
基于模糊聚类的“愤怒”表情细分方法研究
2020-01-10 06:38林巧民
计算机技术与发展 2020年1期
林巧民,潘 敏
(1.南京邮电大学 计算机学院,江苏 南京 210023;2.南京邮电大学 教育科学与技术学院,江苏 南京 210003)
0 引 言
情感是伴随着认知和意识过程的生理以及心理状态[1],在人际交往中起着非常重要的作用。近年来国内外许多研究人员针对情绪识别已经做出了很多的研究,从单一模态情绪识别[2]到多模态情绪识别[3],这些研究大多都是区分六种基本的面部表情。王蓓等[4]提出了一种基于决策层融合机制的人脸表情和语音多模态方法,取得了一定的融合效果。Zeng等[5]提出了一种基于多流隐马尔可夫模型(multistream hidden Markov,HMM)的人脸表情和语音多模态方法,融合后取得了72.42%的识别率。Wang等[6]采用核交叉模型因子分析方法对语音模态和人脸表情模态进行特征降维和特征融合。然而对于相同的面部表情,表情强烈程度不同,表现出的情感状态也会不一样。如愤怒的表情程度可分为生气和到愤怒之间的不同等级。生气表示一种略微愤怒,程度较轻;愤怒则表示人处于一种非常生气的状态。面部表情强度估计是情绪识别的一种延伸,对其进行相关研究的人员相对较少。Mahoor等[7]使用二元分类器的6级分类来进行层次划分,他们从婴儿面部图像的几个代表性行动单元评估了AU强度。但是,无法避免类之间的类重叠,这使得这些方法的鲁棒性较差。在Delannoy等[8]的研究中,他们使用基于图像的分类方法用于三个级别(低,中和高)的强度估计。从以上研究中能够观察到表情的层划分都是预先设置的,于是文中提出了一种基于模糊聚类的表情层次细分方法,该方法采用了一种聚类融合算法,可以不用提前设定强度等级就可以自动获得强度等级。
随着互联网相关汽车行业的快速发展,行业中的缺陷也逐渐暴露出来。如乘客的安全问题,尤其是女性乘客的安全问题。夜晚打车出行的顾客,一旦出现问题,人身安全将无法得到保证,因此对于司机的情绪监控就尤为重要。除此之外,也可应用于公交司机的情绪检测。公交是人们日常生活中必不可少的交通工具,如果公交司机的情绪处于一种极端情绪中,将会对众多乘客的生命安全造成极大的威胁。反之,乘客如果情绪失控影响司机驾驶也会带来严重的交通事故。为了解决这一问题,网约车公司和公交公司可以在合法的车辆上装载摄像,将情绪分析技术与系统设备相结合,应用于检测驾驶途中司机的情绪变化或者司机的“愤怒”情绪。情绪分析技术能够从获取的视频中自动分析情绪类别,再此基础上将情绪强度解析出来。当粗粒度的情绪类别获取之后,如果确定是“愤怒”情绪也不会立刻就提醒后台,而是当“愤怒”情绪强度超过设定的情绪强度阈值时,才会提醒后台关注此车辆的相关信息,提高后台工作人员的工作效率,保障乘客的人生安全[9]。
1 面部表情特征提取和分类识别
