
光场图像基线编辑方法*
2019-11-12 05:41谢柠宇王建明王士同
计算机与生活 2019年11期
晏 涛,谢柠宇,王建明,王士同,2,刘 渊,2
1.江南大学 数字媒体学院,江苏 无锡 214122
2.江苏省媒体设计与软件技术重点实验室,江苏 无锡 214122
1 引言
随着消费级和工业级光场相机的快速发展,光场图像处理算法引起了越来越多研究者的关注。光场相机主要采用主镜头加微镜头阵列的设计方案,仅需一次曝光便可在单个图像传感器上记录下完整的四维光场信息。光场图像能够同时记录场景中光线的位置和方向信息,其保存的丰富三维场景结构信息可以支持各种核心的图像编辑任务,如图像重聚焦、图像拼接[1]、全景图生成[2]、立体透视图像生成[3]和立体显示等。
光场图像相邻子视点间的轴距(baseline)和子视点图像中心像素在图像传感器上的偏移量(shift)是两个核心参数,可以通过编辑这两个参数重构光场图像。通过移动单个相机拍摄一组规则的多视点图像[4]或者采用相机阵列的方案[5]可以获取一组光场数据。光场图像可以分解为一个二维的子视点阵列。相对于普通的多视点立体图像,光场图像分解得到的子视点之间轴距较小,图像的空间分辨率较低,且目前在光场相机硬件实现上尚无有效的解决办法。在进行光场图像编辑(如光场图像拼接,不同光场图像之间物体的拷贝和粘贴)和立体显示时,往往需要修改子视点之间的轴距。本文研究通过修改光场图像的轴距来实现光场图像的重定向。
光场图像新视点生成和图像内容修复/补全是同光场图像的重定向密切相关的两个研究问题。目前针对光场图像的超分辨率(角度和空间超分辨率)研究比较充分。其中角度超分辨率本质上是视点插值,尤其是视点内插已经能够得到不错的效果。但是,能够有效支持视点外插的算法非常少。另一方面,因为光场图像子视点之间的轴距的改变,可能导致光场图像子视点位置和旋转角度发生变化,会在子视点图像中引入去除遮挡后的区域,需要借助光场图像修复算法来进行修复/补全。
Wanner 等[6]提出了一个全变分框架实现光场图像的超分辨率新视点生成,Pujades等[7]在贝叶斯方法的基础上结合基于启发式的方法来得到新视点图像。近年来,不断涌现基于深度卷积神经网络(deep convolutional neural network,DCNN)的新视点生成算法。Yoon 等[8]提出了一个基于DCNN 的光场图像角度分辨率和空间分辨率增强算法,但是只实现了基于四个角上的子视点来生成两倍的角度和空间超分辨率效果。Kalantari等[9]提出了一个基于两个简单的DCNN模型的光场图像新视点生成算法。一个四层的DCNN 网络实现输入光场图像的视差图估计,另外一个四层的DCNN网络用于新视点合成。该方法受限于第一步得到的并不准确的视差图,且仅基于四个角上的子视点图像来实现视点内插。Wu等[10]提出了一个基于光场图像极平面图(epipolar plane image,EPI)超分辨来实现角度超分辨率的算法,引入了模糊和去模糊操作避免超分辨率过程中引入的图像锯齿和模糊效应,该方法无需依赖输入光场图像的视差图。Wang 等[11]提出了一个伪4DCNN 网络实现光场图像的角度分辨率增强,能够更好地利用光场图像子视点图像之间的关联信息。
