
基于N-Gram和动态滑动窗口的改进余弦相似度算法研究
2019-08-27 09:19钟凯迪谭锦涛叶文韬
成都大学学报(自然科学版) 2019年2期
张 洪, 钟凯迪, 柴 源, 魏 济, 吴 艳, 谭锦涛, 叶文韬
(1.成都大学 信息科学与工程学院, 四川 成都 610106;2.成都大学 模式识别与智能信息处理四川省高校重点实验室, 四川 成都 610106)
0 引 言
随着“大数据”时代的兴起,由于大量的数据往往包含着许多重复与相似的部分,分析这类数据所得的结果总与实际偏差较大[1].随着信息技术的发展,科研人员针对数据清洗技术方面的研究已经取得了一定的成果[2].目前,数据清洗主要针对英文或数值型数据,而对于中文文本数据清洗方面的相关研究基本还是空白.所以,研究和发展基于中文的数据清洗技术具有重要的现实意义.研究表明,余弦相似度算法通过计算文本中2个向量的夹角余弦值来表示其统计学方法中的相似程度,其余弦相似度值越大表示文本之间的相似度越大[3].当面对大量的文本数据情况下,余弦相似度算法常被用来计算单文本对应的其他各文本之间的余弦相似度值,通过制定相应的阈值来给重复与相似的文本分类.但该算法的计算步骤随着数据量的增加而呈几何级增长,且十分冗杂[4].N-Gram算法是针对英文与数值的概率计算,通过计算文本中每个词出现的概率计算出文本的概率,将其作为文本属性值[5].事实上,文本之间的属性值越相近,则表示文本之间的数据相似度越高[6].为了提高余弦相似度算法在海量数据中的计算速度以及减少因数据量增加而产生的误差,本研究提出基于N-Gram的余弦相似度改进算法[7],并对改进后的算法制定出一种合理的动态滑动窗口进行重复或相似检验.同时,通过对国家工商行政管理总局商标评审委员会网站获取的数据进行算法测试,结果表明,基于N-Gram的余弦相似度改进算法结合动态滑动窗口策略具有更快的运行速度,且在数据量增加的情形下误差也较小.
1 算法与改进
1.1 N-Gram算法
N-Gram算法认为:某条数据出现的概率与数据中包含的各个词有着密切关系,因此可以用数据中每个词出现的概率来描述该条数据出现的概率,且该条数据出现的概率即为其N-Gram值.当2个数据的N-Gram值越相近,则表示其相似程度越高.N-Gram算法的具体步骤如下:
1)对目标数据进行预处理,删除其中的特殊字符与标点符号,并对数据进行分词处理.
例如,待处理的数据有下列几种:
S1=我刚刚去Starbucks买了1杯Vanilla Latta和4块Oatmeal Raisin Cookie.搭配起来还挺不错的.
S2=Tom Robyn,对刚刚发生的事情感到很意外.
S3=Many people argue that living in the city has more advantages.
对这些数据预处理后的结果为(词与词之间用空格隔开):
S1=我 刚刚 去Starbucks买了 1杯 Vanilla Latta 和 4块Oatmeal Raisin Cookie 搭配 起来 还 挺不错 的
S2=Tom Robyn 对 刚刚 发生的 事情 感到 很意外
S3=Many people argue that living in the city has more advantages
2)对所有数据进行处理后,扫描所有数据的词,建立语料库,记录每个词出现的次数,记为N.
3)处理后的某条数据进行N元分割处理,即取出该条数据的具有N个词的子字符串.当N=2时,处理后的数据如下所示:
S1={“我 刚刚",“刚刚 去",“去 Starbucks",“Starbucks 买了",“买了 1杯",“1杯 Vanilla",“Vanilla Latta",“Latta 和",“和 4块",“4块 Oatmeal",“Oatmeal Raisin",“Raisin Cookie",“Cookie 搭配",“搭配 起来",“起来 还",“还 挺不错",“挺不错 的"}
S2={“Tom Robyn",“Robyn对",“对 刚刚",“刚刚 发生的",“发生的 事情",“事情 感到",“感到 很意外"}
S3={“Many people",“people argue",“argue that",“that living",“living in",“in the",“the city",“city has",“has more",“more advantages"}
4)各条数据出现的概率与数据中的词密切相关,而数据中某词出现的概率与其前面的词息息相关.利用马尔科夫概率计算公式,
P(S)=P(c1c2c3…cn)
=P(c1)P(c2|c1)P(c3|c2c1)…P(cn|cn-1cn-2…c1)
(1)
其中,P(S)为整条数据出现的概率,而c为对应的词.显然可见,当数据的词量越大时,cn-1cn-2…c1等计算量越大,模型也更加冗杂.
