
基于两层分块GMM-PRS 的流程工业过程运行状态评价
2019-12-12 06:53邹筱瑜王福利常玉清郑伟
自动化学报 2019年11期
邹筱瑜 王福利 常玉清 郑伟
过程运行状态评价在过程安全运行的前提下,综合考虑了产品质量、物耗、能耗、经济收益等因素,对过程运行性能优劣进行进一步评价,包括过程运行状态优性在线评价和非优运行状态原因追溯两部分[1−5].优性在线评价实时判断运行性能优劣程度,非优原因追溯诊断导致非优运行状态的原因,指导操作人员进行生产调整.理想的运行状态有助于提高综合经济效益和生产效率、降低生产成本.因此,对过程运行性能优劣评价的研究具有重要的理论和应用价值.
传统的过程运行性能评价方法可分为两类:基于定量信息的评价方法和基于定性信息的评价方法,其中,定量信息指用数值大小描述的变量信息,定性信息指定性描述的变量信息,主要通过语义变量来描述.基于定量信息的评价方法处理以定量信息为主的过程性能评价问题.多元统计方法是一种应用最广泛的定量评价方法,适用于过程先验知识较少的过程[6−8].Liu 等提出了基于主成分分析法(Principal component analysis,PCA)和多集合主成分分析法(Multi-set PCA,MsPCA)的运行状态优性在线评价方法[9−10],但此类方法并没有考虑过程变量与评价指标之间的关系.基于指标预测的评价方法,虽避免了此问题,但所需数据量非常庞大[1−2].概率框架下的性能评价方法,如:基于高斯混合模型(Gaussian mixture model,GMM)[3,10]和贝叶斯理论(Bayesian theory)[11−12]的评价方法,已广泛应用于性能评价中.基于概率理论的评价方法需要先验知识辅助确定概率密度函数.不同于经典方法过于严苛的要求,智能评价方法,如基于人工神经网络(Artificial neural network,ANN)的评价方法,由于其学习能力和非线性处理能力强,受到研究者的青睐[13−14].但是,此类方法容易陷入局部最优值,可能出现过拟合现象.基于定性信息的评价方法处理以定性信息为主的过程性能评价问题.最常用的处理定性信息的方法有贝叶斯网(Bayesian network,BN)、模糊理论(Fuzzy theory)和粗糙集理论(Rough set,RS)等.BN 通过建立表示因果关系的网络和概率表来进行性能评价,BN 的构建通常需要大量过程因果知识[15−16].模糊理论通过隶属度函数来进行评价,但隶属度函数和判定阈值的选取尚无严格的理论指导[17−18].RS 在保持分类能力不变的前提下,对数据表进行约简,去除冗余信息,提取启发式规则,进行评价[19].但经典RS 并未考虑数据与目标概念之间的覆盖关系,因此,概率粗糙集(Probabilistic rough set,PRS)应运而生[20−22].PRS 定义了等价类与目标概念的隶属程度,以后验概率的形式量化数据与目标概念之间的覆盖关系.
定量方法的优势在于:精度高,能够建立变量之间的相关性,预测性能较好,是提取过程内部特性的方法,适用于变量测量准确的过程.但是,传统定量方法解释性差,在样本数目少时,可能会出现病态的模型.定性方法的优势在于:解释性强,可以处理不精确的信息,模型建立容易,适用于过程存在定性信息的过程.但是,传统定性方法精度低,要求数据类型覆盖所有可能的运行情况,是提取过程外部特性的方法,预测性能较差.若采用定性方法处理定量变量,需要将定量信息离散化,在信息离散化过程中,会损失有效信息,降低评价精度.综上所述,定量与定性方法各有优、劣势,相辅相成.在实际流程工业生产中,既有定量变量,又有定性变量.由于定性、定量变量共存的问题,传统评价方法难以直接应用.
实际工业过程还可能面临一个巨大的挑战,即流程工业特性.流程工业过程生产流程长,规模庞大,变量数目巨大,变量相关性复杂.一个流程工业生产过程,通常包含若干生产单元.同一个生产单元内,变量强耦合,不同生产单元间,变量弱耦合.生产过程从前至后,依序进行,每一个生产单元的生产时间不尽相同.因此,将传统的评价方法直接应用于流程工业过程,常常难以得到令人满意的准确率.流程工业过程生产周期长、变量众多、机理复杂,难以建立准确的全局模型.最常用的处理流程工业特性的方法就是将过程根据物理特性划分层次和子块,这种措施已广泛应用于安全性能评价中[23−24].Macgregor 等[25]和Jiang 等[26]分别提出了分块的多元统计方法和分块的概率论方法,来处理流程工业过程性能评价问题.相比于分块方法,分层的性能评价方法更注重子块之间的相关性[27].在分层或分块性能评价思想的基础上,研究者在质量预测[28]、自适应[29]等方向进行了进一步探索.但目前对流程工业过程优性评价的研究还较少.传统的分层分块性能评价方法难以直接应用于实际流程工业过程运行状态评价中,主要原因如下:1)全流程的评价问题难以分解为子块的评价问题;2)子块的优性难以定义;3)未考虑定量、定性变量共存问题.
本文提出一种基于两层分块混合模型的流程工业过程运行状态评价方法.横向上,将流程工业过程,根据其物理特性划分子块,将联系紧密的设备或生产环节划分至同一子块内,将联系相对较弱的设备或生产环节划分至不同子块;纵向上,形成两个评价层次即子块层和全流程层.本文所提两层分块方法与传统方法不同之处在于,所提方法能够评价子块的优劣程度,不需要显式的全流程模型即可评价全流程的运行状态,并快速定位非优的子块.这种灵活的分层分块评价方式,为混合模型的建立提供了便利.在一个子块内,综合考虑评价精度需求、定量和定性变量的比例、模型建立的复杂度,来选择定量或者定性方法进行建模和评价.不失一般性的,本文假设:以定量信息为主的子块,采用GMM 进行建模,获取子块内各运行状态等级数据分布的概率密度函数;以定性信息为主的子块,采用PRS 进行建模,得到子块内各运行状态等级的推理规则;于是,可以建立两层分块GMM-PRS (Gaussion mixture model-probabilistic rough set)模型.该混合模型的优势在于,根据子块的数据特性,灵活地选用恰当的评价方法,可减少有效信息的损失,保证方法的有效性.最后,本文将所提基于两层分块GMM-PRS模型的评价方法应用于国内某黄金湿法冶炼过程中,验证其有效性.此外,综合经济效益是目前应用最广泛的过程运行状态评价指标之一,本文采用综合经济效益为全流程运行状态评价指标.
1 基本方法简介
1.1 GMM简介
高斯分布是一种常见的数据分布,若高维空间点的分布近似为椭球体,则可用单一高斯密度函数来描述这些数据的分布特性.
令R1×J是服从高斯分布的J维过程数据,该类数据的概率密度函数可以用高斯函数表示:

其中,参数θ{µ,Σ},µ为该类数据的均值向量,Σ为协方差矩阵[11].这些参数的取值决定了概率密度函数的特性,如函数的中心点、宽窄和形状等.
一些过程数据不服从高斯分布,但可以用高斯混合模型描述其分布特性.假设该过程数据分布包含N个高斯分量,第n个高斯分量的概率密度函数表示为g(x|θn),其先验概率为ωn,n1,2,···,N.则此过程概率密度函数为:

数据x属于各高斯分量的概率可用贝叶斯理论求得:

其中,Cn表示第n个高斯成分.
1.2 PRS简介
RS是一种在不需要过程先验知识的情况下进行推理的方法,针对定性数据,可进行高效、准确的推理.但是,RS存在没考虑子集间相关性和定义过于严格的问题.因此,PRS应运而生.
令U为目标的非空有限集合,U称作论域,A为一个有限的属性集合,R是A的一个子集.对于任意,定义x在R上的等价类[x]R为[x]R(x,a)f(y,a)},其中,f(x,a)为x在属性a上的取值.给定一个非空子集X ⊆U和一个等价类[x]R,可以计算如下概率:

其中,|S|表示集合S的基,即S中的元素个数.P(X|[x]R)表示[x]R中,X的覆盖程度.
给定阈值α和β,针对0≤β <α≤1的情况,X的下近似、上近似、R边界域定义为:

针对αβ0的情况,X的下近似、上近似、R边界域定义为:

X的下近似中,包含所有一定属于X的元素;X的上近似中,包含所有可能属于X的元素.如果边界域BNR(X)为空,那么X称为精确集;否则,X称为粗糙集.如果取α1、β0,PRS退化为传统RS.
2 两层分块GMM-PRS模型的建立
根据流程工业特性,本文提出两层分块评价结构,并根据每个子块的数据特性,分别用定量或定性方法,建立子块评价模型.
2.1 两层分块GMM-PRS结构
过程运行状态的优劣通常可反映在综合经济指标(Comprehensiveeconomicindex,CEI)上,CEI越高,运行状态越好,CEI 也成为了广泛接受的运行状态优性评价指标[23].传统评价方法对过程变量x和评价指标CEI可建立一个单模型:

为了降低流程工业过程运行状态评价问题的规模、提高模型解释性,本文提出如图1所示的两层分块结构;并且,对以定量和定性信息为主的子块,分别进行定量和定性建模.
在子块层,一个流程工业过程根据其过程特性,划分为多个有物理意义的子块.子块内,变量相关性强;子块间,变量相关性弱.在全流程层,提取各子块间的相关性.因此,两层分块结构增强了模型解释性,减少了问题规模,降低了建模难度,削弱了对子块性能无关变量的影响,放大了对子块性能有关变量的影响.
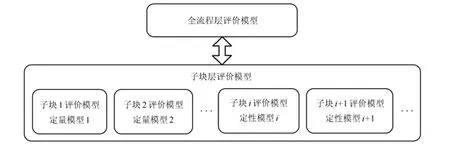
图1 两层分块混合模型结构示意图Fig.1 The illustration of the two-level multi-block hybrid model structure
将过程进行横向分块、纵向分层后,得到了两层分块结构,再根据每个子块的特性建立相应评价模型,为全流程的评价提供基础.按照子块的数据特性选择适当的建模方法,保证了模型的有效性和精度.高斯分布是一种常见的数据分布,若高维空间点的分布近似为椭球体,则可用单一高斯密度函数来描述这些数据的概率密度函数.针对以定量信息为主的单模态过程,同一运行状态等级的定量数据分布特性相似,近似服从单高斯分布,可视为所有定量数据分布的一个高斯成分.过程中,定性变量的数目和状态种类都较少,因此,定性变量可能出现状态组合种类不会很多,其分布可以用历史数据进行学习.而对于定性信息占主导地位的过程,定性变量数目多,相应定性状态的组合数目也会大幅增大.那么,基于GMM 的方法,会面临组合爆炸、建模数量庞大的问题.也就是说,以定性变量为主的过程,不再适合用基于概率分布的方法来进行评价.Pawlak 教授提出的RS 理论是一种在不确定性存在的前提下,进行推理的方法,现已广泛应用于安全性评价和风险评价等领域.为改进RS 无法处理不一致规则的问题,概率粗糙集PRS 方法应运而生.PRS 是一种具有严格理论支撑并且应用广泛的定性信息处理方法,因此本文采用PRS 对以定性信息为主的子块进行建模.值得注意的是,可选的子块建模方法并不局限于GMM 和PRS 方法.
2.1.1 运行状态等级确定
本文所述定性信息指用语义变量对变量状态进行描述的信息,定量信息指用数值大小描述的变量信息.建模数据中,定量变量以变量取值的形式表示,定性变量以变量状态等级序号的形式表示,如温度的高、中、低三种状态,分别对应状态等级1、2、3.其中,定性变量状态等级只与变量幅值大小趋势相关,与性能优劣无关.本文所使用的定量数据是经过平滑处理后的数据,定性数据根据其物理意义划分为了不同状态,并用一系列连续的正整数对状态等级进行区分.其中,平滑处理的原理是用一定长度的滑动窗口内数据的平均水平来代表该滑动窗口的信息,这种预处理方法在一定程度上克服了噪声的影响,使此均值更能反映滑动窗口内的主要信息.针对变化快速或噪声水平较低的过程,为避免过程动态特性被淹没,滑动窗口长度不宜过长.针对变化缓慢或噪声水平较高的过程,为减少系统正常波动导致的误评价,滑动窗口长度不宜过短.
2.2 基于两层分块GMM-PRS 的离线建模
根据过程知识,建立两层分块结构之后,基于两层分块GMM-PRS 的评价模型离线建立包括运行状态等级确定和模型建立,其中,模型建立分定量GMM 和定性PRS 模型.
针对一个复杂的流程工业过程,在划分单元子块之后,如果各子块存在独立的评价指标,那么可以对每个子块建立以子块生产指标为评价标准的模型,再在子块生产指标的基础上,进行全流程的运行状态评价.但是,本文旨在解决无子块评价指标的流程工业过程运行状态优性评价问题.此时,子块的优性定义变得十分困难.本文利用唯一的评价指标– 全流程综合经济指标CEI,作为子块运行状态等级划分标准.企业通常会在一定周期内对CEI 进行估算并作为生产考核的标准,但是估算周期比较长,无法直接根据该估算结果实时指导生产.所以,我们可以将CEI 视作定性变量,只需确定其在一定周期内的定性状态.根据全流程CEI 的定性状态,过程运行状态被划分为若干等级,等级数目通常由过程评价的精度需求、过程检测情况等因素共同决定.本文假设全流程综合经济指标包含N个状态,对应的全流程运行状态等级由1 至N,优性依次降低.在划分子块后,就一个子块的一类运行情况而言,定义此类运行情况下所能达到的最好全流程运行状态等级为这种运行情况下该子块的运行状态等级.从另一个角度看,该运行情况下,当其他子块都处于最好匹配状态时,该子块使全流程所能达到的最好等级代表了该子块所处运行情况的极限最好情况,是子块所处运行情况固有特性的一种体现.如图2 所示,建模数据的运行状态等级离线确定方法包括以下三个步骤:1)数据块划分,2)全流程层等级确定,3)子块层等级确定.
1)数据块划分
令建模数据为RH×J,H表示样本个数,J表示变量个数.根据变量和子块之间的关系,将建模数据XXX划分为I个子块,用XXXiRH×Ji(i1,2,···,I)表示第i个子块的建模数据,Ji为第i个子块的变量数目.
2)全流程层等级确定
根据全流程评价指标CEI,过程运行状态被划分为若干等级,如:优/良/中/差等.那么,每一个子块数据XXXi,可以根据全流程评价指标CEI,划分为不同等级,记为其中,表示子块i中全流程等级为n的数据,i1,2,···,I,n1,2,···,N,I为子块数目,N为全流程等级数目.

