
基于多任务学习的古诗和对联自动生成
2019-11-18 08:04卫万成黄文明邓珍荣
中文信息学报 2019年11期
卫万成,黄文明,2,王 晶,邓珍荣,2
(1. 桂林电子科技大学 计算机科学与技术学院,广西 桂林 541004;2. 广西高效云计算与复杂系统重点实验室,广西 桂林 541004)
0 引言
古诗和对联是中国文化的精髓。古诗一般被用来歌颂英雄人物、美丽的风景、爱情、友谊等。古诗被分为很多类,例如,唐诗、宋词、元曲等,每种古诗都有自己独特的结构、韵律。表1展示了一种中国古代最流行的古诗体裁——唐诗绝句。绝句在结构和韵律上具有严格的规则: 每首诗由4行组成,每一行有5个或者7个汉字(5个汉字称为五言绝句,7个汉字称为七言绝句);每个汉字音调要么是平,要么是仄;诗的第二行和最后一行的最后一个汉字必须同属于一个韵部[1]。正因为绝句在结构和韵律上具有严格的限制,所以好的绝句朗诵起来具有很强的节奏感。

表1 唐诗绝句
对联一般在春节、婚礼、贺岁等场合下写于红纸贴于门墙上,代表了人们对美好生活的祝愿。表2展示了一副中国对联。对联分为上联和下联,上下联具有严格的约束,在结构上要求长度一致,语义上要求词性相同,音调上要求仄起平落。如表2中的对联长度一致,即汉字个数相同;语义相对,“一帆风顺”对“万事如意”,“年年好”对“步步高”;在最后一个字符的音调上仄起平落,“好”是仄,“高”是平,因此好的对联读起来会感觉朗朗上口。

