
不平衡分类的数据采样方法综述
2019-08-17 08:00刘定祥乔少杰张永清魏军林张榕珂
重庆理工大学学报(自然科学) 2019年7期
刘定祥,乔少杰,张永清,韩 楠,魏军林,张榕珂,黄 萍
(1.成都信息工程大学 a.网络空间安全学院; b.软件工程学院; c.计算机学院; d.管理学院, 成都 610225;2.西部战区总医院, 成都 610083)
1 研究背景
针对现实生活中产生的大量数据,人们通过传感器等数据采集设备将其收集、整理,形成了计算机能够批量处理的数据。通过对数据的学习分析,挖掘潜藏在数据背后深层的知识和规律,可提升人们对外界事物的感知和理解能力[1-2]。然而,现实中这些数据大都比例不平衡。例如,癌症基因检测数据[3]中,在几百万个样本基因里可能仅有一个基因是癌症基因;电信通讯中只有少数通讯是具有欺诈行为的通讯记录[4-5];软件检测中也只有不到10%的软件是具有缺陷的[6]。
不平衡数据普遍存在于人类生活的方方面面,不仅数据分布广泛,而且数据比例不均衡。在不平衡数据中数量多的样本称为负样本,数量少的样本称为正样本。正负样本拥有较大的比例差距,例如:全国1年中雷电天气(正样本)天数占全年天数的比例不到10%;新生体检中患肺结核疾病的学生人数占比不到1‰。
在数据分类评价指标中,全局分类正确率是指分类正确的正样本与负样本数量之和除以总的正样本与负样本的数量。正样本分类正确率是指分类正确的正样本数量除以总的正样本数量。同理可得负样本分类正确率。通过上述定义可以知道:不平衡数据中,由于负样本数量远多于正样本,少数正样本被错分并不会大幅度地降低全局分类正确率,但正样本分类正确率会下降。
机器学习[7]利用训练数据对模型进行训练,使模型能够学习到样本数据特征,实现机器对样本数据的自动分类。精准分类一直是机器学习发展所必需的,但绝大多数流行的分类器是根据平衡数据进行设计,不平衡数据不能够充分训练分类模型,导致分类性能下降[8]。现阶段,机器学习大多通过梯度下降[9]方法训练模型参数,不平衡数据训练分类模型会导致分类模型的参数过多向负样本(majority class)倾斜,从而极大地降低了模型对正样本(minority class)的分类正确率。例如:对于同一分类方法,利用平衡数据集对分类模型进行训练时,分类模型能够较好地识别正负样本,获得较高的正负样本分类正确率;利用不平衡数据集对分类模型进行训练时,分类模型对正样本识别能力弱,降低了正样本分类正确率。
为了解决数据不平衡问题,许多数据不平衡处理方法被提出[10]。Anand等[11]早在1993年就对不平衡数据做了比较深入的研究,发现神经网络反向转播收敛速度慢,其原因是训练集中多数样本均属于同一类。与此同时,Krawczyk等[12]针对不平衡问题总结了不平衡数据主要应用领域,如表1所示,其中括号内数字表示统计应用的次数。表1充分说明了不平衡数据应用在各个领域,其分布广,使用频率高,是机器学习中普遍存在和亟待解决的问题。
