
基于校园大数据的学生行为特征分析与预测方法
2019-08-17 07:40李铁波
重庆理工大学学报(自然科学) 2019年7期
李铁波
(吉林交通职业技术学院, 长春 130000)
随着信息技术的不断发展,校园中各项服务管理平台不断增加,使得积累的数据呈海量增长,包括学生消费规律、生活习惯以及学习情况等行为数据,已经形成了一个比较完整的校园大数据环境[1]。为实现校园数据的高效管理和共享,充分利用学生在校行为数据建设数字校园、智慧校园,使得校园信息化水平得以提升,需要采用数据挖掘方法优化学生管理,根据学生的行为特性分析其行为规律,及时指导学生行为向全面、健康方向发展。因此,对学生行为进行挖掘分析已成为学生管理的关键问题。文献[2]建立了学生校园行为分析预警系统,通过挖掘学生行为和心理问题,帮助管理者进行宏观决策,辅助教学安全管控;文献[3]对学生网络行为指标和成绩数据进行挖掘,采用线性支持向量机、梯度上升树和KNN等算法检验了学生学习能力对学习成绩的影响程度,并给出了需要对学生进行干预的阈值;文献[4]采用矩阵模式合并不同的数据,并采用Hadoop分布式处理平台提高大数据处理效率;文献[5]采用决策树、关联规则、逻辑回归3种数据挖掘方法对学生上网行为相关属性与学生学习质量之间的关系进行了研究,实现了较好的预期效果。
基于此,针对目前学生信息化管理过程中存在的问题,建立了基于校园大数据的学生行为分析与预测平台,围绕大数据环境下学生消费规律、生活习惯、学习情况等行为数据,利用决策树、神经网络以及朴素贝叶斯组合预测模型,分析学生行为特点和规律,对学生行为进行预测和预警,便于学校掌握学生生活与学习动态,及时做好引导,实现对学生的有效管理。
1 数据挖掘理论
1.1 数据挖掘流程