针对光场图像修复/补全的研究工作相对比较少。Pendu等[12]提出了一个基于矩阵补全的光场图像修复算法,能够将中心视点修复的结果传播到光场图像的其他子视点。不过,因为中心视点的修复需要借助已有的2D 图像修复算法和用户交互,该算法适用于将单个较大的物体从光场图像中移除以后的背景修复,不适合光场图像重定向情况下对物体边界处众多较小孔洞的修复。Liu等[13]提出了一个基于部分卷积网络的2D 图像修复方法。Yu 等[14]提出了一个基于注意力图和生成式对抗网络的2D图像修复算法。上述两个算法均能在单张图像的修复上取得不错的图像修复结果。
本文提出一个基于深度神经网络的光场图像基线编辑方法,通过构建一个U型深度学习网络模型来实现基线编辑的光场图像重定向,对目标光场图像进行优化和修复,生成高质量的目标光场图像。
2 算法原理
本文算法主要包含三个步骤:(1)对输入光场图像进行预处理,使用光场相机标定算法获取光场图像的关键参数,并计算每个子视点图像的视差图。(2)对光场图像的每个子视点进行基于DIBR(depth image based rendering)的直接重定向处理,即将每个子视点图像投影到目标光场图像对应的子视点,得到基线编辑之后比较粗糙的目标光场图像。(3)构建一个深度神经网络模型来优化目标光场图像,实现对遮挡去除后区域的修复,得到子视点间图像内容一致的目标光场图像。在下列章节中,将对算法的每个部分进行详细介绍。
2.1 光场图像的标定和视差图计算
本文采用LFToolBox 工具[15]对光场图像L进行标定,获取所需的关键相机参数,如焦距f,相邻子视点间的轴距b和子视点在成像传感器上的偏移量ds。采用该分解方法得到的子视点光轴成汇聚关系,子视点的光轴相交于焦平面焦点位置。
为了对基线编辑后的光场图像进行重定向处理,即将基线修改为b′,除中心子视点外的每个子视点图像都需要三维透视投影到新的视点位置。因此本文算法需要得到每个子视点图像对应的视差图。因为现有的绝大多数光场图像视差图计算方法只考虑计算中心子视点的视差图,且有着较高的时间开销,采用基于结构张量和GPU 计算卡加速的从EPI中计算视差的算法[16]来获得输入光场图像的子视点的视差图。光场图像基线编辑示意图如图1所示。
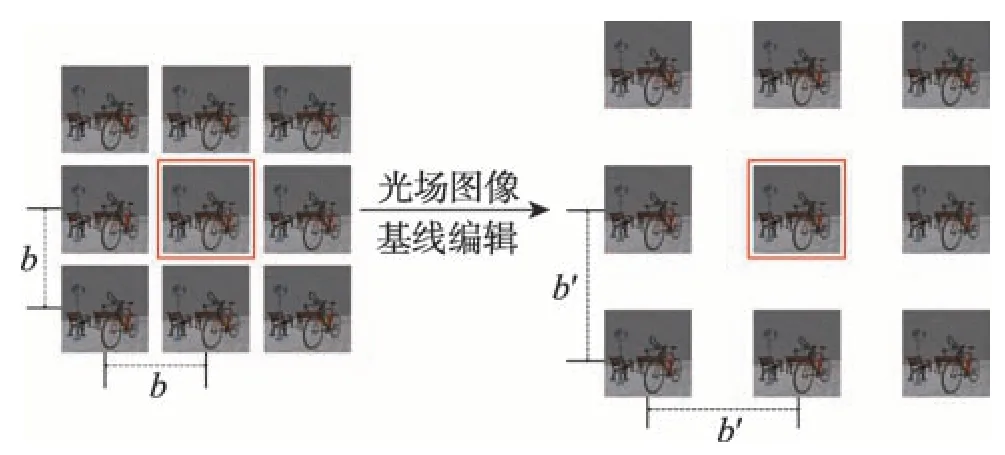
Fig.1 Overview of baseline editing for light field images图1 光场图像基线编辑示意图
2.2 光场图像的重定向
本文算法的目标是将光场图像的基线修改为b′,保持光场图像的焦平面距离不变,即f′d=fd,生成目标光场图像L′。基线编辑模型如图1 所示,左边为输入光场图像,右边为基线编辑之后的光场图像,中心子视点图像在基线编辑过程中位置保持不变,其他子视点图像位置变化为基线编辑后对应的子视点图像位置。
得到每个子视点的视差图以及相机参数后,使用DIBR的思想[17]将每个子视点图像进行透视变换得到初始目标光场图像。对于角度索引为(s,t)的子视点图像,其透视变换过程为:

式中,函数P-1将子视点图像v=L(s,t)中的一个像素p=v(x,y)投影到以该子视点位置为坐标原点的三维空间:

式中,(x0,y0)表示子视点图像中心点的像素坐标,d(x,y)表示像素p的视差值,f表示光场相机的等效焦距,ds为子视点中心像素在成像传感器上的偏移量参数[18],b为编辑前的光场图像基线。得到p的三维坐标后,通过透视投影函数P得到基线编辑后对应的子视点图像v′=L′(s,t)中的像素位置(x′,y′):
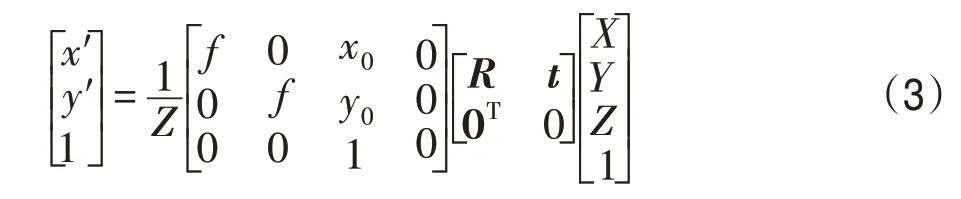
式中,t=[t1,t2,0]表示光场图像重定向过程中子视点位置发生的偏移量:

式中,(s0,t0)表示中心子视点图像的角度索引。R=RαRβ,因为固定焦平面不变,导致子视点需要绕X和Y轴旋转(如图2所示),其旋转量α和β分别为:


光场图像基线编辑后子视点图像对应的视差值表示为:

子视点图像在成像传感器上的偏移量ds和子视点图像焦距fd的关系定义如下:
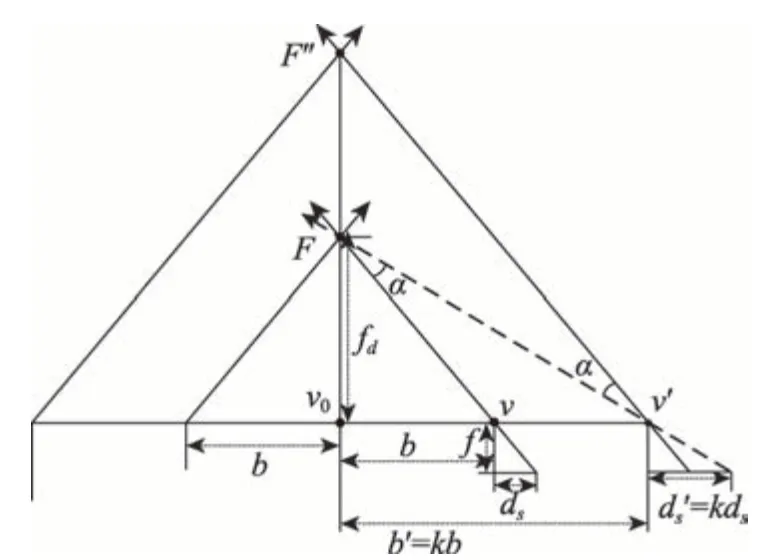
Fig.2 Changes of position and orientation of subaperture viewpoints for baseline editing in light field images图2 光场图像基线编辑中子视点位置和方向变化

