
基于Landsat 8新邵县森林碳密度遥感反演研究
2019-10-31 03:39吴炳伦石军南
中南林业科技大学学报 2019年11期
吴炳伦,石军南,胡 觉,梅 浩
(1.中南林业科技大学,湖南 长沙 410004;2.国家林业和草原局中南林业调查规划设计院,湖南 长沙 410004)
在森林生态系统中,森林生物量是评价森林生态系统碳循环的重要载体和指标参数[1]。随着人类活动所引起的温室效应及其造成的全球气候变化对森林的负面影响正越来越引起全世界的关注。近年来,相关学者围绕不同林分、区域和国家尺度森林碳密度及变化开展了大量研究[2-5]。目前,森林碳密度的估算,常通过直接或者间接测定的森林植被生物量乘以含碳系数获得,但由于研究方法和数据源的不同,导致估算结果有很大的差异,概括起来主要有样地清查法[6]、经验模型法[7]、机理模型法[8]、半经验半机理模型法[9]和非参数估计等方法。随着信息技术的发展,非参数估计的神经网络以模拟人脑神经元进行抽象而成为主流。全局逼近网络有BP 神经网络[10-11],局部逼近网络有RBF、CMAC 小脑网络等。RBF 在网络结构的适用性、训练算法和网络资源的利用方面,其逼近精度、学习效率和分类能力上表现均比BP 神经网络优越[12]。RF 随机森林[13]也是一种基于机器学习的方法,具有随机性,对异常值和噪声具有良好的容忍度,且训练速度快,容易并行化计算。
本研究以新邵县为研究区,通过建立非线性回归、RF 随机森林和RBF 径向基神经网络进行森林碳密度反演。探究不同模型之间的精度,寻找最佳模型,进而为新邵县绿色发展提供参考。
1 研究区概况
新邵县位于湖南省邵阳市北部(27°14′37″~27°38′8″N,111°8′17″~111°49′57″E),介 于 邵 阳盆地和新涟盆地之间。全县总面积1 762.24 km2。属中亚热带大陆性季风湿润气候,常年盛行东北风,年平均气温为17 ℃,年平均总降水量1 365.2 mm。境内资江、湘江两条水系纵贯切割,地貌类型多样,呈北高南低,南向敞开,逐渐递降形态。
新邵县现有主要针叶树种为杉木、樟木、马尾松、黄山松、华山松、油松等,阔叶树种主要有檫木、银杏、油茶、枫香、栎类、楝树等,境内乔木树种面积为762.63 km2,占全县总面积的55.86%。主要经济树种为杉木、油茶、柑桔、板栗等。
2 材料与方法
2.1 遥感影像及样地数据预处理
2.1.1 固定样地数据