数据挖掘指在海量数据中提取隐含的具有潜在利用价值的信息,并通过分析为人们提供决策作用的过程。数据挖掘是一个不断往复优化的过程,主要包括数据预处理、数据挖掘以及模型评估,其流程如图1所示。数据预处理是将杂乱的、不符合规则的数据进行清洗和筛选,为数据挖掘提供数据基础;数据挖掘是在处理好的数据中提取有用信息的过程,是数据挖掘的核心环节;最后要对模型进行评估,以检测结果是否达到预期要求[6]。

图1 数据挖掘流程
1.2 数据挖掘算法
对已有的信息进行数据挖掘分类分析,可以得到预测模型。不同的模型,所用算法也各不相同,随着研究的不断深入,各种算法不断被完善和优化。根据研究内容,现只对决策树、神经网络以及朴素贝叶斯算法进行分析对比。
1) 决策树分类方法、
决策树是一种基于信息增益理论的预测模型,代表对象属性与对象值之间的一种映射关系,是目前应用最广泛的数据分类算法之一。决策树是一种树形结构,包含了若干个节点和分支,分别代表某个属性上的测试和测试输出。决策树分类精度高,易于理解和实现,但不适合类别较多的数据结构。常见的决策树算法有ID3、C4.5/C5.0等[7],主要用于事件的预测分析,预测过程通常分两步:一是构建决策树,由训练样本进化而成;二是决策树的剪技。对决策树进行检验、校正,测试各节点的属性值,对输入数据进行分类,然后用该类的属性值完成预测对象的估计。例如预测用户是否具有偿还贷款的能力,可用图2表示。
2) 神经网络分类方法
神经网络以海量数据并行处理和计算为基础,具有自学习和高速寻找优化解的能力,通常用作数据分类、聚类及预测。BP神经网络是一种按误差逆传播算法训练的多层前馈网络,能学习和存贮大量的输入和输出映射关系,是目前应用最广泛的神经网络模型之一,其表达式为[8]:
H=fj(∑wijxi+θj)
(1)
式中:wij为网络权重;θj为神经网络阈值;fj为激励函数;xi为网络的输入。
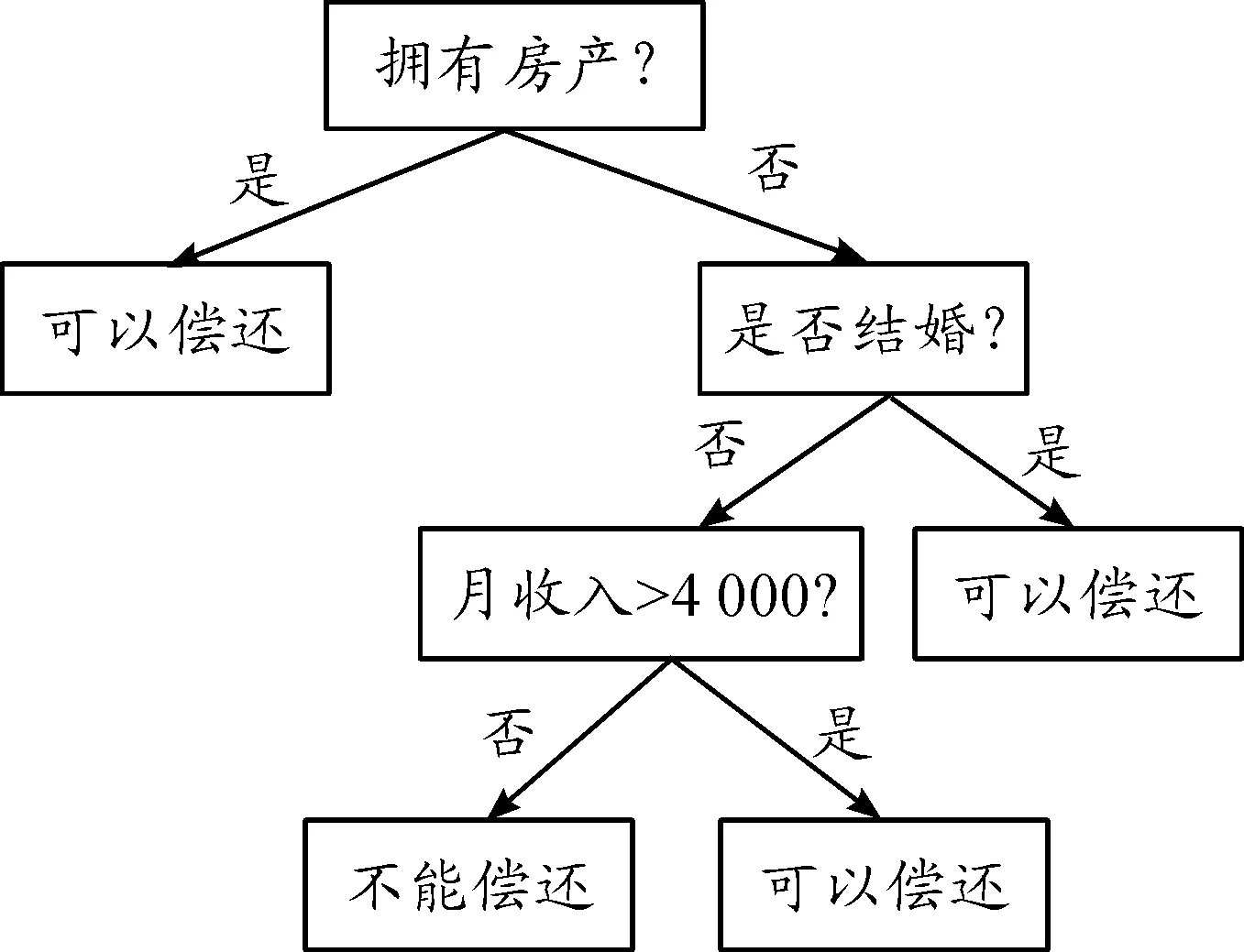