2.3 基于深度学习的光场图像优化与修复
基线编辑后得到的初步光场图像容易出现内容空洞,主要有两方面的原因:一是基线编辑过程中由于子视点位置和方向发生变化导致原本被遮挡的区域变为可见区域;二是依赖于并不非常准确的视差图进行基于DIBR 的新视点渲染容易引入图像内容失真。目前基于深度学习的图像修复方法[19-20]都是以单张图像作为输入进行图像修复,但是光场图像子视点之间图像内容存在极大的相关性,2D 图像的修复算法并不考虑子视点图像之间内容的相关性。根据场景的差异,光场图像的基线修改之后,不同的场景存在内容空洞的区域位置和形状也不尽相同,需要神经网络能够处理不规则区域以及不确定位置的图像空洞。本文基于部分卷积的思想[13]设计了一种U型网络进行基线修改后的光场图像修复和优化。
部分卷积网络[13]的思想是仅对图像有效像素区域进行卷积操作,可以用于修复形状不规则的图像空洞。为了能区分图像的有效像素区域和空洞区域,将待修复图像的掩膜一起作为网络的输入,在卷积操作的过程中同时更新对应的掩膜作为下一个卷积层的输入。部分卷积的操作可以表示为:

式中,⊙表示矩阵对应元素的乘法。1/sum(M)作为一个比例因子,用于调整有效输入的变化量。在每次卷积操作后,需要对图像掩膜进行更新,如果卷积核区域内至少有一个有效像素,则该位置的卷积结果对应的掩膜置为1,表示为:

从式中可以看出,掩膜的更新规则会逐步消除空洞区域。在网络深度足够的情况下,可以修复任意大小的空洞。
本文提出的深度神经网络模型以光场图像的一行或者一列子视点作为输入数据,即三维极平面图像(3D epipolar-plane image,3D EPI),这使网络可以充分挖掘光场图像记录的场景深度和遮挡等信息,而无需显示的输入或者计算输入光场图像的视差图。同时利用一组子视点图像包含的冗余信息,每个视点的图像的语义信息,以及场景的深度信息来提高图像修复的质量。以一整行的输入为例,对于一个待修复的光场图像L(x,y,s,t),固定一行的子视点图像可以表示为
通过多次实验发现直接使用同一行或一列子视点堆叠构成的3D EPI 作为输入,神经网络输出的连续子视点图像颜色与真值相差过大。因此为了减少不同通道颜色之间的干扰,将原本一行的子视点图像的颜色通道进行重排列,首先将所有的R通道拼接在一起,其次是G通道,最后是B通道,即:

式中,函数A表示子视点图像的颜色通道重排列操作。子视点图像对应的掩膜也进行类似操作,通道重新排列后的子视点图像及其掩膜通过网络的生成器得到修复后的结果:

式中,Gp表示卷积神经网络的修复和优化过程。
本文网络结构如图3 所示,输入分为两部分,一部分是一行(列)颜色通道重排列后的子视点图像,大小为512×512×27,另一部分为同样大小的对应掩膜。网络可以分为编码器和解码器两部分,前面7层为编码器,使用部分卷积代替了传统网络的卷积操作,每个卷积层后接一个Relu激活函数,之后接了一个BN(batch normalization)层对数据进行归一化处理后作为下一层的输入。解码器部分首先对上一层的结果进行上采样(本文使用的是最近邻采样),将上采样的结果与编码器部分对应的输出进行跳级连接,然后对连接的结果进行步长为1 的卷积操作,解码器每个层的卷积操作都后接一个α为0.2 的LeakyRelu 激活函数。网络的输出大小与输入一致,为512×512×54,需要经过通道的重排列,恢复成一行(列)单独的子视点图像。原网络[13]的输入为单张图像,信息量有限,仅依靠U型网络难以获取足够的图像纹理特征,因此在设计损失函数时借助VGG 网络[21]结构以提取高层的视觉感知特征,计算风格损失与感知损失[22]。本文所提算法针对光场图像进行处理,子视点图像之间具有丰富的纹理结构相关信息。本文修改了U 型网络输入数据为一列光场图像子视点(9张子视点图像),可以使网络学习到足够的图像纹理特征,因此本文去除了原网络中的风格损失与感知损失。实验结果表明,去除风格损失和感知损失后对结果图像的质量并没有明显的影响。由于在计算损失函数时少了一个VGG 网络,网络训练的速度得到大幅度的提高,同样为1 200 的训练次数,网络的训练时间降低到28 h。

