
基于卷积神经网络的面部图像修饰检测
2019-11-05 07:37王灿军陈嘉欣刘绪崇
应用科学学报 2019年5期
王灿军,廖 鑫,陈嘉欣,秦 拯,刘绪崇
1.湖南大学信息科学与工程学院,长沙410012
2.湖南大学大数据研究与应用湖南省重点实验室,长沙410082
3.湖南警察学院网络犯罪侦查湖南省重点实验室,长沙410138
随着数码相机和智能手机等电子设备的出现,生活中数字图像越来越普及.同时,Facebook、Instagram、Twitter 等社交媒体的发展也促进了数字图像的传播.各种功能强大的数字图像处理软件应运而生,如Adobe Photoshop、PortraitPro Studio Max、美图秀秀、GIMP、Snapseed 等,这些软件在为人们提供便利的同时,也给一些别有用心的人提供了造假的机会,照片编辑者可以轻松地改变人的外观.正是由于这些软件的便利性和广泛性,人们在网络平台上越来越难区分真实人脸图像和修饰后的人脸图像.如果这些经过人为修饰过的人脸图像被用于人脸识别,那么人脸识别算法可能会产生错误的结果,这将给人脸识别技术带来诸多负面影响,在图像取证领域被称为“检测图像篡改”[1-2].广告商和杂志编辑经常会对杂志中的模特图像进行修饰,使模特呈现出来的形象是完美的.然而这种图像可能会促使人们对自己的身体形象有不切实际的期望,从而扭曲人们的审美观[3-4].当试图效仿别人身份或企图隐藏身份时,人为修饰照片的过程则涉及欺骗和伪造,如果经过篡改的图像被广泛使用,将会给个人隐私、社会稳定、国家政治和经济等方面带来严重的负面影响.正如文献[5]中所描述的,媒体报道的用Photoshop 修饰过的超级名模图像给观众的心理带来了负面影响,为了避免种负面影响,有些国家规定,如果广告照片经过人为修饰必须声明,也就是通常所说的“Photoshop法”.因此提高面部修饰检测的精度具有重要的理论及现实意义.
目前以人脸面部图像为处理对象的研究已经成为计算机图像处理技术中的热门课题.对图像的润饰操作可以包括增加图像的亮度、改变图像的对比度、对人脸图像进行磨皮和去皱、去除老年斑、使眼睛变大、牙齿变白、鼻梁变高等.近年来,许多学者对图像润饰的各种可能操作也进行了一些取证研究,例如去皱和模糊等操作.文献[6]提出的图像润饰方法主要包括对图像的色彩校正、魅力和皮肤的修饰、照片重建等.
文献[7]通过使用模糊估计和异常色彩进行数字润饰图像取证.由于模糊操作能破坏图像中颜色通道的一致性,为此文献[8]先用模糊估计获取图像的模糊区域,然后对所获区域中的异常色彩进行检测,以此来确定人为的模糊区域.实验结果表明,该文献所提给出了方法能够精准定位篡改数字图像中的模糊区域.文献[1]给出了测算图像磨皮程度的度量标准,主要利用光学和几何学的变换计算图像磨皮的程度,再通过学习分类的方法将实际的磨皮程度与估计值做映射,然后对一般的图像修饰技术做建模定量,以此分析几何和测光修正的感知影响.一般情况下,这个度量标准能够客观地计算润饰图像与真实图像的偏差情况.文献[8]提出了一种利用高斯模糊核的恢复方法,该方法对原始图像与模糊图像之间的模糊不变量进行评估,从高斯模糊图像中鲁棒地恢复内核,从而区分原始图像和润饰图像.文献[9]提出图像润饰就是对图像进行增强操作的理论,通过调节图像的颜色、对比度、白平衡等改变图像的外形,以此去除掉图像中存在的皮肤瑕疵等问题.文献[10]提出了一种关于检测脸部瑕疵区域的算法.该算法以纹理定位域的Gabor 滤波响应作为图像特征,用GMM 表示正常皮肤与瑕疵皮肤的Gabor 特征分布,进而通过马尔可夫随机场模型合并它们的高斯混合模型分布与纹理定位的相邻像素之间的空间关系,最后通过期望最大化算法将正常区域皮肤与瑕疵区域皮肤进行分类.实验结果表明,所提算法可以有效地检测出人脸图像的面部皱纹,同时也能进行图像的修复工作.文献[5]提出了一种使用受限波尔兹曼机的检测方法.实验表明,经过人为修饰后的人脸图像变化幅度较大,容易干扰人脸的识别过程,导致人脸识别精度降低了25%,这对人脸识别技术的发展造成阻碍.因而该研究团队提出一种监督深度学习算法SDBM,以人脸区域的左眼、右眼、鼻子、嘴作为检测图像块对象来检测人脸图像是否经过人为修饰,识别精度达87%,同时也能进行化妆检测,检测率超过99%.文献[11]提出一种使用判别结构张量的方法来自动检测和修饰面部瑕疵.首先,可以通过显著模型的非线性结构张量区分对自动检测的面部瑕疵,然后在YCbCr 空间中搭建对应的高斯模型,通过OSTU 来精准化标记并去掉鼻孔、眼睛等区域,最后通过结构张量的图像修复算法对上述检测到的区域进行修饰,整个过程没有人工手动干预,全程自动化,润饰性能也比较令人满意.
