
基于优化多类Adaboost的非侵入式负荷监测
2019-10-09 01:44
福建工程学院学报 2019年4期
(福建工程学院 信息科学与工程学院,福建 福州 350118)
非侵入式负荷监测(NILM)技术[1],是在用户入口处安装传感器,采集终端的总电流、总功率等用电数据,从而获得用户家中每台用电器的用电情况。与传统的侵入式负荷监测(ILM)技术相比,NILM具有安装方便,经济可靠的优点。目前,在大数据和智能用电背景的推动下,NILM再次引起了研究人员和专家的广泛关注。NILM系统的概念在1982年由麻省理工学院的Hart教授提出,它旨在为公用事业公司提供一种有效便捷的能耗数据收集方法[2]。通过NILM技术,居民可以实时观察家中各用电器的用电情况,从而提高居民的节能意识,达到节能减排的目的。电力公司可以通过NILM了解每个负荷的特性,从而起到保护电网的作用。因此,研究NILM技术具有重要意义。
国内外学者对NILM技术进行了大量的研究。文献[3]使用有功功率,无功功率和功率因数等特征,利用支持向量机和k-NN(k=5)算法进行分类,比仅使用有功功率特征实现了更精确的设备识别。文献[4]提出了一种利用谐波和功率多重特征的改进遗传算法(GA),其性能明显优于仅使用单功率特征的遗传算法。文献[5]提出了一种基于高阶统计量(HOS)对电器进行分类的NILM方法。采用HOS算法结合Fisher的判别式和遗传算法(GA),对每个负载的50个电流暂态信号进行降维,提取具有代表性的特征,适用于实时监测。文献[6]提出了一种负荷分解和决策融合的分类方法,融合了多种算法的结果,提高了设备状态识别的精度。
文献[7]中提出了一种NILM方法,该方法每10秒采样一次功率变化数据,利用SVM算法对电器事件进行检测。该方法对高能耗设备的精度可达80%以上。Baets L D等[8]提出了将电流电压轨迹通过加权像素化作为一个新特征,采用卷积神经网络(CNN)来提取分类的关键特征,并在大量的电器分类中取得了良好的效果。
王守相等[9]提出一种基于用电模式的居民负荷梯度提升树分类识别方法,采用PCA降维和k-均值算法,从特征的主成分中获得各类负荷用电模式,训练GBDT并进行超参数优化。实验结果表明,该模型具有较好的分类性能。文献[10]提出了一种基于Adaboost的训练集的筛选方法,并采用k-NN和核Fisher判别分析(FDA)相结合的算法,提高了对特征相近的电气设备的识别精度。文献[11]提出将基于Adaboost改进的BP神经网络用于负荷识别,将BP神经网络作为弱分类器,负荷识别准确率高。
上述论文主要研究负荷的识别和开关两种状态,缺乏对设备多状态识别的研究。为了解决多状态用电设备下的状态识别问题,本文提出了一种基于遗传算法优化的多类Adaboost的非侵入式负荷监测技术,该方法利用电流有效值,有功功率,电流有效值变化量和有功功率变化量、无功功率等特征,通过测试集数据验证了算法的有效性。
1 特征提取
一般NILM系统框图如图1所示,分别为数据采集、预处理、特征提取和模式识别四步。本文先对原始数据集进行特征提取,然后使用遗传算法优化的多类Adaboost执行模式识别分类。

图1 系统框图Fig.1 Basic structure of the system
对原始数据集中单个设备的单一态的电流有效值和有功功率,以及九阳热水壶和FUJI激光打印机两个设备共同运行的叠加态的电流有效值、有功功率数据进行分析。
如图2、图3所示,九阳热水壶启动后,有功功率和电流有效值从一个低水平上升到一个高水平,随后保持平稳状态直到关闭。FUJI激光打印机在工作状态下(扫描、打印、复印)的工作时间短。如图4所示,九阳热水壶和FUJI激光打印机共同运行时电流的有效值和有功功率呈现出可叠加性。

图2 九阳热水壶和FUJI激光打印机有功功率Fig.2 Active powers of Joyoung kettle and FUJI laser printer

图3 九阳热水壶和FUJI激光打印机电流有效值Fig.3 Effective current values of Joyoung kettle and FUJI laser printer

图4 九阳热水壶和FUJI激光打印机叠加态电流有效值(左)和有功功率(右)Fig.4 Effective current values (left)and active powers (right)of the superposition state of Joyoung kettle and FUJI laser printer
根据叠加原理,通过式(1)表示几种设备的总有功功率:

