信息的字段包括: 用户ID、访问时间、基站代码、基站经度、基站纬度。 表4 基站周边POI数据表 基站周边POI数据的字段包括: 基站代码、基站经度、基站纬度、POI经度、POI纬度、POI距离基站距离、POI一级标签、POI二级标签。 通过TFT-IDFT的方式对轨迹点周边POI数据进行分析,提取每个轨迹点最具代表性的地址特征。可以看到,在不同时间段,不同年龄段用户的轨迹语义特征存在着一定的差异。 例如,如图8所示,工作日早上的休闲场所,18—25岁的青少年出现的频率最高,而工作日晚上青少年出现的频率最低。25—45岁的青壮年和45—65岁中年人群在两个时间出现的频率比较稳定,且在晚上时段出现的频率明显超过其他两个年龄段的人群。另外,如图9所示,同样是在工作日的早上,中青年人群在公司企业出现的频率明显高于老年人群,而老人群出现在急救中心的频率远超过其他三类人群,与现实相符。 图8 各年龄段人群在工作日早上和晚上访问休闲广场的频率分布 图9 各年龄段人群在工作日早上访问公司企业和急救中心的频率分布 分类模型的训练数据为总数据中随机抽取的67%,剩余的33%作为测试集。采用分类算法中通用的评价指标: 精确度(Precision)、召回率(Recall)和准确度(Accuracy)来评价模型的效果,如式(9)~式(11)所示。 (9) 表5 模型识别评分标准 精确度又称查准率,反映了模型识别正确的正例在所有正例样本中的占比;召回率又称查全率,反映了模型识别正确的正例在所有识别正确样本中的占比;准确率反映了模型对整体样本的识别能力。这三个指标的值越高,说明模型的识别能力越强。 为了更全面地反映年龄识别效果,本文选取了常用的4种分类识别方法: K近邻(KNN)、逻辑回归(LR)、决策树(DT)和随机森林(RF)。识别预测结果如表6所示,4种方法的ROC曲线如图10所示。 表6 年龄段识别结果 图10 4种分类识别方法的ROC曲线 从表6和图10可以看出,对于本文划分的4个年龄阶段,决策树(DT)和随机森林(RF)的识别和预测结果相对更好。准确率分别达到了69.78%和69.82%,好于K近邻(KNN)65.96%和逻辑回归(LR)51.66%的准确度。在精确度和召回率上,决策树(DT)和随机森林(RF)也比其他几种方法表现更好。 此外,通过比较TF-IDF方法和改进的TFT-IDFT方法提取轨迹语义后的年龄识别准确率,如图11所示,可以看出通过TFT-IDFT方法提取轨迹语义,并在此基础上应用Word2vec提取轨迹词向量的用户年龄段识别模型具有更高的预测准确率,即说明了TFT-IDFT的有效性。 图11 基于TF-IDF与TFT-IDFT的用户年龄识别准确率比较 用户轨迹的功能语义是识别用户特征的重要依据。通过深入挖掘不同时间段各轨迹点所具备的功能语义,研究用户访问不同位置语义的概率,对于识别用户特征具有重要意义。 本文从用户的原始轨迹出发,首先从速度、距离、时间、运动方向及其变化等方面,对原始轨迹数据进行有效剪枝和清洗(VSTA Pruning)。然后,通过在传统TF-IDF算法中添加时间标签,利用带时间标签的TFT-IDFT方法提取轨迹点周边的POI语义。在提取出的语义轨迹上通过使用Word2vec模型,对用户的有效轨迹点进行了向量化处理,并在此基础上利用分类模型对用户的年龄段特征进行识别和预测。实验结果表明,改进的TFT-IDFT方法提取轨迹语义的效果明显好于传统的TF-IDF方法。建立在Word2vec模型生成的轨迹点时,时空词向量上的分类模型(分类树和随机森林)对用户年龄段的识别也具有一定的有效性。此外,由于本文使用的基站轨迹数据精确度并不高,而轨迹数据的来源广泛,如手机的地图App或社交App等可以获取更加精确的GPS轨迹数据。因此,本文的研究不仅可以适用于当前的基站轨迹数据,还可以基于精确度更高的轨迹数据进行用户特征分析,应用场景广泛,可以为用户识别与营销推荐提供有效支持。 接下来的研究会从以下方面重点展开: 1)因数据限制,本文并未研究用户的上网操作特征,实际上这也是用户年龄段特征的重要识别因素。结合用户在不同时间、不同地点和用户当时当地的上网链接和操作,可以进一步提升分类的准确率。2)通过向量化轨迹点的位置特征和语义特征,可以得到每个用户唯一的向量化表示。基于此可以进一步判断用户之间的相似性,通过聚类方式可以找出不同年龄段用户的生活规律和行为习惯,甚至可以识别出不属于该年龄段的上网行为,确定移动端实时使用人的身份特征,为进一步分析不同年龄段用户上网行为提供支持。
2.2 轨迹语义分析



2.3 轨迹语义词向量构建



3 实验结果与分析
3.1 实验数据及数据预处理



3.2 不同年龄段人群轨迹语义分布


3.3 年龄识别方法与评价指标



4 结束语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
开放教育研究(2020年2期)2020-03-31
通信技术(2020年2期)2020-03-26
恋爱婚姻家庭·青春(2019年9期)2019-12-10
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