本文用卷积神经网络进行人脸图像润饰检测,是因为卷积神经网络不仅能自动提取图像特征,还能自主学习图像输入输出之间的映射关系,而且能同时进行特征提取和分类,无需输入和输出之间的精确数学表达式,从而使提取的特征更加有效,有助于进行下一步的特征分类.另外,卷积神经网络相邻两层之间神经元是非全连接的方式,且具有权值共享的特点,从而具有更少的网络连接数和权值参数,大大减少了模型的学习复杂度,使训练过程变得更加容易,收敛速度更快.由于卷积神经网络在本质上是一种输入到输出的映射,只需用已知的模式对网络结构模型进行训练,网络便具有了输入输出之间的映射能力,避免了数据重建过程.本文从卷积神经网络的层次化、各层特征图数量和大小、卷积核大小等结构特点入手,设计特殊的CNN网络模型框架用于人脸图像修饰篡改检测.
1 卷积神经网络
卷积神经网络是一种训练深度网络的结构,该结构将神经认知机作为底层基础,同时利用反向传播算法实现手写数字识别、图像、语音、时间序列数据识别[12]等,尤其在手写数字识别中取得了良好的识别效果.传统的图像篡改检测方法通常是设计一个算法,并以此来采集图像特征,如图像的LBP 特征或HOG 特征等,随后再把特征传输给可训练的分类器,如SVM、Logistic 分类器等.但这些传统的图像篡改检测方法并不能解决目标图像因旋转、扭曲、比例变化、外界光照等造成的客观问题.文献[13]用较深层的CNN 模型在ImageNet 大规模视觉识别挑战竞赛中取得了最佳的分类效果,引起图像领域的科学家们对于卷积神经网络的关注,此后,CNN 在这个领域成功地跨出了重要的一步.
整个CNN 的训练过程[14]有正反向传播两种过程:正向传播过程主要提取隐层特征,是信息由网络的输入端向输出端流动的过程,包括卷积和池化两种操作方式;反向传播通过BP反向传播算法对误差值进行传递,再通过随机梯度下降算法更新权值参数,它是一个将误差分类信息向输入端流动的过程.反向传播的训练过程可以不断降低CNN 的误差值至收敛状态为止.CNN 的训练过程就是通过已有样本,求出一个能够得出最小化代价函数(计算样本的真实值和预测值之间的误差)的参数.
当工作信号正向传播时,假设当前第m层的第j个输出为,首先从第m-1 层的特征图里选择若干个特征图,组成第m层输入特征图集合Mj;接着利用卷积核分别与输入特征图中的每个map 即进行卷积并求和;然后加上基使用激活函数f,最后确定需要更新的权值,此时需要分别计算误差对它们的变化率.