(1)
式中,Pi(t)为第i个设备在t时刻的有功功率,n为设备总数。通过计算两个连续有功功率之间的差,得到其变化量,并将所有变化量相加,如式(2)所示:

(2)
相似地,对于电流有效值,总的电流有效值如式(3)所示,变化量以及变化量之和如式(4)所示:

(3)

(4)
式中,Ii(t)为第i个设备在t时刻的电流有效值。ΔPi(t)和ΔIi(t)为提取设备负载工作状态变化量的特征。结合有功功率、电流有效值、有功功率变化量、电流有效值变化量、无功功率判断此时设备的状态。
2 优化多类Adaboost算法状态识别
SAMME[12]算法是一种重要的多类Adaboost算法,通过扩展指数损失函数直接把二类的AdaBoost算法扩展为多类[13],并降低对弱分类器分类正确率的要求,很容易获得足够的分类器,对多类问题具有很好的泛化效果。通过建立多个CART分类树弱分类器,对各个CART分类树弱分类器进行训练,根据每次迭代结果,增加识别用电设备工作状态精确率低的样本的权重,降低识别用电设备工作状态精确率高的样本的权重。直到满足迭代次数,退出循环。最后,将多个CART分类树弱分类器进行组合,得到强分类器,减少决策树容易发生的过拟合问题,提高识别精度。
本文利用遗传算法具有搜索全局最优解特点[14],优化多类Adaboost算法参数,并用GA-Adaboost算法对训练集进行3折交叉验证的准确率均值作为适应度函数,选择出最佳参数组合,提高多类Adaboost对用电设备工作状态的识别准确率。
基于遗传算法优化的多类Adaboost算法将CART作为弱分类器,利用GA对CART中的max_depth、min_samples_split、min_samples_leaf以及Adaboost中n_estimators、learning_rate等参数进行优化,得到最优强分类器,最终识别用电设备工作状态。具体实现步骤如下:
输入:S={(x1,y1),(x2,y2),…,(xm,ym)}有效特征训练集,其中xi是由有功功率P、电流有效值I、有功功率变化量ΔP、电流有效值变化量ΔI、无功功率Q组成的任一向量,yi为标签状态编号,其中yi⊂Y={1,2,3,…,k},k为状态类别数。
输出:各用电设备工作状态。


(5)
步骤2:利用遗传算法,寻找最优参数。
步骤3:根据训练集和样本权重,训练CART分类树弱分类器ht(x),t= 1,2,…,n,n为最大迭代次数。
通过式(6)计算分类误差率:

(6)
其中I(.)是一个指示符函数,如果条件为真,则返回1,否则返回0 。
通过式(7)计算CART分类树弱分类器ht(x)系数:

(7)
通过式(8)更新下一次迭代的样本权重:

(8)
判断是否满足迭代次数,若是,执行步骤4,否则,执行步骤3。
步骤4:输出用电设备工作状态
通过式(9)得到的强分类器表示为:

(9)
将含有P、I、ΔP、ΔI、Q等特征的待测样本x,利用训练好的强分类器G(X)进行状态识别。
输出用电设备工作状态。

图5 基于遗传算法优化的多类Adaboost的NILM流程Fig.5 Flow chart of non-intrusive load monitoring based on multi-class Adaboost optimized by GA
3 实验
实验采用的是Windows 7 64位操作系统的台式计算机,主频为3.30 GHz,8G内存,结合python3试验平台,以第六届泰迪杯A题数据为例,选择两种常见用电设备,九阳热水壶和FUJI激光打印机作为我们的测试目标,其中九阳热水壶有2个状态(关闭,运行),FUJI激光打印机有5个状态(关闭,待机,打印,复印,扫描),采用九阳热水壶,FUJI激光打印机叠加态数据样本为本文数据集。
3.1 评价指标
为了评估本文方法,使用了四个常见的评估指标,包括准确率(acc)、精确率(P)、召回率(R)和F-Score值(F1)。其中,准确率提供实验结果的全局信息,F-Score值综合了精确率和召回率信息。采用下列公式计算四个评价指标。

