
基于项目关联的Slope One协同过滤算法研究*
2019-09-03 07:22申晋祥鲍美英
计算机与数字工程 2019年8期
申晋祥 鲍美英
(山西大同大学计算机与网络工程学院 大同 037009)
1 引言
全球互联网的普及和电子商务的迅猛发展,网上的数据爆发式增长,用户面对大量数据需要从中提取自己所想要的有价值的内容变得越来越不容易。“信息过载”[1~2]问题成为目前学术界研究的热点之一。推荐系统[3]的出现,很好地缓解了信息过载问题,根据用户的历史行为,通过信息过滤技术向用户推荐所需的信息或感兴趣的内容,而协同过滤推荐算法[4~5]是推荐系统中最常用的技术之一,但在大数据环境下因数据稀疏性、冷启动等问题导致评分预测值误差偏大,其不足之处也越来越明显。
Slope One算法是由 Daniel Lemire[6~7]等提出的一种基于项目的协同过滤算法,这种算法简单、运算高效、准确度高且易于实现和维护而得到高度认可,但该算法在预测评分时也存在一些问题,因为该算法只是简单的采用线性回归分析项目间的相似性,未考虑其它因素对算法推荐精度的影响[8~9]。对算法存在的不足近年来研究人员提出了大量的改进方法,比如最常用的加权Slope One改进算法[10~11],考虑用户评分数对计算项目评分偏差的影响,对Slope One加权处理。李桃迎[12]等提出基于用户兴趣遗忘函数和用户最近邻居筛选策略改进Slope One算法,以提高推荐质量。李剑锋[13]等提出一种基于局部近邻Slope One算法,根据活跃用户进一步优化项目之间的平均偏差,有效提高推荐精度。原福永[14]等考虑到不相关项目对偏差计算产生的影响,提出将项目分类和K近邻引入Slope One算法,得到更好的准确性。沈学利[15]等采用用户耦合相似度和项目耦合相似度对加权Slope One算法进行改进。王万良[16]等引入巴氏系数计算相似度,实现在较低计算复杂度的情况下具有较高推荐精度。
综合以上研究,均未考虑项目之间的关联性对算法精度提高的影响,提出一种基于项目关联的Slope One协同过滤算法,将关联规则概念及原理融入传统Slope One算法,考虑项目之间的关联性并引入置信度加权和设置最小支持度阈值去除非频繁项,减少预测过程的计算量,以提高算法预测精度。采用MovieLens数据集进行实验验证,结果表明所研究的算法能有效提高预测的准确度。
2 Slope One算法及加权Slope One算法原理
2.1 Slope One算法
Slope One算法因简单、高效而得到广泛应用,算法的基本原理是根据用户对项目的已有评分,采用线性回归分析的计算方法,得出用户对项目X和项目Y的评分之间有一种线性关系存在即Y=X+b。
预测评分过程,在User-Item评分矩阵中,设用户U对项目i已评分,对项目j未评分,根据原理两个项目之间的评分存在线性关系Y=X+b,b表示两个项目之间评分的平均偏差的值,通过所有同时对两个项目评过分的用户评分,计算两个项目的评分平均偏差,以此得到b的估计值。计算项目之间评分平均偏差如式(1)所示。

根据评分平均偏差计算对项目j的预测评分如式(2)所示。

上式中,Devj,i表示的是项目j相对项目i评分的偏差,Uj,i表示的是对项目i和项目j同时都评过分的用户集合,Dj表示用户u所有已评分的项目集合且与目标项目j计算平均偏差的项目集合,即符合条件(i≠j∩Uj,i≠φ)的项目集合,ru,i和 ru,j表示用户 u对项目i和项目j的评分,N(Dj)表示集合的项目数量。
SlopeOne算法的一般流程如下:
1)筛选用户集合。在User-Item评分矩阵中并非所有用户都参与目标项目的评分,而是只有对目标项目评过分的用户才构成用户集合。
2)筛选项目集合。根据目标用户的已评分项目来筛选集合中其他用户是否对该项目进行过评分,如果有,就把该项目筛选到参与算法运算的项目集合中。如果没有,该项目即不参与运算。
3)预测项目评分。将User-Item评分矩阵通过筛选用户和筛选项目后得到参与Slope One算法运算的评分数据。
举一简单实例说明Slope One算法的原理,评分数据如表1所示。

表1 User-Item评分矩阵
表中“-”表示用户对该项目未评分。如果要预测User_C对项目Item_1的评分,根据式(1)分别计算项目Item_1相对项目Item_2和项目Item_3的评分偏差如式(3)和式(4)所示。

