
基于协同过滤推荐技术在就业推荐系统的应用研究
2019-12-28 08:24刘双双
现代计算机 2019年32期
刘双双
(1.江西农业大学南昌商学院计算机系,南昌330029;2.江西工业职业技术学院电子信息工程学院,南昌330029)
0 引言
随着计算机网络的快速发展及大数据时代的到来,互联网上的招聘信息量呈爆炸式增长,一方面给毕业生带来了极大的便利,他们获取的信息资源越来越丰富,另一方面也给毕业生带来困惑:面对海量的招聘信息,毕业生需要花费更多的精力和时间去搜寻满意的职位信息,“信息超载”(Information Overload)现象越来越严重,从而导致了“双难”(就业难,招人难)现象。为了有效解决“双难”问题,推荐系统(Recommender System)[1]能根据用户的特征,快速帮助毕业生在广袤的岗位信息海洋中针对性地寻找到满意的岗位信息,提供个性化服务。目前推荐系统所采用的推荐技术主要包括基于内容的推荐(Content-Based Recommendation)、协同过滤(Collaborative Filtering)、关联规则(Association Rules)、信息检索(Information Retrieval)和混合推荐(Hybrid Approach)。协同过滤推荐系统是现有推荐系统中最流行、最行之有效的一种推荐系统。目前协同过滤推荐一般分为三类:基于项目的协同推荐、基于用户的协同推荐和基于模型的协同推荐[2]。本研究采用的是基于用户的协同过滤推荐算法。
1 基于用户的协同过滤推荐算法的概述
基于用户的协同过滤推荐算法是协同过滤推荐中最基本的算法,该算法由Resnick 等人于1994 年提出,其原理是根据目标用户的兴趣特征,先找到与目标用户兴趣相似较高的其他用户群,然后把那些用户群感兴趣的并且目标用户没有被推荐过的产品推荐给目标用户。其流程图如图1 所示。

图1 基于用户协同过滤推荐流程图
2 基于用户协同过滤算法实现高校就业推荐模型的构建过程
基于用户协同过滤推荐技术主要分以下三个阶段[3]:第一、用户偏好表示(Representation):邻居用户形成(Neighborhood Formation)、推荐生成(Recommendation Generation)。
2.1 用户偏好表示
(1)偏好信息的收集:在表示用户偏好之前,先要收集用户的偏好信息,基于用户的协同过滤推荐一般先采用显式跟踪和隐式跟踪这两种方式对目标用户的兴趣爱好进行收集[4]。显式跟踪是让毕业生主动向系统提供自己的兴趣爱好,系统先以表单的形式展示岗位信息,并对每个岗位信息提供五个单选项(1 表示很不喜欢,2 表示不喜欢,3 表示喜欢,4 比较喜欢,5 表示很喜欢)让毕业生进行选择,实现五分制评分。隐式跟踪是指通过对毕业生的岗位浏览历史记录等进行分析得到毕业生对岗位的偏好信息。本研究综合采用显式跟踪和隐式跟踪两种方式进行对学生的岗位爱好信息进行收集。本研究中的毕业生岗位偏好信息的收集来源于我校就业推荐系统,数据为2016 年1 月至2018年12 月时间段的所有记录,包括jobxx 岗位基本信息表、graduatesxx 毕业生基本信息表和browseRec 毕业生浏览记录表。其中岗位信息表包括jobId 岗位编号,jobName 岗位名称,jobCon 岗位条件,jobDes 岗位描述,CoName 公司或单位名称,jobAdd 工作地点,jobSal 月薪名称这四项信息;graduatesxx 毕业生基本信息表包括graduateId 毕业生编号,graduateName 毕业生姓名,graduateSex 毕业生性别,graduateBir 毕业生出生日期,graduateAdd 毕业生家庭住址,graduateTel 毕业生联系方式,graduateEmail 毕业生邮箱,graduateSpe 毕业专业,graduateSch 毕业学校,graduateTime 毕业时间这十项信息;browseRec 毕业生浏览记录表有graduateId 毕业生编号,jobId 岗位编号这两项信息。
(2)偏好信息的表示:无论是通过显式跟踪还是隐式跟踪的方式收集的岗位偏好信息,本研究都采用用户-岗位评分矩阵R(如表1 用户-岗位评分矩阵R 所示)表示毕业生的岗位偏好信息。