表2 中国对联
近几年,古诗和对联的自动生成研究得到了学术界的广泛关注。科研工作者们采用了各种方法研究古诗和对联生成,文献[2-7]采用规则和模板的方式生成古诗或对联,文献[8-10]采用文本生成算法生成古诗,文献[11]采用自动摘要的方法生成古诗,文献[12-13]采用统计机器翻译的方法生成古诗及对联。最近,深度学习方法被广泛地应用于古诗对联生成任务上,并取得了很大成效。Zhang等[14];Wang等[15-16];Yi等[17];Yan等[18]均采用序列到序列模型来生成古诗和对联。此类方法在古诗和对联生成任务上取得了很大的进步,但也存在着一定的问题。如采用的单任务模型泛化能力低,在古诗生成上如用户输入现代词汇时,系统就会出现问题。此外,此类方法在生成时,限制用户的输入,当输入符合条件时才能创作,如此增加了用户使用的难度。
本文提出了一种新颖的多任务学习模型用于古诗和对联的自动生成,来弥补以上方法的不足,提高古诗和对联的生成效果。众所周知,古诗和对联的自动生成任务具有高度的相似性,要求平仄有序,对仗工整,尤其在深度学习中,对联可以看作是仅有两行诗句的古诗。尽管古诗和对联有很多的相同点,但是两者还是存在着一定的差别,不能混为一谈,具体的不同点体现在以下3点:
(1) 格式上,古诗绝句由4句组成,每句固定为5个或者7个汉字,对联由两句组成,汉字个数不定,上下联词与词之间必须一一相对;
(2) 内容上,多数古诗绝句用来描述古代生活,采用的词汇与现代不同,自动生成的古诗很难融入现代气息,而大部分对联采用现代词汇,充分体现了现代生活气息;
(3) 韵律上,对联比古诗要求更加严格,对联的上下联最后一个汉字必须遵循仄起平落。根据异同,本文中所提的多任务模型可以很好地融合两个任务。模型底层可以兼容古诗和对联的异同,上层保留各自不同,使模型泛化能力得到增强,相比单任务模型生成效果更佳。另外,将从用户输入意图中提取的关键词信息融入模型中,让模型创作的内容与用户意图一致,使用不受限制,方便生成个性化的古诗及对联。
1 相关工作
在自然语言处理中,古诗、对联的自动生成一直是研究的热点。文献[5-6]提出了一种基于语义和语法模板的西班牙诗生成方法。文献[4]采用基于词联想的方法生成俳句。文献[2-3]采用短语搜索的方法生成日本诗。文献[19]采用统计的方法对格律诗进行分析、生成。文献[20]采用严格的模板方式实现了一个基于语料库生成古诗的系统。文献[8-13]采用一些生成算法生成古诗,其中统计机器翻译(statistical machine translation,SMT)算法是一种很有效的方法。文献[11]认为古诗生成是个可优化问题,采用基于摘要框架并结合一些规则的方法生成古诗。文献[13]采用一种基于SMT的模型来自动生成汉语对联,将上联看成为源语言,翻译出下联,之后文献[12]对这种方法做了延伸,将SMT的模型用来生成绝句,根据前面的句子生成后面的句子。
最近,深度学习方法在古诗和对联生成任务上获得了很大的成功。文献[14]提出了基于循环神经网络(RNN)的绝句生成方法,这种方法首先根据给定的关键词利用2010年Mikolov等[21]提出的循环神经网络语言模型(RNNLM)生成诗的第一行,然后后面行根据前面已经生成的所有行顺序地生成,最后组成一首诗。文献[15]采用一个端到端的神经机器翻译模型生成宋词,通过翻译先前行得出下一行,这种方法类似于SMT,但是在两句话之间的语义相关性更好。文献[17]将这种方法应用在绝句生成上面。文献[22]提出一个新的古诗生成算法,首先根据输入的关键词生成出相关的韵文,然后根据韵文利用序列到序列模型[23]生成整首诗。文献[16]提出一种基于规划信息的神经网络模型用于古诗生成,首先根据用户输入提取关键词,然后利用关键词信息生成古诗。文献[17]训练三种序列到序列模型来分别生成绝句的第一行、第二行和第三、四行,并且采用了一些技巧来提高古诗的押韵。文献[18]将序列到序列神经网络框架应用于对联生成中,达到了较好的效果,但是此方法用户必须输入上联,模型才能应对下联。
本文在前人研究基础上进行改进,提出一种基于多任务学习的古诗和对联生成方法。本文方法的贡献在于:
(1) 第一次将古诗和对联生成任务相结合,设计了一种用于古诗和对联生成的多任务学习模型,提高模型的泛化能力;
(2) 采用TextRank算法和基于seq2seq词扩展相结合的方法来构建古诗及对联的写作大纲,使用户输入不受限制;
(3) 本文方法第一次在对联自动生成中引入用户意图信息来生成个性化对联。
2 方法实现
2.1 概述
方法的总体思路为首先从用户输入文本中提取写作大纲,然后根据写作大纲采用基于多任务的古诗和对联生成模型生成古诗与对联。方法通过变量来控制模型是生成古诗还是对联。
图1展示了古诗生成的流程。在生成古诗时,假设一首古诗由N行诗句组成,Li代表第i行诗,首先根据用户输入的文本,构建出N个关键词(K1,K2,K3,…,KN)作为作诗大纲,Ki表示第i个关键词,在生成阶段作为第i行诗句的子标题,然后将Ki和L1:i-1作为输入,生成Li,其中L1:i-1为已生成的所有行诗,每行诗根据作诗大纲中的一个子标题和之前生成的所有行诗句进行生成,如此,顺序地生成整首诗。图2展示了对联生成的流程。生成对联时,根据用户输入文本构建出两个关键词,分别用于生成上联和下联。对联大纲的获取首先从用户输入的文本中提取一个最重要的关键词,然后再扩展得出此关键词的相对词,两个词作为生成上联和下联的子标题。注意的是,对联大纲构建时,之所以构建一组相对词,是因为对联与古诗生成不一样,对联的上下联每个词汇、句法之间具有严格的对应关系,一旦上联确定了,下联采用的词汇就会受到一定限制,如再强加随意的主题信息进去,模型生成下联的效果会明显受到影响。
2.2 写作大纲构建
古诗生成时,生成一首N行的诗需要构建N个关键词来作为作诗大纲,每个关键词作为每行诗句的子标题。首先,根据用户的输入从中提取一些关键词。用户的输入为A,A有长有短,从A中提取出来的关键词数要小于等于N。如果用户的输入A很长,那么提取其中最重要的N个关键词作为作诗大纲。N个关键词对应于N行诗句。如果从A中提取出的关键词小于N个,那么需要将关键词个数扩展成N个。对联生成时,需要获取一组相对词作为生成上联和下联的子标题。首先从用户的输入文本中提取一个最重要的关键词,然后再根据此关键词扩展出其相对的词。