进而根据式(2)计算User_C对项目Item_1的预测评分如式(5)所示。
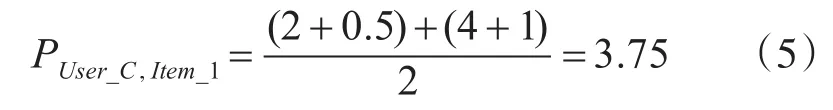
2.2 加权SlopeOne算法
加权Slope One算法(Weighted Slope One algorithm,WSO)是比较常用的Slope One改进算法。其改进原理是考虑到不同的项目对被共同评分的次数差异,在计算过程中加上共同评分次数作为计算权重。改进后的WSO如式(6)所示。

根据式(6)计算上述实例User_C对项目Item_1的预测评分如式(7)所示。

3 基于项目关联的Slope One算法
3.1 关联规则算法
关联规则算法最初来自“购物篮”问题,商家通过分析客户同时购买物品之间的关联进一步掌握客户的兴趣或偏好以便更好地经营。
设 I={i1,i2,…,im}为事务集的项集,事务集中的每个事务T是一个项集,且T⊆I具有唯一的事务标识Tid。设A是一个由项目构成的集合,称为项集,且A⊆T。关联规则“A=>B”表示项集B与项集A存在一定的关联性(A⊆I,B⊆I且A∩B=φ)。
支持度:是指规则中所出现模式的概率,能反映用户对规则的兴趣度。
置信度:是指包含的强度,即包含项集A的事务中同时包含项集B的概率。能反应关联规则的可靠性。
频繁项集:是指支持度大于最小支持度阈值的项集。
当规则“A=>B”即满足最小支持度阈值又满足最小信任度阈值时,称其为强规则,也是最终需要的规则。
关联规则的过程是先通过迭代检索事务集中所有频繁项集,也就是支持度不低于用户设置的最小阈值。然后在频繁项集中构造出强关联规则。
举一简单实例说明关联规则的过程,事务数据库如表2所示。

表2 事务数据库
设最小支持度阈值为2,通过迭代检索事务数据库,得到每个项目的支持度如表3所示,再选取大于最小支持度阈值的选项生成频繁一项集如表4所示。

表3 每个项目的支持度

表4 频繁一项集
以频繁一项集为基础再次检索事务数据库生成二项集并得出支持度如表5所示,再选取大于最小支持度阈值的选项生成频繁二项集如表6所示。
同理进一步类推得到事务数据库最终频繁项集{I2,I3,I5}。
3.2 基于项目关联的Slope One算法
3.2.1 采用置信度为加权权值
将关联规则算法的概念融入到加权Slope One算法中,即同时对项目A和B评过分的用户数也就是关联规则“B=>A”的支持度,相应计算规则“B=>A”的置信度方法如式(8)所示。
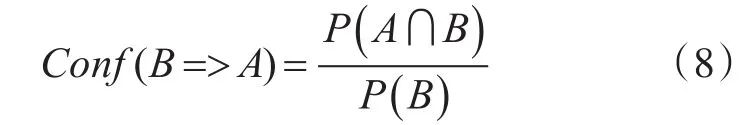
上式中P(B)表示项目B出现的概率即项目B的支持度,当支持度大于所设阈值时即为频繁一项集,P(A∩B)为项目A和项目B同时出现的概率即二项集的支持度,当支持度大于所设阈值时即为频繁二项集,式中Conf(B=>A)是项目B对项目A的置信度,即项目B出现时项目A出现的概率。

表5 二项集的支持度

表6 频繁二项集
关联规则计算“项目B=>项目A”的置信度得到项目A与项目B之间的关联性,再以项目对之间的关联性为加权Slope One算法中的权值进行预测,已知评分项与预测评分项的关联规则置信度越高则用此对项目的评分偏差值计算目标项目的评分可信度就越大。显然可知关联规则中的支持度和置信度能较好地反映出不同项目之间的关联程度,较传统加权Slope One算法仅以一对项目评分过的用户数量为权值来预测,基于关联规则置信度加权的Slope One算法能更合理、更准确地预测未评分项目的评分。
针对前例,采用基于项目关联的Slope One算法预测User_C对项目Item_1的评分,通过式(8)计算“项目Item_2=>项目Item_1”和“项目Item_3=>项目Item_1”的置信度分别为2/3=0.667和1/2=0.5,由此可得User_C对项目Item_1的预测评分值是(2.5*0.667+5*0.5)/(0.667+0.5)=3.571。
3.2.2 设置最小支持度阈值去除非频繁项
在User-Item评分矩阵中,对用户评分极少的项目来讲,实际上并不能准确反应其他用户的评分情况,而且这些极少评分的项目会因偶然性或其他特殊偏好导致对预测结果产生较大的影响,同时还会增加预测过程的计算量。对此可通过设置最小支持度阈值,去除支持度小于所设阈值的非频繁项,且非频繁一项集和非频繁二项集均去除,从而减少预测过程的计算量,同时有效提高预测的准确度。
结合前例,假设最小支持度阈值为2,则项集{Item_1,Item_3}为非频繁项被去除,可得User_C对项目Item_1的预测评分值是(2.5*0.667)/0.667=2.5。
综上所述,改进的基于项目关联的Slope One算法计算过程如式(9)所示。