当误差信号反向传播时,假设在CNN 中每个卷积层m后均有一个下采样层m+1,此时需要求出m层的每个神经元的灵敏度δ才可求出训练参数的梯度.为求m层的灵敏度,需将m+1 层灵敏度与连接权值相乘后求和,再求出与当前神经元节点m关于输入u的激活函数f的导数值.其中下采样层一个像素对应的灵敏度δ对应于第m层卷积层的输出map的一块像素(采样窗口大小),所以,需要进行上采样操作使采样层m+1 的大小与卷积层m的大小一致,均为up().通常下采样层的权值都取同一个可训练常数β,因此最后将上述得到的结果乘以β即为m层的灵敏度,公式为
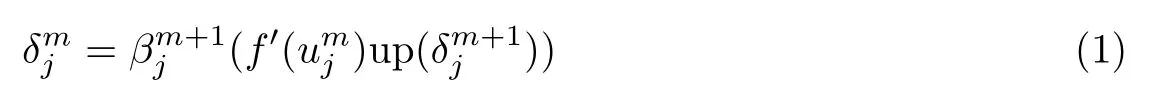
式中,up(·)表示上采样操作.接着对第m层中的灵敏度map 中所有的节点进行求和,可得到基的梯度为

然后再计算卷积核的梯度.对于一个给定的权值,对所有共享该权值点的连接求梯度后,对这些梯度进行求和
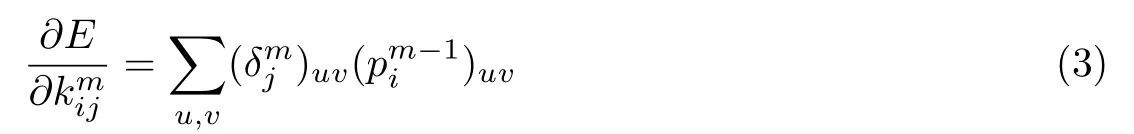
2 基于CNN 的人脸面部修饰检测算法实现
图1为人脸面部图像修饰前后对比图,在每对图像中,第一行为原始图像,第2 行为修饰后的人脸图像.在不知道原始人脸图像的情况下,仅通过肉眼观察修饰后的人脸图像是很难发现图像经过了篡改的.为了保证人脸图像的真实性,本文基于卷积神经网络实现人脸图像修饰检测.

图1 人脸面部图像修饰前后对比图Figure1 Comparison between cover image and tampered image
虽然卷积神经网络模型架构的设计多样化,但大多数卷积神经网络模型架构都是通过堆叠多个卷积层和池化层构建而成,各层只与自己上一层的神经元节点相连,这使得CNN 能够在前面几层中学习一些低级特征,然后再将学习到的特征转化为后续层中的高级特征,最后这些特征会被传递到完全连接层执行分类.与传统的神经网络一样,卷积神经网络完全连接层的每个神经元均连接到前一层的输出.多个完全连接层可以彼此堆叠以形成深层架构,通过训练完全连接层的神经元,获得每一类的类别分数,也就是类概率.对于卷积神经网络的改进可以进行许多工作,如对Loss 函数的改进可增加惩罚项,使得到的权值更容易稀疏化,也可以改变网络层级结构,从而改进神经网络.研究表明,影响CNN 性能的因素主要有3个:层数、特征图的数目、网络组织.本文主要调整网络的层级结构,改变网络中各层特征图的数量及核大小等以形成新的网络模型.
该模型由3个卷积层、2个最大池化层、1个全连接层组成,图像通过输入层(也称为数据层)进行CNN 训练,算法模型结构如图2所示.新的网络结构模型改变了每层特征图的数量和卷积核的大小.减少卷积核的大小可以在保证网络精度的前提下,减少网络模型的参数,保证在具有相同感知野条件下提升网络的深度,从而在一定程度上提升卷积神经网络的效果.另外,新的网络模型结构增加了最大池化层.这样一方面减少参数起到降维的作用,并降低计算的复杂度,提高网络模型的泛化能力,从而更好地分辨图像降低特征图的分辨率;另一方面最大池化层可以有效提取图像的纹理特征.其中,池化层是通过2×2 的滤波窗口作用于特征图像区域,随后提取窗口内的最大值并将其作为采样特征.
