
对多功能相控阵雷达干扰决策方法综述
2019-10-22 06:03张柏开朱卫纲
兵器装备工程学报 2019年9期
张柏开,朱卫纲
(中国人民解放军航天工程大学 a.研究生院; b.电子与光学工程系, 北京 101416)
多功能相控阵雷达可同时完成搜索、跟踪、识别、制导等多种功能,可取代多部搜索雷达和跟踪雷达[1-2],具有反应快、波束灵活、抗干扰能力强、隐身性能好等突出优点。多功能相控阵雷达的不断发展使得传统的、单一的干扰方式捉襟见肘,如何快速有效地对多功能相控阵雷达进行干扰是亟待解决的问题。传统电子战缺乏对电磁环境的感知和优化处理,面对高功率、多域压制、快速变化的电磁干扰,往往探测能力严重削弱。在整体能量、时间、频谱资源受限的条件下,雷达传统对抗方法就不再适用[3];同时组网雷达和认知雷达[4]的快速发展也使得传统对抗方法捉襟见肘。为了解决上述问题同时也为了更好应对日益复杂的战场电磁环境和层出不穷的自适应电子战装备,认知电子战的概念应运而生。认知电子战[5-8]由认知侦察、认知对抗、认知效能评估、动态知识库四个环节组成,每个环节各司其职,相互独立又实时地交互信息,既提高了工作效率又提升了系统性能。
干扰决策作为认知对抗环中的关键环节,在认知电子战中具有十分重要的作用。其任务是对认知侦察环节提供的威胁数据和动态知识库进行分析,从而为威胁对象决策出合适的干扰方法,并根据认知评估环节不断地调整干扰方法。在日益复杂多变的电磁环境下,干扰方法和抗干扰技术层出不穷且现阶段很难将具体的雷达工作模式和某种干扰样式建立起一一对应的关系,所以选择准确的干扰方法可以使雷达系统发挥出最大的威力。同时,新装备的快速发展,新体制、多功能雷达的大量出现又使得现有的干扰决策方法不能有效的应对。对于传统的依靠操作人员和专家的经验判断和人为“试错”效率显然是低下的。一方面,操作人员的精力和知识总是有限的,现有的知识库往往会滞后于战场的需求;另一方面,战场要求的准确性和时效性往往用传统的决策方法得不到满足,快速准确的决策方法可以直接影响到战局的进程,掌握战争的主动权。所以,对干扰决策方法的研究刻不容缓。关于干扰决策方法的文献资料极少公开,国外的相关资料更是难以查找,根据已有资料,现阶段对于干扰决策的方法研究大体上可以分为四类。
本文全面回顾和介绍了四类主要的雷达干扰决策及发展现状,在此基础上提出未来需要发展的重点方向,并探讨了几种可行方案。
1 雷达干扰决策方法
1.1 基于模板匹配的干扰决策方法
传统的干扰决策方法是基于模板匹配的方法。基于模板匹配的方法[9-10]的核心在于充分的先验知识,所以先验知识库的质量直接决定了此类干扰决策方法的时效性和准确性。其原理如图1所示。

图1 基于模板匹配的干扰决策原理框图
基于模板匹配的干扰决策方法主要适用于参数不变的雷达体制,故上述方法存在两点明显不足:第一,先验知识库不具有时效性,往往滞后于战场的实际需求,构建针对新型雷达数据的干扰样式数据库,往往是通过不断地“试错”机制建立,这样的方法短则数月,长则数年,浪费了大量的精力和时间;其次,面对体制日益复杂的雷达体制,先验知识库没有与之对应的先验知识,基于模板匹配的方法就无从对抗。
1.2 基于博弈论思想的干扰决策方法
博弈论的核心就在于盈利矩阵的建立。这种方法将博弈时如何使损失最小,利益最大作为原则,应用到雷达干扰决策中。博弈论的研究最早源于数学运筹学中的对策论思想。西安电子科技大学的张永顺和赵国庆等[11]详细介绍了博弈论的纯策略和混合策略的基本原理,并且列出了雷达干扰手段对抗干扰技术的部分盈利矩阵如下:

