
基于改进的Mca-sLDA模型的图像分类和标注模型研究
2020-01-04 07:11罗菊香
荆楚理工学院学报 2020年5期
罗菊香


摘要:从增强类标签和标注关联性出发进行验证研究,提出了一个类标签生成直接来自图像主题同时做图像分类和标注的概率主题模型,即改进的Mca-sLDA模型。给出了基于变分EM算法的模型参数推导过程以及使用该模型分类和标注图像的方法,并在两个真实数据集上对模型的分类和标注性能进行了验证。
关键词:图像分类和标注;变分EM;Mca-sLDA模型
中图分类号:TP391 文献标志码:A 文章编号:1008-4657(2020)05-0073-09
0 引言
计算机视觉在人工智能和深度学习的背景下又一次正在经历蓬勃发展,图像分类和标注[1]作为计算机视觉的关键技术也伴随着相应的挑战。图像分类是指自动的给图像分配类标,图像标注是指用关键词描绘图像中出现的事物或某些区域。图像的分类和标注技术在文本检索、图像信息管理、模式识别与机器学习等领域都具有重要的理论意义[2-3]。当今,图像标注和分类问题已经成为计算机视觉中的研究熱点。
随着词袋特征[4]的出现,概率主题模型的图像标注和分类算法[5-13]近年来受到研究人员和学者的广泛关注,并已成为图像标注和分类问题研究领域的一个主要工作。近年来研究人员已经做了大量工作,包括基于概率主题模型的图像标注方法[5-8],基于概率主题模型的图像分类研究[9-11],基于概率主题模型的同时做图像分类和标注模型[12-14]。
文献[5]在Corr-LDA模型的基础上利用图像类别来改进图像的标注性能。Xu等[6]提出了图像标注的Corr-CTM模型,该模型以Corr-LDA模型为基础引入了主题之间的相关性。文献[8]将图像视觉特征、环绕文本以及实体抽取所得到的能够描述图像中显著特征的词在概率主题模型中进行联合建模,学习到多种数据模态之间的关联关系。sLDA-bin模型是Putthividhya等[9]将sLDA模型和Corr-LDA模型结合提出的做图像分类的概率主题模型。近年,神经主题模型的图像标注和分类研究也相继展开。如无监督神经网络DocNADE模型[11],模型能够实现文档的检索与分类任务。Mca-sLDA模型[12]是CVPR会议上提出的同时做图像分类和标注的经典模型。文献[13]在Mca-sLDA的基础上提出了一个类标和标注相互促进的同时做图像分类和标注的模型。DocNADE的扩展模型SupDocNADE[14]模型可以对图像词、文本词及类别进行共同学习。
上述工作基于不同目的都取得了相对较好的性能。到目前为止,同时做图像分类和标注的工作相对较少,且大多是基于Mca-sLDA模型做的改进,注意到该模型中类标签和标注只是通过潜主题连接,这也就使得类标签和标注之间的关联性有一定限制,对于从增强类标签和标注关联性出发进行的验证研究还比较欠缺。