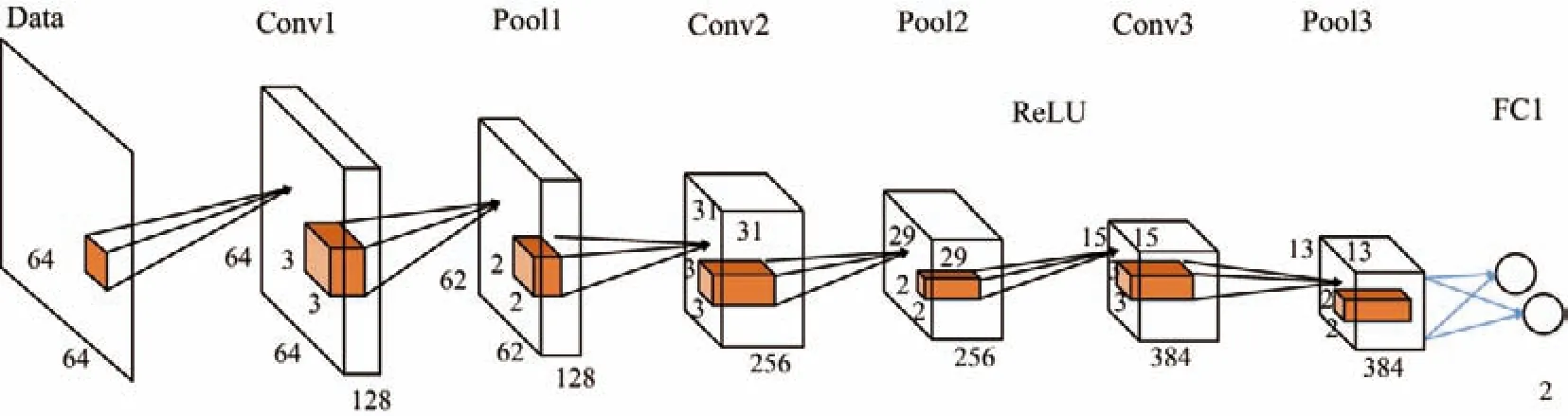
图2 Wang-Net1网络结构模型图Figure2 Network model of Wang-Net1
在Wang-Net1 模型中,输入图像的尺寸大小为64×64 像素,特征图的数量为128,即Conv1 输入大小为64×64×128.第1个卷积层Conv1 使用128个大小为3×3的卷积核进行卷积,Conv1 输出的特征图大小变为62×62 卷积后,经过一层最大池化层Pool1,特征图的大小减半为31×31.第2个卷积层Conv2 使用256个大小为3×3 的卷积核进行卷积,此时Conv2 特征图的输出为29×29×256.再经过最大池化层Pool2 后,特征图大小变为15×15.第3个卷积层Conv3 使用384个大小为3×3 的卷积核进行卷积,卷积后Conv3 的输出变为13×13×384.Wang-Net1 模型各层的输入大小、卷积核大小、特征图数量等参数情况如表1所示.卷积层之后通常使用非线性激活函数(sigmoid,tanh 等)处理特征图,以此获得非线性操作.但用不饱和非线性函数(non-saturating nonlinearity)不仅可以加快收敛速度,还能解决梯度消失问题.目前,在CNN 中常用的不饱和非线性函数主要是ReLU 函数.本文将ReLU激活函数应用于Wang-Net1 模型中的Pool2 层后,不仅具有单侧抑制性,使网络在训练时不易出现梯度消散且大型数据集上训练的大型模型能够快速收敛,而且还能获得较好的稀疏性输出.用ReLU 激活函数的CNN 模型比用其他激活函数的模型训练速度更快,能够较快达到收敛状态,大大节约了训练时间.

表1 Wang-Net1 模型各层参数汇总Table1 Parameters of Wang-Net1 model
2.1 Wang-Net2 卷积神经网络模型构造
Wang-Net2 卷积神经网络模型框架结构共包含12 层,如图3所示.该模型中包含了6个卷积层、3个池化层、3个全连接层.模型中卷积层分别用大小为3×3 和1×1 的卷积核,图像的输入大小为64×64 像素.第1个卷积层Conv1 使用128个大小为3×3 的卷积核进行卷积,第2个卷积层Conv2 使用256个大小为3×3 的卷积核进行卷积,第3个卷积层Conv3 使用384个大小为3×3 的卷积核进行卷积,第4个卷积层Conv4 使用384个大小为1×1 的卷积核进行卷积,第5个卷积层和第6个卷积层特征图的数量均为384,分别与1×1 和2×2 的卷积核进行卷积.在第1 层、第2 层、第6 层卷积层后均有一个最大池化层,其中池化区域大小为2×2,步长为2.在第1 层、第2 层、第3 层、第6 层卷积层后都有一层Relu 激活函数,且全连接层FC1 和FC2 后面均为dropout 层.