图2 离线数据划分示意图Fig.2 The diagram of data processing
3)子块层等级确定
由于全流程层运行状态等级不能单独取决于一个子块的运行状态,所以,相似的子块数据可能被标记了不同的全流程层运行状态等级.对于一个子块:若该子块运行于最优运行状态,并且其他子块运行于最优匹配状态时,全流程层运行状态可能达到最优等级;若该子块运行于一个非优运行状态中,无论其他子块是否运行于最优匹配状态,全流程层运行状态都不可能达到最优等级.因此,一个子块数据的子块层运行状态等级定义为:该子块内相同数据所能达到的最好全流程层运行状态等级.所以,全流程层的等级数目和子块层的等级数目相等.假设运行状态,等级1 到N的优性依次降低.确定子块层运行状态等级n中数据的具体做法为:以全流程层等级n,n+1,···,N中数据为基础,将等级n+1,n+2···,N中与等级n中数据相似度大于阈值ε的数据,从原来的等级中转移至等级n的数据集中,更新后的等级n中的数据为子块层运行状态等级为n的数据,记为,更新后的等级n+1,n+2,···,N中的数据为确定下一等级数据的基础.两条数据的相似度定义如下:

x1,j(x2,j)是x1(x2)的第j个变量;若第j个变量为定量变量,是该变量的工艺最大值(最小值);若第j个变量为定性变量,|x1,j−x2,j|表示x1,j和x2,j对应定性状态等级的等级差值的绝对值;Aj是第j个变量的状态等级数目,为变量数目.
根据上述三个步骤,子块数据的全流程层等级和子块层等级能相应确定.由于上述等级划分规则,并不需要建立显式的全流程层模型.全流程层运行状态等级由子块层中最劣的子块运行状态等级决定,原因将在第4 节的全流程运行状态在线评价方法中阐述.
2.2.1 定量建模
针对以定量信息为主的子块,将每一个运行状态等级的数据作为一个高斯分量,分别建立单高斯模型,拟合各等级数据的概率密度函数.但由于少数定性变量的存在,无法直接建立高斯模型.
假设x来自于第i个子块的第n个等级,即.令其中,表示定性变量,表示定量变量.根据定性变量状态的不同,存在多种组合形式.以定量信息为主的子块所含定性变量数目少,一个定性变量的状态种类一般不会很多,不是每一种理论上存在的定性组合都会在实际应用中出现.所以,中可能出现的定性状态组合种类一般不会很多.用表示中,定性变量对应为的样本的定量变量部分,其中,k1,2,···,K,K为定性变量组合的数目.假设则针对定性变量为的情况,第i个子块第n个等级的概率密度函数可用高斯函数表示为:


其中,Num[ψ]表示矩阵ψ中的样本个数.