当前,提升分类器在不平衡数据中的学习效果主要采用两种方法:
1) 对不平衡数据分类算法的优化。由于现阶段的分类算法主要是根据平衡数据集进行设计的,故优化不平衡分类算法不仅难度大,且在正样本分类正确率上提升不显著。
2) 对不平衡数据采样算法的优化。采样算法着手于数据层面,能够有效地解决不平衡数据正负样本分布不平衡的问题,且采样算法的优化设计相对容易,在正样本分类正确率方面性能可得到显著提升。研究不平衡数据采样算法能够有效地提升正样本分类正确率。本文着重从数据采样的角度介绍如何对不平衡数据进行处理。
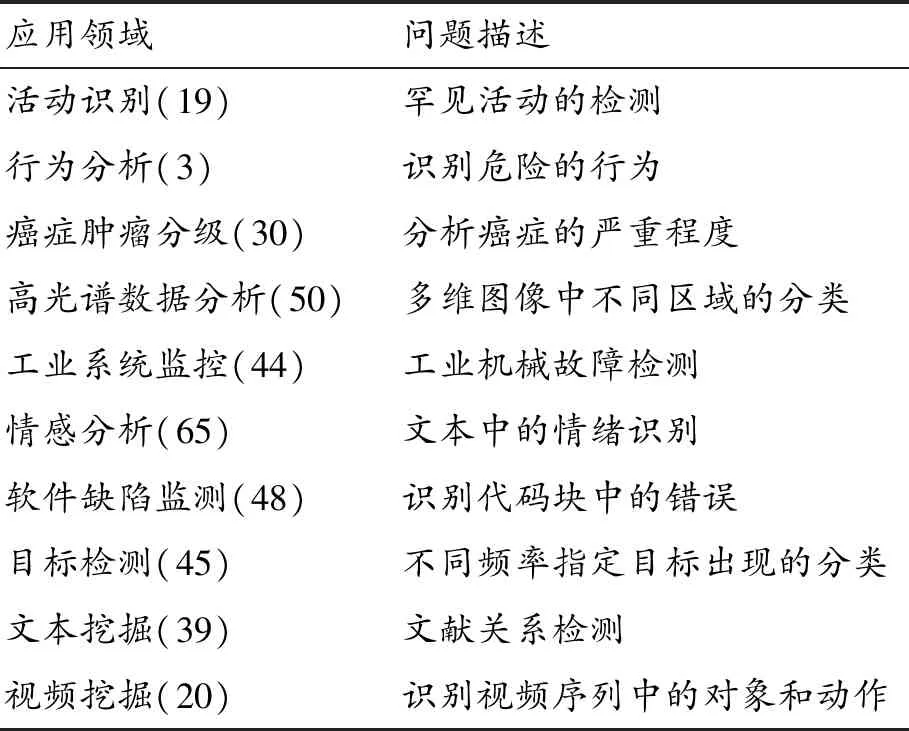
表1 不平衡数据的典型应用
当前,采样方法主要有以下3类:欠采样[13-20]、过采样[21-40]、混合采样[41-51],这三类方法都有各自的优缺点。
1) 欠采样方法指筛选一些具有代表性的负样本,使负样本和正样本达到比例相当,即所谓的“数据平衡”。其优点是训练集达到了平衡,提升了正样本分类正确率,缺点是丢失了大量的负样本特征,模型不能充分地学习到负样本的样本特征,降低了负样本分类正确率,欠采样过程如图1(a)所示。
2) 过采样方法是时下比较流行的方法,其工作原理和欠采样相反,目的是将现有的少数正样本通过模型生成新的正样本,使数据集中正负样本达到平衡。其优点是增加了正样本数量和正样本的多样性,提升了模型对正样本的学习量。缺点是生成的正样本不是真正采集获得的正样本,在增加样本数量和多样性的同时带来了样本噪声(样本不具有的特征)。模型学习样本噪声,降低了模型对正样本的分类正确率。过采样思想如图1(b)所示。
3) 混合采样是指将欠采样和过采样结合,正样本通过某种样本生成模型生成一部分新的正样本,负样本通过样本筛选模型筛选一部分具有代表性的负样本,达到正负样本数量平衡。混合采样旨在减少负样本的特征丢失,同时减少正样本的噪声生成,达到正负样本数量平衡,混合采样过程如图1(c)所示。
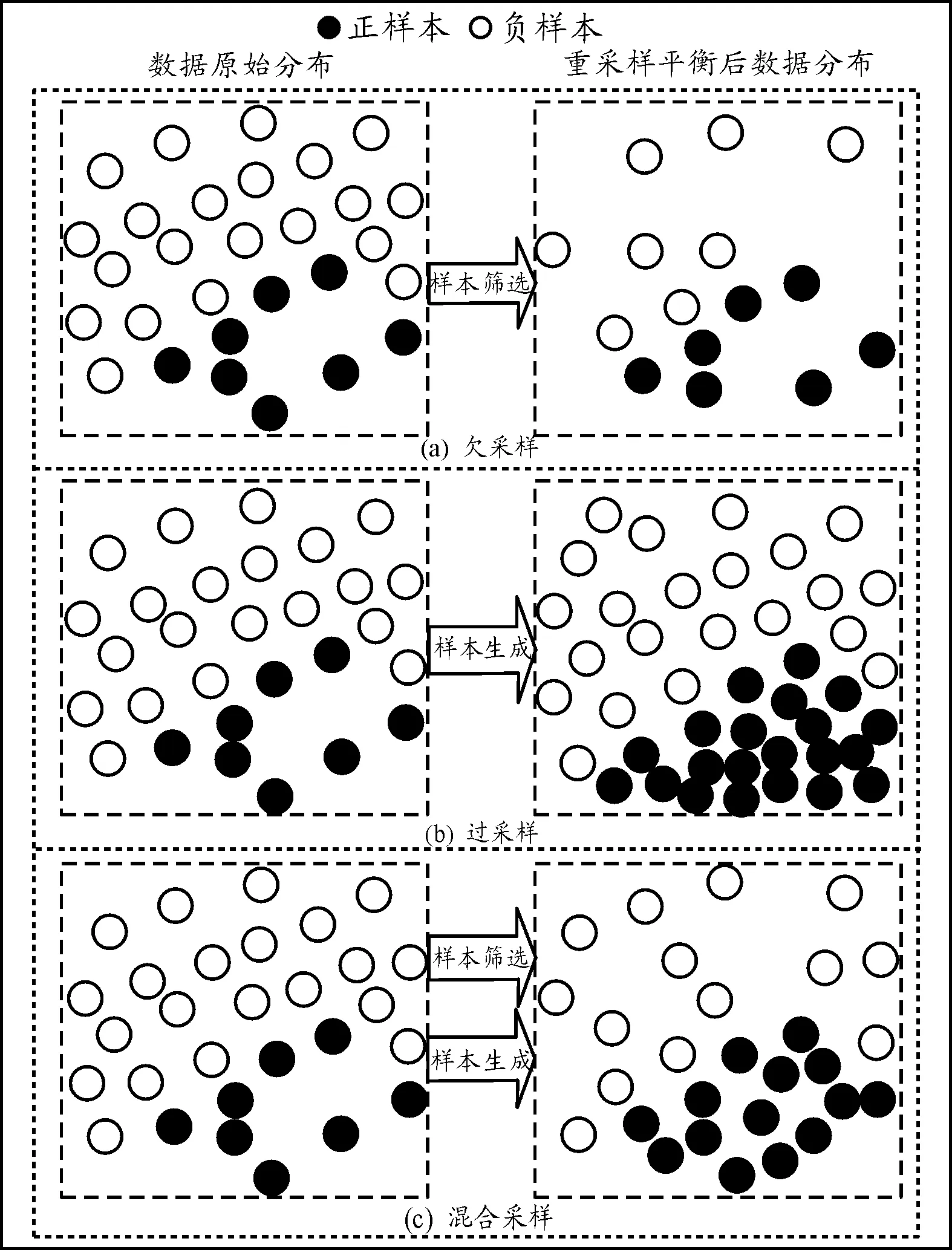
图1 不同采样算法工作原理
本文通过对当前国内外具有代表性的不平衡分类学习中的采样研究进行统计发现:其19%是欠采样的研究,52%是过采样的研究,29%是混合采样的研究。单从统计数据上可以发现,不平衡数据采样研究中过采样的研究较多。通过整理,将本文讨论的研究内容汇总如表2所示。
2 欠采样方法
解决数据不平衡问题,最简单的欠采样方法是随机欠采样[13]。它通过随机丢弃一部分负样本使正负样本达到平衡。但这种做法具有很大的缺陷,因为随机丢失了大量的负样本特征,随机欠采样不能大幅度地提升模型的正样本分类正确率。