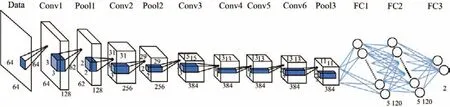
图3 Wang-Net2网络结构模型图Figure3 Network model of Wang-Net2
Wang-Net2 模型使用了1×1 大小的卷积核,一方面可以降低特征的维度,也就是压缩了通道数而不改变图像的宽和高;另一方面1×1 大小的卷积核给神经网络增加了非线性,从而提升网络的表达能力.在时间复杂度相同的前提下,具有更小的卷积核且深度更深的卷积神经网络结构比具有大卷积核且深度浅的结构获得实验结果更好.Wang-Net2 模型中,在第1层、第2 层、第6 层卷积层后加入了池化层,能够减少卷积层输出的特征向量,提高模型的训练速度,且不易出现过拟合的效果,从而大大改善训练效果.当在规模较大的神经网络中训练小数据集时,由于高容量不匹配,可能导致测试结果不理想[15].为避免训练中的过拟合问题,通常会在全连接层中采用正则化方法,即丢失数据技术(dropout).在Wang-Net2 模型中,全连接层FC1 和FC2 后均加入了dropout 层,含有dropout 的神经元并不会参与前向传播和反向传播,而会使隐层神经元的输出值为0 的概率变为0.5,减少了神经元之间的复杂协同适应性,进而学习更强大的功能,此外还可以有效降低过拟合的可能性而提高模型的适应性.在图3中,FC1 和FC2 具有5 120个神经元.输出层中有一个神经元对应到每个可能的分类,即每一张原始图像都对应一个神经元,每一张修饰后的图像也有一个神经元与之对应.本文研究针对人脸图像修饰篡改检测的二分类问题,故输出层FC3 仅有2个神经元输出,在FC 中应用Softmax 进行分类得到分类概率.
2.2 实验设置
2.2.1 实验平台搭建
本文所有实验均使用开源深度学习框架Caffe1.0[16](convolutional architecture for fast feature embedding).Caffe 深度学习框架研发出来以后,在伯克利大学进行发布,同时GitHub上的研究者们对框架研发也提供了很大的支持和帮助.Caffe 内部提供了MatLab 和Python接口,通过C++语言实现并采用CUDA 架构,可以训练常见的CNN 和深度学习算法,同时也支持CPU 和GPU 的计算.Caffe 的工具包可用于训练、测试、微调/部署模型.本文基于Windows 下的Caffe 框架,通过GPU 进行计算,且调用Python 接口.
2.2.2 实验参数设置
实验在存储器为12 GB RAM 的电脑运行,利用GPU 进行计算,实验之前将数据集转换成LMDB 格式,利用小批量随机梯度下降解决实验中所有的CNN.在训练阶段,批量大小batch 设置为64个图像,验证集的batch 设置为100个图像.动量值(momentum)固定为0.9,权重衰减(weight_decay)为0.000 5,基础学习率(base_lr)初始化为0.002,学习策略(lr_policy)为multistep,stepsize 为30 000,gamma 为0.2,最大迭代次数设置为120 000 次.
2.2.3 图像集构造
为了评估提出的Wang-Net1 和Wang-Net2 两个模型对人脸图像润饰检测的性能,首先分别建立一个未经修饰的图像库和经过人为润饰的图像库.实验采用ND-IIITD 修饰面部数据库[13]并自行采集人脸图像集Myimage1 和Myimage2.ND-IIITD 数据库是由一些欧洲人脸图像组成的,Myimage1 和Myimage2 主要由中国人的面部图像组成,其中Myimage1 数据库中的图像是背景相同的证件照,是由光源相同且用同一相机拍摄而成,Myimage2 数据库中的图像是由不同光源且用不同相机拍摄而成.由于欧洲人的面部皮肤状态和中国人的面部皮肤状态有差异,训练集采用ND-IIITD 库和Myimage1 库进行混合训练.用Matlab 工具以64×64像素为单位,通过从左至右和从上到下的方式依次裁剪原始图像,直接剔除小于64×64 大小的图像块,然后从裁剪后的图像块中挑选人脸皮肤部分的图像块.训练集图像库统计如表2所示,验证集图像库统计表如3 所示,测试集图像库统计表如4 所示.用专业软件Photoshop插件Portraiture 应用各种预设操作对原始图像进行篡改,这些篡改操作可以改变皮肤纹理、图像的对比度和亮度等.
本文以人脸皮肤图像块为检测对象能够检测出人脸是否经过人为修饰,图像块过大可能会造成少量人脸皮肤纹理模糊而难以被检测,图像块则很难被卷积神经网络所学习到,所以本实验确定图像块大小为64×64 像素.分别在图像库ND 库、Myimage1、Myimage2 这3个图像库上进行测试.图像库示例如图4所示,其中(a)为ND-IIITD 图库示例,(b)为Myimage1图库示例,(c)为Myimage2 图库示例.其中数据集中60%的图像用于训练CNN 模型,10%的图像用于验证模型精度,30%的图像用于面部图像修饰测试.每个图像样本都有对应的数字标签,分别组成训练集、验证集、测试集,选择已有的网络结构LeNet-5 模型与本文提出的Wang-Net1 和Wang-Net2 两个新模型进行对比测试.