JJ1J2…Jn RR1R2︙RmE11E12…E1nE21E22…E2n︙︙…︙Em1Em2…Emn

根据以上分析可知,盈利值E的获得至关重要,许多电子战的学者通过大量的实验和不断的探讨,提供了大量的宝贵经验,部分参考值如表1所示[12]。
表1为电子战中常用的干扰措施和抗干扰措施之间的盈利值,不仅为基于博弈论的干扰决策方法提供了建立盈利矩阵所需要的具体数据,也为之后电子战决策研究提供参考。
基于博弈论算法的雷达干扰决策方法有如下局限性:一方面太过于依赖盈利矩阵的建立,如果没有合适的盈利矩阵,那么博弈论的方法就无从谈起,而且随着新装备的大量出现和战场环境的复杂多变,盈利矩阵建立的工程性和难度极大甚至是不可能完成;另一方面是盈利矩阵算法所固有的缺陷:博弈论“追求”的是损失最小,从而在一定的概率下放弃了最佳的干扰样式。
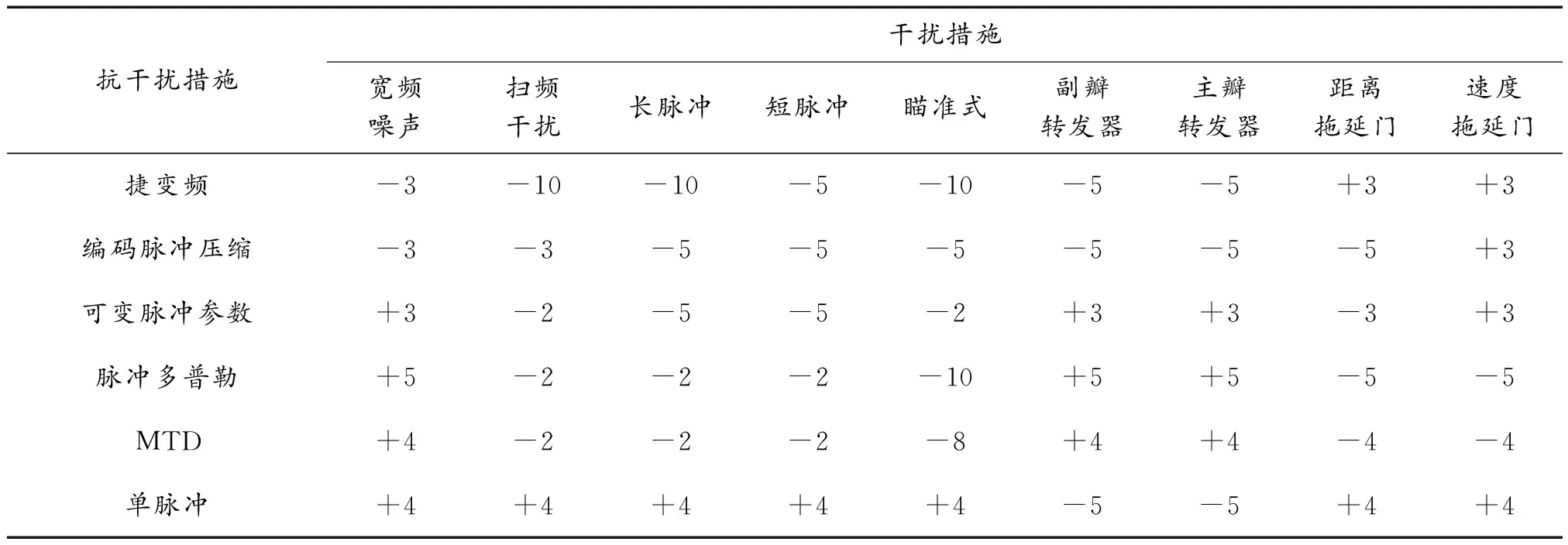
表1 盈利值
针对于干扰和抗干扰措施的与日俱增,盈利矩阵也不断更新且趋于大型化,传统的求解方法显然难以适用,赖中安等采用迭代法-Brown 算法求解大型矩阵对策,得到了干扰方的最优干扰策略[13],但其本质还是基于博弈论算法的干扰决策方法,未能很好地解决博弈论算法本身固有的缺陷。文献[14]中刘清等将干扰效能分为干扰效果和干扰效率两个方面并进行了定量分析,建立了雷达对抗策略矩阵,在此基础上运用对策论的相关原理,研究了干扰方式的选择问题。博弈论算法在提出阶段就引起了广泛的关注,在其后的数年时间,很多学者不断地对此种算法进行改进,2014 年周脉成运用博弈论算法部分解决了雷达抗干扰样式多样性、难识别性的特点[15],给出了获得盈利矩阵的两种方法,详细分析了不同先验信息条件下的雷达干扰决策方法。2017 年唐文龙等针对以往博弈论算法局限于最大最小决策准则,提出一种基于多决策准则的干扰样式选择方法[16],最后将不同准则中选有次数最多的干扰样式作为最终的干扰方案。但是即使采用多种决策准则也无法从本质上改变上述“博弈论”思想本身的局限性。
1.3 基于决策支持系统的干扰决策方法
王杰贵等研究了应用于地对空场景下的智能雷达干扰决策支持系统(IDSSRJ)。 IDSSRJ[17]由人机会话系统、问题处理系统、模型库、知识库、数据库和推理机组成,可以为指挥员进行干扰决策提供参考,主要功能包括预先决策、干扰资源配置和干扰方案拟定。孙宏伟等[18]在阐述了D-S证据理论的基础上,提出一种基于 D-S 证据理论的电子干扰模式选择方法,用以解决电子对抗设备如何选择干扰频率、干扰功率和干扰模式等重要问题。D-S证据理论[19-20]是一种信息融合的方法,其主要思想是在某一确定的雷达体制下,使用不同的干扰模式的干扰效果可以表示成干扰成功的概率形式,如表2所示。例如不同干扰模式(J1,J2,J3)针对某种体制雷达的干扰结果为(1,0,0),其意义是其中J1模式干扰成功率为1,其余模式的干扰成功率为0。