欠采样主要分为两类:① 基于聚类的欠采样(clustering based under-sampling):通过对负样本进行聚类,并在每一个类中选取具有代表性特征的样本作为负样本训练集;② 通过整合的思想,将负样本分成很多份,利用每一份负样本和唯一一份正样本对多个分类器进行训练,最后对多个结果进行集成。
表2 典型采样方法及采样策略
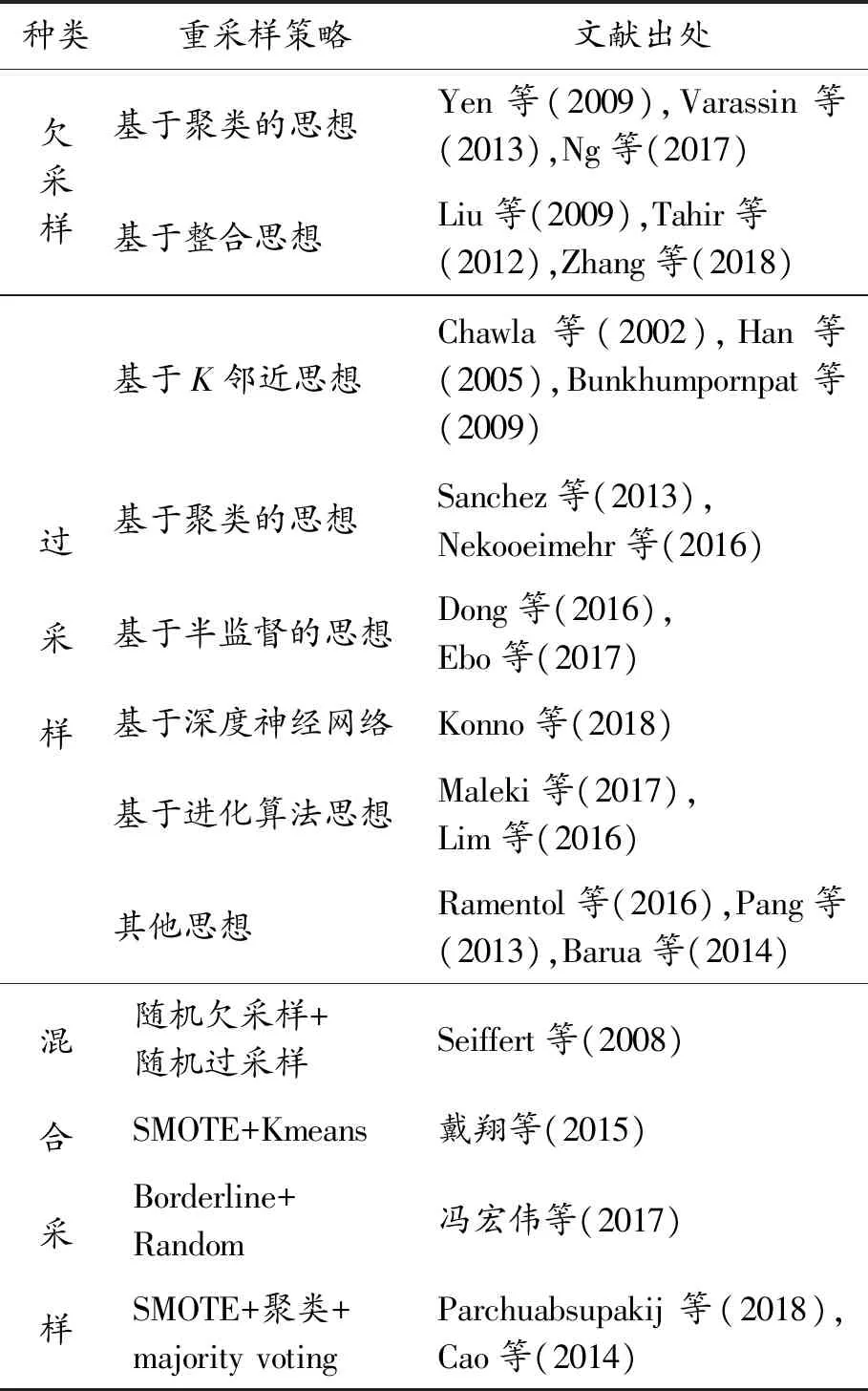
种类重采样策略文献出处欠采样基于聚类的思想Yen等(2009),Varassin等(2013),Ng等(2017)基于整合思想Liu等(2009),Tahir等(2012),Zhang等(2018)过采样基于K邻近思想Chawla等(2002),Han等(2005),Bunkhumpornpat等(2009)基于聚类的思想Sanchez等(2013),Nekooeimehr等(2016)基于半监督的思想Dong等(2016),Ebo等(2017)基于深度神经网络Konno等(2018)基于进化算法思想Maleki等(2017),Lim等(2016)其他思想Ramentol等(2016),Pang等(2013),Barua等(2014)混合采样随机欠采样+随机过采样Seiffert等(2008)SMOTE+Kmeans戴翔等(2015)Borderline+Random冯宏伟等(2017)SMOTE+聚类+majority votingParchuabsupakij等(2018),Cao等(2014)
2.1 基于聚类的欠采样方法
为了解决欠采样的随机性问题,Yen等[14-15]将负样本进行聚类,选取有代表性的样本作为训练集,以尽可能地提取具有代表性的负样本特征,减少负样本的特征丢失,优化训练效果,在提升对正样本识别率的同时减少负样本的错分率。虽然通过聚类使得训练集包含了更加全面的特征,但依然无法避免样本特征丢失的缺陷。Ng等[16]认为样本的分布信息有助于代表性样本的选取,通过对负样本进行聚类获取其分布信息,选取每一个类中具有代表性的样本,计算样本的敏感度,再根据敏感度选取k个负样本和k个正样本,将这2k个样本作为训练集。Varassin等[17]将欠采样的方法运用到DNA剪切位点的预测中,通过对负样本进行聚类,选取距聚类中心最近的样本作为代表性的负样本。
2.2 基于整合的欠采样方法
Liu等[18]针对欠采样提出了一种将负样本划分为多份的思想对模型进行训练,然后对结果进行集成,其基本思想为:随机将负样本分成和正样本数量相当的若干份,然后对每一份负样本和仅有的一份正样本进行训练,这样可以训练出若干个模型,再将每一个模型的分类结果进行集成得到最终结果。由于考虑了所有负样本的特征,所以应用这一方法可以有效地提升正样本与负样本的分类正确率,其算法流程如下所示:

算法1 简单集成欠采样算法输入:所有正样本P,所有负样本N,|p|<|N|,数据集个数T输出:分类预测结果1.选择合适的模型Xi,将N划分为T个子数据集{N1,N2,N3,…,NT};2.For i=1,2,3,…,T 利用P和Ni对模型Xi进行训练,得到结果Ri; EndFor3.将T个结果{R1,R2,R3,…,RT}进行集成,得到最终结果;
该方法考虑了所有负样本的特征,能够获得较高的正样本与负样本分类正确率,但是对于一些处于样本边界的数据,并不能有效地提升分类性能。因为在没有强化学习边界样本的情况下,分类器大概率会出现错分的情况。Zhang等[19]提出了一种反向随机欠采样的方法,其思想是将负样本分成比正样本少的若干份,将每一份负样本和正样本作为训练集,然后对多个结果进行集成得到最终结果。由于欠采样后每一个训练集中负样本比正样本少,所以称为反向欠采样。实验结果表明:反向欠采样具有一定的有效性与可靠性。Tahir等[20]针对上述问题提出了一种寻找正样本和负样本边界的欠采样方法。首先将负样本进行反向欠采样,产生若干个负样本少于正样本的训练集;然后寻找每一个训练集中正负样本的边界,将这些边界进行拟合,得到最终的样本边界,进而通过边界对样本进行分类。实验结果表明:此方法在二分类和多分类问题上均取得了较高的正样本分类正确率。
3 过采样方法
过采样方法主要指通过数学模型或者方法合成正样本。由于合成样本的方法是人为设定的,使得生成的正样本会包含一些原正样本不具有的特征,即噪声数据。该特征被分类器学习进而造成分类正确率下降。如何使生成的正样本具有丰富多样的正样本特征,且使得正样本均匀分布在样本空间是过采样方法研究的关键与核心[21]。已有过采样方法较多,不同方法具有各自的优缺点。最简单的过采样方法是随机过采样[22],其思想是随机复制正样本,单纯地使得正负样本比例达到相对平衡。虽然模型对正样本的分类正确率有一定的提高,但其最大的缺点在于生成的正样本与初始正样本一样,不具有多样性,并不能大幅度地提升正样本的分类正确率。
3.1 基于K邻近的过采样方法
为了解决随机过采样的局限性,提升样本的多样性,Chawla等[23]提出了SMOTE方法。SMOTE算法的主要过程如下所示:

算法2 基于K邻近的SMOTE过采样算法输入:原始样本数据集N,采样比率P输出:新的平衡数据集Nnew1.对于每一个正样本Xi,计算Xi到正样本集合N中所有样本的欧式距离,得到其K邻近;2.根据采样比率计算生成的正样本数量,从其K邻近中随机选择相应数量的邻近配对;3.对每个配对的样本(Xi,Xn)按照如下公式生成新的正样本,直到达到采样比率: Xnew=Xi+rand(0,1)∗|Xi-Xn|;
