
基于Haar-NMF特征和级联AdaBoost的脱岗检测算法
2019-09-19 06:08魏京天王玉楠2薄煜明
测控技术 2019年2期
魏京天, 王 军, 王玉楠2, 薄煜明
(1.南京理工大学 先进发射协同创新中心,江苏 南京 210094; 2.东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
近些年来,国防、安防、消防等高危化行业的岗位执勤工作日益受到重视,因此设计并实现一套可用于检测值班室人员是否脱岗的系统具有十分现实的意义[1-2]。由于值班人员的“空岗”往往会造成不可估量的损失,脱岗检测就显得尤为重要。早期一般是通过指派专人不定期地查岗来进行脱岗检测[3],但这种方式实时性很差,难以第一时间处理突发状况并且查岗耗费太多不必要的时间。随着目标检测领域的不断发展,一套基于视频监控平台的值班室人员脱岗检测系统应运而生。
脱岗检测的方法论是基于机器学习中统计学习的方法[4],设计一个完整成熟的脱岗检测系统必须要解决一些关键问题,包括适应行人姿态变化的多样性、单一场景下对行人和背景的分辨性和检测的准确性和实时性等,其中在工程化和商业化的过程中最需要解决的问题就是如何同时兼顾检测的准确率和检测速度,设计并实现一种特定场景下满足特定需求的脱岗检测算法。在解决检测速度和检测准确度方面,由于对检测准确性的高要求通常使得算法处理的过程中消耗了大量时间,而对于脱岗检测这种单一场景下单一目标检测的情况,对于区分有人和没人的情况不需要使用很复杂的训练过程和算法,因此,主要需要解决的问题就是检测速度的问题,这也是目前所有的脱岗检测应用急需解决的问题。
针对以上问题,为了降低算法的复杂度,没有采用基于深度学习的方法,而是采用传统的脱岗检测的算法,对基于Haar特征和分类器的算法进行了改进,提出了一种基于Haar-NMF特征和级联分类器的算法。
脱岗检测系统一般分为外观特征提取和分类学习两个部分,常用的外观特征有Haar特征、形状特征、颜色特征、以及方向梯度直方图等[5-6]。常用的分类方法有人工神经网络、聚类算法以及集成算法[7-8]。本文重点研究基于Haar特征,提出利用非负矩阵分解Haar特征进行降维,提取出训练样本的Haar-NMF特征,得到基于人体特征的弱分类器,级联得到14级的强分类器。针对分类器所产生的错误检测进行噪声消除等优化措施[9]。实验表明,经过降维的Haar特征的训练时间要短于普通的Haar特征,通过级联得到分类器的检测效果也比单一分类器的检测效果好,整个基于Haar-NMF特征和级联分类器组成的系统实现了检测速度和准确率的折中,对脱岗检测场景有较强的适用性。
1 基于Haar-NMF特征和级联AdaBoost的脱岗检测基本原理