图1 古诗生成框图

图2 对联生成框图
2.2.1 关键词提取
本文采用TextRank算法[24]从用户输入的文本中提取关键词作为古诗和对联的写作大纲。TextRank算法可以评估词在一句话或者一段话中的重要程度。TextRank是由PageRank算法[25]演化而来,是一种基于图排序的算法。在TextRank的算法中,由节点及节点间的连接关系构成一个无向的网络图,节点之间的权重根据两个词的总计共现次数来设定。根据TextRank最终得分进行排序,得出用户输入文本中最关键的M个词 (M≤N)。一开始,给S(Vi)一个初始化值,然后根据式(1)进行迭代,计算得分,直到收敛。
(1)
其中,ωji是节点Vj和Vi连接边的权值,E(Vi)表示与Vj连接的节点的集合,d表示阻尼因子,通常设为0.85[25],S(Vi)为节点Vi的TextRank得分,初始分被设为1.0。
2.2.2 关键词扩展
作诗大纲构建时,从用户输入A中提取的关键词M一般都会小于N,这时需要对关键词进行扩展,扩展出相互之间具有联系的关键词。对联大纲构建时,需要根据从用户输入中提取的关键词扩展出与其相对的词。本文借鉴文献[26]采用基于注意力机制的序列到序列模型对关键词扩展,将词扩展看成是序列到序列的问题,分别训练出用于古诗大纲构建的关键词扩展模型(pkeseq2seq)和用于对联大纲构建的关键词扩展模型(ckeseq2seq)。在pkeseq2seq中,输入序列是从用户输入文本中提取出的和当前模型已生成的所有关键词的组合,输出序列是预测出的关键词。pkeseq2seq模型学习的是词与词之间的联系,通过模型将具有联系的词扩展出来。在ckeseq2seq中,输入序列是一个关键词,输出序列也是一个关键词,ckeseq2seq模型学习的是一个词与另一个词之间的相对关系,尤其是在对联用词方面的相对性。pkeseq2seq和ckeseq2seq的模型结构相同,都采用基于注意力机制的编码-解码结构,结构如图3所示,编码器采用BiLSTM,解码器采用LSTM。

图3 基于注意力机制的序列到序列关键词扩展模型
关键词扩展模型中,编码器将输入序列(x1,x2,…)编码成隐层状态(h1,h2,…),其中,xi为第i个字符的编码向量,解码器用隐层状态(h1,h2,…)生成输出序列(y1,y2,…)。在每一个生成时刻,字符yt根据上一时刻的预测字符yt-1、当前状态St以及当前的文本向量ct进行生成,ct由编码器的隐藏层状态(h1,h2,…)得来,每个隐藏状态hi对预测yt的贡献程度由权重at,i控制,at,i由计算St-1和hi相似性得来,通过权重at,i的控制,解码器将会更加注意与当前生成密切相关的输入部分。
pkeseq2seq和ckeseq2seq模型的不同点在于训练语料。pkeseq2seq训练数据采用古诗中提取出来的关键词,每首古诗采用TextRank算法提取出4个关键词,每句诗对应一个关键词。扩展时,根据所有已存在的关键词组成序列,扩展出与之联系的关键词,如 “明月 故乡 惆怅”扩展出“感伤”。ckeseq2seq训练数据采用从对联中提取出来的关键词,每副对联对应两个关键词,采用TextRank算法在上联中提取最重要的关键词,在下联中提取与上联相对的关键词,如在“春风轻拂千山绿,旭日东升万里红”中提取出“春风”和“旭日”两个相对词,春风作为输入序列,旭日作为输出序列。
2.3 基于多任务学习的古诗和对联生成模型
古诗和对联有诸多相似特征,且两者的自动生成方法大致相同。针对这一现象,本文引入多任务学习机制来融合古诗和对联的自动生成。此外,在古诗和对联创作中,一般作者都会先拟定一个简单的大纲再进行创作。在计算机创作时,也需要根据大纲信息进行创作。本文借鉴Wang等人基于规划的古诗生成模型[16],将写作大纲融入到生成模型中,提出一种基于多任务学习的古诗和对联生成模型(mtgseq2seq)。模型结构示意图如图4所示。模型输入由两个不同序列组成: 关键词和所有已生成的句子,模型输出根据设定的参数,输出对应的古诗和对联。

