
共享时代下高校高性能计算系统的设计与实践
2019-08-16 00:32姚舸
实验室研究与探索 2019年7期
姚 舸
(南京大学 物理学院,南京 210093)
0 引 言
随着计算机技术的高速发展,高性能计算已经成为与理论和实验并驾齐驱的三大研究方法之一。2006年2月9日,国务院颁布的《国家中长期科学和技术发展规划纲要(2006-2020)》中提出将千万亿次高效能计算机研制列入优先主题:重点开发具有先进概念的计算方法和理论,发展以新概念为基础的、具有1017/s次以上浮点运算能力和高效可信的超级计算机系统、新一代服务器系统,开发新体系结构、海量存储、系统容错等关键技术。
高性能计算可以模拟高温、高压、强磁场等极端环境下研究对象的变化;获取实验全过程、全时空的全部变化信息;以极低的成本反复运行,获取各种条件下的全面数据以便于比较。这些都是真实实验无法达到或代价过于高昂而不值得的。[1]从“中国制造”向“中国创造”的跨越,创造新产品如同科研,需要通过高性能计算进行各类仿真,缩短研发周期抢先占领市场,近些年来高性能计算扮演着越来越重要的角色。[2]
1 高校高性能计算建设现状
2010年11月由国防科技大学研制的天河1A超级计算机系统首次问鼎世界超级计算500强系统排名中的占用率逐年增加,从2013年至2018年初我国一直占据TOP500第一的位置[3-4]。随着国家对于高性能计算重视程度不断提升,科研院所科研经费投入加大,我国已建成6个国家级超级计算中心,众多高校均建设了校级的高性能计算中心,部分院系有院系级高性能计算平台,许多课题组也自建有高性能计算集群,科研人员可使用这些计算资源进行数值计算模拟。[5-6]
1.1 校级高性能计算中心
南京大学是国内较早成立校级高性能计算中心的高校,分别于2007年购置了共享内存型架构的小型计算机SGI Altix 4700(256核,512GB内存),2009年购置了IBM大型刀片集群(约3200核,理论计算峰值34×1014/s)[7],2015年学校又投资5 000余万元购置了联想刀片集群,具备910台计算节点、21 840个CPU核心,8块NVIDIA Tesla K40,理论计算峰值达885×1014/s[8-9]。类似的,中国科学技术大学超级计算中心的曙光TC4600 1016/s超级计算系统,具备506台计算节点、12 200颗CPU核心,8块NVIDIA Tesla K80,8个Intel Xeon Phi 7210,理论计算峰值519×1014/s[10]。上海交通大学高性能计算中心的“π”集群,具备435台计算节点、约7 000个核心,100块NVIDIA Tesla K20、10块K40、24块K80、4块P100,理论计算峰值343×1014/s[11]。
不难看出,作为服务于全校性的大型共享平台,校级高性能计算中心规模大、预算充足,能获得学校、厂商和代理商的重点支持。此外,校级高性能计算中心一般均配备有相当数量的专职管理人员,且管理人员队伍稳定,集群运行状态良好。
1.2 院系及课题组级别的高性能计算平台
