
可变属性粒度的中文文本概念格聚类研究
2019-11-17 04:05吴湘华曹丽君
电脑知识与技术 2019年26期
关键词:特征词
吴湘华 曹丽君
摘要:传统的中文文本聚类方法需要将半结构化或非结构化的数据构建数学模型,一般情况下都要进行降维处理,这些操作均会带来一定失真,影响聚类的准确性和效果。该文以待聚类文本为研究对象,以文本特征词为属性,引入形式概念分析理论,采用概念格聚类的方式对中文文本进行聚类,同时,将特征词匹配至可变属性粒度的属性树上,避免因为属性粒度过细导致聚类速度慢的问题,该算法聚类效果良好。
关键词:中文文本聚类;形式概念分析;概念格;可变粒度;特征词
中图分类号:中图分类号:TP319 文献标识码:A
文章编号:1009-3044(2019)26-0027-02
开放科学(资源服务)标识码(OSID):
针对文本数据进行数据挖掘与知识描述、知识发现的过程统称为文本挖掘。随着信息时代的日益发达,许多信息都是以文本的形式出现,與传统数据挖掘中不同,文本是一种半结构化或者非结构化数据,文本挖掘成为数据挖掘领域中的一个热点,同时也是一个难点。文本数据一般具有高维度,一些传统的数据挖掘方法在文本挖掘中往往无法获得良好的效果。文本聚类技术[1]是文本挖掘中非常重要的一个方向,通过对文本之间的相似性挖掘,将相似的多个文本对象划分至同一个类别,不相似的文本对象划分至不同的文本类别中,最终将混乱的文本整理成为多个规范的文本集合。通过文本聚类,可以实现多文档自动文摘[2]、信息过滤[3]、搜索结果进行聚类[4]、 数字图书馆推送服务[5]等。
1 中文文本聚类
中文文本聚类是以中文文本为对象的文本聚类。在中文文本聚类之前,需要做一系列预处理工作,预处理一般包括分词、去停用词、词条标准化、特征词提取等等。中文文本预处理之后,将用一组特征词代替原始文本,文本预处理过程会导致一定的失真,不同的预处理方法对后续的聚类会产生不同的影响。中文文本除了用标点分隔句子之外,每一句话的词与词间是连续的,不存在明显的分隔符号,必须进行分词处理,分词处理技术一般有基于词典匹配的分词法、基于理解的分词法和基于统计的分词法等。停用词是在文本集中出现对文本特征词提取没有意思的词,且这些词出现频率较高,在所有文本中具有近似的分布概率;通过构建一个停用词表,删除文本集中出现的停用词,这个过程就叫作去停用词。中文对同一个事物的表述往往有很多种方式,如“电脑”和“电子计算机”表述的是同一事物,为此,文本通过分词与去停用词后,需要将词条进行规范化,将不规范的自由词替换为标准词,通过去停用词和词条标准化后得到的词条集合能够更加精准的反映原始文本、降低维度、提高文本聚类的精度和效率。经过上述处理之后,就要采取一定的算法提取出合适数量最能代表和概括文本特征的特征词,一般使用评估函数进行特征词的提取,用评估函数对词条进行赋值,并选取一定数量得分较高词条特征词提取的结果。文本一般都是半结构化的或者非结构化的,无法直接聚类,先要建立一个形式化的数学模型有效的反映原始文本的特征,常用的有布尔模型、向量空间模型、概率型等。接下进行聚类分析,常用的有K-means算法、EM算法、层次聚类算法等,但是这些聚类对文本聚类效果没有明显的突破和创新。