图4 基于多任务学习的古诗和对联生成模型
2.3.1 目标函数

(2)
其中,Φ={Φin,ΦoutT,T=1,2},Φin表示编码器的参数集合,ΦoutT表示第T个解码器的参数集合。NT表示第T种平行语料的大小,本文中T=1为古诗语料,T=2为对联语料。古诗和对联多任务学习模型中,编码器部分共享参数,解码器部分需要分开优化,编码器兼容古诗和对联的语义和语法特征,解码器学习古诗和对联各自的语义、语法特征。
2.3.2 模型细节
本文中,多任务学习模型的编码部分由两个BiLSTM组成并融入注意力机制,一个BiLSTM用于关键词输入,另一个BiLSTM用于已生成的古诗和对联输入;解码部分由两个LSTM组成,一个LSTM用于古诗的解码输出,另一个LSTM用于对联的解码输出。
假如关键词K有Tk个字符,K={a1,a2,a3,…,aTk},已生成的文本X有Tk个字符,X={x1,x2,x3,…,xTk}。编码阶段首先将K编码成隐藏状态的向量[r1:rTk],将X编码成[h1:hTk]。然后将[r1:rTk]整合成一个向量rc,将前向传播中的最后一个状态和反向传播中第一个状态进行连接,如式(3)所示。
(3)
文本用向量H=[h0:hTk]来表示关键词K和已生成的文本X,其中h0=rc,[h1:hTk]表示已生成的文本。当没有已生成的文本时,Tk=0,H=[h0],所以第一行诗句和上联的生成仅仅根据大纲的第一个关键词来生成。
在解码阶段,根据flag值确定采用poetry-decoder还是couplet-decoder来维护内部状态向量st,并在t时刻,被选中的编码器根据st、语义向量ct和先前的输出yt-1生成最可能的输出yt。如式(4)所示。
(4)
其中,flag要么是0要么是1,0表示使用couplet-decoder,1表示使用poetry-decoder。在每一时刻,st按照式(5)进行更新。
st=f(st -1,ct -1,yt -1)
(5)
其中,f(·)是LSTM模型的一个激活函数。ct由所有输入序列的隐层状态得出,按照式(6)计算。
(6)
其中,hj是输入序列中第j个字符的编码向量,αtj为hj的注意力权值,αtj的计算如式(7)所示。
(7)
k从0开始,其中,etk如式(8)所示。
(8)
其中,Vα,W和U是三个参数矩阵,需要在模型训练中优化。
3 实验与评估
3.1 数据处理
本文主要研究了绝句和对联的自动生成,绝句由4行组成,每行有5个或者7个汉字,对联由两行组成,每行汉字个数不定。实验从网上爬取了76 475首绝句和202 383副对联,从中随机挑选了2 000首绝句和6 000副对联作为验证集,2 000首绝句和6 000副对联作为测试集,剩余的72 475首绝句和190 383副对联作为训练集。
首先,实验对所有语料进行分词处理,然后计算每个词的TextRank分,将TextRank分最高的词作为每个句子的关键词。一首诗中提取出4个关键词,如表3所示。一副对联中提取两个关键词,从上联中利用TextRank提取出一个关键词,然后根据关键词在上联中位置将下联对应的关键词取出,如表4所示。从绝句的训练语料中提取了289 900个关键词,从对联的训练语料中共提取了380 766个关键词。将每首诗的关键词组合成如表5形式用于训练pkeseq2seq模型;将每副对联的关键词组合成如表6形式用于训练ckeseq2seq模型;将绝句和对联组合成如表7形式用于训练mtgseq2seq模型。

