
一种语义稀疏服务聚类方法
2020-01-05 07:00胡文生谢芳
软件导刊 2020年11期
胡文生 谢芳


摘 要:随着SOA迅猛发展和互联网上服务数量俱增,服务发现成为极具挑战性的工作。传统的服务发现方法在语义稀疏情境下精准度不高,主要是缺乏有效信息对发现工作的支持,无法对服务进行准确的类别划分。针对此问题,提出一种基于BTM面向Web服务短文本描述的服务聚类方法S3C,该方法的主要思想是利用BTM在短文本聚类过程中使用Biterm(词对)优势对服务描述进行潜在特征表示,基于服务潜在特征使用Kmeans聚类方法进行服务聚类。BTM采用词对的主题建模方式,能够极大程度地扩展文本信息,解决短文本中的关键词稀疏问题。采用PWeb数据集进行大量对比实验可知,该方法与经典聚类方法相比,类簇的平均纯度提高30%,平均熵降低近50%。
关键词:服务聚类;语义稀疏服务;BTM模型;服务发现;人工智能
DOI:10. 11907/rjdk. 202157
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)011-0006-05
A Semantic Sparisity Web Service Clustering Approach
HU Wen-sheng,XIE Fang
(School of Computer Science, Hubei University of Technology, Wuhan 430068, China)
Abstract: With the rapid development of SOA and the increasing number of service on the Internet, service discovery has become a challenging task. The accuracy of traditional service discovery approach is not high in the context of senmantic sparseness, which is mainly due to the lack of effective information to support it. Faced with this issue, this paper proposed a web service clustering approach S3C based on BTM model for short text web servcie description. This approach takes advantage of BTM in short text clustering to establish latent feature vector of Web service, and use Kmeans to cluster service based on latent feature vector. The BTM uses biterm to train topic-model, which can greatly expand information and solve semantic sparsity in short text. Compared with the classical clustering approach, the proposed approach improves the average purity by 30% and reduces the entropy by nearly 50%.
Key Words:Web service clustering; semantic sparsity service; BTM model; Web service discovery; artificial intelligence
0 引言