2 概念格聚类
Wille教授[6]提出基于序理论的形式概念分析理论。具有自反性、反对称性、传递性的二元关系称为偏序关系,集合N及其上的偏序关系≤组成的有序二元组称为偏序集。格是一种特殊的偏序集,一个偏序集中,集合N中任意两个元素都存在上确界和下确界,我们称该偏序集为格;完全格则是格的特例,对于任意偏序集的子集都存在上确界和下确界,则该格称为完全格。形式背景是一个三元组K=(G,M,I),G表示对象集合,M表示G中对象所有属性的集合,I是集合G和集合M笛卡尔积的子集,[(g,m)∈I]表示对象[g]具有属性[m]。集合A是集合G的子集,则将集合A中所有对象的共同属性定义为A,集合B是集合M的子集,将含有B集合中所有属性的对象集合定义为B,且A=B,B=A,则称(A,B)为形式背景K的一个概念,β(G,M,I)是背景K上所有概念集合。若(A1,B1)和(A2,B2)分别是形式背景K的两个概念,若A1包含于A2等价于B2包含于B1蕴含A1包含A2则称(A1,B1)是(A2,B2)的子概念,(A2,B2)是(A1,B1)的超概念,记为(A1,B1)≤(A2,B2),为偏序关系。将形式背景K上所有的偏序关系集合称为该背景上的概念格,记为Β(G,M,I),概念格是一个完全格,具有对偶性,将形式背景中的对象和属性交换,同样可以得到一个概念格,只是在哈斯图中与原概念格相比上下层顺序倒过来了。概念格建立的过程就是一个聚类过程,概念格聚类是一个双聚类,不仅可以对对象进行聚类也可以对属性进行聚类。形式概念分析最重要的是构建形式背景、生成概念格,概念格构建算法一般有自顶向下和自底向上批处理算法和渐进式算法。对于同一形式背景,不管构建过程怎么样,最终生成的概念格都是一样的。使用形式概念分析方法进行概念格聚类,会完整保留数据的细节信息,不会降低数据的复杂性。概念格中每一个概念代表一个聚类类别,概念的外延是文本对象集合,概念的内涵为外延中文本对象的共同特征集合。概念格的上下层概念为包含与被包含的关系,下层概念为上层概念的细分,是一种较新的并且具有很多优点的聚类方法,其缺点是待聚类对象数量大、属性多的情况下,概念格构建速度慢。
3 可变属性粒度中文文本概念格聚类
对象的属性往往是指在一定粒度下的属性,比方说,对象具有某一属性A,属性A可以细分为LA和RA两个更加具体的属性,如果在较粗的粒度,某个对象具有的属性即为A,但是在比较细的粒度,某个对象具有的属性为LA或者是RA,属性粒度的粗细也是具有层次性。粒度越粗所暴露的细节越少、属性数量越少;粒度越细,描述越详细、属性数量越大。在中文概念格聚类中,通过构建可变属性粒度树,实现对聚类效果的优化,使得聚类结果更加有效、更加合理,避免属性多过情况下聚类速度慢的情形。具体算法如下:(1)对于待聚类文本集,基于百度百科构建属性粒度树;(2)将文本特征词匹配至属性粒度树上;(3)以待聚类文本为对象,属性粒度树上词条为属性构建概念格,实现可变属性粒度中文文本概念格聚类。