许多高校除了校级高性能计算中心,部分计算需求较高的院系建设有院系级的高性能计算平台[12]。某高校自2012年1月至2017年12月购置的各类服务器,排除校级高性能计算中心、明显不用于高性能计算的学校部处机关、职能部门(如网络中心、图书馆等)和部分文科院系,设备资产总值已超过4 000万元。各品牌的采购金额统计见表1,其中5大主流品牌IBM/Lenovo System X、HP/HPE、Dell、浪潮和曙光的占比约88%,且绝大部分均应用于高性能计算,属于院系及课题组级别的高性能计算平台。以某学院为例,现有的高性能计算平台中IBM 105台、Lenovo System X 72台、HP/HPE 126台、Dell 104台、浪潮63台、曙光8台,五大品牌均有涉及。

表1 院系级高性能计算设备品牌统计
相较于校级计算中心,院系和课题组集群专为本学科方向科研服务,配置和环境更贴合本学科的计算需求。特别是课题组自有集群,完全自主控制无需排队,可优先计算突发紧急任务,受到众多科研人员的喜爱。另一方面,高校工作人员编制异常紧张,学校更多地将有限的编制名额用于引进科研人才,普遍忽略了实验技术队伍的建设,导致课题组内的高性能计算集群一般由年轻教师或研究生兼职管理。由于集群管理专业性很强,科研人员的专长在学术研究不一定在集群管理,他们花费了宝贵的时间和精力却又很难管好。以研究生管理为例,第一位学生一般参与服务器的安装部署过程,对集群构架有了整体的了解,能够较好的管理集群。几年后,当第一位学生面临毕业,专注于撰写论文和找工作,后续接替管理的学生则很难再次得到系统的培训。一旦第一位学生毕业离校,集群管理就容易“断档”,甚至出现后续学生只会使用登录节点计算,而不知道还存在计算节点的情况。集群长期处于亚健康状态运行,疏于管理使用率低,一定程度上造成了科研经费的浪费[13]。甚至出现设备采购后,因无人管理一直没有正常运行,多年后直接报废,造成的浪费令人痛心。
课题组和院系紧密联系不可分割,院系级的高性能计算平台管理一般有4种类型:
(1)院系无机房等公共设施,各个课题组完全自行建设管理高性能计算集群。因无专门的机房,课题组一般在其实验室分割一小块区域作为简易机房安装高性能计算集群,机房环境较差,很难保证设备长期稳定运行。
(2)为提高实验用房利用效率加强管理,避免分散建设机房,院系统一建设机房供各个课题组使用。课题组将高性能计算集群统一托管,院系负责机房基础设施运行,如空调、UPS、配电等,不涉及计算机系统的管理,一般无需专职管理人员。
(3)在为课题组托管设备的基础上,院系还购置有公共的高性能计算集群共享使用,院系需管理共享集群,因此需要专职管理人员或服务商管理维护。
(4)院系将公共和课题组高性能计算集群统一管理互联互通,实现了真正的融合统一,资源共享,需要专职管理人员或服务商协助管理。
一般高校的大多数院系属于前3种管理类型,各个课题组集群自行管理、各自为政,无法避免上文提及的无人管理的困境。而且各组研究进度不同,相应集群资源使用也不平衡,有的组有大量资源闲置,而有的组却很紧张需要到外面购置计算资源。各用户账号和科研数据均不互通,所用系统支撑软件有所不同,无法进行共享。
只有第4种类型的统一共享才能解决上述问题,由院系的专职人员管理,让课题组师生从日常管理中解脱出来专注于科研,通过打通用户账号和科研数据,实现资源共享,提高集群的工作效率和科研经费的使用效率。
2 构建混合品牌和架构的共享高性能计算系统
校级高性能计算中心由于规模大,普遍为一次性投资,单一品牌和架构便于管理,厂商或代理商也均能提供良好的售后服务。而课题组和院系集群属于持续性投资,特别是各个课题组经费预算和使用周期不同,一些较大规模的院系基本每年均有购置。计算机设备各品牌竞争极其激烈,每次招标各有胜负,这也就造成了院系级或课题组的计算平台设备品牌众多架构复杂,要实现这些集群的互联互通,需要考虑多方面因素。