采用2014年湖南省森林资源一类调查数据。该数据以湖南省为单位,按照系统抽样的方法以4 km×8 km 的间距布设,每块样地呈正方形设置,面积为0.067 hm2。新邵县共布设57 块固定样地,采用一类固定样地调查的标准调查因子共64 项。森林碳密度的估算,分树种采用生物量回归方程估算的方法结合实测数据,再乘以相应树种含碳系数,从而得到固定样地碳密度数据。生物量回归方程(表1)采用李海奎[14]于2010年建立的生物量回归模型,分树种计算其地上生物量和地下生物量,对于不明确的树种,其生物量按照相近树种求算而得。

表1 不同树种生物量回归方程†Table 1 Biomass regression equation and carbon content rate of different tree species
2.1.2 遥感数据
采用Landsat 8 遥感影像,空间分辨率为30 m× 30 m,接收时间为2014年9月27日,轨道号124/41,数据质量较好,清晰且无云覆盖。数据预处理包括辐射定标、大气校正和地形校正,校正误差控制在半个像元之内(图1)。之后对预处理影像的7 个波段进行单波段、倒数运算、比值运算(2 波段、3 波段、4 波段组合间的比值运算),提取植被指数(NDVI、SAVI、ARVI、EVI)、纹理及地形因子共生成96 个遥感变量。
2.2 非线性回归模型
非线性回归是回归函数关于未知回归系数的非线性结构的回归。为探讨Landsat 8 遥感因子与森林碳密度之间的关系,首先,通过SPSS 20.0 分析反演因子与实测森林碳密度的相关系数,采用逐步回归分析和方差扩大因子法对自变量(纹理因子、光谱因子及衍生因子)进行筛选,寻找影响森林碳密度空间分布的主导因子,消除变量间的共线性问题。然后采用SPSS 20.0 提供的11 种拟合方法开展基于单变量的非线性回归分析,保留最优拟合模型。最后,在单变量最佳曲线模型拟合的基础上,以筛选后的变量为参考,逐步引入新的变量建立基于多变量的回归模型。
2.3 RF 随机森林模型
随机森林模型是一种基于分类树(Classification tree)的统计算法。具有较高的精度,高度灵活,对异常值和噪声具有很好的容忍度,不需考虑普通回归中面临的多重共线性,且不易出现过拟合。随机森林采用Bootstrap 重新抽样的方法构建分类树,因变量选择的随机性,每次构建的决策树可能不同,最后通过投票的方式选重复率最高的树作为最优模型。