隨着面向服务的体系架构(Service Oriented Architecture,SOA)的迅猛发展,互联网上Web服务数目呈持续增长趋势。如何为用户快速有效地推荐合适的服务成为一项极具挑战性的研究任务。由于版权和资金等原因,大量UDDI服务注册中心相继关闭[1],基于搜索引擎技术的服务发现方法成为主流方式。常用搜索技术基本采用基于关键字匹配的方式,导致服务发现的精准度受到服务描述中缺少关键字或同形异义等因素的影响[2]。长期以来,服务聚类被视为解决该问题的一种有效途径,并得到了学术界的广泛关注[2-5],它将功能相似的服务聚类到一起从而减小搜索空间,提高服务发现效率[3]。例如文献[2]从WSDL文档中抽取服务特征建立特征向量,依照特征向量组织成不同的服务类簇。尽管上述服务聚类方法在不同情景下具有很好的效果,但是当面对服务描述语义稀疏时发现此过程中仍然会出现一些问题,造成这些问题的主要原因是诸多聚类算法在服务描述语义稀疏时,语义稀疏描述导致缺乏足够的统计信息进而无法进行有效的相似度计算[6]。互联网上最大的服务注册中心ProgrammableWeb(http://www.programmableweb.com,PWeb)提供了针对各类服务的注册功能,同时提供了服务关于功能的自然语言描述信息,通过这些信息进行服务分类。存在的关键问题是,这些服务描述往往以短文本形式存在,语义稀疏程度非常高。据统计,PWeb中服务数量最多的前10个分类中,服务描述文本平均长度仅为72,其中包含大量的无意义词语。面对互联网上与日俱增的服务规模,在语义稀疏的情境下,传统服务聚类方法精确度普遍不高,影响服务发现和推荐效率。
1 相关工作
文献[7]建立基于统计的模型动态计算服务相似性,促进搜索引擎发现服务的能力;文献[8]基于层次Agglomerative聚类算法,采用一种自下而上的方式将功能相似的服务组织成不同类簇,提高服务发现效率;文献[9]提出一种WTCluster服务聚类方法,利用Kmeans算法联合WSDL和标签相似性进行服务聚类;文献[10]利用Petri网技术针对服务功能和过程两个侧面的相似性进行服务聚类,提升服务发现效率;文献[11]提出一种支配服务的概念,通过分析服务支配关系构建服务与用户请求之间的相关性;文献[12]提出一种基于Info-Kmean与概要的增量学习方法,解决K-means算法中心点选取0值特征导致KL散度值无穷大的问题。
目前,基于主题模型的服务聚类研究有很多。文献[13]使用PLSA(Probabilistic Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)从服务描述中发现服务的潜在主题,使用主题模型对OWL-S服务的Profile和功能描述进行聚类;文献[9]利用LDA将WSDL中提取的特征描述构建成为层次结构,获取关于服务的主题—特征分布,建立基于主题的服务发现技术;文献[14]将WSDL文档预处理获取特征向量表征且与服务功能标签相融合,利用WT-LDA模型实现服务聚类。
上述方法在不同程度上提高了服务聚类效率,但仍然存在以下不足:①参与聚类的服务文档大多数是基于某种特定格式的服务描述文档,缺乏对自然语言描述的服务发现方法研究;②针对自然语言短文本描述的服务发现方法经常会遭遇语义稀疏的情况,而服务发现过程中鲜有考虑此方面的问题。因此,本文提出一种基于BTM对服务描述进行特征构建的方法,有效规避描述信息的语义稀疏问题,在此基础上利用服务潜在特征进行服务聚类的方法以提高服务聚类质量。
2 基于BTM的语义稀疏服務聚类方法
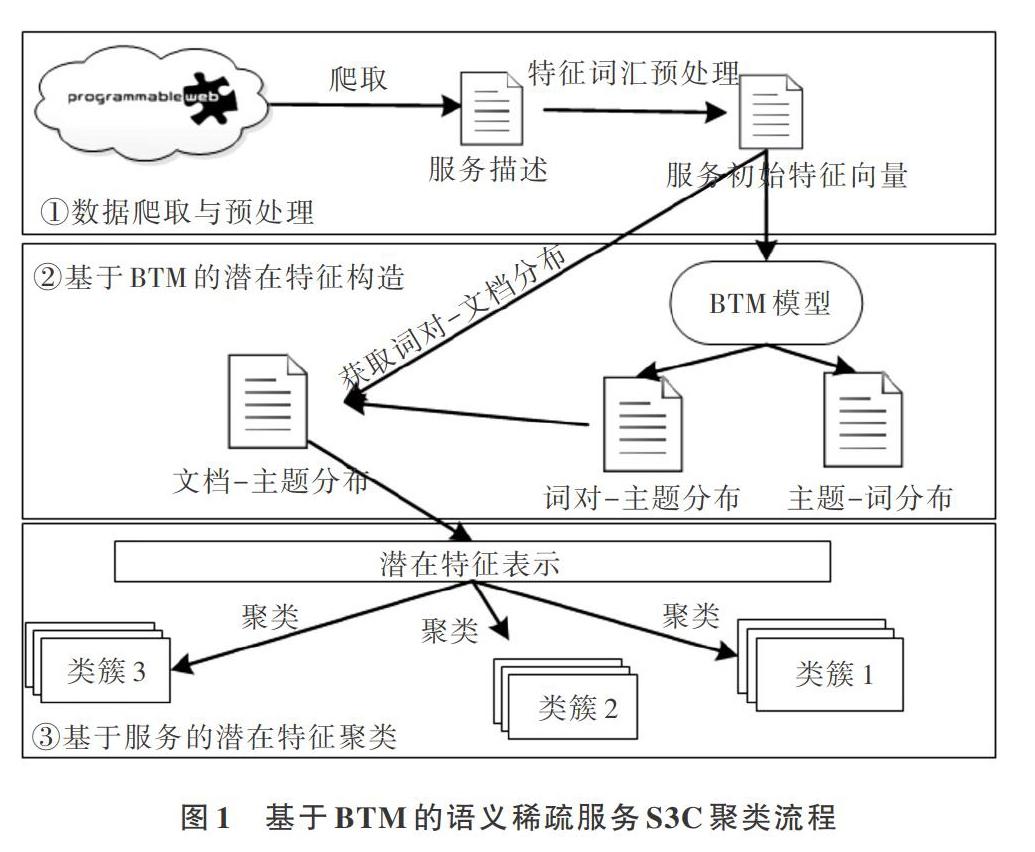
本文提出的基于BTM的语义稀疏服务聚类方法(Semantic Sparse Service Clustering,S3C)是一种基于主题模型进行服务聚类的方法,聚类过程主要分为3个阶段:数据爬取与预处理、基于BTM的潜在特征构造和基于服务的潜在特征聚类,具体流程如图1所示。第一阶段,主要从服务注册中心爬取服务的描述文件进行数据清洗;第二阶段,通过训练BTM模型获取文档—主题分布,构建服务的潜在特征;第三阶段,依据上阶段获取的服务潜在特征,利用聚类算法进行聚类工作。