表2 训练集统计情况Table2 Statistic of the training set
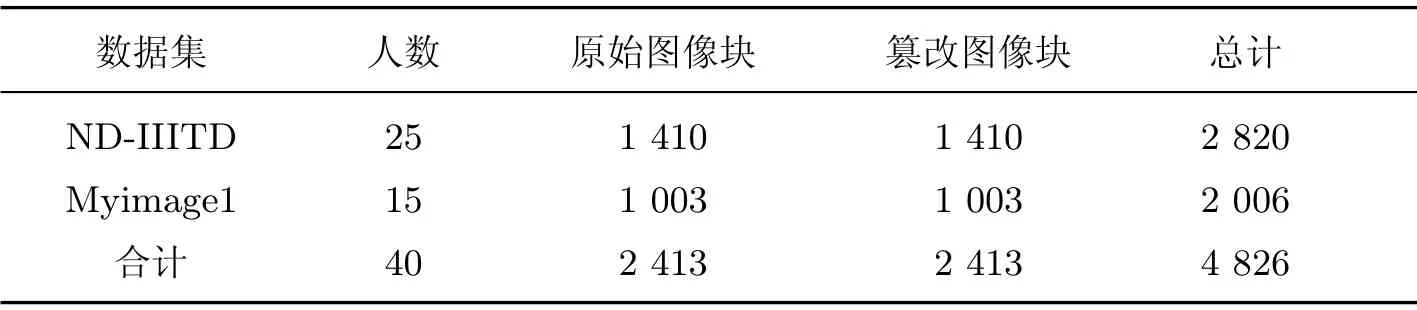
表3 验证集统计情况Table3 Statistic of the validation set
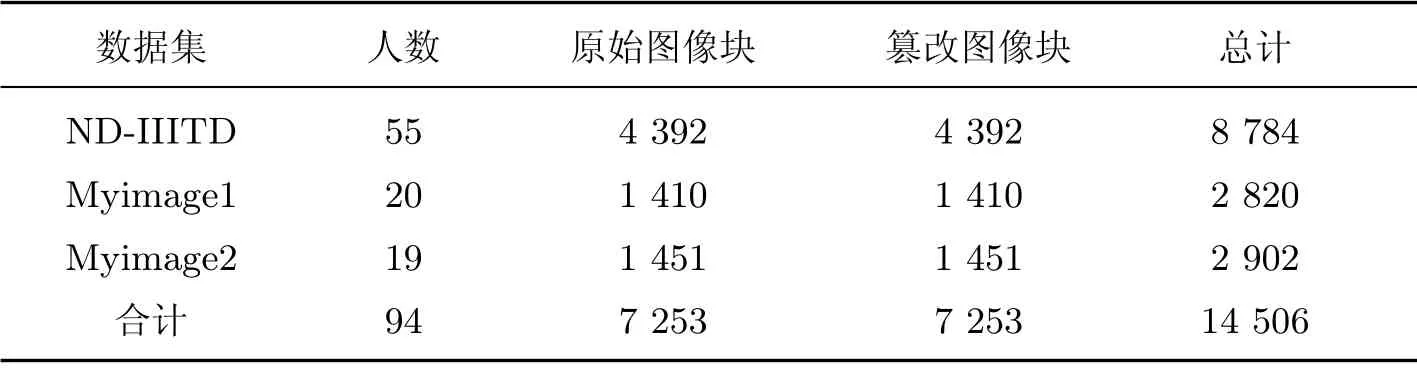
表4 测试集统计情况Table4 Statistic of the testing set
2.3 实验结果及分析
对CNN 模型进行训练时,采用同样的迭代次数、学习率、动量等参数且测试数据于输入数据没有任何重叠,分别在不同的预设操作和不同的网络结构下进行测试.表5中图像的阈值大小设定为默认值20,使皮肤变得更加光滑;表6在阈值大小为20 的基础上增大图像的亮度,将其由默认的0 设定为20,使人脸皮肤变得更光滑更亮;表7在表6的基础上同时增加图像的对比度,将其由默认的0 设定为20.