表3 绝句对应的关键词

表4 对联对应的关键词

表5 pkeseq2seq模型训练数据结构

表6 ckeseq2seq模型训练数据结构

表7 mtgseq2seq模型训练数据结构
3.2 模型训练
实验对pkeseq2seq模型、ckeseq2seq模型和多任务生成模型mtgseq2seq模型分别进行了训练。模型训练参考了Wang等[15]的训练方法,采用交叉熵作为训练的损失函数,优化器采用小批量随机梯度下降算法(the minibatch stochastic gradient descent algorithm)。另外,采用AdaDelta算法去调节学习率[28]。最后,根据在验证集上的困惑度来选取模型最优参数。
其中,pkeseq2seq和ckeseq2seq模型的输入基于词向量,采用Word2Vec模型初始化word embedding,大小设为512,BiLSTM和LSTM的隐层单元大小都设为256,mini-batch大小为128。mtgseq2seq模型的输入基于字向量,随机初始化字向量,大小设为512,随着训练进行不断优化,BiLSTM和LSTM的隐层单元大小都为512,mini-batch大小为128。
3.3 评估方法
(1) BLEU自动评估
BLEU由Papineni等[29]于2002年提出,原先用于评估机器翻译系统,因为古诗和对联生成任务和机器翻译任务有一定的相似性,所以在古诗和对联生成任务上,诸多研究者都采用BLEU自动评估方法,典型的有He等[12];Zhang等[14];Wang等[15];Yan等[17];蒋等[30];Sun等[17]。本文同样采用BLEU自动评估方法,计算出每种方法的BLEU得分。值得注意的是,由于古文中采用的词汇大多为一个字或者两个字,所以对于古诗及对联的评估,计算其BLEU-2得分是最有效的[17]。
(2) 人工评估
本文采用BLEU自动评估的同时也采用人工评估。古诗的人工评估,参考文献[10-12,17]的评估思路,从“前后押韵、语言流畅、内容一致、主题意义”4个部分去判断一首古诗的好坏。对联的评估,本文参考文献[17]的评估思路,从“句法、语义”两个部分去判断一副对联的好坏。每个部分设置最高分为5分,得分越高越好,古诗和对联的评估细则见表8和表9。实验让每种方法对应的系统分别生成20首绝句和20副对联,然后邀请10位具有硕士学历及以上的学者对所有生成的绝句和对联分别进行打分,取平均作为最后得分。

表8 古诗人工评估细则

表9 对联人工评估细则
3.4 实验对比设置
在BLEU自动评估中,本文设置了4种方法对比: RNNPG(1)RNNPG: https://github.com/XingxingZhang/rnnpg[14]、ANMT(2)ANMT: https://github.com/nyu-dl/dl4mt-tutorial/tree/master/session3[31]、S2SPG[26]和本文方法(MTLPCG)。其中,S2SPG和MTLPCG是单任务学习模型与多任务学习模型的对比,S2SPG方法中写作大纲构建、数据处理、模型训练等过程与MTLPCG一致,唯一的区别在于S2SPG是单任务,MTLPCG是多任务。其中,RNNPG和ANMT通过其开源代码进行实现,注意的是,实验未验证RNNPG和ANMT方法的对联生成,故方法对联部分的对比缺失。另外,因为RNNPG和ANMT的第一行诗在测试时需要事先给出,然后生成后三行,所以为了对齐实验,实验只计算所有方法生成的后三行诗的BLEU-2分,然后计算平均分。S2SPG和MLTPCG中输入的关键词和第一行诗来源于测试集。
在人工评估中,设置了6种方法的对比: RNNPG[14]、ANMT[31]、PPG(3)JIUGE: https://jiuge.thunlp.cn[16]、JIUGE[17]、S2SPG和本文方法(MTLPCG)。其中,S2SPG和MTLPCG同样为单任务学习模型和多任务学习模型的对比。其中,JIUGE方法生成的绝句来源于其公开的系统,因其公开的系统未实现对联的生成,故此方法对联部分的对比同样缺失。PPG方法未公开系统,本文对其进行了复现,利用PPG方法分别生成了对应的古诗和对联。注意的是,PPG和S2SPG在古诗生成时,采用古诗语料库进行训练,在对联生成时,采用对联语料库进行训练。
此外,需要说明的是在诸多对五言律诗和七言律诗做区分评估的论文实验中,五言律诗和七言律诗在表现模型效果上是一致的,如文献[14,16-17]等,因此,在本文评估中并未对五言律诗和七言律诗做区分评估。然而,在人工评估的20首古诗中,取10首五言律诗,取10首七言律诗。
3.5 实验结果分析
表10展示了自动评估得分,表11展示了人工评估得分,表中每栏最好成绩用*着重标记。另外,为了方便阅读,同样在图5和图6中分别以柱状图的形式展示了评估结果。
从结果中可以看出,本文提出的MTLPCG方法在绝句和对联生成中的表现优于所有基准方法。在自动评估结果中, MTLPCG和S2SPG的得分明显高于RNNPG和ANMT,这正是因为S2SPG和MTLPCG在生成模型中都融入了大纲关键词信息,如此保证了生成诗句的内容和效果。ANMT、PPG、JIUGE、S2SPG、MTLPCG都采用了基于注意力机制的序列到序列模型框架,效果都优于RNNPG,说明了基于注意力机制的序列到序列模型比单独的RNN模型能够更好地学习诗词前后的语义关系。值得一提的是JIUGE生成的古诗在前后押韵和语言流畅方面得分高于PPG和S2SPG,在内容一致和主题意义方面得分低于PPG和S2SPG,这说明了JIUGE方法对古诗的前后押韵和语言流畅方面有很大的帮助,但是JIUGE方法中用户意图仅影响第一行诗的生成,对后面诗句并没有太大影响,然而PPG和S2SPG基于大纲生成每行诗句,所以在内容一致和主题意义两方面得分远远高于JIUGE。最后,从单任务S2SPG和多任务MTLPCG的对比来看,MTLPCG在绝句和对联生成上都明显优于S2SPG,这说明采用的多任务学习方法起到了相应的效果,在古诗和对联自动生成任务上,两者融合可以相互促进,相辅相成,提高生成效果。