情感信息的提取能够通过“生理信号”进行分析、判别,这种方式应用在非医学领域将极大地增加了实验的难度。反之,通过对人脸的检测和分析,极大地提高了实验的可行性。目前流行的人脸检测技术为卷积神经网络(convolutional neural networks,CNN)和VJ(viola-jones,VJ)算法,文中采用的传统的VJ算法[10]已经可以满足需求。VJ算法主要用于人脸的检测和定位,在预处理阶段将图像中与面部无关的背景删除。
特征提取技术中有两种比较常用的技术是PCA(主成分分析)和LDA(线性判别分析),这两种方法常用于人脸识别的研究。PCA和LDA的不同之处在于前者主要的任务是降维,而后者是加强区分从不同类别中获得特征。双向主成分分析(bi-directional principal component analysis,BDPCA)[11]和最小平方线性判别分析(least-square linear discriminant analysis,LSLDA)[12]是对PCA和LDA的一种改进,算法性能得到了提升,对于人脸识别的准确率也有所提升。PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,称为主成分(principal components)。新的低维数据集会尽可能保留原始数据的变量,但是计算比较复杂。BDPCA优于PCA在于它可以在图像的行和列方向上找到最优投影子空间,而无需矩阵进行矢量变换,也不会产生协方差矩阵,减少了处理时间。将BDPCA算法和LSLDA算法进行融合,先以BDPCA算法对预处理后的图像进行降维处理,然后将BDPCA的输出作为LSLDA的输入,得出投影子空间。
从LSLDA阶段得到的面部特征传送到高斯核映射,并通过核映射形成核矩阵。核矩阵中存储了一些在高维空间中数据的相似信息。面部特征同样也传送到拉普拉斯图映射中,并通过拉普拉斯映射形成了拉普拉斯矩阵。拉普拉斯矩阵中存储了在低维空间中数据的关系信息。OKLC模块表示一种优化的k-均值拉普拉斯聚类[13],为了获得VOKLC(最优的核拉普拉斯聚类),需要OKLC模块找到核函数和拉普拉斯矩阵的最优系数。在测试阶段,为了获得用于测试数据的核矩阵和拉普拉斯矩阵,在LSLDA阶段提取到的测试特征进行映射。测试数据的两个矩阵训练阶段使用加性模型[14]和从OKLC模块的最优系数进行合并。最后通过RBF分类器对特征进行分类识别。表情识别系统框图如图1所示。
2 表情强度层次划分
对于同一种面部表情来说,强烈程度不同,反映出的情感状态也会不同。当粗粒度情绪被识别之后,从RBF情绪识别分类器末端选择了200帧被标记为“愤怒”的连续图像样本,这200帧包含了不同强度等级的“愤怒”。人的愤怒情绪虽然是在很短的时间内产生的,但是也是有过程的,因此该采样样本体现了愤怒情绪的发展以及生成过程。文中将对这200帧连续图像进行强度等级划分。

图1 表情识别系统框图
聚类分析是很多分类的基础,目的是从样本数据中找出本质联系,从而鉴别出这些样本从属于不同的聚类。在数据处理方面将模糊均值聚类和减法聚类进行融合对数据进行处理,解决模糊C聚类对于初始值设定敏感并且容易陷入局部最优解的问题。所以文中提出了一种模糊聚类的表情层次细分方法来对已识别的情绪进行细分以对应不同强度的情感状态。首先用融合聚类算法对样本进行聚类,得到不同的聚类中心。接着把聚类后的数据由MATLAB中的ANIFS(自适应神经模糊推理系统)进行训练,最后将“愤怒”进行层次上的划分[15-16]。