图4 图像库示例图Figure4 Diagram of image set
由上述实验结果可知,现有LeNet-5 网络模型与新提出的Wang-Net1 和Wang-Net2 网络模型均可有效地进行人脸面部修饰检测,且新模型的检测效果均比传统的卷积神经网络模型LeNet-5 的检测效果好.对比表5~7 的检测效果发现,在表7情况下篡改操作增多,网络模型检测效果降低,这是因为卷积神经网络对图像的亮度和对比度的检测不敏感,导致表7情况下检测效果比表5和表6效果弱.

表5 不同网络结构下的精度对比(预设1)Table5 Accuracy comparison under different network structures (preset 1)

表6 不同网络结构下的精度对比(预设2)Table6 Accuracy comparison under different network structures (preset 2)

表7 不同网络结构下的精度对比(预设3)Table7 Accuracy comparison under different network structures (preset 3)
以经过表5操作处理的人脸面部图像为研究对象,把该论文提出的新的卷积神经网络模型与传统的LeNet-5 网络模型及文献[1]中的方法进行了对比实验,比较结果如表8所示.
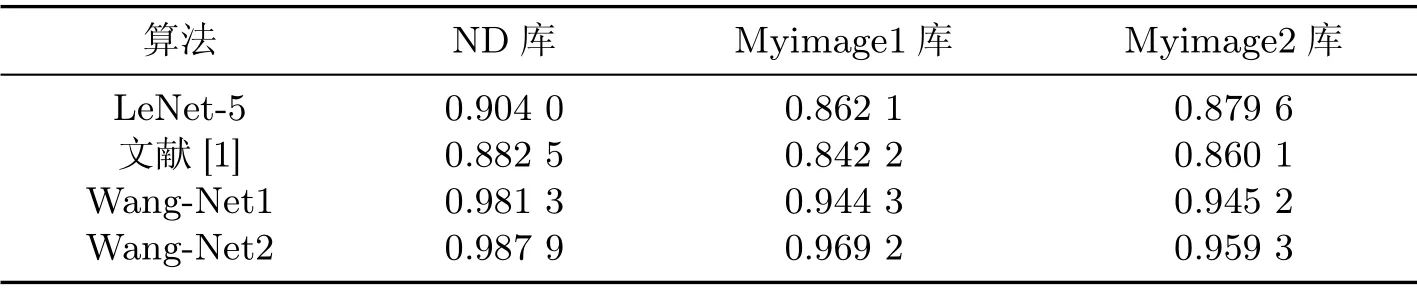
表8 不同算法的分类精确度对比Table8 Classification accuracy of different algorithms
由上述对比实验结果可知,新提出的卷积神经网络模型Wang-Net1 和Wang-Net2 比传统的卷积神经网络模型LeNet-5 和文献[1]方法的效果都要好,且准确率更高.
本文训练神经网络模型使用的迭代次数为12 万,图5分别表示在表5操作下不同的网络结构模型下验证精确度随迭代次数的变化情况.图6分别表示3个网络模型训练的误分类率随迭代次数的曲线变化图.可以看出,3个模型在训练过程中都能很快达到收敛状态,且新提出的Wang-Net1 模型和Wang-Net2 模型要比传统的LeNet-5 模型收敛速度快.
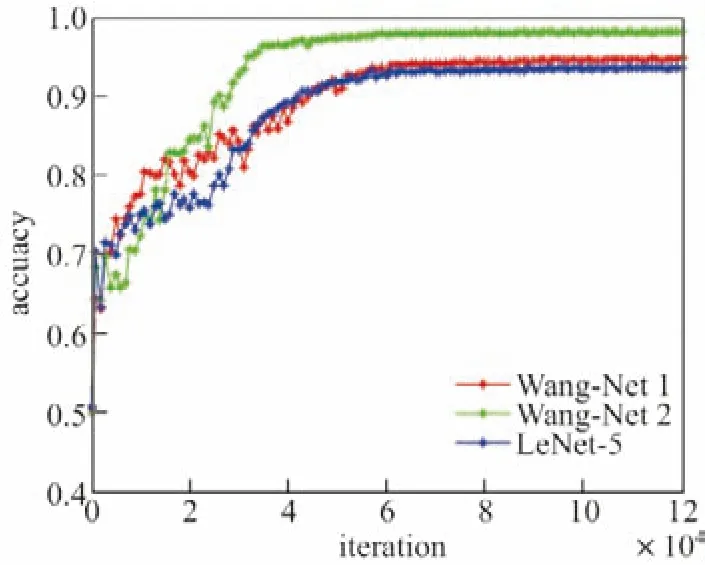
图5 验证精确度随迭代次数的变化情况Figure5 Verification accuracy with the change of iteration times
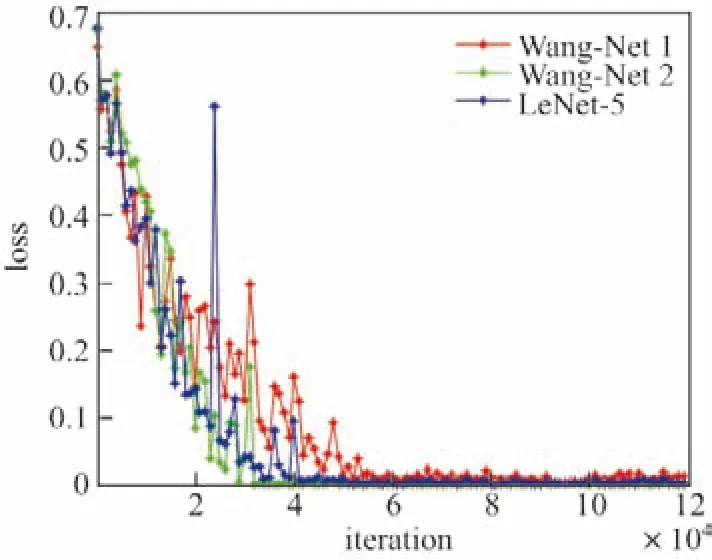
图6 误分类率随迭代次数的变化情况Figure6 Misclassification rate with the change of iteration times
2.4 单张人脸图像检测