1.1 Haar-NMF特征
Haar-NMF特征分为边缘特征、线性特征、中心特征和对角线特征[10-11],可由白色矩形和黑色矩形经过不同的组合得到不同的特征模板。Haar-NMF特征可以很好地表征图像中局部区域的特征,如在岗人员的头部和肩部特征,并且可以满足高精度的要求。具体计算方法如下。
(1) 设T是长度为L的Haar特征向量,将其取绝对值后转化为m×n的矩阵A,文中将训练样本归一化后,得到L=122512,为便于后续进行低秩矩阵分解运算,需将向量T中的特征量放进矩阵A中存放,对于m、n的取值,没有原则性的要求,但需满足L=m×n与m>n,经查阅相关资料[12],一般列数n的取值较小,本文取m=4712,n=26。
(2) 对转化后的矩阵A进行秩为r的NMF分解:
A=W×KT
(1)
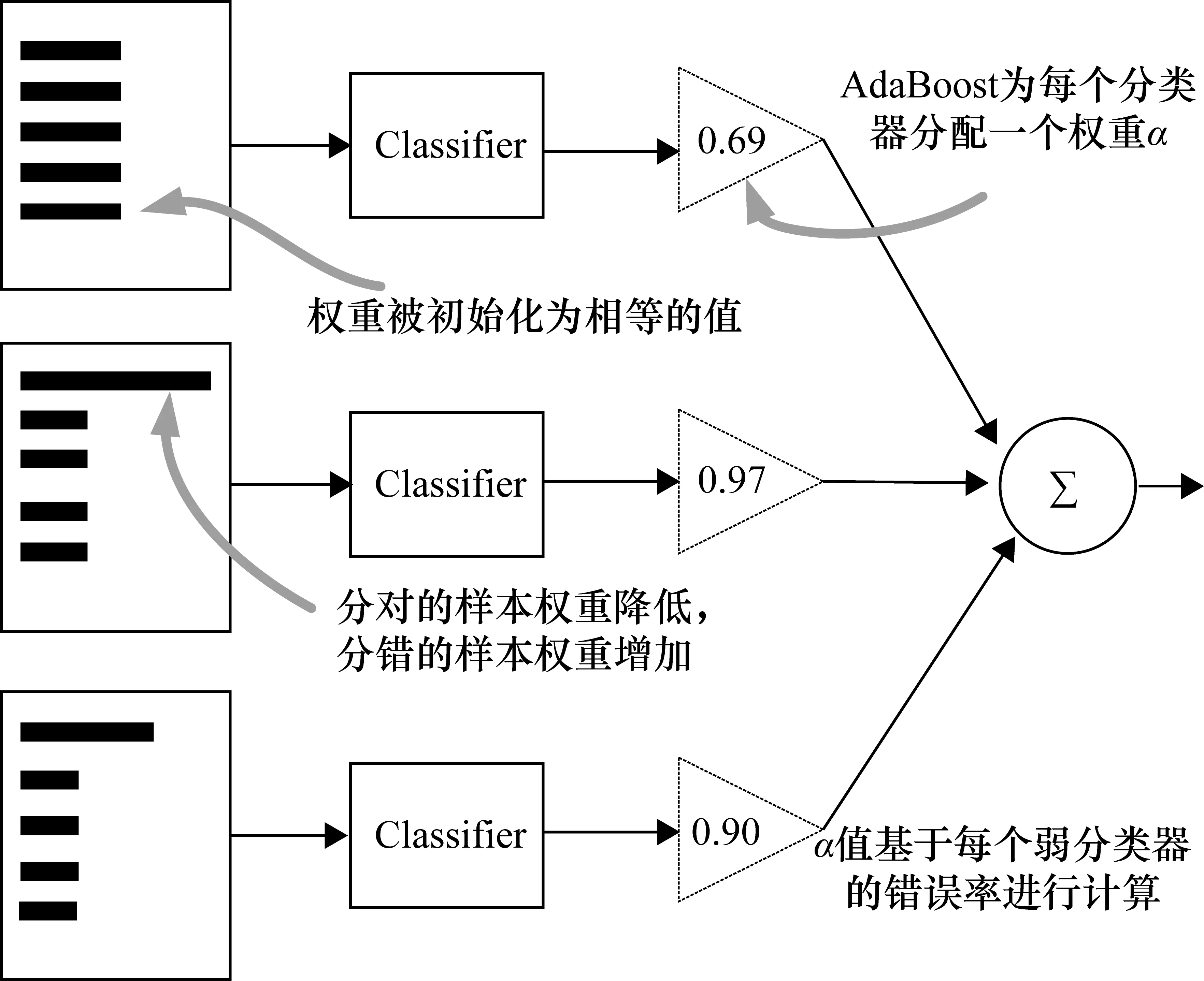
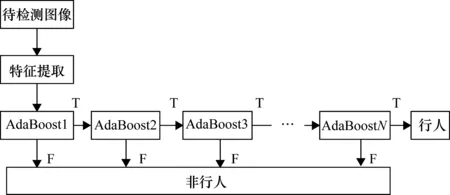
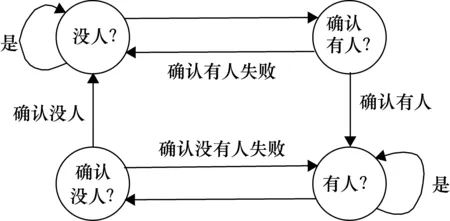
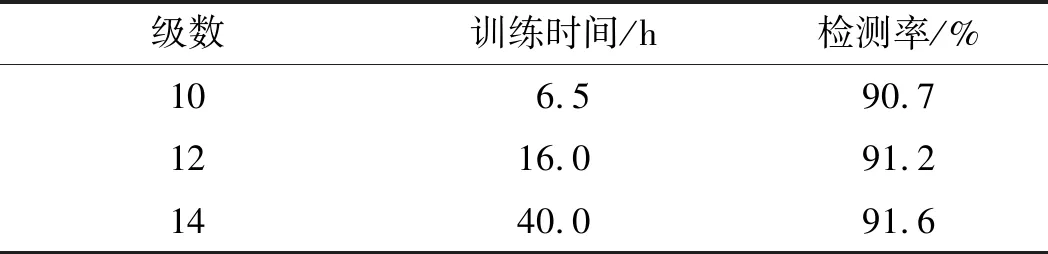
式中,W和K分别为m×r和n×r的非负的基矩阵和系数矩阵,应满足r< (3) 对W和K的每一个列向量进行归一化处理,即 (2) (4) 将所有的ia级联成Haar-NMF特征。Haar-NMF特征通过低秩分解得到的基矩阵和系数矩阵很好地保留了Haar特征的特性,并且减少了算法的计算时间。 在得到Haar-NMF特征后,需要送入Cascade AdaBoost分类器进行训练,目的是生成结果文件cascade.xml,以便被程序在进行实际检测时调用。通常情况下,AdaBoost算法示意图如图1所示。 图1 AdaBoost算法示意图 算法流程如下:给定一个训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中实例xi∈X,实例空间x⊂Rn,yi属于标记集合{-1,+1}。 (1) 首先对训练数据的权重进行初始化,给每一个训练样本赋予同样的权值:1/N。 D1=(w11,w12,…,w1i,…,w1N) (3) (4) (2) 接着进行多次迭代运算,其中m表示迭代的轮数(m=1,2,…,M)。 ① 使用具有权值分布Dm的训练数据集学习,选取让误差率最低的阈值来设计基本分类器: Gm(x):x→{-1,+1} (5) ② 计算Gm(x)在训练数据集上的分类误差率em: (6) 式中,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和,I为单个样本的代价函数,取值为“0”或“1”,当样本的预测结果和真实结果相同时,代价函数的值为“0”,反之代价函数值为“1”。 ③ 计算Gm(x)的系数,αm表示Gm(x)在最终分类器中的重要程度,该步骤的目的在于计算出基本分类器在最终分类器中所占的权重αm: (7) 式中,em≤1/2时,αm≥0,且αm随着em的减小而增大,即分类误差率越小,基本分类器在最终分类器中的作用越大。 ④ 更新训练数据集的权值分布,目的是得到样本新的权值分布,用于下一轮迭代: Dm+1=(wm+1,1,wm+1,2,…,wm+1,N) (8) (9) 式中i=1,2,…N。AdaBoost是通过增大基本分类器Gm(x)误分类样本的权值以及减小正确分类样本的权值来重点关注那些比较难区分的样本,式(10)中Zm是规范化因子,使得Dm+1成为一个概率分布: (10) (3) 组成各弱分类器f(x)。 (11) 得到的最终强分类器如下: (12) 实际应用中,一般将上述训练得到的强分类器AdaBoost串联起来构成级联分类器,即Cascade AdaBoost。概括来说,Cascade AdaBoost就是一簇包含若干层的强分类器AdaBoost的集合[13]。 由于AdaBoost本身由多个弱分类器构成,故级联的AdaBoost本质上来说是由若干簇弱分类器层层叠加所构成的,其中每一簇的弱分类器构成一个AdaBoost分类器,多个AdaBoost分类器串联组成一个Cascade AdaBoost,之后提取每个平滑窗上的不同特征,并把这些特征依次放进不同的AdaBoost的弱分类器里进行判断,如果所有的弱分类器都判断为正标签,则表示该平滑窗内检测到目标,接下来就送到下一级AdaBoost的弱分类器里继续进行判断,分类器结构图如图2所示。 图2 级联分类器结构图 采用级联分类器的好处主要有两点:一是通过多个弱分类器的级联形成一个强的级联分类器,能够提高检测的准确率[14];二是可以减少运算量,比如采用一个包含400个弱分类器的AdaBoost和采用20级包含20个弱分类器的Cascade AdaBoost检测效果相同,但是当一个平滑窗第一个特征没有通过第一个分类器,那么Cascade AdaBoost就没有必要继续运算下去,直接拒绝掉当前平滑窗,转而处理下一个平滑窗。Cascade AdaBoost的级联思想保证了可以快速抛弃掉没有目标的平滑窗,从而提高了检测效率,满足了系统实时性的需求。 脱岗检测的本质是分类问题,即检测目标图像是“有人?”还是“没人?”。基于此,本项目所设计的检测系统,其状态机共4种状态,分别是“有人?”、“确认有人?”、“没人?”、“确认没人?”。该状态机可形象地用图3来表示。 