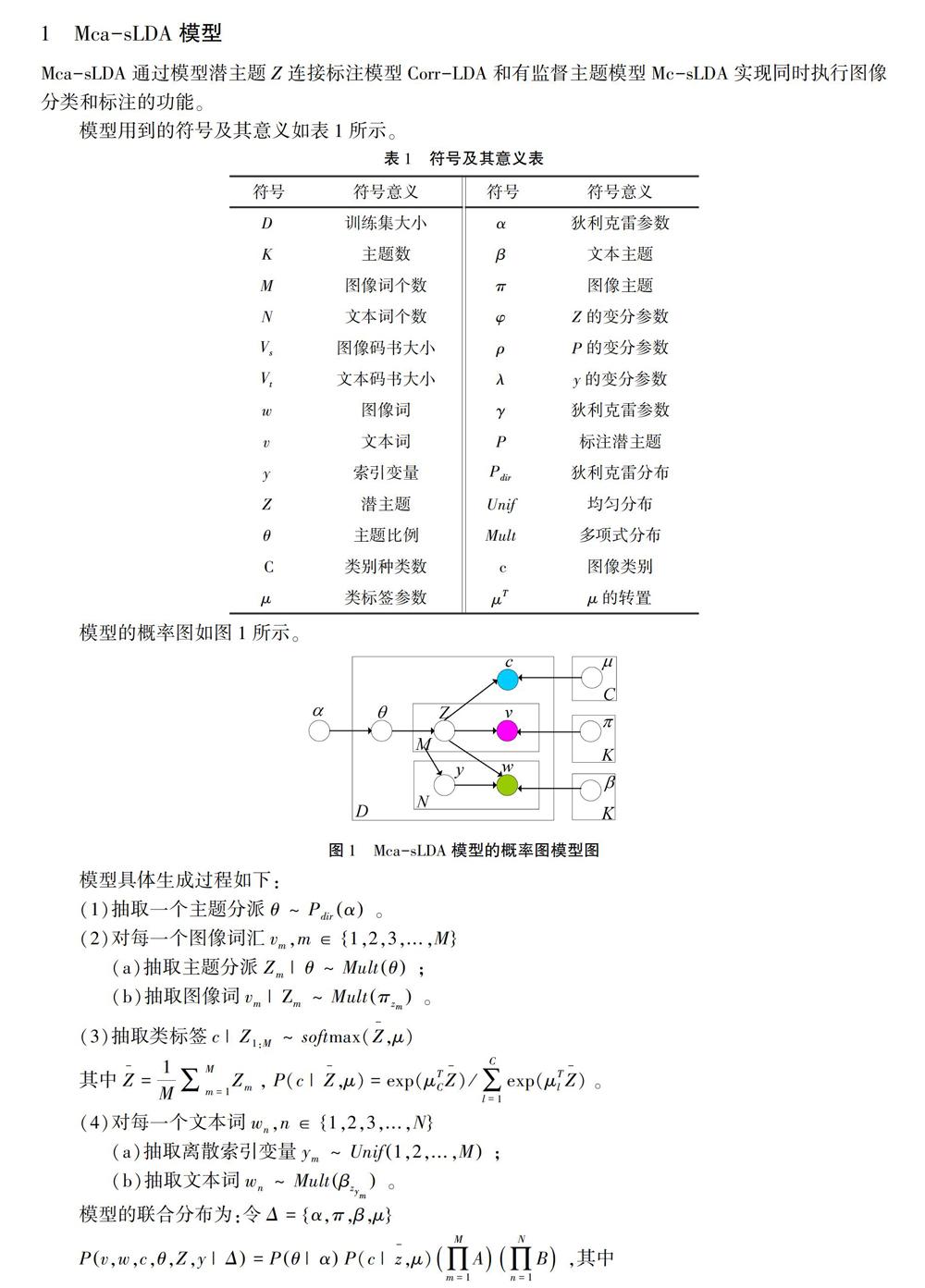
1 Mca-sLDA模型
Mca-sLDA通过模型潜主题Z连接标注模型Corr-LDA和有监督主题模型Mc-sLDA实现同时执行图像分类和标注的功能。
模型用到的符号及其意义如表1所示。
2 基于改进的Mca-sLDA模型同时做图像分类和标注的方法
本文在研究基于概率主题模型做图像分类和标注课题时注意到Mca-sLDA模型中类标签和标注只是通过潜主题Z连接,类标签和标注之间的关联性较弱。为此,本文对Mca-sLDA模型进行改进,新模型文本主题是按图像主题分布从已抽取的图像主题中抽取,模型类标签直接从文本主题中生成,提出了一个类标签生成直接来自图像主题同时做图像分类和标注的概率主题模型,模型简称为P-Mca-sLDA模型。本文推导了模型的参数估计算法,同时也给出了利用该模型分类和标注图像的方法,真实数据集上的实验也验证了模型的分类和标注性能得到了改进。
P-Mca-sLDA模型用到的符号及其所表示意义如表1所示,令E=v,w,c表示可观测变量,Δ=α,π,β,μ表示模型参数,ω=γ,φ,ρ表示变分参数。
模型具体生成过程如下:
模型的生成过程:从潜主题中生成图像,在已抽取的图像主题中按图像主题分布抽取文本主题,同时生成图像词和类标签,类标签生成过程的主题直接来自文本主题,这就使类标签和标注的关联性增强。
3 P-Mca-sLDA模型参数求解与图像分类和标注
3.1 变分E步骤
3.1.1 计算后验Dirichlet参数γ
3.1.2 计算参数φ
3.1.3 计算参数ρ
3.2 变分M步骤
经过E步骤,可求得变分参数ω=γ,φ,ρ的值。在M步骤中,固定变分参数ωd=γ,φ,ρ,d∈1,2,3,...,D,相对于模型参数Δ=α,π,β来最大化集合D上的log似然。即最大化
3.2.1 求解模型参数π
3.2.2 求解模型参数β
3.2.3 确定模型参数α:
本文没有对α进行优化,多次实验发现,将α设置成全为1的向量,模型性能较好。
3.2.4 确定模型参数μ:
3.3 图像的分类与标注
测试集中的图像没有标记类标和标注。对于分类,使用文本的主题频次P-分类图像,概率最大的类标将被作为此图像的类,也就是使得μTP-的期望最大时的类标。即确定类的公式如下该预测程序使主题频次的均值的期望代替图像的原始特征。每个类别有一个对应的的参数μ,与该图像最相近的类别会分派给这个预测图像。
4 实验结果与分析
为评估Mca-sLDA模型的分类和标注性能,本文在LabelMe和UIUC-Sport两个真实数据集上进行相关实验。分别采用分类平均准确度和F值来评价模型的分类和标注性能。