2.1 模糊C均值(FCM)聚类算法
FCM算法[17-18]也是一种聚类算法,它是基于划分的。其核心算法是将被划分为不同聚类的对象之间的相似度减为最小,而相同聚类之间的相似度增加到最大。对普通C均值聚类算法的改进方法之一有模糊C均值。C均值的算法思想是将提供的数据进行硬性划分,一个样本将会精确地归属某一个聚类,FCM将模糊地对数据进行划分,样本属于某一类聚类的程度由隶属度来表示,一般记为μA(x),其自变量的取值范围是可能归属于集合A的全部对象(也就是说,集合A在所有空间),取值区间为[0,1]。其中μA(x)=1表示x全部属于集合A(x∈A)。在空间X={x}定义的隶属度函数定义了一个模糊集合A,或定义在域X={x}上的模糊子集。对于有限个对象(x1,x2,…,xn),模糊集合可以表示为:
A={μA(xi),xi∈X}
(1)
以上描述了模糊集这一概念,可以了解到一个元素归属于某个模糊集不再像C均值一样是硬性分类。可以假设由聚类形成的簇为模糊集,那么属于聚类的每一个样本点的隶属度在区间[0,1]中。在对数据集的隶属度进行归一化处理后,总和为1:
其中,c表示聚类个数;uij表示隶属于聚类ci的第j个样本的隶属度。
那么,FCM的目标函数为:
(2)
其中,0≤uij≤1;ci为模糊组i的聚类中心;dij=‖ci-xj‖为第i个簇中心ci与数据点xj之间的距离;m>1为权重指数。
聚类中心ci的计算公式如下:

(3)
用式4更新隶属度:
(4)
算法步骤描述如下:
(1)m为指定参数,C为聚类中心数,ε为最大迭代次数以及迭代停止误差;
(2)对聚类中心C进行初始化;
(3)计算初始距离矩阵D,由dij组成;
(4)根据式4来更新隶属度,得到隶属度矩阵U,如果距离为0,则将该点和对应类的隶属度设置为1,其余的设置为0;
(5)按式3更新聚类中心;
(6)重新计算距离矩阵,并根据式2计算目标函数;
(7)如果与上一级的目标函数的绝对差小于迭代停止误差或迭代次数达到最大,那么就立刻停止,否则转步骤4,同样也可以判断用前后两个隶属度矩阵差;
(8)对应聚类的隶属度哪一个最大,则将样本点划分到哪一个聚类。
2.2 FCM与减法聚类融合的模糊聚类
FCM在对数据进行模糊聚类时,它对初始值的设定十分敏感,初始值的设置不佳将会使最终结果处于局部最优解状况,针对这一问题引入了减法聚类。在FCM进行聚类之前,引入减法聚类来设定FCM的初始值,不仅能获得一开始的聚类个数,而且能提高聚类速度,从而解决局部最优解的问题[19]。
基于密度的聚类算法的一种方式有减法聚类,其算法原理是把每个数据点都当作一个聚类中心,计算每个数据点成为聚类中心的概率的方法是按照每一个数据点周边的数据点密度来计算。被选做聚类中心的数据点的特征是其在周围的数据点中具备最高的数据点密度,并且排除那些离该数据点相近的数据点成为聚类中心的可能[20];当选择了第一个数据中心以后,采用与上述一致的方法,从可能成为聚类中心的其他数据点中选择出下一个聚类中心。直到全部剩下的数据点成为聚类中心的概率低于设置的阈值。融合基本过程如下:
(1)假定所有的数据点都在一个单位超立方体内,即各维的坐标都在0~1之间,定义数据点xi的密度指标为:
(5)
这个数据点的密度范围由半径ra决定,在这个数据点密度范围内的点对密度影响较大;反之在此数据点密度范围外的点对密度影响较小。算出每个数据点的密度之后,第一个聚类中心为密度最高的那个数据点,将这个数据点记作xi。
(2)把Dxi设为它的密度时,其他数据点密度根据Dxi依次由式6修正为:
(6)
其中,rb是一个常数,它定义的密度范围显著减小,一般情况下大于ra。之后继续重复上面的步骤,直到剩下的可能作为聚类中心的数据点的概率小于设定的某个阈值。
(3)初始化模糊隶属度矩阵U(0)。
(4)对每一步用式3算出c个聚类中心ci。
(5)在第t步更新隶属度矩阵U(t):如果对任意的k,j存在dkj(b)>0,那么得:
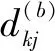
(6)‖u(b+1)-u(b)‖≤ε,则停止;否则令t=t+1并返回步骤4。
3 实验结果与分析
前面已经用eNTERFACE’05数据库作为第一部分情绪识别阶段的训练集和测试集,这节继续用该数据库对情绪强度层次划分的性能进行评估。该数据库共记录了1 293个成人的人脸表情样本,包含了最常见的6种情绪:高兴、悲伤、厌恶、生气、恐惧、惊讶。接着在扩展的Cohn-Kanade数据集(Ck+)上对强度划分性能进行评估。最后,文中招募了10名志愿者分别采样了20秒的视频,让志愿者通过观看视频的方式产生愤怒的情绪,情绪由平缓到极端愤怒。
3.1 在eNTERFACE’05数据库的评估
eNTERFACE’05数据库是一个同时记录人脸表情模态和语音模态的双模态情感数据库。该数据库共记录了1 293个成人的人脸表情和语音数据样本。图2为eNTERFACE’05数据库各种人脸表情样本。

图2 eNTERFACE’05数据库各种人脸表情样本
从第2节中的RBF神经网络分类器末端选择75%被标记为“愤怒”的表情作为训练样本,这多帧图像包含了不同强度等级的“愤怒”。首先用融合聚类算法对样本进行聚类,之后再将训练样本进行分类处理。接着将聚类后的数据由MATLAB中提供的自适应推理系统来进行训练,对面部表情“愤怒”进行层次划分。在实验过程中还可以得到每一个样本点到聚类中心的距离,当聚类中心最终确定以后,就可以对‘愤怒’表情进行层次划分。d1表示样本点到第一个聚类中心的距离,d2表示样本点到第二个聚类中心的距离,依此类推,dn表示样本点到第n个聚类中心的距离。将L=d1/(d1+d2+…+dn)表示为愤怒的等级。愤怒等级划分流程如图3所示。

图3 “愤怒”等级划分系统框图
训练结果和拟合图如图4和图5所示,训练误差为0.002 339 2。

图4 “愤怒”表情训练误差