从图像库中随机挑选1 张男性图像和1 张女性图像,应用表5操作对其进行面部修饰操作,修饰前后对比如图7所示,其中:(a)为未经任何篡改的原始男性图像,(b)为经过润饰后的男性图像,(c)为原始女性人脸图像,(d)为经过润饰后的女性人脸图像.对图7中的男、女人脸图像分别用LeNet-5 网络模型、Wang-Net1 网络模型、Wang-Net2 网络模型进行检测,检测结果如图8所示.图8中蓝色区域为检测结果正确的范围,黄色区域为检测结果错误的范围,对于随机挑选的男性人脸图像(a)中LeNet-5 模型检测的黄色块数为15,误分类率约为13.9%,图像(b)中Wang-Net1 模型检测的黄色块数为10,误分类率约为9.3%,图像(c)中Wang-Net2模型检测的黄色块数仅有3 块,误分类率约为2.8%.由此可见,LeNet-5 网络模型检测的误分类率最高,Wang-Net2 网络模型检测的误分类率最低.在女性图像(d)中,LeNet-5 模型检测到的黄色块数为17,误分类率约为2.7%,图像(e)中Wang-Net1 模型检测的黄色块数为13,误分类率约为2.0%,图像(f)中Wang-Net2 模型检测到的黄色块数为10,误分类率约为1.6%,即对于女性人脸图像,Wang-Net2 模型检测的误分类率最低,LeNet-5 模型检测的误分类率最高.由此可见,无论是现存的卷积神经网络LeNet-5 模型,还是新提出的卷积神经网络模型Wang-Net1 和Wang-Net2,都能有效地实现人脸面部图像修饰检测,也证明了卷积神经网络在面部修饰检测研究中的可行性和有效性.

图7 人脸面部图像修饰前后对比图Figure7 Comparison between cover image and tampered image

图8 不同网络结构下单张人脸图像测试效果图Figure8 Diagram of single-face image testing effect under different network structures
3 结 语
本文主要研究了基于卷积神经网络的面部修饰检测技术,建立了图像样本库并提出新的卷积神经网络模型Wang-Net1 和Wang-Net2.实验发现,本文提出的卷积神经网络模型在人脸面部修饰检测研究中具有高检测率和高鲁棒性,也证明了卷积神经网络在面部修饰检测研究中的可行性和有效性.在目前条件下仅能对人脸图像进行全局润饰篡改,但在实际操作中可能会对人脸图像进行局部的润饰篡改操作.因此,如何在局部篡改后的人脸图像中定位到篡改区域有待进一步研究.
另外,由于采集到的人脸面部图像数据集规模并不大,在训练时无法使用近几年比较流行的卷积神经网络模型AlexNet、VGG、GoogLeNet 与新提出的模型进行对比实验.这些网络模型要求输入图像的像素较大,导致分割图像样本较少,所以不能得到较好地训练.未来将采集更大规模的人脸面部图像数据集并用更多经典网络对大规模的数据集进行对比实验,经过大量图像样本的训练才能表现更好.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