2.1 数据爬取与预处理
从PWeb中获取服务的文本描述数据,获得这些信息之后,创建表征服务内容的初始特征向量。
(1)建立初始向量:基于自然语言处理包NLTK实现服务描述文档的分词。
(2)词干还原:利用NLTK提供的PorterStemmer算法将特征向量中的特征词汇进行词干还原,例如,Learned和Learning具有相同词干Learn。
(3)移除功能词:功能词汇指诸如“the”、“a”等对服务特征没有实际意义的词,需要从文档中移除此类功能词。
完成上述数据清理过程,为潜在特征构造提供数据支持。
2.2 基于BTM的潜在特征构造
BTM和LDA都是主题模型。BTM模型中,即使文本只有10个关键词,也会构造出45个Biterm,该方法极大程度地解决了LDA对短文本处理存在的弊端。同时,大量实验发现,使用Biterm对文本建模要比用单一词语建模能够更好地挖掘文本的隐藏主题。
2.2.1 BTM模型
BTM概率图模型如图2所示,首先生成基于BTM模型的语料库。从概率图模型可以发现:对于一个短文本的服务描述文档,不同词对所对应的主题Z=1,2,…,z是独立的,这是BTM与传统主题建模方法的显著区别。BTM针对整个语料集合[B]中每个词对[b(wi,wj)]进行建模,未对文档的生成过程进行建模,在学习过程中尚未获得服务文档的主题分布,得到的仅是词对—主题与主题—词的分布。为了获取文档—主题分布,本文采用贝叶斯公式推理得到服务文档的主题分布。
使用式(1)计算每个词对的概率。
使用式(2)计算整个语料库[B]的概率。
首先,根据全概率公式,使用式(3)表示文档主题—分布。
其中,利用贝叶斯公式计算词对—主题分布,如式(4)所示。
式(3)中,[P(b|d)]可以将服务描述文档中词对的经验分布作为[P(b|d)]估算值,具体如式(5)所示。
其中,[nd(b)]表示文档d中词对b出现的次数。
2.2.2 参数估算
利用BTM获得服务描述文档的主题分布,必须要估算出BTM中参数[θ]和[φ]的设置。常用参数估算方法有期望传播、变分推理和Gibbs抽样等[15],本文采用Gibbs抽样方法作为BTM的参数估算方法,如式(6)所示。
对于语料集合[B]中的每一个词对[b(wi,wj)],计算词对的条件概率分布,获得其主题分布[zb],其中[z-b]表示在集合[B]中除该词对外的主题分配,[nz]表示主题z分配给词对[b]的次数,[nwi|z]表示主题z分配给单词[wi]的次数,[nwj|z]表示主题z分配给单词[wj]的次数,M表示特征词的个数。
根据词对—主题分布情况,利用式(7)和式(8)计算出参数[θ]和[φ]。
其中,[φw|z]表示主题z中单词w的概率,[θz]表示主题z的概率,[B]是词对集合中词对的总数。
2.3 基于服务的潜在特征聚类
根据上文分析,通过式(3)使用贝叶斯公式计算得到服务的文档—主题分布[P(z|d)]。通过大量实验对比,采用式(9)的方法对每个服务描述进行表示,将服务表示转换成潜在特征。
将服务表示成潜在特征后,使用Kmeans方法对服务进行聚类,聚类具体过程见算法1。
算法1 语义稀疏的服务聚类算法
输入:服务集合SS,超参数[α]、[β],主题数目。
输出:服务类簇。
1 初始化Z,并使得|Z|等于聚类数目。
2 WHILE 算法未收敛 DO
3 FOR iter = 1 TO Niter DO
4 FOR [b∈B]DO
5 基于[P(z|z-b,B,α,β)],采样[zb]
6 更新[nz],[nwi|z]和[nwj|z]
ENDFOR
ENDFOR
ENDWHILE
7 得到参数Θ和Ф。
8 根据式(3)—式(5),建立主题—服务分布,使用式(9)建立服务潜在特征表征。
9 基于服务潜在特征,使用K-means算法对服务进行聚类,最终返回服务类簇。
第1-7步使用Gibbs抽样获得BTM模型的模型参数;第8步基于式(3)—式(5)计算获得服务的文档—主题分布,根据式(10)构建服务的潜在特征表示;第9步实现服务聚类,并返回服务的类簇信息。