图2 决策树结构模型
神经网络的学习和记忆具有不稳定性,为完成对复杂非线性映射功能, BP神经网络采用有师学习方式进行训练,如图3所示,训练中以误差最小为原则,逐层修正各阈值和权重系数。

图3 BP神经网络训练过程
3) 朴素贝叶斯(NB)分类算法
朴素贝叶斯是一种简单的概率分类算法,是求解每个待分类实例在各个类别中的后验概率。设X表示属性集,包含d个属性,Y表示类变量,P(Y|X)为Y的后验概率,P(X|Y)表示类别Y的条件概率,P(Y)称为先验概率。现有一类别的标号为y,以特征属性间的相互独立为前提,类条件概率可表示为:
(2)
由此可推导出朴素贝叶斯公式[9]:
(3)
算法流程如下:
① 设x=(a1,a2,…,an)为待分类样本,aj=(j=1,2…,n)为样本各属性取值;
② 选取训练样本,用n维向量X表示数据样本,类标签集合为C=(c1,c2,…,cm);
③ 计算各属性在给定类标记下的条件概率;
④ 确定后验概率的大小;
⑤ 预测属性集所属类别。
1.3 基于多算法组合的数据挖掘模型
针对上述分类算法的特点,将决策树、神经网络以及朴素贝叶斯3种分类算法进行结合,构建组合预测模型。现构造Lagrange函数[10]如下:
(α1xi+α2yi+α3zi-yi)2+
(α1xi+α2yi+α3zi-zi)2+
λ(α1xi+α2yi+α3zi-1)
(4)
式中:xi,yi,zi分别为3种模型的预测值;αk为模型的权重系数,k=1,2,3;λ为Lagrange函数算子。变换后得到:
(5)

组合模型的预测流程为:
① 划分数据集,其中训练集样本占60%,测试集样本占40%;
② 分别选用3种分类算法对训练集进行建模;
③ 在单一模型中对测试集中的样本数据进行预测,得到预测结果;
④ 将步骤3中的预测结果代入式(4),计算权重系数,建立组合预测模型;
