
基于深度卷积对抗生成网络的人脸图像生成
2019-08-21 03:50陆萍董虎胜
现代计算机 2019年21期
陆萍,董虎胜
(苏州经贸职业技术学院,苏州215009)
0 引言
使用计算机自动生成具有真实视觉效果的图像近年来逐渐成为了计算机视觉领域中一个新的研究热点。随着深度学习模型在计算机视觉领域中的应用日益广泛,基于深度模型的自动图像合成受到了越来越多的关注。通过使用深度模型强大的学习能力,可以有效地挖掘数据中的内在分布规律,从而生成具有类似分布的图像。这些生成的图像能够应用于图像的自动合成、不同年龄段的人脸图像预测、获得艺术效果图片等不同的场景中。另外,高质量的生成图像还可以用来扩充数据集中的图像数据量,在一定程度上缓解深度学习模型训练时的大量训练样本需求。
当前在图像的自动生成研究中,主要都是采用了基于对抗生成网络(Generative Adversarial Net,GAN)的思想,通过判别器(Discriminator)与生成器(Generator)的博弈达到平衡,捕捉数据的内在分布。在分别使用深度卷积网络(Deep Convolutional Neural Network)和深度反卷积网络(Deep Transpose Convolutional Neural Network)作为GAN 模型中的判别器与生成器时,即获得了深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN)。本文基于DCGAN创建了图像的生成模型,并在CelebA 数据集上进行了测试,实验结果表明该模型具有良好的图像生成效果。
1 GAN模型结构
在GAN 模型中包含了两个最基本的模型,一个是生成器G,另一个是判别器D,通过这两个基本模型的相互博弈来实现学习数据内在分布的目标。生成器G不断地学习训练集中真实数据的概率分布,将输入的随机噪声数据转化为可以以假乱真的样本;这些生成的样本与训练集中的“真”样本一同被送入判别器D中,它们的标签分别被标注为0 与1。判别器D 的任务就是试图将这两类样本成功地分类开来,即区分样本是由生成器生成的造假数据,还是取自于真实训练集。在GAN 模型的学习过程中,生成器G 在没有先验知识与先验分布的前提下努力地使生成的更接近于真样本的数据;而判别器D 则努力地试图区分它们,所以两者就形成了博弈关系。在两者的迭代优化过程中,生成器与判别器的性能都将不断提升。当生成器生成的数据达到了以假乱真的效果时,判别器的分类准确率将趋于50%,也就是当无法区分生成的样本与真实样本时,模型就达到了某种Nash 平衡。此时可以认为生成器G 成功地学习到了数据内在的分布,可以由其生成接近于真实样本的数据。
设由生成器G 生成样本为G(z;θg),其中z 为随机噪声,服从的分布为pz(z);来自训练集中的真实训练样本的概率分布为pdata;判别器D 对样本x 的分类概念为D(x),GAN 模型的优化目标可以表达为式(1)所示的形式:

从式(1)可知GAN 模型本质上是一个min-max 的博弈问题,在优化该模型时可以采用交替优化的方式来获得生成器G 与判别器D 的模型参数。图1 给出了GAN 模型的结构图。