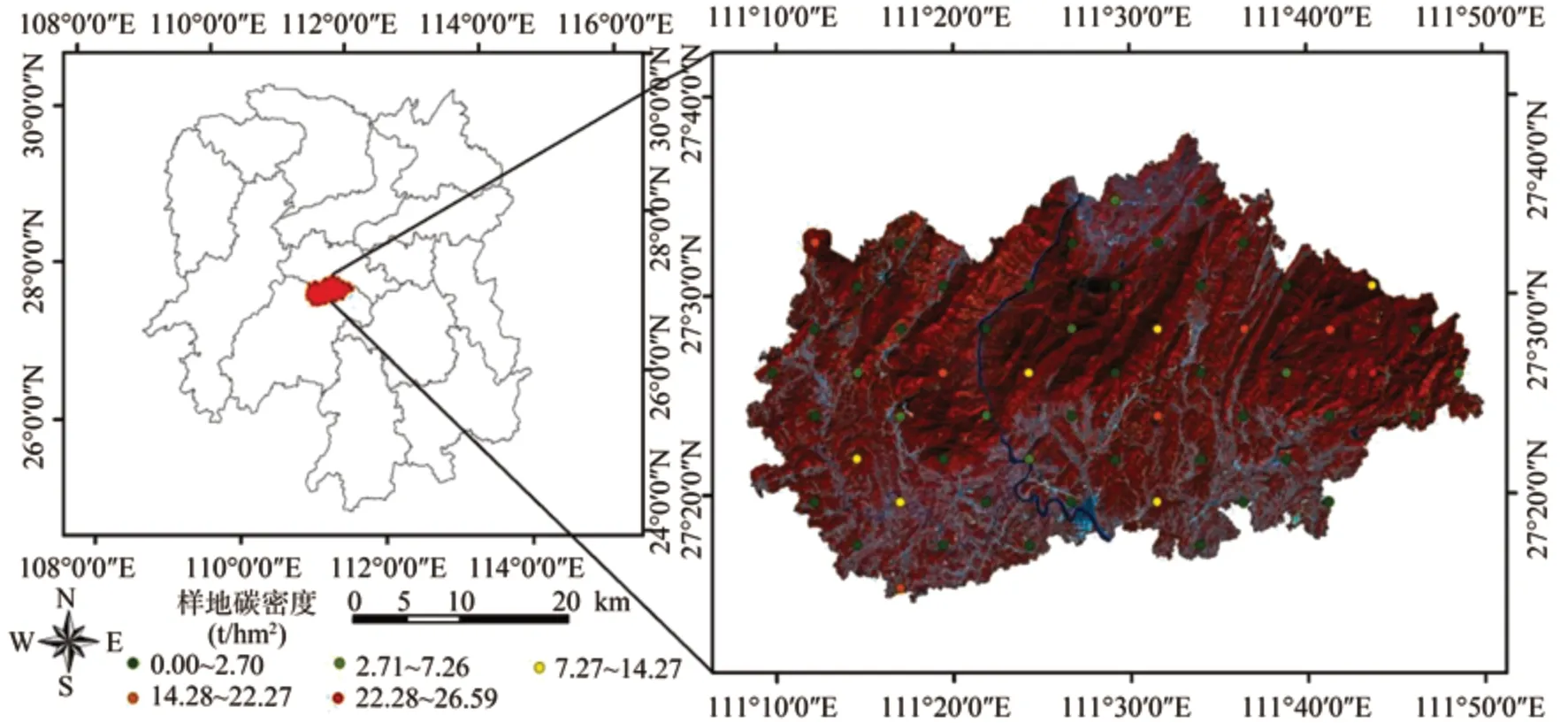
图1 新邵县位置及样地分布遥感影像Fig.1 Location of Xinshao county and remote sensing image of plot distribution
2.4 RBF 神经网络模型
径向基神经网络(Radical basis function)是一种性能优良的前馈型神经网络。以高斯函数为激活函数,具有任意精度的全局逼近能力;网络输出对隐单元的线性关系,从而避免了陷入局部极小的可能;采用局部逼近网络,相比“牵一发动全身”的全局逼近网络,拥有更快的学习和收敛速率。由输入层、隐含层和输出层搭建,输入层到隐含层由输入样本与隐藏节点之间的距离连接,隐含层用RBF作为隐单元的“基”构成隐含层空间,采用核函数的思想,通过调节隐含层到输出层之间的线性加权和来达到最优。
2.5 精度评价
模型精度是衡量预测方法是否适用于预测对象的一个重要指标。为了检验模型可靠程度的高低,对所建立的非线性回归模型、RF 随机森林模型和RBF 径向基神经网络模型通过决定系数(R2)和均方根误差(RMSE)进行评价。
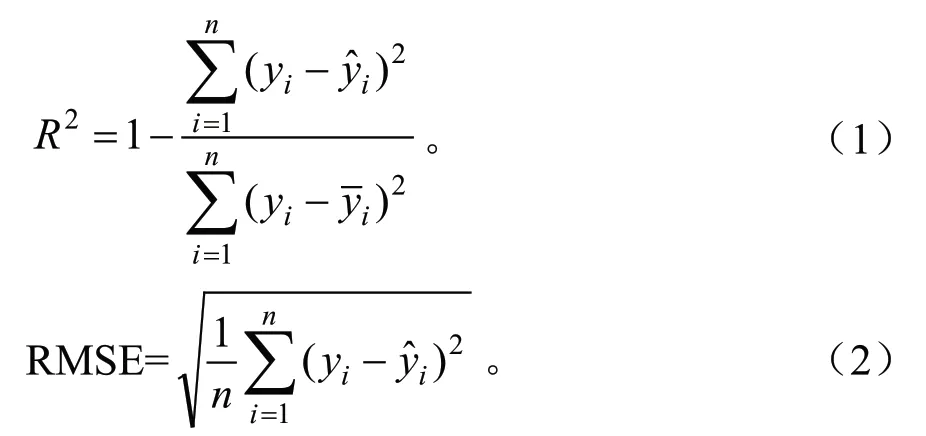
式中,n为检验样本容量,yi为第i个检验样本值,为 对应第i个样点估计值,为 检验样本值的平均值,决定系数(R2)指回归方程估测值与实测值之间的趋势线拟合程度,其变化范围为0~1,其中R2越接近于1,表明模型估测能力越强,效果越显著;RMSE 为总均方根误差,表示实测值与估计值之间的离散程度,其值越小,模型精度越高。
3 结果与分析
3.1 样地数据分析
通过对研究区57 块固定样地进行测算,得到新邵县固定样地碳密度统计结果(表2)。由表2可知,新邵县固定样地碳密度浮动范围介于0~26.59 t/hm2,标准差和变异系数分别为6.16、1.1,变异程度较大,表明数据波动较大。

表2 新邵县固定样地碳密度统计结果Table 2 Statistical results of carbon density in the sample plots of Xinshao county
3.2 变量筛选