⑤ 根据式(5)得出组合预测结果,具体流程如图4所示。

图4 组合模型预测流程
2 基于校园大数据的学生行为特征分析与预测平台
2.1 平台架构与流程
Spark是专为大规模数据处理而设计的快速通用的计算引擎,能更好地适用于数据挖掘与机器学习等需要迭代的算法[11-12]。针对上述问题,建立了基于Spark的学生行为分析与预测平台,为提高数据处理效率,平台采用分布式并行计算框架,如图5所示。
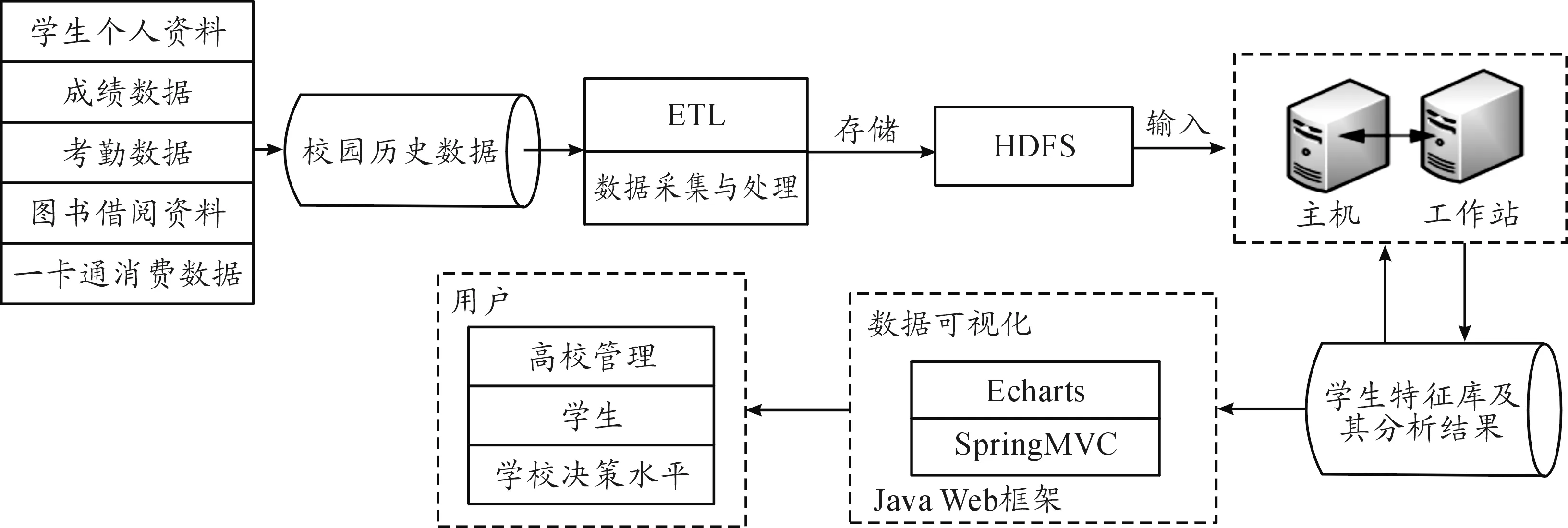
图5 平台架构与流程
平台以校园各管理平台中学生的消费、考勤、成绩以及图书借阅等数据作为数据来源。首先,将经过预处理后的学生数据存储到分布式系统 HDFS中,为确保数据转换方便,以及数据与关系型数据库中数据类型保持一致;其次,将数据进行聚类分析,关联规则挖掘,完成对学生行为分类、行为分析等工作,从而通过分析学生行为特征,预测学生生活规律和习惯。
2.2 学生行为数据处理
预处理是整个数据挖掘过程中关键的步骤,包括对数据的采集、过滤、分析以及特征提取等几个过程。其中数据采集是为了获取学生行为数据,通过校园“一卡通”等各管理平台获得;采集后的数据往往杂乱无章,需要进行清洗过滤,以去除重复数据、异常值和缺失值,为数据挖掘提供良好的数据基础;数据分析是对过滤后的数据进行进一步认识和管理;特征提取是将原始数据进行变换,以此降低数据挖掘的复杂度,获得准确、有效的数据挖掘结果。通过分析数据可用性以及评价学生在校行为的指标,构建学生行为特征库,如图6所示。

图6 学生在校行为特征指标
1) 消费规律
对学生在学校的消费行为进行分析,提取包括学生消费习惯、月平均消费额、学期消费额、单笔最高消费以及消费频次等在校消费记录作为数据特征来源,从而找出学生的消费规律和消费水平。