图1 GAN模型结构
2 DCGAN模型
在GAN 模型中并未对判别器D 与生成器D 的模型结构作出具体的定义与要求。当使用深度卷积神经网络作为GAN 的判别器,使用深度反卷积网络作为生成器时,就形成了深度卷积生成对抗网络DCGAN 模型。使用这样的模型结构可以由1 维的随机噪声出发来生成二维图像数据,因此可以利用它来获得图像数据的内在分布,生成具有比较真实显示效果的图像。
在使用CNN 卷积神经网络模型来实现对图像的分类时需要不断地经过多层卷积-池化结构进行卷积与下采样运算,但是在生成器从随机噪声中生成图像的逆处理过程中无法直接进行上采样运算,此时可以通过反卷积运算来此目标。图2 给出了一个具体的反卷积运算示例,从图中可知该运算将卷积运算与上采样运算合并成了一体,在运算中首先需要对输入图像进行填0 扩充操作,然后使用卷积核对其进行卷积运算,最后需要将获得的卷积结果裁剪即获得输出结果。
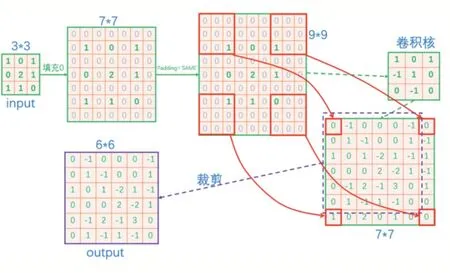
图2 反卷积运算示例
在DCGAN 模型为了简化运算,判别器与生成器具有着类似逆过程的运算流程。由于反卷积运算中没有上采样运算,在判别器的CNN 结构中也相应地取消了池化操作,为了实现对卷积后获得的特征图(feature map)的下采样,可以在卷积运算中修改卷积核的移动步长(stride)。为了加快判别器与生成器的收敛,在每次卷积/反卷积运算后需要作批归一化(Batch Normalization,BN)处理。在生成器G 中,由于最后一层需要生成图像,而图像的像素值一般在0~255 之间,可以使用tanh 函数将结果映射到-1~1 之间,在加上1 与乘127.5 后即可映射到需要的值区间内。另外,在判别器D 中一般使用Leaky ReLU 激活函数,在G 中除最后一层使用tanh 外,其余各层使用的是ReLU 激活函数。
3 本文图像生成模型
根据对DCGAN 模型的分析,本文设计了如表1 所示的DCGAN 中生成器G 的模型结构。表中→指代了运算顺序,n2@k×k×n1指代了当前层中的反卷积核设置,如512@5×5×1024 表明当前反卷积运算中使用的卷积核为5×5×1024,输出为512 个特征图;strides 指出了在反卷积运算中的移动步长。在表1 的G 的结构中第1 层为全连接层接收100 维的随机噪声信号向量,与权重矩阵相乘后变形(reshape)为[4,4,1024]的三维张量;其余各层均为反卷积运算层,在作反卷积运算中使用了2×2 的移动步长与ReLU 激活函数;在最后一个反卷积层中使用了tanh 激活函数以方便生成3 通道图像。

表1 本文DCGAN 模型中生成器G 的结构
本文使用的判别器模型D 的结构与生成器D 基本上呈逆向运算关系,其具体结构如表2 所示。在判别器中接收64×64 像素大小的3 通道图像,经过多次卷积运算后获得4×4×512 大小的特征图,在将其变形为8192 维的向量后映射为1 个标量值,并使用Sigmoid交叉熵函数来确定判别器的损失函数值。在该判别器模型中使用了2×2 的卷积核移动步长代替池化(pooling)运算,另外使用的激活函数均为Leaky ReLU。

表2 本文DCGAN 模型中判别器D 的结构
4 实验
本文在香港中文大学开放的CelebA 数据集上进行了模型的训练与测试。该数据集收集了10177 个名人身份的202599 张图片,每张图都作好了特征标记,为与人脸相关的模型训练提供了便利。本文从该数据集中选取了如图3(a)所示的采集自演员Nicholas Cage的所有图片作为训练样本对设计的图像生成模型进行了训练。实验中使用的环境为TensorFlow 1.12,设置的迭代次数为5000 次。实验硬件条件为Intel Core i7@6700 CPU,NVIDIA GTX 1080 8G 显示卡,32G RAM。最终获得的随epoch 迭代变化的生成图像如图3(b)~(d)所示。从图中可以发现随着迭代次数的增加,生成图像的显示质量不断提升,最终获得的图像已经具有比较高的显示质量。

图3 实验中使用的训练图像示例与生成的图像
5 结语
本文对生成对抗网络GAN 模型及深度卷积对抗生成网络DCGAN 模型进行了研究,并基于TensorFlow深度学习框架设计了图像生成模型。实验中使用了CelebA 数据集中的图像进行了模型的训练,训练后的模型具有比较好的人脸图像生成效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
学苑创造·B版(2019年4期)2019-05-09
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
数学学习与研究(2017年3期)2017-03-09