SMOTE方法是最具代表性的过采样方法,其基本思想是在每一个正样本和其K邻近的样本之间随机地生成一个新的样本。由于生成的样本是两个样本之间的随机值,所以该方法解决了样本多样性的问题。 Han等[24]分析了SMOTE方法的不足,提出了Borderline SMOTE方法,认为在正样本的边界区域样本容易被分类器错分,因而要强化边界区域数据的训练。算法思想:找到正样本的边界区域,对处于边界区域的正样本采用SMOTE方法进行样本生成。由于增加了边界样本的数据量,强化了边界样本的学习,正样本分类正确率相比SMOTE方法有一定的提升。但SMOTE和Borderline SMOTE方法均通过寻找K邻近生成样本,在选取K邻近样本时,均未考虑存在选取到负样本的情况。Bunkhumpornpat 等[25]提出了Self-Level-SMOTE方法,通过计算K邻近附近正样本的权重来生成正样本,避免了生成样本跨越正样本边界的问题。
3.2 基于聚类的过采样方法
基于聚类的过采样方法思想是:为了将具有相同特征的正样本聚在一起,在每一个类中通过样本生成的方法生成样本。由于对正样本进行了聚类,所以处于每一个类中的样本都会有新样本生成,避免了生成样本过于集中在某一个类中,使得生成的正样本能够均匀地分布在正样本的样本空间,提升了正样本分类正确率。Sanchez等[26]将正样本进行聚类,根据需要生成的样本数量在每一个类中单独进行过采样。由于聚类后在同一个类中的样本具有相似的属性,新生成的样本不会跨越类边界,同时减少了样本生成的盲目性,提升了采样的效果。Nekooeimehr等[27]利用层次聚类对正样本进行聚合,在每一个层内部进行过采样,并对边界样本进行识别,对处于边界的样本不进行过采样,避免了生成样本跨越边界的问题。
3.3 基于半监督学习的过采样方法
不平衡数据集中有一些数据集不平衡比例较大,正样本数量非常少,通过简单地样本生成不能有效地生成具有多样性的样本。Dong等[28]利用半监督的方法解决正样本过于稀少的问题,不断把新生成的样本合并到原来的样本中进行下一轮迭代,从而达到正负样本平衡。Ebo等[6]认为:无论是SMOTE方法,还是通过高斯分布或者基于特征生成的模型都是基于K邻近生成的,K邻近生成的新样本会跨越正样本的边界,如图2所示。
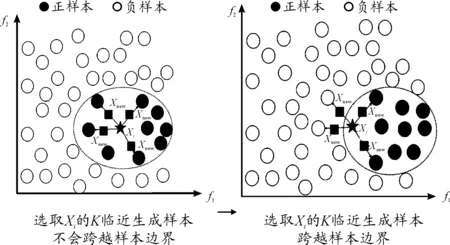
图2 基于K邻近(K=4)的样本生成示意图
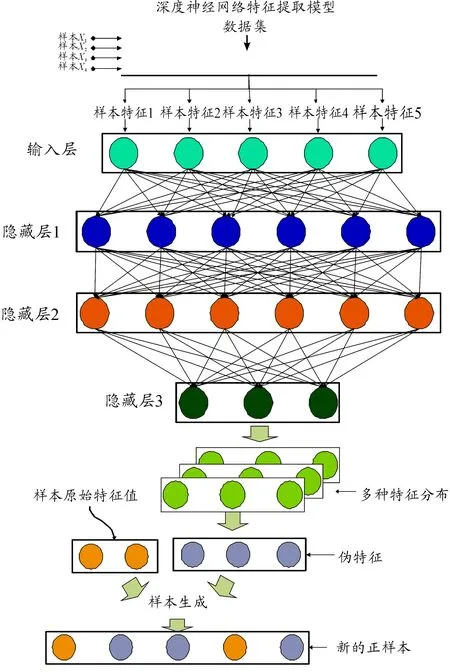
通过图2可以发现:正样本(用实心五角星表示)被选取时,基于K邻近方法生成的样本有部分跨越了样本边界(虚线以外)。Ebo等[6]提出了一种染色体遗传理论的过采样方法MAHAKIL,通过计算每一个正样本和正样本中心的马氏距离,按距离大小排序,将距离较大的一半和距离较小的一半分别作为父亲样本和母亲样本进行交配,生成新的样本,然后利用半监督的思想迭代生成需要的样本数量,具体过程如算法3所示。