表1 用户-岗位评分矩阵R
R 是一个m×n 阶矩阵,其中m 表示毕业生的数目,n 表示岗位的数目。Rij代表的含义如下:

2.2 邻居用户形成
最近邻选择是基于用户的协同过滤中最核心的步骤,通常做法是先求出用户间岗位偏好相似性系数数据表,并按岗位偏好相似度sim(ua,ui)从大到小的顺序排列。然后选择相似度较高的用户组成ua的最近邻集合。
(1)求用户相似性:依据用户-岗位评分矩阵R 计算目标用户与其他用户的相似性。求用户相似性目前主要有均方差相似性(Mean Squared Differences)、余弦相似性(Cosine Similarity)和Pearson 相关系数(Pearson Correlation Coefficient)这三种方法,本研究采用余弦相似性方法求解用户间的相似度,具体公式如(1)所示:
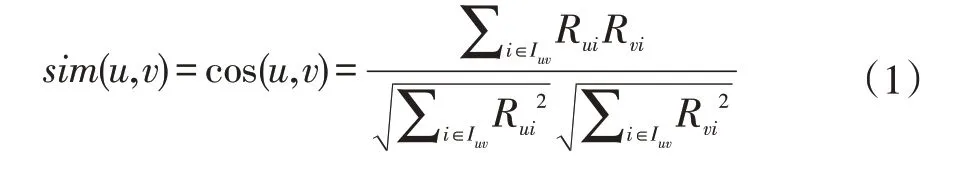
公式中的u、v 分别表示两个用户,i 表示岗位,Rui用户u 对岗位i 的评分,用户相似性通过向量间的余弦夹角来度量,夹角越小则相似性越髙。将用户-岗位评分矩阵的数据作为基础数据,通过余弦相似度算法编程执行后,得到一组以岗位代码为主键关联得出用户间岗位偏好相似性系数的数据表,如表2 邻居岗位相似性表(Similarity)所示。
(2)确定最近邻数量形成邻居用户:确定最近邻数量的方法有两种—是事先设定一个相似性参考值,取与目标用户相似性大于该参考值的用户作为最近邻集合。二是直接选取相似性最大的前k 个用户作为最近邻集合;本研究采用第二中方法确定最近邻数量,选择相似性较高的用户组成ua的最近邻集合Un={u1,u2,u3,…,uk}形成ua的邻居用户。

表2 邻居岗位相似性表(Similarity)
2.3 岗位信息推荐
将ua的邻居用户浏览过的而用户ua未浏览过的岗位信息推荐给ua。具体实现代码如下:
Select distinct jobId from browseRec as a where jobId not in
(Select distinct jobId from browseRec as a where graduateId=ua的id 号)
and graduateId in(邻居用户列表)
3 结语
在毕业生就业推荐系统中应用协同过滤推荐技术,根据毕业生的兴趣爱好、专业方向等实现了毕业生的个性化精准就业和企业精准招聘。但随着就业推荐系统中用户和项目数量庞大,项目类别的增加,用户-项目评分矩阵将成为高维矩阵,计算复杂度会越来越高,将会严重影响推荐的实时性;当就业推荐系统中项目类别的内容完全不同时,使用协同过滤算法搜寻出的最近邻用户会不够合理,将严重影响推荐质量。协同过滤中的稀疏问题和多内容问题有待于进一步研究。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
汽车观察(2019年2期)2019-03-15
读与写·教育教学版(2017年10期)2017-11-10
民生周刊(2017年19期)2017-10-25
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