图3 脱岗检测状态机 检测视频图像帧序列,当检测不到人时,首先在图像中找人,当检测到一帧图像中有人时,继续检测进行确认,当检测到与该帧图像相邻的连续5帧图像中有3帧中有人或者连续5帧有3帧画面中存在移动时,则判定画面中有人,即值班人员在岗,否则确认有人失败,值班人员脱岗;当连续检测到有人状态,突然某一帧无法检测到人,则继续在视频序列中找人确认是否的确没人,当接下来的连续5帧图像中有2帧检测不到有人或者连续5帧有4帧没有检测到存在移动时,则认定视频中没有人,否则值班人员在岗。实际检测结果中当屏幕显示AffirmNoPeople(确认没人)、PeopleInPic(有人)状态时字幕都呈绿色,而显示AffirmPeople(确认有人)、NoPeopleInPic(没人)状态时字幕则呈橘色,当NoPeopleInPic(没人)状态持续超过1 min时,字幕变成红色,系统自动报警,同时系统自动将此时的脱岗图片存放到程序中指定的报警图片文件夹。 本文样本集由3000张正样本和4000张负样本组成,正样本由人的头部和肩部等上半身特征组成,负样本由复杂的环境特征和其他无关特征构成,选用的部分正负样本集分别如图4、图5所示。 图4 部分正样本集 图5 部分负样本集 系统整体的训练及检测流程图如图6所示。 图6 系统训练和测试流程图 在系统测试过程中,画面中出现在岗行人运动时,系统通过检测相邻画面的帧的差值来判断是否有运动的行人,即是否在岗。当在岗人员处于坐立状态时,除了像普通人脸识别对人体面部进行检测外,还因人体坐姿的不确定性,对头部的侧方和后方的特征进行检测。 本文的测试平台为Visual Studio 2012和OpenCV 3,编程语言为C++,测试计算机配置为Intel Core i7-7700K,内存为16 GB,GPU为6 GB的GTX1060。 分别对提取的Haar特征和Haar-NMF特征进行分类训练,分类器均为10级的AdaBoost分类器,计算训练时间和检测率。其中检测子窗口的大小为30×30,步长为8,单帧图片的平均检测时间为33 ms。使用Haar-NMF特征训练的时间明显小于Haar特征的训练时间。对比结果如表1所示。 表1 特征训练时间与检测率对比 由表1可以得出,使用Haar-NMF特征与使用Haar特征进行训练相比,训练时间大大降低,但是训练的结果(检测率)并没有大幅下降。因此可以得出结论,使用Haar-NMF特征可以有效地降低算法的复杂度,提升系统训练和检测的速度。 启动程序调用训练好的级联分类器文件cascade.xml,加载入多个测试视频,测试视频的帧率为60 f/s,清晰度为720p,图片的分辨率为1816像素×988像素,检测效果如图7、图8所示。 图7 初步测试结果(1) 图8 初步测试结果(2) 测试时发现有时会有误检的情况,误检目标一般为桌面上的小物件,如图9所示。 