表2 各种干扰模式下干扰结果统计
表中aij即为各种模式下对不同雷达体制的干扰效果值。通过D-S证据合成法则[21],将不同种雷达体制对应的干扰模式的成功概率进行融合,通过融合后的结果选取干扰效果最好的模式。
2007 年,李文宫等在王杰贵等研究内容的基础上再次提出基于知识库和问题求解单元的智能决策支持系统(IDSS)的设计方法,着重细化了每个部分,并给出了 IDSS 中问题求解方法和整个系统的最终评估方式[22-23]。2009 年,在研究雷达对抗中敌我双方的参数、特征知识及知识表示的基础上,提出智能化雷达干扰系统中的 2 个过程自学习模型:雷达辐射源识别规则自学习模型和对敌雷达干扰策略自学习模型,为深入研究智能化雷达干扰系统提供模型基础[24]。2017 年吴剑锋等在分析国外智能干扰技术最新研究成果的基础上,提出了一种复杂电磁环境下的智能干扰系统架构,最后介绍利用遗传算法[25]作为智能干扰系统认知引擎的技术[26]。
基于决策支持系统的干扰决策方法较以往的决策方法成功率更好,干扰效果有明显的提升,适应性更加广泛,但是此种干扰决策方法太过依赖后验概率不具有实时性,且对于新出现的雷达体制,该方法便“束手无策”;且后验概率一经确定后续算法过程中不会再次改变,这就表示如果后验概率出现较大的误差,运用D-S证据法则没有及时“更新”该后验概率,则会造成严重的“误差累积”。
1.4 基于机器学习的干扰决策方法
将机器学习思想应用于雷达干扰决策这一思想提出的时间较晚,可供参考的研究资料比较少。
上述基于模板匹配的干扰决策方法、基于博弈论的干扰决策方法和基于决策支持系统的干扰决策方法都是依赖于充分的先验知识进行“匹配”,主要适用于特征参数不变的雷达。而机器学习的本质在于“学习和归类”,如图2所示。

图2 基于机器学习的雷达干扰决策模型框图
陈凯利用多功能相控阵雷达的特点,即雷达工作模式可以表现雷达对干扰方的威胁等级,有效干扰会降低雷达对目标的威胁等级,所以雷达状态的改变可以反映出干扰样式的优劣,提出了基于干扰方的干扰效果评估方法,在此基础上,干扰系统根据评估结果动态修正干扰知识库,构架了整个干扰决策体系,智能选择效果最佳的干扰样式[27],初步引入“认知”思想,对基于机器学习的干扰决策方法有一定的启发,但是论文中所用的方法还是基于决策支持系统,机器学习的思想体现的不是很充分。
基于机器学习的决策模型对于参数完全匹配的要求不严格且准确率高,该模型的样本集训练过程实质上是寻找一个映射:
f′∶χs→λs
(1)
机器学习的目的就在于构造一个函数f′,使得它尽可能逼近真实的f,从而尽可能提高决策的准确性。寻找f′的机器学习方法有很多,包括有监督学习,无监督学习,强化学习三大类。
强化学习[28]是专门针对于决策问题的一种机器学习算法。当机器处于环境E中时将某个动作a∈A作用在当前状态x上,则环境将从当前状态按照潜在的转移概率P转移到另一个状态,与此同时,环境会根据潜在的“奖赏”函数R反馈给机器一个奖赏。综合起来,强化学习任务对应了四元组E=〈X,A,P,R〉。所以此类方法不需要充分的先验知识,也不需要直接告诉机器在什么状态下必须做什么动作,只有等到最终结果揭晓,才会通过“反思”之前的动作是否正确来进行学习。图3是强化学习应用于雷达干扰决策的一个简单框图。
图3中S表示多功能雷达在某一时刻t的工作状态,r表示由于目标雷达工作状态改变从环境中得到的奖赏值,干扰机根据侦察到的目标雷达工作状态依据强化学习算法选择正确的干扰样式a并执行;根据得到的实际干扰评估值及实际战场环境,调整算法中的相关参数,实时地选择新的干扰样式。其中Q-学习算法是强化学习中的一种高效的免模型学习算法。