对此,马尔可夫提出了简化的计算方法,假设该条数据中某个词的出现概率仅与前一个词有关,则式(1)可简化为,
P(S)≈P(c1)P(c2|c1)P(c3|c2)…P(cn|cn-1)
(2)
实际计算式为,

(3)
其中,N(c)为词c出现的次数.
5)通过以上计算出的数据出现概率即为该条数据的N-Gram值,也可看成是该条数据的属性.
通过计算每条数据的N-Gram值,并对所有数据进行排序,利用滑动窗口等方法,对数据进行比较或求阈值,就能找出数据中重复与相似的部分.
1.2 余弦相似度算法
余弦相似度用空间中2个向量的余弦值来表示它们之间的相似程度:当余弦值越接近1时,2个向量之间的夹角值越接近0°,则2个向量的相似程度就越大.相反,当余弦值越接近0时,2个向量的夹角越接近90°,其相似度就越小.余弦相似度算法本身的特点导致其更适合处理较少量的数据,而面对大量数据的情形时,往往会导致计算缓慢且冗杂.
1.3 改进余弦相似度算法
相似度算法在数据量较大的情况下进行数据挖掘,往往需要进行重复与相似数据的清洗.本研究通过N-Gram算法的排序思路改进余弦相似度算法,并采用动态滑动窗口对重复与相似记录进行清洗,其数据清洗流程图如图1所示.
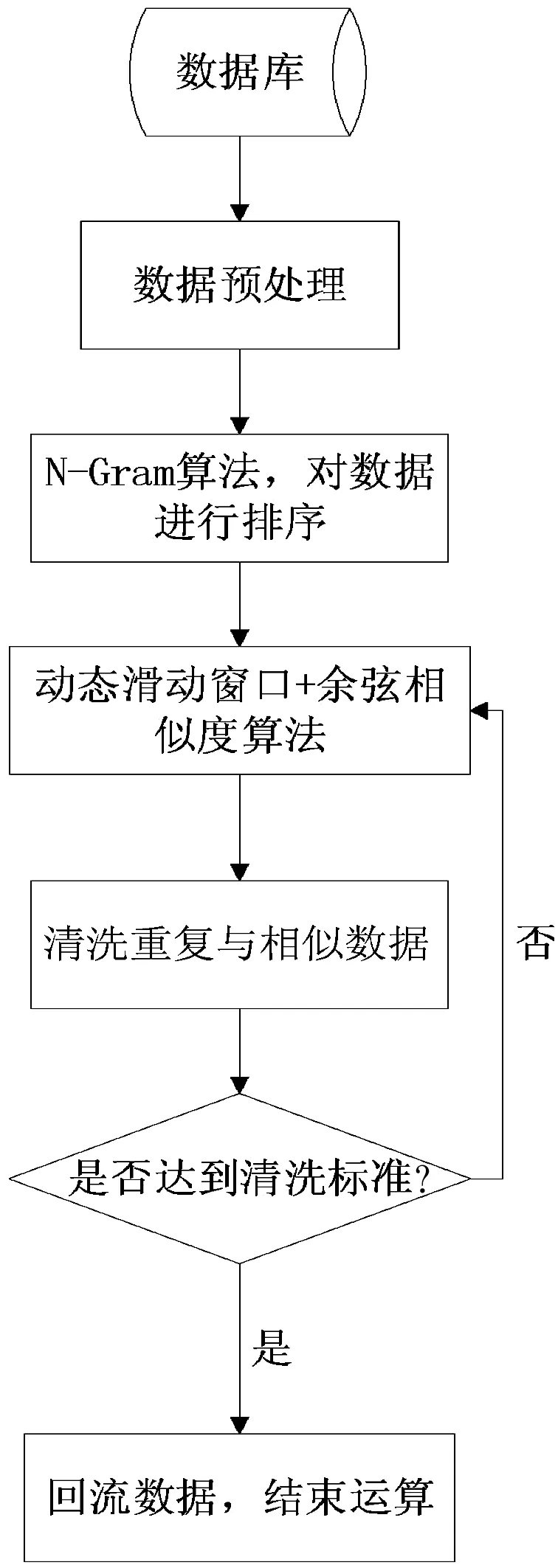
图1重复与相似数据清洗流程图
改进余弦相似度算法首先对清洗的数据进行预处理,即去掉标点符号与特色字符,并进行分词操作.本研究采用Python的jieba库进行精确分词,分词主要有两种模式:在不存在冗余的情形下把文本精准切分的精确模式;把文本中所有可能的词语都扫描出来的全模式.分词后,本研究再通过N-Gram算法计算出每条数据的N-Gram值,对数据进行排序处理.