图9 部分误检结果 本设计进行了多次正负样本的补充,最终使用的正样本数为4000个,负样本数为5000张,当然分类器自行分割的负样本数远不止于此,部分补充后的样本如图10所示。 图10 部分补充后的样本 增加正负样本训练后检测效果有所提升,实验证明补充样本后的检测效果有所改善,检测率由原来的88.1%提升为90.7%,最终测试结果如图11所示。 图11 最终测试结果 为了进一步改善分类性能,本设计对级联分类器也进行了多次调试,级数由原来的10级提高至12级并最终增至14级,其对比结果如表2所示。 表2 不同分类器级数训练时间与检测率对比 采用14级分类器分别对Haar特征和Haar-NMF特征进行训练,得到的检测时间与检测率如表3所示。 表3 14级分类器训练时间与检测率对比 通过表2和表3的实验结果可以得出,提高分类器计数能在一定程度上提升检测率,对分类性能有所改善。运用Haar-NMF特征进行检测时,在检测率很好的同时,大大降低了训练时间。 本文针对传统的脱岗检测技术和理论进行了一定的改进并加以实现,提出了一种基于Haar-NMF特征和级联分类器的算法。 采用低维Haar-NMF特征代替传统的Haar特征,Haar-NMF特征可以很好地表征图像中局部区域的特征,如在岗人员的头部和肩部特征,满足系统对检测准确率的要求;采用级联AdaBoost分类器代替AdaBoost分类器,提高了检测的准确率并减少了运算量,满足系统对检测速度的要求。实验表明,此算法在保证检测成功率的基础上,缩短了样本的训练和检测的时间,并且通过增加分类器的级数提高了系统的部分性能,验证了本文理论的正确性和实现的可行性。1.2 级联AdaBoost算法
2 实验设计与过程
2.1 基本思想
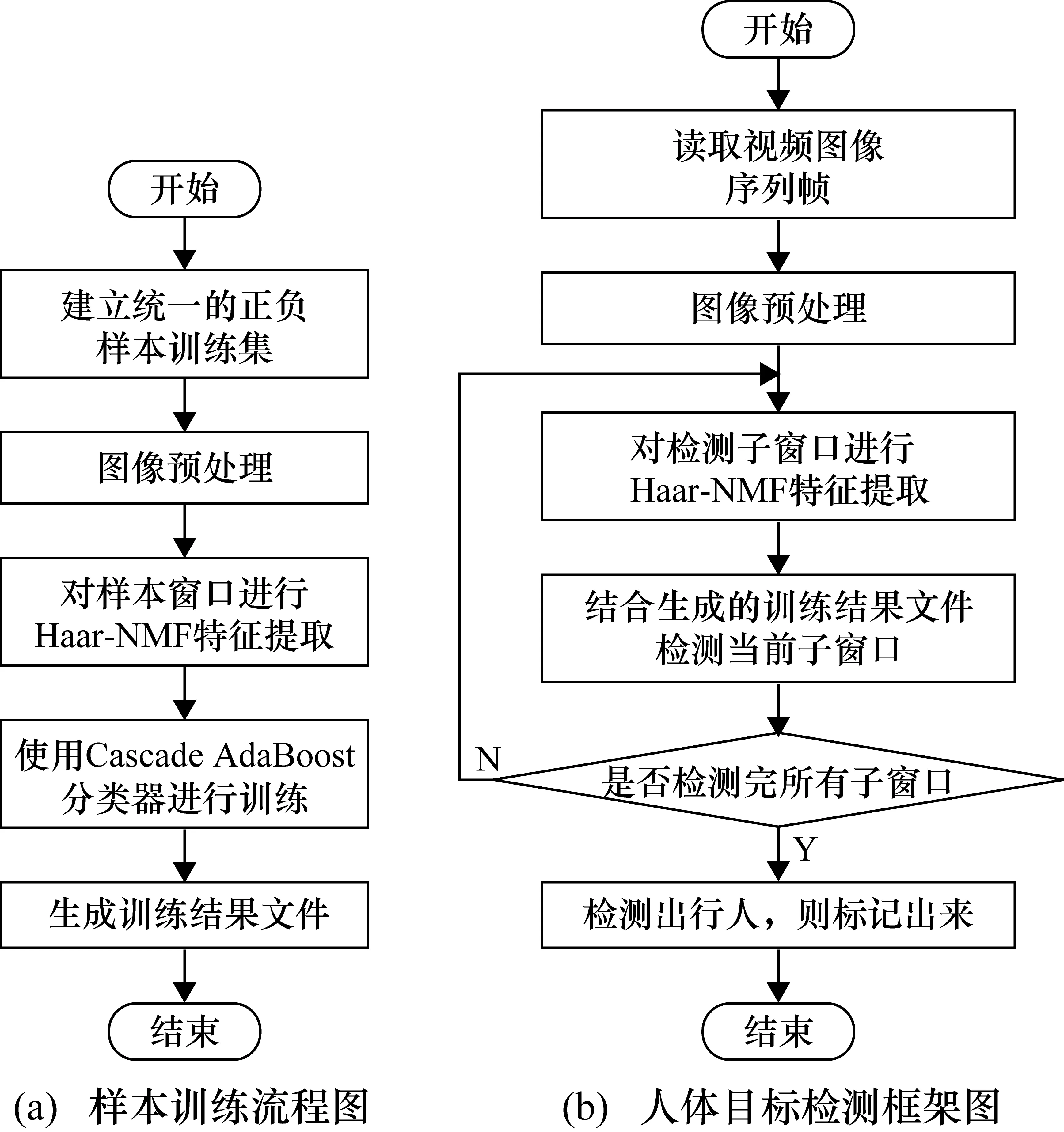
2.2 分类器训练流程
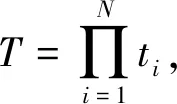
3 实验测试与分析









4 结束语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
核安全(2022年3期)2022-06-29
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
—— “T”级联
同位素(2019年1期)2019-03-14
江苏通信(2018年4期)2018-12-04
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
自动化学报(2017年7期)2017-04-18
原子能科学技术(2015年12期)2015-07-07
原子能科学技术(2015年1期)2015-05-25