(10)
在式(10)中,ei和zi分别为第i个样本的预测值和真实值,I(.)是一个指示函数,如果ei=zi返回1,否则返回0。
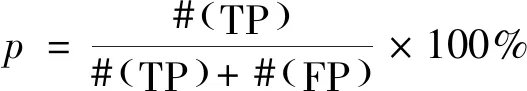
(11)
在式(11)中,TP(true positive)表示样本被标记为ci并被预测为ci,而FP(false positive)表示样本被标记为cj但被错误地预测为ci。ci和cj为两个类,ci≠cj。#(.)返回全部预测结果。

(12)
在式(12)中,FN(false negative)表示样本被标记为ci但被错误地预测为cj。

(13)
3.2 实验结论与分析
本文应用3折交叉验证,对模型进行训练,并对超参数进行优化,最后用测试集测试。从数据样本中随机选择70%和80%作为训练集样本,剩余的30%和20%分别为其测试集样本,分别定义为样本1、样本2。将GA-Adaboost算法与DT和SVM算法进行比较(如表2)。针对样本1、样本2,GA-Adaboost算法对识别九阳热水壶和FUJI激光打印机共同运行状态的整体识别率高于决策树和SVM。针对样本1、样本2的训练时间,决策树算法训练时间最短,SVM次之,GA-Adaboost算法训练时间较长,该算法超参数较多,因此寻找最优超参数增加了训练时间;从测试时间上看,GA-Adaboost算法测试时间仍多于决策树和SVM算法。本文方法的训练时间和测试时间较决策树和SVM算法长,但其准确率比其余方法高 。
利用3种算法对九阳热水壶和FUJI激光打印机共同运行状态的精确率、召回率和F1值进行测试(如表3、表4)。最后给出了两种不同样本比例下设备状态分类的混淆矩阵图(如图6、图7)。
如表3和图6所示,针对样本1,对于识别九阳电热水壶与FUJI激光打印机共同运行的七种工作状态(数据集中仅含0、1、4、6、7、8、9状态),GA-Adaboost对于7状态的识别精确率较低,P值为50%,对8状态的召回率低,对其余状态的识别能力较好,决策树算法未能识别出8和9状态,SVM算法未能识别出8状态。
如表4和图7所示,针对样本2,相对于GA-Adaboost算法,决策树未能识别9状态,SVM算法未能识别出7和8状态。
在样本1以及样本2中,基于遗传算法优化的Adaboost算法分类效果最好,SVM算法在3种算法中效果较差。

表2 不同划分比例样本下的 DT、SVM和GA-Adaboost算法的状态分类结果Tab.2 State classification results of DT,SVM and GA-Adaboost algorithms under different scaled samples

表3 样本1下的 DT、SVM和GA-Adaboost算法的状态分类精确率、召回率、F1值Tab.3 Precision,recall rate and F1 value of state classification by DT,SVM and GA-Adaboost algorithms under Sample 1 %

图6 在样本1下,基于DecisionTree(左)、SVM(中)、GA-Adaboost(右)对九阳热水壶和FUJI激光打印机共同运行的混淆矩阵图Fig.6 Confusion matrix diagram of common operation between Jiuyang Kettle and FUJI laser printer based on DecisionTree (left),SVM(middle)and GA-Adaboost (right)under Sample 1

表4 样本2下的DT、SVM和GA优化的多类Adaboost算法的状态分类精确率、召回率、F1值Tab.4 Precision,recall rate and F1 value of state classification by DT,SVM and GA-Adaboost algorithms under Sample 2 %

图7 在样本2下,基于DecisionTree(左)、SVM(中)、GA-Adaboost(右)对九阳热水壶和FUJI激光打印机共同运行的混淆矩阵图Fig.7 Confusion matrix diagram of common operation between Jiuyang kettle and FUJI laser printer based on DecisionTree(left),SVM (middle)and GA-Adaboost (right)under Sample 2
4 结论
提出一种基于遗传算法优化的多类Adaboost算法的非侵入式负荷监测,采用电流有效值、有功功率、有功功率功率变化量、电流有效值变化量、无功功率等多特征,实验结果表明该方法对于多状态设备的状态辨识,较决策树算法和SVM算法精度高。但是实际生活中,居民家庭中不仅仅只有两种用电器共同运行,因此对于多种用电设备共同运行的状态辨识,特别是多状态设备的状态辨识,仍然需要进一步研究。
猜你喜欢
作文小学高年级(2021年3期)2021-04-15
家用电器(2019年4期)2019-09-10
计算机应用(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
三月三(2017年1期)2017-02-25
三月三(2017年1期)2017-02-25
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代计算机(2016年34期)2016-02-28