表10 BLEU-2得分结果

表11 人工评估得分结果

图5 BLEU-2得分统计图

图6 人工评估得分统计图
3.6 生成示例
表12列举了人工交互生成的绝句与对联。通过输入“秋天来了,枫叶落下了”来生成绝句,提取出的作诗大纲为“秋风;万里;枫叶;孤城”,然后根据作诗大纲生成古诗: “秋天夜色月华明,南北东西万里情.枫叶满庭霜露湿,独坐听雨落孤城.”。通过输入“健康吉祥”生成对联,提取出的对联大纲为“健康吉祥;安定团结”,生成的对联为“健康吉祥宝贵地,安定团结幸福家”。
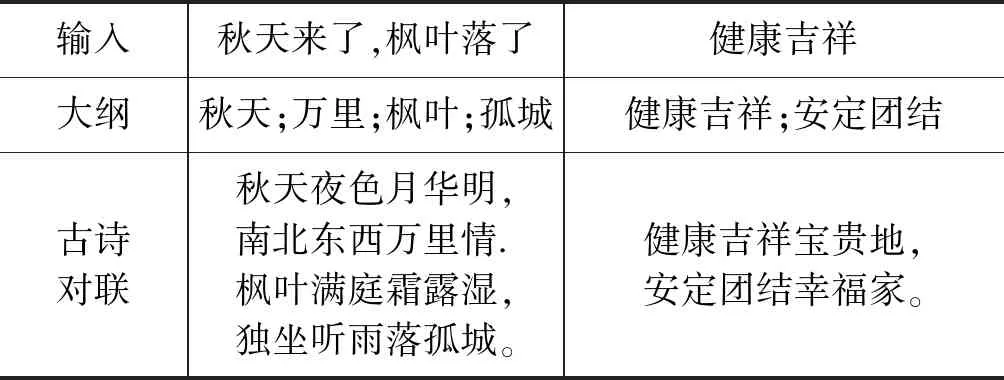
表12 人工交互生成的古诗和对联
4 总结与展望
本文创新性地将古诗生成任务和对联生成任务联合,提出了基于多任务学习的古诗和对联自动生成方法。方法中,本文设计了一种新颖的多任务学习模型来生成古诗和对联,使得一个模型框架不仅可以生成个性化古诗,还可以生成个性化对联。从实验结果来看,本文提出的方法优于所有基准方法,方法采用的多任务模型相较于单任务模型,模型的泛化能力得到了大大增强,表现效果得到了很大提升。
本文的研究取得了较好的成果,相信会对古诗和对联生成以及其他自然语言生成的研究有很大的参考价值。在未来工作中,我们会将多任务的学习方式应用于根据图片生成古诗和对联的任务中。另外,我们还会继续研究基于主题的古诗生成,在大纲中加入主题模型,例如,采用PLSA、LDA等主题模型,让自动生成的古诗和对联的主题与用户意图更加一致。
猜你喜欢
工会博览(2022年33期)2023-01-12
应用心理学(2022年5期)2022-11-05
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代信息科技(2021年21期)2021-05-07
中国新技术新产品(2016年23期)2016-12-26
军事体育学报(2016年2期)2016-06-15
对联(2011年2期)2011-11-19
对联(2011年22期)2011-09-19
对联(2011年8期)2011-09-18
对联(2011年6期)2011-09-18