2.1 高热密度机房
为了整合各个集群,首先需将集群集中托管。高速低延迟网络(如InfiniBand、Omni-Path等)对线缆长度有严格的要求,在可接受的延迟内只能满足机房内的互联。随着高性能计算集群密度不断提升和刀片式服务器等高密度设备的广泛应用,应建设统一的高热密度机房,实现集群的集中托管。
与普通机房不同,高热密度机房是专为高密度服务器设计的。2 m高度标准机柜提供42U空间,主流品牌平均10U高度提供约16台双路CPU计算节点,规划使用30U高度安装约50台双路服务器,剩余空间用于安装存储、I/O节点、交换机、电源分配单元等低热密度设备和布线。基于上述需求单机柜设计供电散热能力应达到20 kVA,机柜一路为UPS供电,另一路为市电直接供电,每回路采用三相五线制,每相电流32 A。
散热是高热密度机房遇到的最大挑战,针对高热密度制冷方式主要有冷热通道分离、密闭制冷机柜和温水冷却。冷热通道分离将热空气区和冷空气区分隔,防止冷热空气混合,迫使所有冷空气经过服务器等设备后进入热区再回到空调进行冷却,提高了冷却效率,常用行间制冷空调冷却热空气。密闭制冷机柜前后柜门密闭,空调和机柜一体化,冷热空气完全在机柜内部循环,进一步提高了制冷效率[14]。温水冷却使用温水直接冷却CPU等主要热源,具有极佳的能效比[15],电源使用效率(Power Usage Effective,PUE)值约1.1。但温水冷却尚无统一的标准,先建设机房后分批采购设备无法采用此种冷却方式,只能使用冷热通道分离或密闭制冷机柜。采用传统房间级空调冷热通道分割如图1所示。
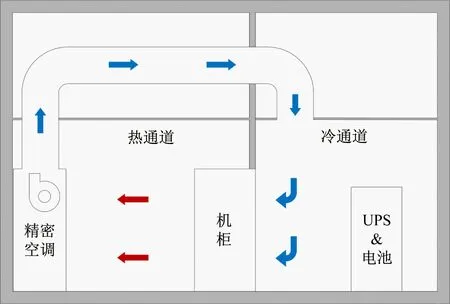
图1 高热密度机房剖面图
2.2 服务器等设备要求
虽然不同批次采购的设备品牌架构不同,但是为了统一管理应制定一套基本要求。根据采购相关管理规定,此套基本要求应是大多数产品均能满足的,不应成为采购过程中的限制条件。
服务器应支持完善的远程管理功能,这也是服务器与工作站或台式机的重要区别。X86服务器普遍支持的智能平台管理接口(Intelligent Platform Management Interface,IPMI)是由Intel发起的远程控制服务器接口,提供了统一的服务器硬件远程操控和监控方案。IPMI的核心是提供IPMI功能的基本管理控制器(Baseboard Management Controller,BMC),BMC独立于操作系统直接对服务器硬件进行操控[16]。通过IPMI远程控制服务器,实现开关机和设置下一次启动设备,服务器安装操作系统和开关机日常维护均可远程进行,IPMI还提供了丰富的监控功能,在线对故障进行报警和诊断,实现远程报修。需要注意的是Lenovo System X、HPE、Dell的部分服务器需购买许可升级才可远程查看控制台界面,这对查看安装操作系统中的错误或宕机状态极其重要。
所有硬件设备均应支持远程操作和监控,做到日常运维不进机房;应支持远程日志发送和电子邮件报警,通过远程日志发送集中归档,关键故障通过电子邮件报警通知管理员及时处理。
2.3 网络架构
通过统一的网络将各个品牌和架构设备互联才能构建单一的系统。网络分为3种:硬件管理网、集群管理网和高速低延迟通信网。