2.2.2 定性建模
针对以定性信息为主的子块,采用PRS 进行建模.基于PRS 的离线建模包含以下三个主要步骤:1)数据预处理;2)决策表组织;3)属性约简.
1)数据预处理
PRS 是一种以定性或离散数据为基础的推理方法,因此,需要将数据进行相应预处理.针对定性数据,为后文计算方便,将变量的各定性状态用一系列整数表示.针对以定性信息为主的子块中少数的定量数据,需要将定量数据进行离散化,得到一系列离散数值.离散化处理方法很多,如等距离划分、等频率划分、Naive Scaler 算法、基于断点重要性的离散化算法、基于属性重要性的离散化算法等[30].
2)决策表组织
决策表的每一列表示一个属性,每个属性的取值被划分为若干离散状态.通常,属性可分为条件属性和决策属性.决策表每一行代表论域中的一个元素和一种推理规则.以子块内过程变量为条件属性,以子块层运行状态等级为决策属性,分别建立各子块决策表.
3)属性约简
属性约简目的在于简化决策表,在保持分类能力不变的前提下,删除对决策没有影响的条件属性.常用的属性约简方法有:一般约简算法、基于差别矩阵和逻辑运算的属性约简算法、归纳属性约简算法等[30].
3 基于两层分块GMM-PRS 的过程运行状态在线评价和非优原因追溯
基于两层分块GMM-PRS 的过程运行状态在线评价方法,先在子块层,对各个子块分别进行评价,再在全流程层,综合各子块信息得到最终评价结果.针对非优运行状态,在非优的子块内进行原因追溯.
3.1 子块层的运行状态在线评价
用xt表示t时刻子块i的数据.若子块i为以定量变量为主的子块,xt可分解为xt中的定性变量取值与的相似度为sim针对等级n,如果max小于一个事先定义的判定阈值δ(0<δ ≤1),那么认为xt不可能处于此等级,令否则,可以根据式(12)获得.
若子块i为以定性变量为主的子块,在子块内,首先,对定量变量进行离散化.然后,从历史数据中得到xt的等价类[xt]R,其中,R为条件属性集合.最后,根据式(4)计算[xt]属于子块层第n等级的概率:

其中,n1,2,···,N,i1,2,···,I.
t时刻,子块i所处运行状态等级为:

3.2 全流程运行状态在线评价
在获得所有子块的子块层运行状态等级后,全流程层运行状态等级与子块层最劣的子块运行状态等级相等.假设全流程层等级1 至N,优性依次递减.那么全流程层运行状态等级表示为:

显然,根据子块等级定义,由于各子块运行状态等级被定义为相似度大于阈值ε的同类数据所能达到的历史最好全流程层等级,所以全流程层运行状态等级不可能比任何一个子块的运行状态等级更优.也就是说,全流程层运行状态等级不会比子块层最劣的子块运行状态等级更优.从另一个角度看,如果全流程层运行状态等级比子块层最劣的子块运行状态等级更劣,说明全流程层运行状态等级比所有子块运行状态等级都更差.这种情况在实际生产中较少出现,大部分子块运行状态应与全流程运行状态相一致.所以,定义全流程层运行状态等级为子块层最劣运行状态等级,如式(15)所示.
3.3 非优原因追溯