图5 “愤怒”表情训练拟合
将数据库剩余的25%被标记“愤怒”的图像输入到ANFIS系统中进行检验。训练样本受到检验样本的拟合,由图可知,两者基本是相互符合的,*在圆圈内表示没有出现过拟合的现象,准确率达到81%。
3.2 在Ck+情绪数据库上的评估
文中采用Ck+人脸表情识别数据库作为测试集,这个数据库包括123个主题和593个图像序列。在这593个图像序列中,有327个图像序列有情绪标签。选取其中75%的愤怒情绪作为训练集,剩下的25%作为测试集。这个数据库比较适合本次实验,因为它有连续的“愤怒”表情,并且已经标注了情绪,为本次实验提供了便利。图6为Ck+数据库中一位受试者“愤怒”表情的部分连续图。
由图6可以观察到受试者的愤怒情绪程度越来越高,对应的愤怒强度指数也越来越大。这符合人体情绪的生成过程。Ck+数据库中的数据分为不同的主题,规律性较好,通过测评准确率可达83%。
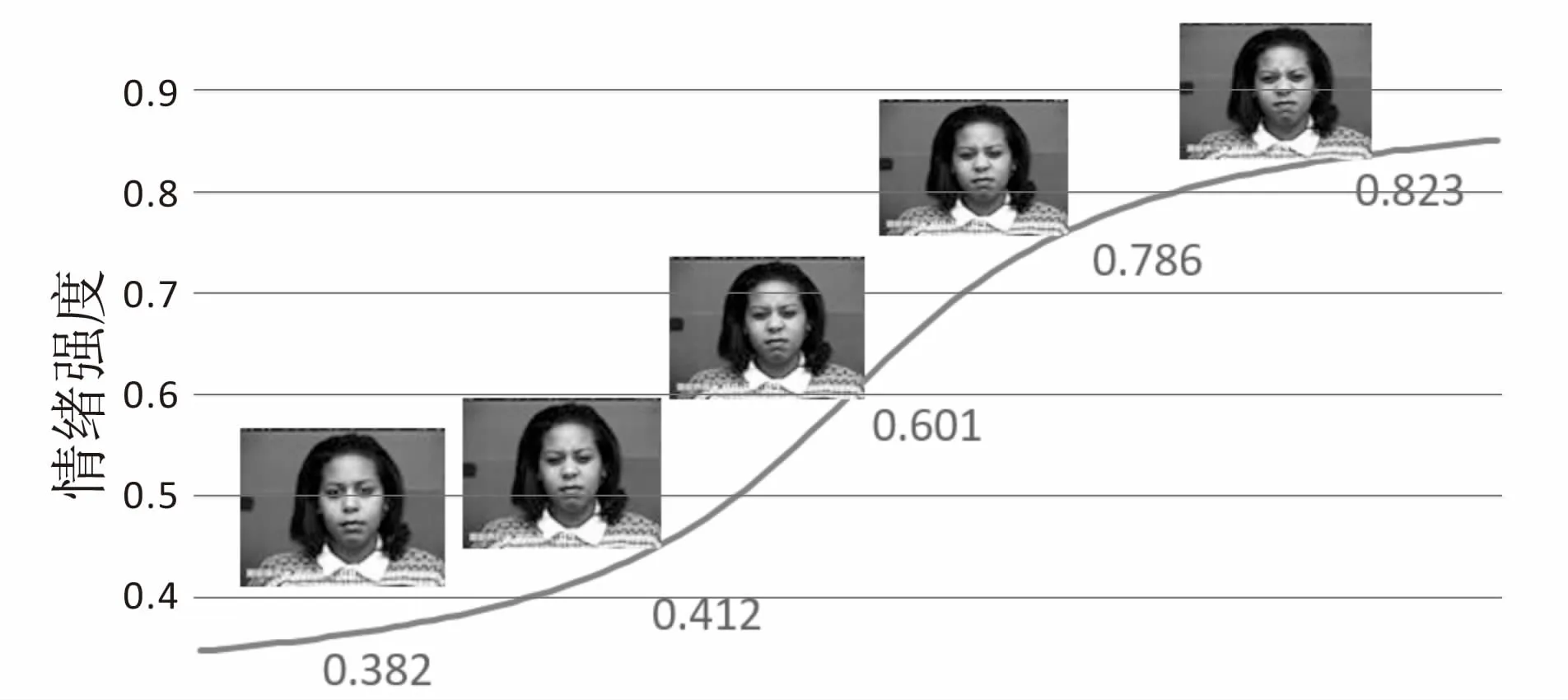
图6 CK+数据库上的情绪强度走势
3.3 随机采样对情绪层次划分的评估
对于测试集,选择招募10个年龄和性别都不相同的志愿者录制了10段视频。视频的前半部分是“生气”的表情,后半部分是“愤怒”的表情。前半部分是提供的“愤怒”程度较低的测试图像帧数,后半部分是“愤怒”程度较明显的测试图像帧数。其中二位志愿者的测试结果如图7所示。

图7 愤怒的测试结果
从志愿者录制的“愤怒”视频中截取三帧图片测试,结果如图7所示,较准确地描述出了被测试者的愤怒程度。表1显示了在三个不同的数据集上的准确率,其中Ck+数据集上的准确率最高。

表1 三种数据库识别结果
4 结束语
面部表情细分方法的研究对于解决交通安全隐患问题具有重要的研究价值,此方法可以应用于网约车行业的乘客的安全问题,尤其针对夜间打车乘客的安全问题和公交乘客的安全问题,通过监测驾驶员的情绪程度,能够对乘客起到一定的保护效果。文中提出了一种基于模糊聚类的表情层次方法,首先通过BDPCA+LSLDB提取视频中的图片特征,用RBF神经网络识别出情绪。在此基础上,将模糊聚类中的减法聚类和模糊C-均值聚类相结合,这样开始的聚类个数不仅可以自动获得,聚类的速度还能够得到提高,解决局部最优解这个问题。再通过ANFIS系统对识别出的情绪类型进行进一步的细分。接着通过两个标准数据集检测该方法的可行性。实验结果表明,在两个标准数据集上,该方法能够较好地划分情绪层次和估计情绪强度,采集得到的数据库在准确率上比标准数据库略低。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机应用与软件(2021年7期)2021-07-16
奥秘(2021年5期)2021-06-15
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
读与写·教育教学版(2017年10期)2017-11-10
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