同时,算法还采用动态滑动窗口对数据进行分组:当某窗口的N-Gram值相对差别较小时,则增加该窗口的大小来提高计算的准确性;而当窗口的N-Gram值相对差别较大时,则减小该窗口的大小来提高运算的速率.
Wi表示第i个窗口的大小,通过窗口中数据的离散程度来改变窗口的大小.Si表示窗口中的N-Gram值的方差,则动态滑动窗口大小为,
(4)
其中,n为窗口的动态变化量.
在本研究中,窗口变化有以下情形:
1)窗口大小向窗口中第一条数据往上变化,若运行至总数据开端处,则停止变化.此种方式能更全面处理重复与相似数据.
2)窗口大小向窗口最后一条数据往下变化,若运行至总数据的最后一条,则固定窗口大小且停止移动.此种方式能使运算过程更加快捷.
在研究中,采用余弦相似度算法计算滑动窗口中重复与相似的数据,对滑动窗口中的数据进行预处理,得到分词的数据,选取窗口中的2条数据,扫描此2条数据的所有词汇,制定出该次计算的语料库.根据语料库,本研究计算出2条数据的词频向量,并根据词频向量得出其余弦相似度值,如式(5)所示,
(5)
当余弦值大于规定的其阈值时,即判定此2个数据为重复与相似的.例如,2条数据进行预处理后的结果如下所示:
S1={“当",“1个",“量",“在",“1个",“既定的",“时间",“周期",“中",“其",“百分比",“增长",“是",“1个",“常量",“时",“这个",“量",“就",“显示",“出",“指数",“增长"}
S2={“当",“1个",“量",“在",“1个",“既定的",“周期",“中",“呈现",“出",“指数",“增长",“其",“百分比",“增长",“是",“1个",“常量"}
本研究计算每个词出现的次数,构成对应的字典,即为语料库:
Corpus={‘当':2,‘1个':6,‘量':3,‘在':2,‘既定的':2,‘时间':1,‘周期':2,‘中': 2,‘其':2,‘百分比':2,‘增长':4,‘是':2,‘常量':2,‘时':1,‘这个':1,‘就':1,‘显示':1,‘出':2,‘指数':2,‘呈现':1}
通过语料库得到对应的词频向量:
D1=[1,3,2,1,1,1,1,1,1,1,2,1,1,1,1,1,1,1,1,0]
D2=[1,3,1,1,1,0,1,1,1,1,2,1,1,0,0,0,0,1,1,1]
其余弦相似度为:
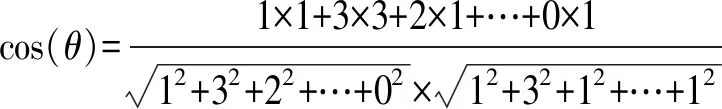
=0.8876
根据余弦相似度便可确定S1与S2为相似度极大的数据.
2 结果及分析
在算法测试中,本研究根据上述算法,设计出对重复与相似数据清洗的实验,并通过比较余弦算法、N-Gram算法及改进余弦算法的运行速度和准确率对实验结果进行了分析和解读.
1)通过获取国家工商行政管理总局商标评审委员会网站的数据并存入SQL数据库中,具体数据如图2所示(因篇幅有限,SQL数据库中仅列出部分数据).

图2部分实验数据表格
2)准确率能较好地展示算法的可行性与可用性,是评价算法好坏的重要指标,其计算式为,正确识别的重复相似数据/(错误识别的重复相似数据+正确识别的重复相似数据).
3)实验采用jieba库的精准分词,初始动态移动窗口大小为5,动态变化量选取3,且以窗口末端进行变化,改进余弦相似度算法设定0.8为重复相似数据阈值,并以每百条数据为1个记录点.数据清洗一次得到的实验结果如图3所示.

图3数据清洗准确率图
由图3可知,改进余弦相似度算法准确率明显高于N-Gram算法,且随着数据量的增加,其准确率也更加接近余弦相似度算法.
运行时间是评价算法实用性与复杂度的重要指标.数据量算法运行时间的变化如图4所示.

图4数据运行时间图
由图4可知,改进余弦相似度算法较余弦相似度算法更快地区分出重复与相似数据,且在数据量增加的情况下,其运行时间接近于运行较快的N-Gram算法.因此,改进余弦相似度算法拥有更好的实用性与较小的复杂度.
3 结 语
本研究通过对SQL数据库(国家工商行政管理总局商标评审委员会网站)的数据进行测试.结果表明,改进余弦相似度算法在数据量越多的情况下拥有更高的准确率,相对于未改进的余弦相似度算法有着更低的运行时间,且在清洗大量重复与相似数据的过程中拥有更好的清洗结果.
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
校园英语·月末(2021年13期)2021-03-15
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