算法3 基于多样性的MAHAKIL过采样算法输入:原始数据集N,生成比例P输出:和生成比例P相当的数据集1.将数据集N分成正样本Nmin和负样本Nmaj,获取正样本的个数NNmin和负样本的个数NNmaj;2.根据生成比例P得到样本生成后总的正样本数量NG=NNmaj∗P;3.while NNmin MAHAKIL方法按照半监督的原理生成样本,在增加样本多样性的同时不会降低样本的有效性。算法实现简单,生成的新样本在多数数据集上不会跨越样本边界,且生成的样本分布均匀,在计算成本、时间成本、采样效果方面均取得较好的效果。由于MAHAKIL方法按照距离样本中心的马氏距离进行聚类,导致该方法在数据小析取项[29-31]的问题上存在缺陷。小析取项又称为类内不平衡问题,是指正样本分布并不都在一个连续的样本空间,可能分布在两个或者多个不连续的样本空间,其结构如图3所示。 图3 正样本类内分布不平衡的情况(数据小析取项) Konno等[32]将深度神经网络技术应用于过采样中,其思想是:通过深度神经网络(DNN)提取正样本特征作为样本基本特征,在基本特征上加入一部分伪特征(pseudo feature)产生新的样本。该方法的特点在于伪特征的加入能增加样本的多样性。通过深度神经网络能够有效地提取样本特征,具有较好的普适性,但存在一些不足,例如:伪特征中仍会产生许多噪声,特征提取过程中会有部分样本特征丢失。算法思想如图4所示。 样本生成过程中减少噪声是影响过采样性能的关键因素之一。为了减少噪声,同时提升生成样本的多样性,学者们提出了一些基于进化算法的过采样方法[33-35]。进化算法的基本原理是通过选择、交叉、变异等操作在问题空间寻找最优解,其主要步骤包括:首先,选择合适的正样本分别作为父亲类和母亲类;然后,父亲类样本和母亲类样本进行交叉生成新的样本;最后,在新样本上进行变异操作,增加样本的多样性。当前较新的进化算法是Lim等[36]提出的基于进化理论的过采样算法ECO-Ensemble。该方法通过优化正样本中的类内和类间的样本生成比例,使得生成的样本具有多样性和均匀分布的特性。 图4 基于深度神经网络的过采样模型 目前,将过采样方法应用于机器学习技术的研究日益普及。Ramentol等[37]将模糊粗糙集的编辑技术应用于过采样中,取得了较好的正样本分类正确率。Pang等[38]利用不平衡时间序列和稀疏混合的高斯模型对正样本进行过采样,降低了过采样的随机性。Moreo等[39]认为要提取样本的分布特征,根据样本分布特征生成新的正样本,使生成的正样本具有合理的分布,其缺点在于:不同的数据具有不同的分布特征,基于特征分布来生成新样本的方法不具有普适性。