2) 学习情况
为了分析学生的努力程度和学习成绩,以课堂考勤率、图书阅读量、学习时长、学习习惯以及课程通过率等作为数据特征来源进行分析,从而了解学生平时的学习情况,掌握学习动态。
3) 生活习惯
为了对学生的生活习惯进行有效评价,将学生的作息时间、身体锻炼情况、上网时间以及活动地点等作为评价指标,对采集的数据进行分析,从而了解学生平时的生活习惯规律。
2.3 行为结果分析
采用吉林交通职业技术学院数字化校园“一卡通”记录以及各部门管理系统中的数据作为数据来源,包括10 000名在校学生从2016年10月到2018年10月的学生校园消费记录、图书馆借阅与自习记录、校园网络访问记录、课堂学习与成绩记录以及体育锻炼记录数据等。首先,通过Sqoop工具将数据进行转换后导入到HDFS 中并完成对数据清洗等预处理;其次,对准备好的数据进行分析,建立学生行为特征库;最后,利用特征库中的各项指标为学校提供管理学生的决策。由于篇幅有限,这里只对与学生学习有关的数据进行处理,以分析学生的努力程度。在Spark 平台上依据努力程度可将学生划分为8组,分析得到学生各指标的平均值如表1所示。
由表1可见:第2、3及6组的大部分学生学习比较刻苦,学习成绩也比较高,占总人数的54.47%。只有少数的学生努力程度不够,成绩较差,占总人数的5.04%。其余部分的学生虽然成绩合格,但努力程度还不够,如果加以督促成绩会有更大进步。分析结果与真实情况基本一致,表明用所提出的方法进行学生行为分析合理有效。
3 基于校园大数据的学生行为特征预测实例
采用所构建的组合预测模型对学生行为进行分析预测,通过平均相对误差反映学生行为特征预测结果与真实值之间的关系,并与单一预测方法进行对比。测试数据规模分别为200、500、1 000、2 000、5 000以及 10 000 名学生。预测平均相对误差如图7所示,学生典型行为特征指标的平均相对误差如图8所示。