针对以定性变量为主的子块,直接在最优运行状态等级历史数据中,查找与当前非优数据xt相似度最高的数据,记为与上述追溯方法类似,用式(16)中的公式,计算变量贡献率,贡献率较大的属性为非优属性.
4 基于两层分块PRS-GMM 的流程工业过程运行状态评价方法在黄金湿法冶炼过程中的应用
湿法冶金过程是现代工业生产中金属富集、分离与提取的重要手段和技术.湿法冶金,又称之为化学冶金,是相对于火法冶金和电解法冶金而言,一种利用液相环境的特点,通过一定的化学反应,进行目标金属的提炼和萃取的技术.黄金湿法冶炼通过液相环境,将矿石中固相的金,浸出至矿浆中,形成液相的金氰络合物离子.在浸出子块中,氰化钠是一种重要的添加药剂,并通过影响浸出率来影响综合经济效益.然后,通过洗涤进行固液分离,得到矿渣和富含金氰络合物离子的贵液.其中,贵液经过锌粉,发生置换反应,得到金泥.在置换环节中,锌粉的添加量和质量对运行状态影响较大.
本文将所提评价方法应用于国内某黄金湿法冶炼过程中,该过程可划分为五个子块:第一次浸出、第一次洗涤、第二次浸出、第二次洗涤和第二次置换,分别对应子块层的五个子块.两浸两洗的工艺设置是为了提高浸出率.黄金湿法冶炼过程是一个复杂的流程工业过程,同时包含定量和定性变量.第一次浸出和第二次浸出子块以定量信息为主,因此,用GMM 对这两个子块进行建模.第一次洗涤和第二次洗涤子块以定性信息为主,因此,用PRS 对这两个子块进行建模.至于置换子块,定性和定量信息大量共存,没有某种信息占主导地位的现象.但是,其影响优性的关键变量均为定性变量,故采用PRS 对置换子块进行建模.
选取36 个过程变量,列于表1.根据综合经济效益先将黄金湿法冶炼全流程层运行状态划分为优、中、差3 个等级,分别对应等级1、2、3.从湿法冶金仿真平台,选取3 000 组数据进行离线建模,其中,每个等级的数据各1 000 组,建模数据量充分,可以建立准确的离线模型.然后,确定每个子块各个等级所包含的数据,即确定数据子块层等级.根据5个子块的特性,分别建立GMM 或PRS 模型.设置相似度判定阈值ε0.9.
重新选取400 组数据进行在线测试,实验设计如表2 所示.在实验1 中,前100 组数据运行状态等级为优(等级1),后100 组数据由于氰化钠添加量2 (子块3,定量)不足,导致运行状态等级变为差(等级3).在实验2 中,前100 组数据运行状态等级为优,后100 组数据由于锌粉添加量(子块5,定性)过量,导致运行状态等级变为中.其中,在实际生产中,锌粉添加量只能获得8 小时的累积量,因此,在本实验中,将该变量作为定性变量进行处理.用所提方法进行运行状态在线评价和非优原因追溯,以验证其有效性.

表1 过程变量列表Table 1 The process variable list

表2 实验设计Table 2 The experiment design
实验1 的评价结果如图3 所示,在评价时间内:子块1、2、4、5 都处于等级1;子块3 前100 个评价点处于等级1,后100 个评价点处于等级3;全流程运行状态评价结果为前100 个评价点处于等级1,后100 个评价点处于等级3.显然,评价结果与实际运行状态等级设置一致.从第101 个评价点起,全流程运行状态等级为非优等级,导致全流程非优的是子块3,第二次浸出子块.因此,在子块3 中,进行非优原因追溯.第101 个评价点的非优原因追溯结果如图4 所示,显示非优原因变量有第二次浸出氰化钠添加量、第二次浸出后氰根离子浓度和第二次浸出后金氰络合物离子浓度.事实上,由于第二次氰化钠添加量不足,会导致第二次浸出后氰根离子和金氰络合物离子浓度下降.因此,非优原因追溯结果与实际情况一致.

图3 实验1 运行状态等级在线评价结果Fig.3 The assessment result in Case 1
实验2 的评价结果如图5 所示,在评价时间内:子块1、2、3、4 都处于等级1;子块5 前100 个评价点处于等级1,后100 个评价点处于等级2;相应的,全流程评价结果为前100 个评价点处于运行状态等级1,后100 个评价点处于等级2.评价结果与实际运行状态等级设置一致.然后,在非优的子块中,进行原因追溯.非优的子块为置换子块,是一个定性建模的子块,其追溯结果展示于图6.实际上,锌粉添加量过多,置换率已无法再提升,反而会增加置换物耗,降低总经济效益,导致运行状态等级变为非优.