Fig.3 U-shaped DCNN model for baseline editing图3 U形深度神经网络光场图像基线编辑模型
修改后的损失函数由两部分组成,分别为有效像素区域生成图像与真值的L1损失Lossvalid和空洞区域生成图像与真值的L1损失Losshole:

式中,每个单独的损失函数定义为:

式中,Vgen表示网络生成的图像,Vgt表示图像的真值。λ1和λ2的取值通过对比不同权重设置下的实验结果质量来最终决定,在本文实验中,λ1=1,λ2=6。
3 实验结果
神经网络的训练需要大量的数据集,使用LytroIllum光场相机采集的真实光场图像其基线是单一和固定的,且相机参数精确标定和高质量视差图获得有一定的难度,因此难以用光场相机大规模采集真实场景数据作为神经网络的训练数据。本文采用Blender(https://www.blender.org/)软件作为网络训练的数据来源,主要有两方面的优势。一是Blender可以直接获取光场图像每个子视点图像对应的视差图,无需额外的视差图计算算法;二是Blender软件在获取更改基线后的光场图像时只需要简单调整相机参数便可以渲染相应的光场图像及其视差图。本文渲染了13 个不同的场景共计88 组光场图像数据作为训练数据,每组光场数据包含原始基线下的光场图像以及编辑为2倍基线的光场图像,每组数据光场图像的空间分辨率均为512×512,角度分辨率均为9×9。其中75 张光场图像用于神经网络训练,对应的2倍基线的光场图像作为真值,3个用于评估模型,剩下10个图像用于测试。本文同时利用了少部分斯坦福真实场景光场数据集(http://lightfield.stanford.edu/lfs.html)中的图像对本文的深度神经网络模型进行训练。本文在Titan X GPU上进行网络的训练,训练次数为1 200,初始学习率设为2E-4。

Fig.4 Initial results of baseline editing for synthetic light field images图4 虚拟光场图像基线编辑的初步结果

Fig.5 Initial results of baseline editing for real light field images图5 真实场景光场图像基线编辑的初步结果
基线编辑后的光场图像重定向结果如图4和图5所示(第一行为输入光场图像的子视点图像,第二行为重定向后对应的粗糙子视点图像(绿色标注区域为遮挡去除后的空洞),第三行为第一行子视点对应的视差图)。由于篇幅有限,本文只选取距离中心子视点最远的子视点图像进行展示,即角度坐标索引为(-4,-4)的子视点图像。光场图像的核心参数(如修改前基线以及修改后的基线)如表1和表2所示。
3.1 合成光场图像结果对比
本文将合成光场图像的基线编辑结果与全变分优化[6]、基于贝叶斯的新视点生成算法[7]结果进行对比。同时,本文算法与基于单张图像的神经网络修复算法[13-14]进行比较。实验结果如图6~图11所示,其中(a)为文献[7]得到的结果,(b)为文献[6]得到的结果,(c)为文献[14]得到的修复结果,(d)为文献[13]得到的结果,(e)为本文算法得到的结果,(f)为基线编辑后子视点的真值图像。

Table 1 Parameters of synthetic light field image表1 合成光场图像的参数
从结果图像可以看出,基于贝叶斯的新视点生成算法结果图像容易产生纹理的缺失和混乱,如图8中熊的脚部放大细节和图1中自行车的细节,并且在物体的边缘处容易产生模糊和大量噪声。本文算法结果能较好还原图像的纹理细节,不存在明显的噪声现象,具有较好的视觉效果,但是可能在较大空洞区域的边缘会产生一个轻微的伪影,这是目前深度学习方法面临的一个共性问题。

Table 2 Parameters of real light field image表2 真实光场图像的参数

Fig.6 Comparison of light field image retargeting results(scene1)图6 光场图像重定向结果比较(场景1)

Fig.7 Comparison of light field image retargeting results(scene 2)图7 光场图像重定向结果比较(场景2)

Fig.8 Comparison of light field image retargeting results(scene 3)图8 光场图像重定向结果比较(场景3)