为了获得影响森林碳密度估测的主要因子,采用SPSS 20.0 对提取的96 个变量采用逐步回归分析和方差因子扩大法进行筛选,计算其Pearson相关性(表3)。分析表可知,在显著水平0.01时,与森林碳密度达到显著相关的有Band3、Band2、Band1mean、NDVI 等25 个因子;当显著水平在0.05 时,H、Band4homogeneity、Band47、Band46共4 个因子与森林碳密度显著相关。其中Band3、Band4、Band14、Band4mean等17 个因子相关系数在0.500 以上,特别是Band3 的相关性达0.550。

表3 碳储量与自变量的相关性†Table 3 Correlation coefficients between carbon storage and independent variables
3.3 非线性回归预测
将显著性相关最强的28 个因子的像元值和57组样地碳密度数据导入SPSS 20.0 中,建立单变量最优曲线拟合模型,然后在单变量最佳曲线模型拟合的基础上,逐步引入多变量建立最优非线性模型:

最后,将57 组数据代入公式(3)中计算预测值,并对预测值结果与实测值进行分析,得到均方根误差为3.87 t·hm-2,其拟合结果与预测结果如图2、图3所示。结果表明,模型预测结果和实测值之间具有良好的线性拟合关系,决定系数R2为0.62,且残差点分布较为均匀,表明拟合模拟效果良好。

图2 非线性回归模型拟合结果Fig.2 Simulated results of nonlinear regression model
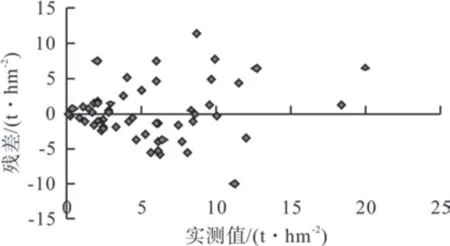
图3 非线性回归模型预测结果 Fig.3 Predicted results of nonlinear regression model
3.4 RF 随机森林预测
调用Matlab 函数包,分别设置ntree 为500、1 000、1 500、2 000,将57 组样本数据全部作为输入,采用留一交叉验证的方法训练,每个学习集都是通过除了一个样本以外的其它所有样本创建的,测试集是被留下的样本,直到所有样本数据都被测试一遍则停止训练,输出最优模型。经过不断测试,选取ntree 为2 000,mtry 为25,得到最佳逼近效果。模型决定系为0.91,均方根误差为2.50 t·hm-2,其拟合结果与预测结果如图4、图5。由图可知,样地实测值与预测值之间具有有较好的拟合关系,残差分布在[-8,8]之间。
3.5 RBF 神经网络预测
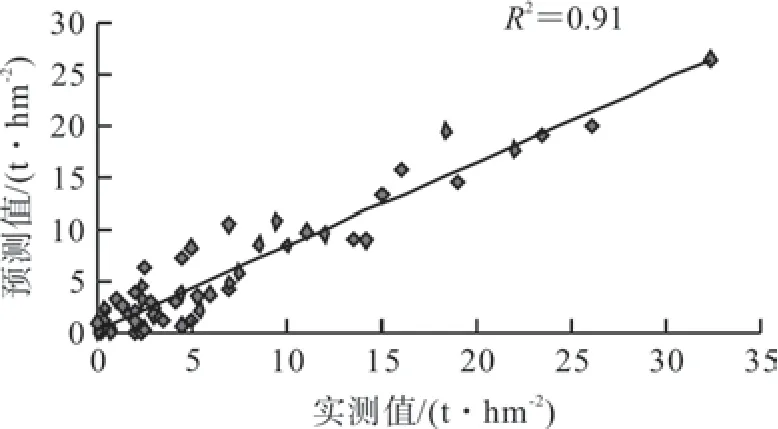