3 实验评价
3.1 实验准备
实验数据来源于PWeb,该网站提供的服务具有详细的Profile信息。实验过程中爬取10 050个Web服务及其相关信息,筛选了包含服务最多的5个类别,总共包含2 761个Web服务,数据统计如表1所示。
使用纯度(purity)和熵(entropy)作为评价指标,其中,纯度越高,且熵越小,表明服务聚类的效果越好。设类簇[ci]包含个数为[ni],使用式(10)和式(11)计算每个类簇的纯度和所有类簇的平均纯度。
其中,[ni]代表类簇[ci]中包含的服务数目,[nji]代表第j个分类中被成功分入[ci]中的服务数目。
使用式(12)和式(13)计算每个类簇的熵和所有类簇的熵。
3.2 结果与分析
3.2.1 方法性能
为了评测本文所提出S3C方法的聚类性能,将其与3种常用的服务聚类方法进行性能对比。
(1)K-means:该方法是基于划分的聚类算法,实验过程中,直接使用K-means对服务进行聚类。
(2)Agglomerative:该方法是基于自底向上的层次聚类算法,实验过程中,直接使用Agglomerative方法对服务进行聚类。
(3)LDA:该模型是一种无监督的主题聚类模型,实验过程中,直接使用LDA模型对服务进行聚类。
在实验过程中,使用BTM开源代码(http://code.google.com/p/btm)构造潜在特征,超参数采用文献[16]中设置的[α]=50/K,[β]=0.01。
从图3得出如下结论:①S3C算法不论是在纯度还是熵上的表现都优于其它方法,特别是与直接使用LDA相比,算法性能得到明显提升,说明S3C算法是有效的;②K-means算法、Agglomerative算法和LDA模型在基于语义稀疏服务聚类的时候性能并不好,说明传统算法在语义稀疏的环境下容易遭受相似度计算困难的问题,进一步验证了文献[6]结论的正确性。实验结果说明,基于BTM的方法在语义稀疏的情境下进行服务聚类的优势,也进一步说明在聚类中考虑语义稀疏的必要性。
3.2.2 参数影响
主题个数K的选取是影响主题模型性能的重要因素。本文采用基于贝叶斯模型[17]选择方法,确定本文所用实验数据的主题数目。在不同K值下运行Gibbs抽樣算法,观测[log(P(w|K))]变化情况。具体实验结果如图4所示,当主题数目K=200时,后验概率能够得到最好性能,主题模型对于给定数据取得最佳拟合度。因此,S3C中主题个数K的取值选取为200。同时,S3C中对BTM超参数设定选择文献[16]中设置的[α]=50/K,[β]=0.01。
4 结语
本文基于BTM提出了一种面向语义稀疏的服务聚类方法S3C,使用公开服务注册中心Pweb真实数据进行相关实验,验证基于BTM的语义稀疏服务聚类方法的可行性和有效性[18]。与经典的服务聚类方法进行对比,S3C方法在聚类纯度、熵等方面均具有更好的聚类效果,从平均纯度看,该方法达到0.68,比其它方法提升30%左右;从平均熵看,该方法降低到0.41,性能提升50%左右。下一步研究重点:①在语义稀疏服务聚类的基础上研究面向领域的服务发现技术[19-20];②研究推荐与发现相结合的服务发现方法[21-22],提升服务发现过程中的个性化程度。
参考文献:
[1] Al-MASRI E, MAHMOUD QH. Investigating web services on the World Wide Web[C]. Proceedings of the 17th International Conference on World Wide Web,2008:795-804.
[2] ELGAZZAE K, HASSAN A.E and MAERIN P. Clustering wsdl documents to bootstrap the discovery of web services[C]. Proceedings of 2010 IEEE International Conference on Web Services (ICWS), 2010: 147-154.