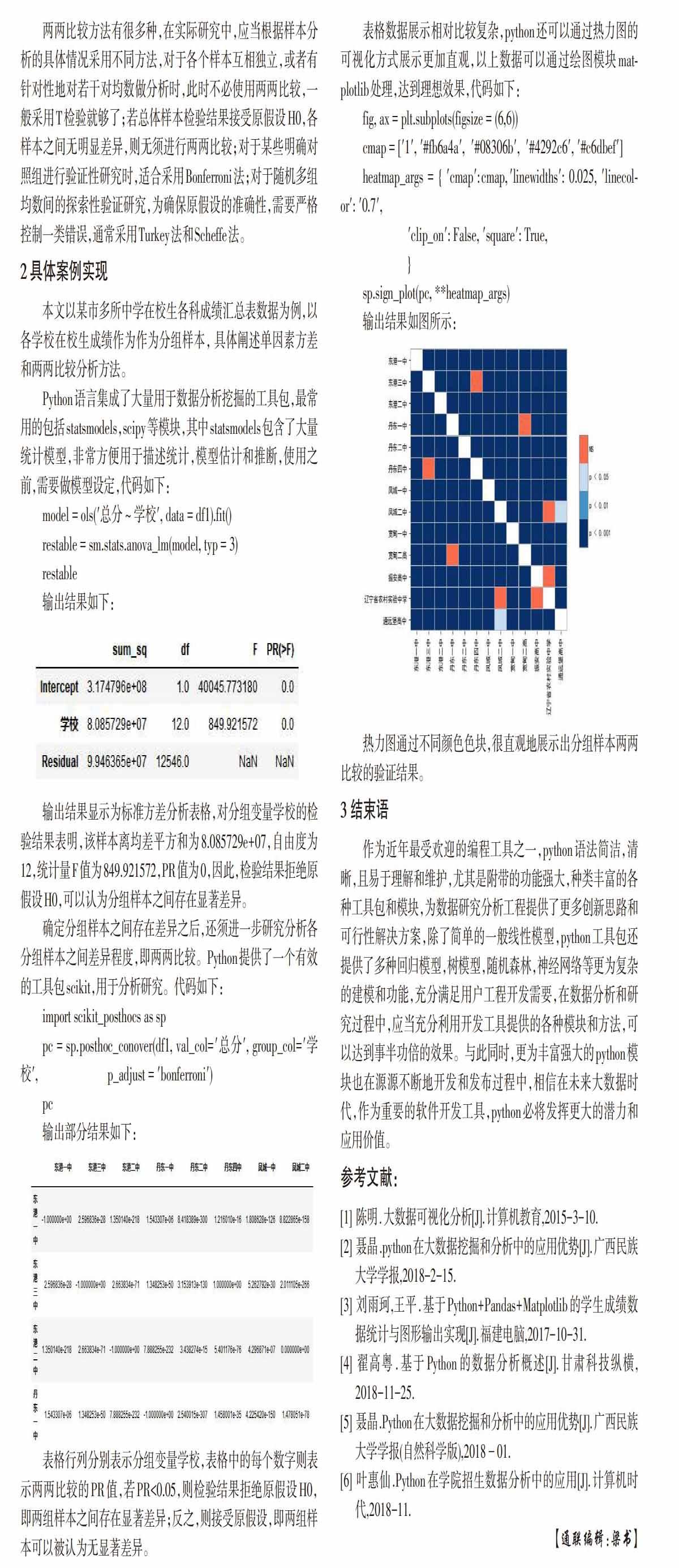
取150篇文本进行可变粒度概念格聚类,在不同粒度下的聚类结果如下图1:
(1)细粒度下的概念格聚类
(2)中等粒度下的概念格聚类
(3)粗粒度下的概念格聚类
通过实验发现,在细粒度下,聚类过程缓慢,在粗粒度下聚类结果粗糙,通过建立合适可变粒度的属性书,在上述中等粒度下进行概念格聚类,既保证了聚类结果的准确性,又有比较快的聚类速度,该算法有效。
4 结束语
本文以中文文本为研究对象,以文本特征词为属性,采用形式概念分析理论,使用概念格的聚类方法,通过构建合适粒度的可变属性粒度树,实现中文文本聚类,该算法比传统的中文文本聚类方法更为准确和有效。
参考文献
[1] Rui X,Donald W.Survey of clustering algorithms[J].Neural Networks IEEE Transactions on,2005,16(3):645-678.
[2] Hatzivassiloglou V,Klavans J L,Holcombe M L,et al.SIMFINDER:A flexible clustering tool for summarization[J].Proceedings of the Naacl Workshop on Automatic Summarization,2003:41-49.
[3] 林鴻飞,马雅彬.基于聚类的文本过滤模型[J].大连理工大学学报,2002,42(2):249-252.
[4] Zeng H J,He Q C,Chen Z,et al.Learning to cluster web search results[C].2004.
[5] Rauber A,Frühwirth M.Automatically Analyzing and Organizing Music Archives[C].2010.
[6] Wille R.Restructuring lattice theory:An approach based on hierarchies of concepts[J]. Springer,2009.
【通联编辑:朱宝贵】
猜你喜欢
计算机技术与发展(2022年8期)2022-08-23
现代语文(2022年2期)2022-03-09
计算机系统应用(2021年9期)2021-10-11
科技风(2020年31期)2020-11-23
现代信息科技(2020年18期)2020-02-22
计算机技术与发展(2018年8期)2018-08-21
计算机应用与软件(2018年1期)2018-02-27
中国机械工程(2017年22期)2017-12-02
中文信息学报(2015年4期)2015-04-21
武陵学刊(2011年5期)2011-03-20