图3 强化学习用于干扰决策示意图
2015年李云杰将强化学习的思想引入雷达对抗[29-30],对比了Q-学习算法的Q值收敛过程和雷达对抗过程,设计了基于Q-学习算法的雷达干扰决策方法,总结了认知对抗实现中的关键技术难点,并仿真验证了雷达认知对抗中Q值的收敛过程以及先验知识对算法性能的改善情况,确定最具针对性的干扰策略,实现动态高效干扰。
朱斐等应用强化学习的思想,针对不稳定环境下的策略求解问题,利用MDP分布对不稳定环境进行建模,提出一种基于公式集的策略搜索算法-FSPS[31]。FSPS算法在学习过程中搜集所获得的历史样本信息,并对其进行特征信息的提取,利用这些特征信息来构造不同的用于动作选择的公式,采取策略搜索算法求解最优公式,并给出所求解策略的最优性边界。将FSPS算法用于经典的Markov Chain问题,实验结果表明,所求解的策略具有较好的性能。
2 展望
2.1 各干扰决策方法的利弊
综前所述,基于模板匹配的干扰决策方法是结构最简单的方法,且目前工程应用大多数是基于此类方法,但是此类方法也存在明显的不足;基于博弈论算法的干扰决策方法引入了“对策论”,为干扰样式的选取提供了新的依据,提高了决策准确率,但是也只适用于参数特征不变的雷达体制;基于决策支持系统的干扰决策方法初步引入“智能化”的思想,干扰样式的选取方式引入了“D-S证据合成理论”,增加了决策的准确率,但同样难以适用于复杂多变的现代雷达体制;
基于机器学习的干扰决策方法是基于“认知电子战”思想提出来的,大多数机器学习的方法都是选择以强化学习为基础,理论上强化学习可以不需要任何先验知识,所以完全适用于复杂体制、新体制的多功能相控阵雷达,也可以应对现代日益复杂的战场环境,所以基于机器学习的干扰决策方法必将是未来的发展趋势和主要研究方向。但同时,由于认知电子战中认知效能评估环节技术发展相对薄弱,而此类决策方法选择引入了干扰效果评估值作为指导下一次干扰的依据,所以此类决策方法尚存在技术不成熟的弱点。
2.2 基于Q-学习算法的干扰决策方法推广
多功能相控阵雷达工作状态为搜索时,可细化为远距搜索、近距搜索、低空搜索、立体搜索、边搜索边跟踪、搜索加跟踪等多种搜索状态,事实上,当多功能相控阵雷达的工作状态根据雷达工作的不同载频、重频、脉宽、带宽、脉内信息进一步细化成不同的工作状态时,有利于更加精确的进行干扰,干扰效果也会明显提高,但同时也会使得雷达状态明显增多,甚至会出现成百上千种状态,与之对应的干扰措施也会随之增加,此时传统的基于Q-学习算法的干扰决策方法通过建立Q值初始化表的方法[32]难以完成决策,且查询效率大打折扣。基于此,出现了一种基于深度强化学习[33-35](DQN)的雷达干扰决策方法。
DQN是一种融合了深度神经网络和强化学习的新的机器学习方法,也是为了解决传统强化学习无法解决大量状态的弊端所提出来的。其基本思想如图4所示,神经网络接收外界感知的雷达状态,经过其模型后直接输出该状态下可能选择的干扰样式以及估计的奖赏值,再根据强化学习的方法选出奖赏值最大的动作进行决策。

图4 DQN用于干扰决策简图
3 结论
本文总结了现阶段四类多功能相控阵雷达干扰决策方法的基本原理并分析了各方法的优缺点,基于机器学习的干扰决策方法可以适应日益复杂的现代战场环境,是未来发展的趋势的结论,其中基于Q-学习算法和DQN的干扰决策方法是主要的研究方向。
猜你喜欢
天然气与石油(2022年4期)2022-09-21
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
戏曲研究(2021年4期)2021-06-05
海外文摘·艺术(2020年22期)2020-11-18
北京航空航天大学学报(2020年10期)2020-11-14
智富时代(2018年9期)2018-10-19
智富时代(2018年9期)2018-10-19
岁月(2016年5期)2016-08-13
课堂内外(初中版)(2015年9期)2015-09-10