Barua等[40]提出了一种根据样本权重生成新样本的过采样方法MWMOTE。首先,算法识别一些分类器比较难识别的正样本;然后计算这些正样本和最近负样本的欧式距离,根据距离大小赋予正样本相应的权重,依照权重对正样本进行聚类;最后在每一个类中应用SMOTE方法对样本进行过采样。该方法提升了比较难识别(权重较大)的样本的学习效果。为了解决数据不平衡的问题,已有研究虽然取得了一些进展,提升了不平衡数据分类正确率,但仍存在诸多不足,典型过采样研究方法简介如表3所示。 表3 典型过采样研究方法简介 过采样方法算法特点随机过采样平衡了正负样本训练集,产生的样本不具有多样性SMOTE过采样方法生成样本具有多样性、但生成样本有可能跨越边界Borderline SMOTE强化了边界样本的学习基于聚类的过采样方法生成样本更符合样本类内的分布基于深度神经网络特征提取的过采样方法具有很好的普适性,样本特征容易丢失,产生噪声较多基于半监督思想的过采样方法解决样本稀少问题,但新样本噪声较多基于样本分布特征的过采样方法样本生成效果好,不具有普适性基于进化理论的过采样方法样本生成效果好,实现困难,代价大 混合采样是将过采样方法与欠采样方法结合以达到平衡正负样本的采样方法,其主要从以下两个方面提升正样本与负样本分类正确率[41]:① 不会造成大量的负样本特征丢失,模型能学习到足够多的负样本特征;② 不会产生过多的噪声,模型学习到的噪声少。 为了验证混合采样的性能,Seiffert等[42]将随机过采样和随机欠采样技术结合,通过实验验证了混合采样技术能够显著提升决策树的正样本分类正确率。戴翔等[43]综合过采样与欠采样的优点,将SMOTE算法运用于少数类样本的生成,利用K-means聚类对负样本进行欠采样,提升了正样本与负样本的分类正确率。Li等[44]将混合采样技术运用于支持向量机SVM中,并利用K邻近方法对混合采样的结果做进一步约减,解决了数据混淆的问题,提高了支持向量机的泛化性能。Cervantes等[45]利用欠采样和支持向量机得到初始SVs和超平面,将这些实例作为遗传算法的初始种群。原始数据集包含生成和演化的数据,通过学习达到最小化不平衡数据的目的。该方法提高了支持向量机在不平衡数据集上的泛化能力。高锋等[46]提出一种基于邻域特征的混合采样技术,根据样本领域分布特征赋予采样权重,利用局部置信度的动态集成方法对不同的数据选择不同的分类器,并将不同分类器结果集成。实验结果表明,在查全率和查准率上该混合采样技术都有较大的提升。冯宏伟等[47]认为,位于边界区域的样本是最容易错分的样本,于是针对边界样本进行SMOTE过采样以强化边界样本的学习,然后针对负样本进行随机欠采样。该方法的正样本与负样本分类正确率较经典的采样方法有较大的提升。