4 实验结果及分析
4.1 实验数据集
实验采用广泛用于机器学习和数据挖掘的MovieLens官网提供的电影评分数据集,数据集有用户特征信息、电影属性信息、用户对电影的评分信息等。评分范围是从1~5的整数,电影划分为19(0~18)个不同类别。实验采用1MB的数据集,其中包括6040个用户对3900部电影的1000209条评分数据。将数据集随机分成五等份,选择其中四份为训练集,一份为测试集,实验采用五重交叉验证的方法执行多次实验,确保实验的准确性。
4.2 实验评估标准
本实验通过平均绝对偏差(MAE)值和均方根误差(RMSE)值来评估算法的准确度,MAE是算法计算得出的预测评分值和用户对项目的实际评分值之间的偏差,RMSE是计算预测评分与真实评分之间的偏差的均方根值。MAE值和RMSE值越小,说明预测值和真实值之间的误差越小,预测的准确度越高。用N表示实验测试项目数,Pi表示预测评分值,Ri表示实际评分值,MAE和RMSE的计算如式(10)和式(11)所示。

4.3 实验结果及分析
1)实验验证算法预测精度
采用实验数据集将本文提出的基于项目关联的Slope One算法和传统Slope One算法以及加权Slope One算法进行对比,各种算法的MAE和RMSE的实验结果如图1和图2所示。

图1 各种算法的MAE

图2 各种算法的RMSE
改进算法因采用关联规则的相关概念和理论,计算时考虑到不同项目之间的关联性,相比传统Slope One算法及其改进算法,实验结果表明预测的准确度有明显提高,验证了改进算法在预测准确度上的有效性。
2)设置最小支持度阈值对比预测精度
本文所提算法通过设置最小支持度阈值,去除User-Item评分矩阵中支持度小于所设阈值的非频繁项,从而减少预测过程的计算量,同时有效屏蔽了极个别用户因偶然性或其他特殊偏好的评分导致对预测结果产生的影响,以进一步有效提高算法的准确度。
通过实验验证基于项目关联的Slope One算法,在不同最小支持度阈值的情况下去除非频繁项后的MAE和RMSE值,实验结果如图3和图4所示。

图3 不同最小支持度阈值的MAE值

图4 不同最小支持度阈值的RMSE值
实验结果表明,改进算法通过设置最小支持度阈值,MAE值和RMSE值均有明显减小,MAE值在最小支持度阈值等于2时最低,RMSE值在最小支持度阈值等于3时最低,另外从实验结果可以看出,当最小支持度阈值继续逐渐变大时,也就是相应的去除非频繁项更多时,改进算法的MAE值和RMSE值又会逐渐变大。因此改进算法需要设置合适的最小支持度阈值,这样即去除了非频繁项评分对预测结果的影响,减少算法计算量,又能提高算法预测结果的准确度。但是最小支持度阈值的设置与User-Item评分矩阵中的数据属性及大小有很大关系,设置的阈值过大会去除很多有效的评分项,算法误差就会变大。所以改进算法要针对具体数据集进行多次测试选取合适的最小支持度阈值,以提高预测结果的准确度。
5 结语
针对简单且高效的Slope One算法及其相关改进算法所存在的不足,未考虑项目之间的关联性,在研究关联规则原理后将支持度和置信度引入传统Slope One算法中,提出基于项目关联的Slope One算法,通过置信度加权和去除小于所设最小支持度阈值的非频繁项,减少预测过程的计算量,同时提高算法的准确度。实验结果表明所提算法有效地提高了预测结果的准确度。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
计算机应用与软件(2022年7期)2022-08-10
小型微型计算机系统(2022年4期)2022-05-09
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
哈尔滨理工大学学报(2021年4期)2021-10-07
计算机与数字工程(2020年7期)2020-10-09
智能计算机与应用(2020年4期)2020-08-31
中国科技纵横(2016年20期)2016-12-28