图4 实验1 子块3 中非优原因追溯结果Fig.4 The cause identification result within Sub-block 3 in Case 1
与传统评价方法相比,两层分块GMM-PRS 主要在分层分块和混合模型两方面做了改进.分层分块使得评价难度降低,解释性强,可以直接在非优子块中进行原因追溯,快速定位原因变量.混合模型充分利用不同变量提供的信息,提高了评价精度.将PRS、两层分块PRS、GMM、两层分块GMM 和两层分块GMM-PRS 方法分别应用于黄金湿法冶炼过程运行状态评价中,经过多次试验,评价准确率均值如表3 所示.其中,基于PRS 的评价,对全流程建立一个PRS 模型;基于两层分块PRS 的评价,将全流程进行层次和子块的划分,对每个子块分别建立一个PRS 模型;基于GMM 的评价,针对全流程不同定性变量的组合,分别建立全流程的GMM;基于两层分块GMM 的评价,将全流程进行层次和子块的划分,在子块内,针对不同定性变量的组合,分别建立GMM.从准确率的对比可以看出,相比于PRS、两层分块PRS、GMM 方法,本文所提两层分块GMM-PRS 具有明显优势.两层分块GMM 方法,由于应用了本文所提的分层分块和针对不同定性变量组合分别建立GMM 的思想,具有与两层分块GMM-PRS 相当的正确率.但是,相比于两层分块GMM 方法,所提两层分块GMM-PRS 具有模型数量少、计算量小、计算时间短的优势.

图5 实验2 运行状态等级在线评价结果Fig.5 The assessment result in Case 2
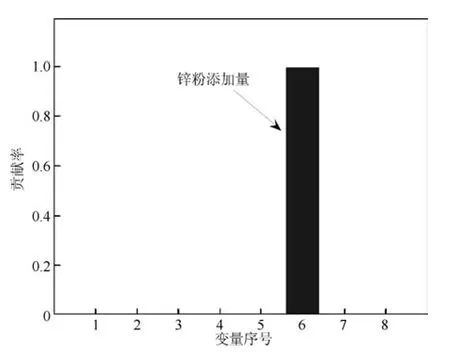
图6 实验2 子块5 中非优原因追溯结果Fig.6 The cause identification result within Sub-block 5 in Case 2
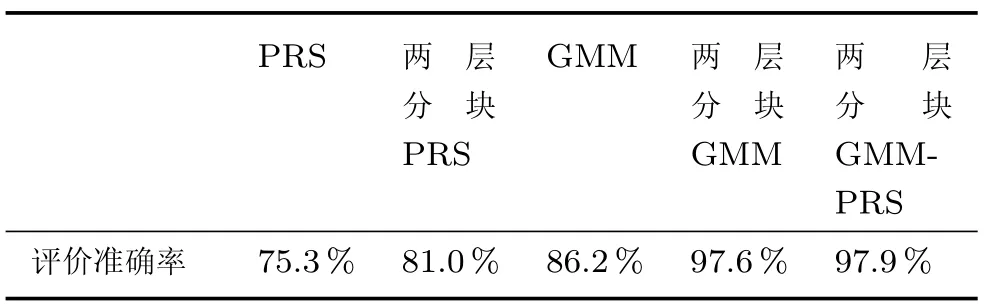
表3 不同方法评价准确率对比Table 3 The assessment accuracy rate comparison of different methods
5 结论
针对定量、定性变量共存的流程工业过程运行状态评价问题,本文提出了基于两层分块混合模型的评价方法.将流程工业过程,根据其物理特性划分为运行子块,同时,形成了子块层和全流程层,两个评价层次.在子块层,对于以定量信息为主的子块,根据不同的定性变量状态组合,分别建立GMM.对于以定性信息为主的子块,将定量变量进行离散化,建立PRS 模型.全流程层运行状态等级由子块层最劣运行状态等级决定.当过程运行于非优运行状态等级,非优的子块可根据子块运行状态评价结果进行确定.在非优的子块内,本文提出了基于贡献率的原因追溯方法.最后,本文将所提方法应用于湿法冶金过程运行状态评价中,并与传统方法进行了比较.仿真结果证明了所提方法的有效性和优势.
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
北京航空航天大学学报(2022年8期)2022-08-31
纺织标准与质量(2022年1期)2022-07-12
房地产导刊(2022年4期)2022-04-19
成都信息工程大学学报(2021年5期)2021-12-30
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
现代计算机(2021年36期)2021-03-14
南京理工大学学报(2020年4期)2020-09-21
艺术探索(2019年1期)2019-04-17
计算机应用(2018年12期)2019-01-07