[3] WU J, CHEN L, ZHENG Z. Clustering web services to facilitate service discovery[J]. Knowledge and Information Systems, 2014, 38(1):207-229.
[4] AZNAG M,AUAFAFOU M,JARIR Z. Leveraging formal concept analysis with topic correlation for service clustering and discovery[C]. Proceedings of 2014 IEEE International Conference on Web Services (ICWS),2014:153-160.
[5] CAO B, LIU X F, RAHMAN M, et al. Integrated content and network-based service clustering and Web APIs recommendation for mashup development[J]. IEEE Transactions on Services Computing, 2020, 13(1):99-113.
[6] TANG J, WANG X,GAO H. Enriching short text representation in micro-blog for clustering[J]. Frontiers of Computer Science, 2012, 6(1):88-101.
[7] SHU Z, XIE S,LI Q. Single-phase back-to-back converter for active power balancing, reactive power compensation, and harmonic filtering in traction power system[J]. IEEE Trans. Power Electron, 2011, 26(2):334-343.
[8] AGARWAL N, SIKKA G, AWASTHI L K. Enhancing web service clustering using length feature weight method for service description document vector space representation[J].Expert Systems with Applications,2020:113682.
[9] CHEN L, HU L, ZHENG Z, et al. Wtcluster: utilizing tags for web services clustering[C]. International Conference on Web Services, 2011:91-98.
[10] JINBO X, JUN R, LEI C, et al. Enhancing privacy and availability for data clustering in intelligent electrical service of IoT[J]. IEEE Internet of Things Journal, 2018: 1-5.
[11] SKOUTAS D,SACHARIDIS D.Ranking and clustering web services using multi-criteria dominance relationships[J].IEEE Transactions on Services Computing, 2010, 3(3):163-177.
[12] CAO J, WU Z,WU J. SAIL: Summation-based incremental learning for information-theoretic text clustering[J].IEEE Transactions on Cybernetics,2013, 43(2):570-584.
[13] CASSAR G,BARNAGHI P,MOESSNER K. Probabilistic methods for service clustering[C].Proceedings of the 4th International Workshop on Semantic Web Service Matchmaking and Resource Retrieval, 2010,99: 1-4.
[14] CHEN L, WANG Y, YU Q, et al. WT-LDA: User tagging augmented LDA for web service clustering[C].Proceedings of Service-Oriented Computing,2013:162-176.
[15] 李征, 王健, 張能, 等.一种面向主题的领域服务聚类方法[J].计算机研究与发展, 2014, 51(2):408-419.
[16] CHENG X,YAN X, LAN Y, et al. BTM: topic modeling over short texts[J]. IEEE Transactions on Knowledge and Data Engineering, 2014,26(12):2928-2941.
[17] ROSEN-ZVI, GRIFFITHS T, STEYVERS M, et al. The author-topic model for authors and documents[C]. Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence,2004:487-494.
[18] ZHANG N, WANG J, HE K, et al. Mining and clustering service goals for RESTful service discovery[J]. Knowledge and Information Systems, 2019, 58(3):669-700.
[19] 陈婷, 刘建勋, 曹步清. 基于BTM主题模型的Web服务聚类方法研究[J].计算机工程与科学, 2018, 40(10): 25-33.
[20] HE Q, ZHOU R, ZHANG X, et al. Keyword search for building service-based systems[J]. IEEE Transactions on Software Engineering, 2017(b):658-674.
[21] ZHANG N, WANG J, HE K, et al. Mining and clustering service goals for RESTful service discovery[J]. Knowledge and Information Systems, 2018, 58(5):1-32.
[22] DING F, WEN T, REN S, et al. Performance analysis of a clustering model for QoS-aware service recommendation[J]. Electronics, 2020, 9(5):740.
(責任编辑:孙 娟)
收稿日期:2020-09-20
基金项目:湖北省自然科学基金面上项目(2020CFB807);湖北省教育厅科学技术研究计划重点项目(D20201402);湖北工业大学高层次人才科技启动基金项目(337396)
作者简介:胡文生(1975-),男,博士,湖北工业大学计算机学院讲师,研究方向为人工智能与大数据;谢芳(1981-),女,博士,湖北工业大学计算机学院讲师,研究方向为智能计算与软件工程。本文通讯作者:谢芳。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
开放教育研究(2020年2期)2020-03-31
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
电子设计工程(2015年6期)2015-02-27
大连民族大学学报(2015年2期)2015-02-27