图4 随机森林模型拟合结果 Fig.4 Simulated results of random forest model
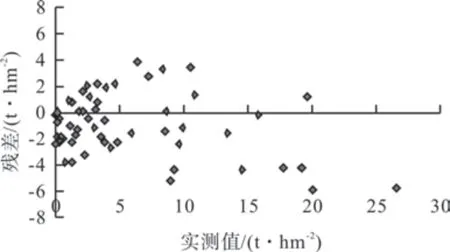
图5 随机森林模型预测结果 Fig.5 Predicted results of random forest model
在Matlab 中调用newrb 函数,相关参数分别设置为:goal=0.01;spread= 0.1、0.2、0.3、0.4;mn=200;df=1,通过不断调整函数参数、采用留一交叉验证的方法观察训练结果的步长来调整其收敛速度,最终选择spread=0.1,步长为42 为最优模型,拟合结果和预测结果如图6、图7。观察可知,样地实测值和预测值之间具有很好的线性拟合关系,R2为0.96,均方根误差为1.33 t·hm-2,残差分布表现为均匀分布在[-4,4]之间,说明模型具有良好的泛化能力。

图6 RBF 神经网络模型拟合结果 Fig.6 Simulated results of RBF model
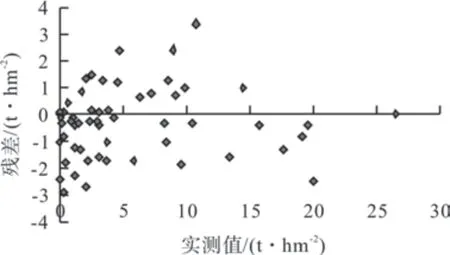
图7 RBF 神经网络模型预测结果 Fig.7 Predicted results of RBF model
3.6 模型比较
精度评价是评价模型估测能力高低的指示性指标。鉴于此,以R2、RMSE 为评价指标,对建立的3 个模型进行精度评价。由表4可知,RBF神经网络的决定系数最大,均方根误差最小,很好的拟合了样地实测碳密度;RF 随机森林次之,拥有不错拟合精度和均方根误差;非线性回归模型精度最低。
在建立的模型过程中,非线性回归模型通过逐步回归分析和方差因子扩大因子法选取Band34、Band3、ARVI 和Band47 共4 个因子参与建模。在RF 随机森林和RBF 神经网络建立的过程中,选取在0.01 水平以上显著相关的共28 个因子参与建模。然后通过ENVI 5.0 及Matlab 输入输出碳密度估计值。最后,利用ArcGIS软件生成森林碳密度反演图,图8(I)、图8(II)、图8(III)分别是非线性回归、RF随机森林模型、RBF 神经网络的碳密度反演结果。

表4 不同模型之间的比较Table 4 Comparison of accuracy by different models
4 结论与讨论