硬件管理网连接所有硬件设备管理网络,如服务器的IPMI端口、存储管理端口,实现硬件设备远程操控和监控。网络带宽需求低,无高可用要求,采用100 MB接入1 GB级联即可满足需求。集群管理网连接所有服务器操作系统的以太网,用于节点互相通讯,对网络带宽需求较高,有高可用性要求,一旦瘫痪整个集群都不可用,采用1 GB或10 GB接入40 GB/100 GB级联。考虑到安全因素,上述两个网络应实现隔离,既可通过硬件隔离也可通过VLAN逻辑隔离。
高速低延迟通信网是采用InfiniBand、Omni-Path等专用网络,与普通以太网相比延迟和带宽均有数量级的提升,能够为消息传递接口(Massage Passing Inteface,MPI)和文件系统提供高带宽低延迟的通讯,是实现大规模并行计算的关键。对于部分要求不高的集群,可以采用集群管理网兼顾该项功能,那么集群管理网应采用10 GB甚至25 GB接入。
上述3套网络将不同品牌和架构的设备互相连接,规划IP地址时应使用3个容量相同的独立子网,预留在可预见的将来足够使用的地址资源,如3个B类网络可以满足绝大多数需求。集群一旦建立正常运行以后,修改网络架构和地址可能需要长时间停机以调整各个设备配置,这基本是不可接受的,因此需要前期预留足够的冗余。
高性能计算集群中非计算和I/O的节点,可利用虚拟化技术减少硬件投入,共享高性能计算系统架构见图2。
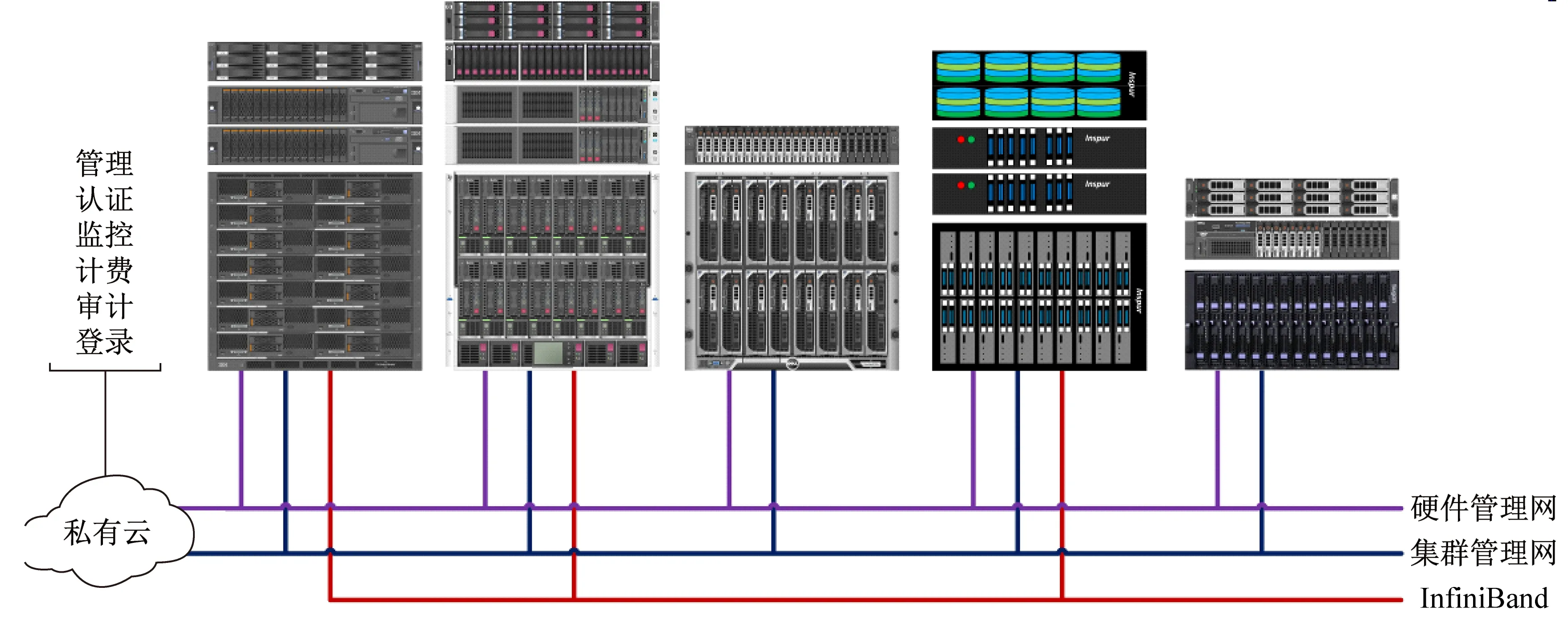
图2 高性能计算集群架构
2.4 集群系统管理软件
xCAT(Extreme Cluster/Cloud Administration Toolkit)作为集群系统管理工具是一套开源的集群管理和配置工具,它允许使用者通过单点控制和管理一套集群系统,不仅简化集群管理,还提供批量部署功能,从而提高了管理员的工作效率[17]。
xCAT使用数据库存储集群信息,如每个节点的BMC地址、操作系统版本、主机名、MAC地址、IP地址等,并生成相应的配置文件。集群部署时xCAT通过BMC设置节点下一次通过网络启动,再远程开启节点电源。节点开机从网卡启动,向本地广播地址发送含有PXE option的DHCP Discover包,xCAT服务器根据请求的MAC地址提供对应的网络配置和PXE启动文件。节点获取相应配置后,从xCAT服务器下载文件,在本地部署操作系统,并执行后处理脚本,如建立SSH互信等。
管理员使用xCAT的批量文件分发和执行命令的功能,在所有节点并发安装驱动程序、文件系统等工作,工作强度和执行时间与节点数量无显著关系。xCAT提供的批量功能操作,不仅将管理员从繁琐重复的劳动中解脱,而且各个节点执行命令统一,尽量消除节点间差异。编排一套系统部署流程,将其标准化脚本化,实现了节点从部署操作系统到最终上线正常运行的全自动操作。节点出现无法通过重启解决的故障时,使用一条命令即可在10 min以内,无人工干预完成节点操作系统重新安装,将重装的时间从h级缩短到min级,提高了整个集群的利用效率也降低了管理员的工作量。
2.5 并行文件系统