Fig.9 Comparison of light field image retargeting results(scene4)图9 光场图像重定向结果比较(场景4)
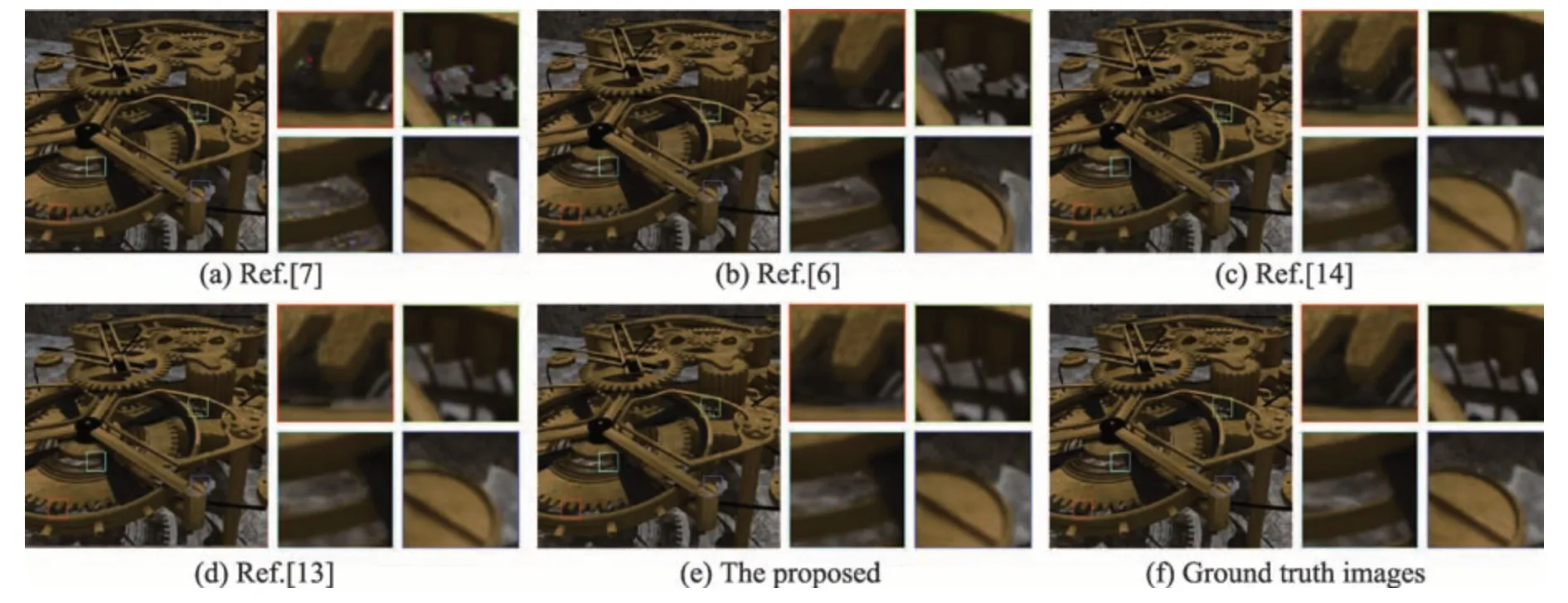
Fig.10 Comparison of light field image retargeting results(scene5)图10 光场图像重定向结果比较(场景5)