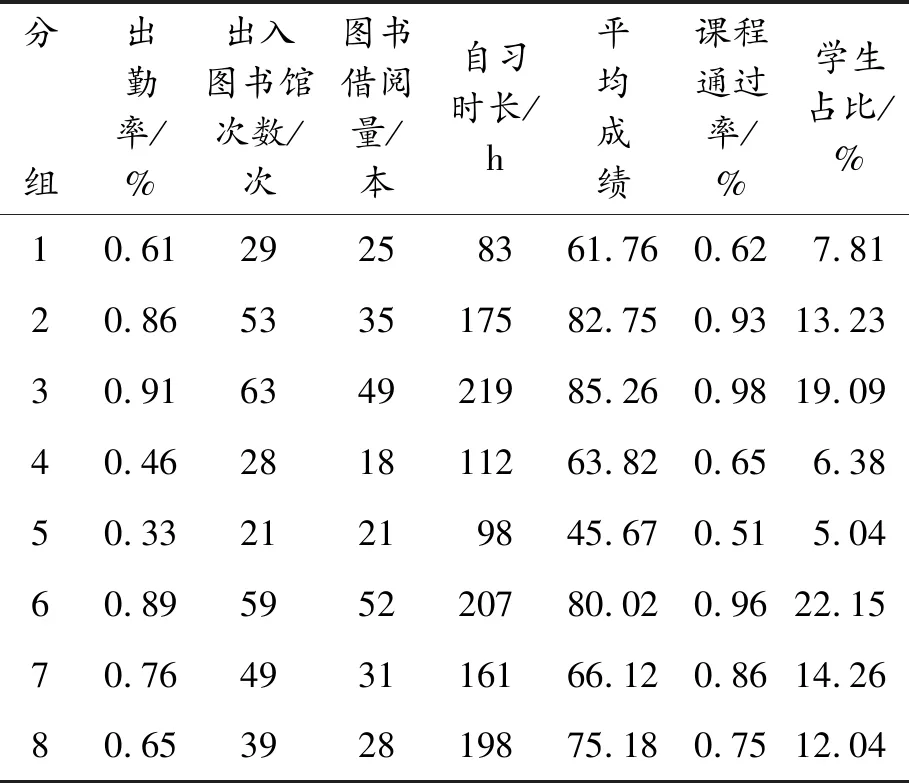
表1 学生努力程度分析结果
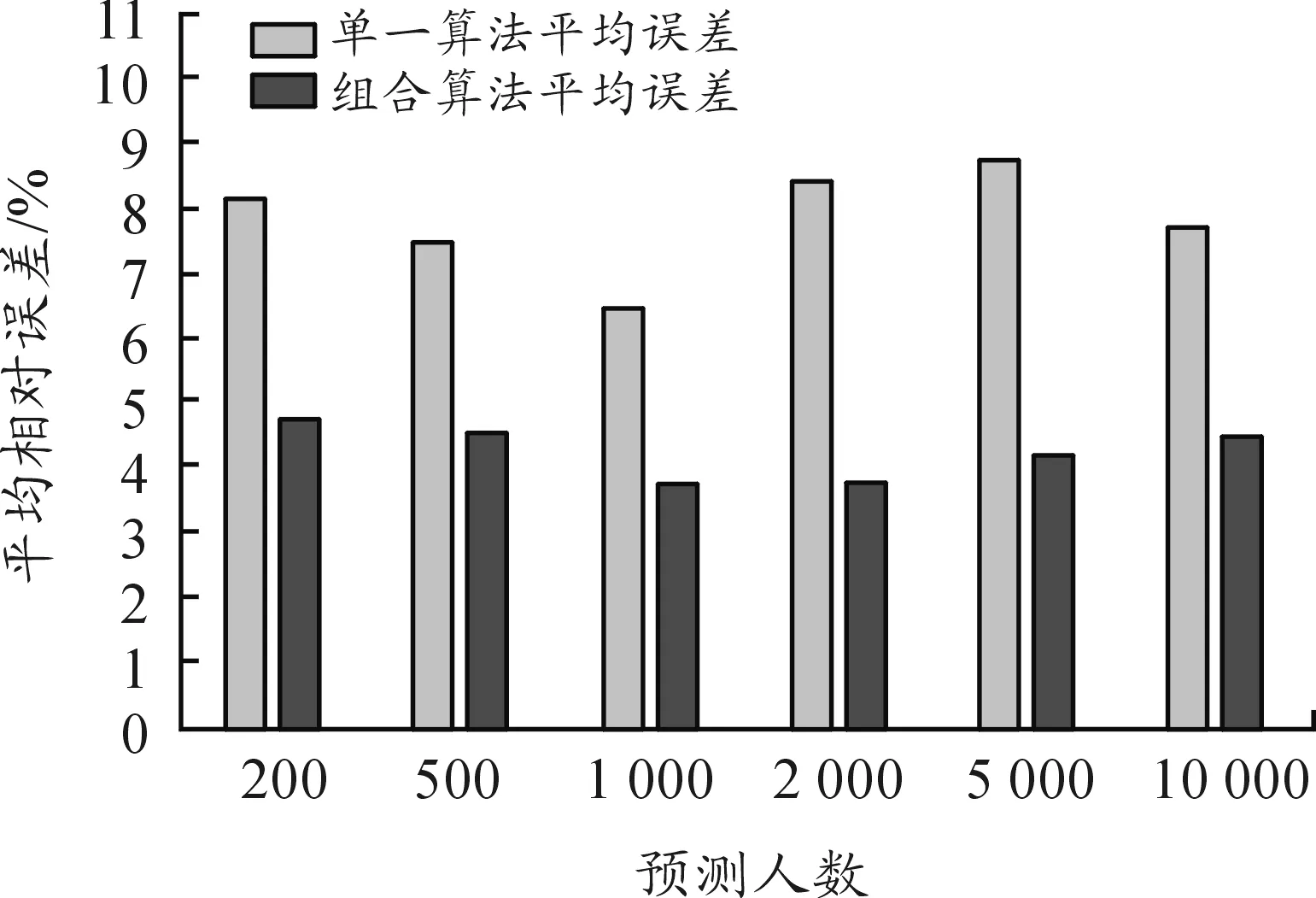
图7 预测平均相对误差

图8 学生行为各指标平均相对误差
可见,与传统预测方法相比,本文提出的基于多算法组合的学生行为预测模型预测精度较高,平均相对误差不超过5%,具有很好的预测效果。随着预测学生人数的增加,平均相对误差变化不大,预测精度基本保持稳定,从而表明此预测模型的可扩展性较高。各个学生行为特征指标上的相对误差分布比较均匀,说明在各维度的学生行为特征上的平均相对误差都比较小,适合多维学生行为的预测。
4 结论
1) 探讨了数据挖掘相关理论,对典型数据挖掘算法进行分析,为提出新的预测模型提供基础。
2) 利用学生校园行为数据,构建基于Spark的学生行为分析和预测平台,建立了以消费规律、生活习惯以及学习情况等在校行为为指标的评价体系,从而建立能够描述学生个人行为的特征库,分析表明,所建平台可有效预测学生在校行为,预测结果与实际情况相吻合。
3) 利用决策树、神经网络以及朴素贝叶斯算法建立组合预测模型,对典型的学生行为作为实例进行预测。预测结果表明:与传统预测方法相比,所建组合模型预测精度高,可扩展性好,平均误差不超过5%,学校可以根据学生的行为特性分析掌握学生生活与学习动态,以及时发现问题,有效预警。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
重型机械(2016年1期)2016-03-01
智能系统学报(2015年4期)2015-12-27
郑州大学学报(医学版)(2015年1期)2015-02-27
海军航空大学学报(2015年4期)2015-02-27