并行文件系统为高性能计算集群提供了共享、统一命名空间的共享存储空间,与传统的NFS文件系统相比,并行文件系统支持MPI-I/O多进程可对单一文件并发读写,有更高的性能和更好的横向扩展性[18]。对于各课题组原有存储,将性能相近的存储合并为一个文件系统,性能差异明显的作为不同的文件系统使用。每个课题组仍使用原有存储,但文件系统挂载到整个共享平台中,打破数据壁垒。院系还应购置公共的存储供所有用户使用,其中元数据宜采用独立的固态硬盘,大幅提高元数据操作性能,这样当存储负载较高时,用户前台操作不会有明显的延迟。
集群中有部分文件是所有用户均需使用的,如作业调度系统、编译器数学库等,有条件时可将公共软件使用独立的硬盘阵列提供,防止由于用户作业大、I/O阻塞,导致所有用户访问公共目录缓慢,甚至作业调度系统崩溃。
2.6 计算队列
不同时期购置的服务器,CPU网络等配置均不尽相同,不同配置的服务器如果运行同一个并行计算,慢的节点会显著拖慢整体计算,需要通过不同的队列区分,相同CPU和网络的节点才能组成一个计算队列。
与校级或院系级平台不同,整合的平台中各个队列的节点由不同的课题组购买,课题组自建集群的重要因素是可以独享使用而无需排队,故作为整合平台应首先满足课题组自己的计算需求,空闲节点再开放共享。因此在作业调度策略上,应该配置两个优先级不同的队列,低优先级的队列对所有用户开放,高优先级队列只对队列节点购置的课题组成员开放。作业派发时,首先派发高优先级的队列,当高优先级队列为空时派发低优先级队列作业,这样就在作业派发环节上保证了队列节点所有者的优先权。在实际使用中发现,有时由于队列节点所有者课题组作业很少,此队列大多数节点被低优先级队列的作业运行占用,当队列节点所有者提交作业到高优先级队列时因无空闲节点而无法派发作业。出现此种情况可以配置抢占策略,当高优先级队列作业无足够资源派发时,可以挂起低优先级作业空出足够的资源让高优先级队列作业运行。
一个队列的节点可能由不止一个课题组购置,当有两个或两个以上课题组购置的节点组成同一个队列时,在高优先级队列上限制正在运行作业所使用的CPU核数为本课题购置节点的CPU核数总和,这可保证在高优先级队列上多个课题组最多只能使用自己购置的那部分节点。
2.7 账号管理
高校的学生,特别是研究生是高性能计算集群的主要使用者,从精细化管理和数据安全的角度出发,应该为每个人开设独立的账号。但是每年都有约1/5的学生更替,即老学生毕业离校和新学生入校,大量的账号删除和新建操作增加了管理员的工作量,故很多集群只给导师开设账号,并由导师负责管理这些账号。这就不可避免的导致账号多人共享,使用情况混乱,学生毕业后无法及时回收账号,给集群带来违规使用和安全风险。鉴于面对的风险,开发了用户管理平台,系统管理员只管理导师账号,学生账号由导师自主管理,每个学生均有独立的账号,学生毕业时系统自动收回账号。
3 共享平台运行情况统计
将各课题组高性能计算集群统一管理并融合为一套混合品牌和架构的高性能计算系统后,通过对2015-01-01~2017-12-31日作业信息进行统计,结果显示共累计完成作业1.257×107个,达9.801×107CPU h。集群运行近3年,根据机房基础设施情况和收费政策,可分为以下3个阶段:
2015-01-01~2016-03-11为第1阶段。因机房空调系统长时间高负荷使用,加之室外机散热不良,空调故障频发,集群无法全部开放使用,故于2016年3月12至18日更换了机房空调。此阶段集群不收费。
2016-03-19~07-14为第2阶段。新空调提供稳定而高效的制冷效果,集群满负荷运行,此阶段集群不收费。