Fig.11 Comparison of light field image retargeting results(scene6)图11 光场图像重定向结果比较(场景6)
实验结果表明,基于单张图像的神经网络无法充分学习光场图像子视点之间图像内容的相关性,在空洞区域的纹理生成时,容易产生纹理预测错误和叠影现象,如图6 中路灯的灯柱和图9 中书架边缘。相比之下,本文提出的深度学习算法框架能正确修复目标光场图像空洞区域的纹理细节。
本文通过计算不同结果图像子视点的平均峰值信噪比(peak signal to noise ratio,PSNR)和平均结构相似性(structural similarity index measure,SSIM)对不同的算法结果进行定量分析。定量分析见表3。从结果可看出,本文所提算法在大部分数据的数值上远远高于对比算法。定量分析结果表明,本文算法在合成场景数值上高于对比算法,具有更好的修复准确度,可以看出所提算法的有效性。
3.2 真实光场图像结果对比
真实场景的光场图像往往场景内容更为复杂,子视点图像和视差图含有相当的噪声,导致处理起来更加困难。本文将真实光场图像的基线编辑结果与全变分优化的新视点生成方法[6]、基于贝叶斯的新视点生成算法[7],以及基于单张图像的神经网络修复算法[13-14]的结果进行对比,实验结果如图12~图16所示。
实验结果表明,本文算法在真实图像上也具有较大优势,在视差图有大量噪声与错误的情况下也能获得较好的视觉效果。基于贝叶斯的新视点生成算法在真实场景上容易出现纹理与结构上的破坏,如图12中的推土机尾部,并且伴随着大量噪声,如图16中的叶子区域以及图13中的车头后视镜区域。基于单张图像的神经网络则容易出现色彩上的误差,如图14的天空和图15的椅子背部。

Table 3 Quantitative analysis of synthetic light field image baseline editing results表3 合成光场图像基线编辑结果定量分析
本文通过计算不同结果图像子视点的平均PSNR 和平均SSIM 对不同的算法结果进行定量分析,如表4 所示。定量分析结果表明,本文算法在真实场景数值上高于对比算法,具有更好的修复准确度,能够适应较为复杂的场景结构,对子视点和视差图噪声/错误具有较好的鲁棒性。

Fig.12 Comparison of light field image retargeting results(scene 7)图12 光场图像重定向结果比较(场景7)

Fig.13 Comparison of light field image retargeting results(scene 8)图13 光场图像重定向结果比较(场景8)

Fig.14 Comparison of light field image retargeting results(scene 9)图14 光场图像重定向结果比较(场景9)

Fig.15 Comparison of light field image retargeting results(scene 10)图15 光场图像重定向结果比较(场景10)

Fig.16 Comparison of light field image retargeting results(scene 11)图16 光场图像重定向结果比较(场景11)

Table 4 Quantitative analysis of real light field image baseline editing results表4 真实光场图像基线编辑结果定量分析
4 结论和展望
本文提出了一种基于深度神经网络的光场图像基线编辑方法,使用光场图像一行(或一列)的子视点图像堆叠成3D EPI并将不同子视点相同的颜色通道排列在一起作为神经网络的输入,进行基线编辑后目标光场图像的重构和优化。本文提出的深度神经网络模型能够实现基线编辑的光场图像重定向处理,对重定向过程中因遮挡去除产生的空洞区域可以实现快速准确的图像修复和优化,得到具有较好准确度和视觉效果的结果图像。提出的光场图像基线编辑方法能够服务于一系列光场图像编辑应用,如光场图像拼接、不同场景光场图像的物体拷贝和复制、合成立体图像和光场图像显示等。
本文提出的进行目标光场图像优化的DCNN模型主要基于合成光场数据进行训练,能够有高质量的视差图和目标光场图像真值来方便模型的训练。但是,真实场景得到的光场图像往往场景更为复杂,面临子视点存在噪声和视差图可能很不准确等问题,会影响光场图像重定向的结果图像质量。下一步需要研究改进本文的深度学习模型和训练方法,争取在真实场景光场图像上取得更好的实验结果。同时,研究对光场图像的另外一个非常重要的参数ds实现有效的编辑。
猜你喜欢
计算机应用与软件(2022年1期)2022-01-28
小型微型计算机系统(2022年1期)2022-01-21
计算机与数字工程(2020年11期)2020-12-23
疯狂英语·新悦读(2020年6期)2020-06-28
兵器装备工程学报(2020年2期)2020-03-23
光学仪器(2017年1期)2017-04-10
环境(2016年7期)2016-05-14
新闻前哨(2015年2期)2015-03-11
国外科技新书评介(2014年7期)2014-12-01
摄影之友(2014年3期)2014-04-21