Gazzah等[48]提出的方法不是单纯地进行过采样和欠采样,进行过采样时重点考虑具有代表性的正样本,进行欠采样时丢弃相关性较小的负样本。Cao等[49]认为正负样本比例大时,单纯应用混合采样的效果不理想,将混合采样和集成的思想结合能够有效地提升模型正样本与负样本的分类正确率。基于集成的混合采样方法工作原理如图5所示。 算法基本思想:首先,将正样本进行一次过采样,并随机地将负样本欠采样成与正样本相当的若干份;然后,将每一份负样本和正样本进行混合,形成多个训练集,得到多个训练好的分类器;最后,将不同分类器的结果进行集成,得到最终结果。模型通过该方法能够充分学习负样本特征,是目前比较流行的混合采样方法[50-51]。 图5 基于集成的混合采样方法工作原理 不平衡数据分类问题是当前机器学习领域比较热门的研究内容,已经吸引越来越多学术界和工业界专家对其进行广泛和深入的研究。本文详述了不平衡分类问题中采样方法的研究现状和发展趋势,介绍了欠采样、过采样和混合采样3大类采样方法原理和典型算法。应用这些方法可以提高不平衡数据分类的正确率。 为了进一步研究更高效稳定的不平衡学习方法,未来可以从以下几个方面展开研究: 1) 在样本信息获取中,样本信息获取不完善是导致不平衡分类学习性能下降的最根本原因。对样本的物理、化学属性进行分析,以便多角度、多方位获取更多的样本属性,提升正负样本的区分度,达到提升不平衡分类学习性能的目的。 2) 在样本聚类中,通过单一的距离指标进行聚类不能全面地衡量样本间的距离,应结合多个距离指标进行聚类,并引入普适高效的聚类方法提升聚类效果。 3) 在过采样特征提取中,需要研究多层次的样本特征提取模型,强化样本特征的提取,生成噪声量少、多样性丰富的新样本,提升过采样的有效性。 4) 在强调边界的采样方法中,需要研究有效的边界寻找方法,结合多个评价指标对样本边界进行拟合,并对样本进行降噪处理,提升样本边界的有效性。 5) 基于进化算法的过采样中引入更多参数,优化生成样本的分布,提升生成样本的多样性与有效性。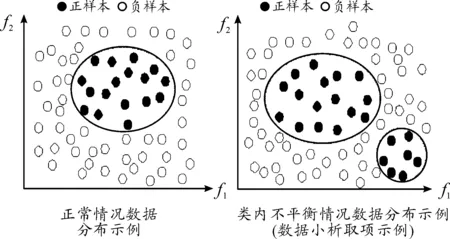
3.4 基于深度神经网络的过采样方法
3.5 基于进化算法的过采样方法
3.6 其他过采样方法

4 混合采样方法

5 结束语
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
中华养生保健(2020年7期)2020-11-16
现代装饰(2020年4期)2020-05-20
铁道通信信号(2019年6期)2019-10-08
证券法律评论(2018年0期)2018-08-31
雷达学报(2017年6期)2017-03-26
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