2017-7-17~2017-12-31为第3阶段。2017-07-15~16机房停电,17日恢复运行后集群开始执行收费政策。用户在使用非本组购置的节点时,按照CPU核时收取计算费,并将收取的计算费返回给被使用节点的购置课题组。
对每个阶段总的和共享的CPU核时进行统计,其中共享的CPU核时指用户使用非本组购置的节点,在第3阶段共享CPU核时需要缴纳计算费,见表2。

表2 高性能计算集群使用统计 CPU核×104h
2011年Intel推出Sandy Bridge微架构,开始支持高级矢量扩展(Advanced Vector Extensions,AVX)指令集,AVX将向量化宽度扩展到256位,理想状态下每时钟周期浮点运算能力是前一代的2倍[19-20]。集群中部分节点CPU较老,不支持AVX指令集,实际使用中发现这些节点使用率低,故排除这些节点后再做一次总的和共享的CPU核时统计,见表3。
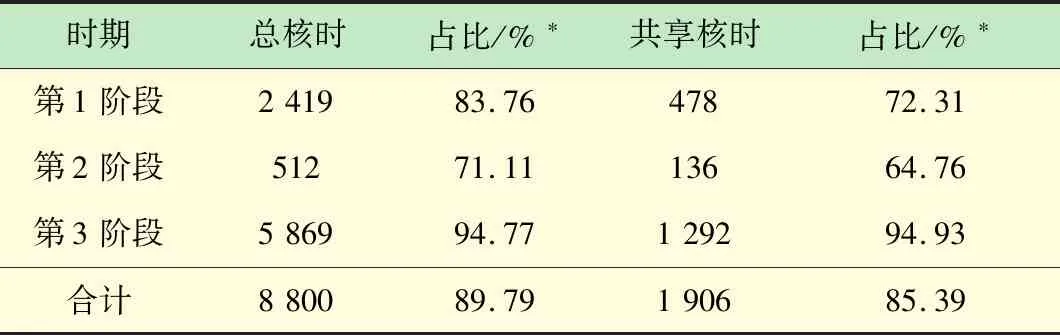
表3 高性能计算集群使用统计(CPU支持AVX) CPU核×104h
*支持AVX的CPU核时占所有CPU核时的比例。
从表2可见,3年间总计2 232万CPU核时的计算时间均为多集群融合后,课题组间可方便共享计算资源多出的计算时间。其中第2阶段机房制冷条件好,且不收取任何费用,共享达到顶峰,整个集群基本满负荷运行。在第3阶段,增加对共享CPU使用的收费,用户倾向于使用本组购置的节点,共享CPU使用比有所下降。表3展现出在经济杠杆的调节下,一旦开始收费,用户会尽可能使用新的节点,追求更高的性价比。
集群融合统一,3年间不仅增加了2.232×107CPU核时的计算,且在整个第3阶段集群一直稳定运行,无超过24 h的停机,这在以前各个课题组独立管理无专人负责的情况下基本不可能。这足以说明打破课题组壁垒,构建一个统一的集群可极大的提高集群使用效率,挖掘潜能,节约经费开支。
4 结 语
通过整合各个高性能计算资源,构建混合品牌和架构的共享高性能计算系统方案。对于每年分批次采购的校级高性能计算中心,将各个批次集群统一融合,打破了账号和数据的壁垒,提高整体使用效率。对于院系内各个课题组高性能计算集群,将其与院系已有公共集群融合,成为新的院系级高性能计算平台,解决了课题组集群分散无专人管理的窘境;在满足本组优先使用的前提下,开放共享,减少资源闲置。该方案有利于科研人员专注于科研工作本身,从集群管理中解脱出来真正成为集群的使用者。截至目前,共享集群规模近600个节点,涵盖IBM/Lenovo、HP/HPE、Dell、Huawei、H3C、浪潮、曙光、DDN、Brocade、BNT等主流品牌,3大高速网络InfiniBand、Omni-Path和iWARP,iSCSI、SAS、FC和Infiniband等各类存储,期间经历操作系统、并行文件系统和作业调度系统的大版本升级,六年多来整个集群系统一直稳定运行,很好地支撑了科研工作。
猜你喜欢
现代经济信息(2022年27期)2022-11-24
科技创新导报(2021年31期)2021-05-10
中国计算机报(2020年42期)2020-12-03
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
大学生(2016年7期)2016-04-29
中央社会主义学院学报(2015年4期)2015-12-01
中国音乐教育(2015年7期)2015-05-16