随着遥感技术的普及,遥感反演制图已普泛应用于林业领域。基于国家森林资源连续清查(湖南省第七次复查)的数据,建立非线性回归模型、RF 随机森林模型、RBF 径向基神经网络模型进行森林碳密度估计。然后对3 种模型进行比较分析,结果表明:
1)利用Landsat 8 数据进行森林碳密度遥感反演所提取的纹理、光谱及衍生因子中,Band3、Band4、Band14、Band4mean、Band1234、Band3mean、Band2 与森林碳密度具有显著相关性,其Pearson 相关系数达到0.5 以上。
2)RBF 神经网络的决定系数为0.96,均方根误差为1.33 t·hm-2,很好的拟合了样地实测碳密度RF 随机森林优于非线性回归模型,拟合精度、均方根误差分别为0.91、2.50 t·hm-2;非线性回归模型精度最低,决定系数和均方根误差分别为:0.62、3.87 t·hm-2。
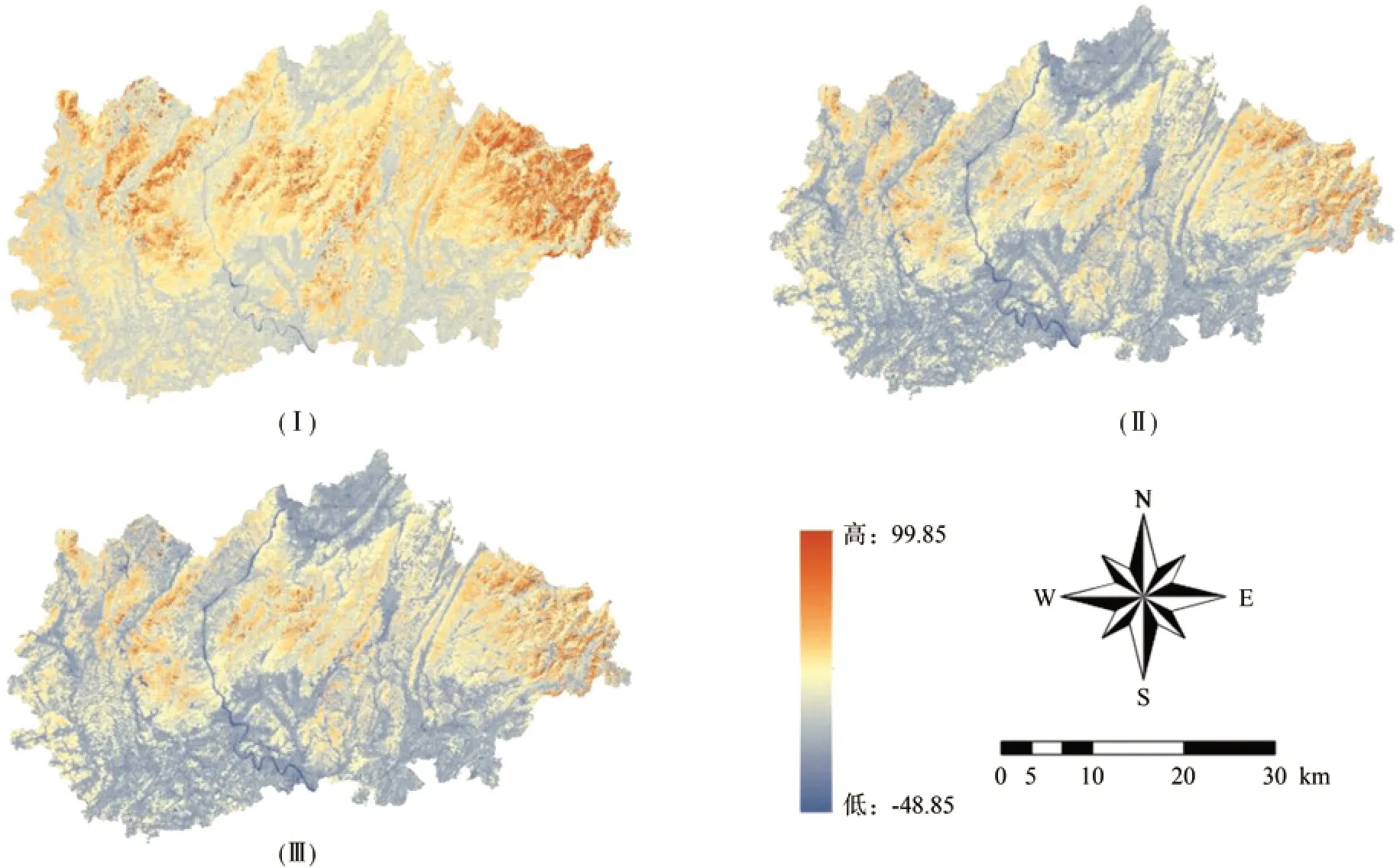
图8 新邵县森林碳密度反演结果图像Fig.8 Inversion results of forest carbon density in Xinshao county
3)RBF 径向基神经网络的精度最高,能很好的拟合样地实测数据的分布,这也验证了局部逼近网络虽无法揭示内部规律,但具有良好泛化能力与学习收敛速度。RF 随机森林表现良好,由其强随机性,模型得到较好的预测结果。受到样本数量的限制,但为大样本森林碳密度遥感反演提供了方向。
综上,研究区森林碳密度分布为南高北低,这与其实际地形地貌、森林分布一致。除了少数地区受到固定样本分布的影响出现异常点之外,普遍表现为与森林分布密切相关;另一方面,样地数据普遍偏小。可能在计算碳密度数据过程中,没有考虑灌木、草本层的森林碳储量多少,在之后样本的采集与研究方面将会继续深入,考虑灌木、草本层植被的影响提取大样本数据,采用混合像元分解的方法,为大尺度城市森林碳汇提供有力依据。
猜你喜欢
贵州畜牧兽医(2022年3期)2022-06-28
环境技术(2022年1期)2022-03-21
现代园艺(2021年23期)2021-12-01
安徽农业科学(2021年16期)2021-08-30
新农业(2020年18期)2021-01-07
科教新报(2021年47期)2021-01-03
现代园艺(2020年19期)2020-10-02
飞天(2019年6期)2019-07-08
南方农业·下旬(2018年9期)2018-01-03
新高考·高二数学(2015年2期)2015-05-27
