
基于期望效用-熵模型的基金评级方法及其在中国基金评级中的应用
2020-01-16 01:41杨继平石晨晓DanielCHIEWJudyQIUSirimonTREEPONGKARUNA
中国管理科学 2019年12期
杨继平,石晨晓,Daniel CHIEW,Judy QIU,Sirimon TREEPONGKARUNA
(1.北京航空航天大学经济管理学院,北京 100191;2.西澳大利亚大学商学院,珀斯 6009)
1 引言
截至2016年7月底,我国共有开放式基金2965只,基金净值达79806.03亿元,开放式基金只数占全部基金只数的93.27%(数据来源于中国证券投资基金业协会),成为证券市场中的重要组成部分。开放式基金,由于其投资便利、风险适中,以及收益稳健等特点,吸引着越来越多的普通投资者,逐渐成为当前的主要投资品种。在众多基金中,投资者选择投资哪些基金就显得非常重要。随着基金规模的快速扩大,众多基金评级机构提供的基金评级结果可以帮助投资者进行决策。但是,这些基金评级结果只有基金历史评级对未来业绩具有预测性时,对投资者才具有参考价值。
现在国内外主要的基金评级方法有晨星、理柏(Lipper)和Zacks评级,使用风险调整后收益对基金划分星级,对于基金评为5星到1星。这其中,晨星评级是最有影响力的基金评价方法,被认为是投资者在选择共同基金时最重要的量化参考指标[1]。共同基金较高的评级往往意味着更好的业绩[2]。Del Guercio和Tkac[3]研究得到当共同基金的晨星评级提高后,共同基金会获得正向的现金流,反之会获得负向的现金流;即投资者资金投向星级提高的基金,流出星级降低的基金,这表明投资者以基金评级作为基金业绩表现的重要依据。国内学者王擎等[4]研究也证实明星基金的正向现金流入要大于非明星基金。这些研究表明投资者相信这些基金评级结果包含关于基金未来业绩的重要信息。然而,进一步研究表明晨星评级提供的基金业绩预测能力较小,而且不能够很好区分评级星级较高基金和普通基金的差别。如Sauer[5]对于1976-1992年美国所有晨星评级的共同基金的研究表明以投资为目标的基金业绩的持续性不明显,在这种意义上基金前一期的业绩对后期业绩参考价值较小。Blake和Morey[6]以1992-1997年期间美国的股票基金作为样本,使用虚拟变量回归来评估基金评级的预测能力,结果表明晨星评级可以预测低评级基金的表现,高评级和中等评级基金的基金业绩没有明显差异。同样的,Gerrans[7]也指出尽管大部分的投资者进行投资时主要依据晨星评级的结果,但事实是在短期内,基金评级结果缺乏预测能力,高评级的基金与低评级基金没有明显差异。Füss等[8]研究了德国晨星评级的预测能力,Sah等[9]研究了美国房地产共同基金市场晨星评级的预测能力,Watson等[10]研究澳大利亚的超级年金,研究结果均表明晨星评级最多可以预测低评级基金的表现。
由于基金评级作为投资者决策的初始参考信息,基金评级结果缺乏预测能力对于投资者的参考价值得到质疑[1]。另外,Lisi和Caporin[11]分析了晨星风险调整后收益(Morningstar risk-adjusted return,MRAR)对于风险描述的情况。MRAR以期望效用理论为基础,可能没有考虑到基金面对的适当比例的风险,而忽略了基金本身的风险和投资者的偏好。晨星评级对于风险的不适当调整可能源于其评级依赖于期望效用理论。期望效用理论是一种被广泛接受的理性风险决策方法,但期望效用理论没有给出风险和回报的明确度量方法[12]。而Allais悖论指出期望效用理论不能描述表示人们进行风险决策时的偏好[13]。Kahneman和Tversky[14]也指出人们在实际决策时偏离期望效用理论描述的行为。
Shannon信息熵可以度量一个风险投资决策的不确定性[15]。Yang Jiping和Qiu Wanhua[16]将信息熵引入风险型决策理论中,提出了期望效用-熵(EU-E)模型,该模型将期望效用和信息熵结合起来,可以更加准确地描述决策者对于风险的感知;并证明了在一定条件下可以解决不能用均值-方差模型合理解决的风险型决策问题,且可以解释Allais悖论等。Yang Jiping和Qiu Wanhua[17]改进了EU-E模型,使得模型在某些条件下具有一定的规范性质,运用这种模型可以直观地解释展望理论中的确定性效应等决策问题。Yang Jiping等[18]进行了实证方面的研究,应用EU-E模型对股票进行筛选,研究结果显示利用EU-E模型优于利用期望效用模型选择股票进行投资组合优化的结果。另外,作为不确定性度量的Shannon熵也被采用在各种金融模型中的风险度量。Ormos和Zibriczky[19]研究得到在度量金融风险时发现Shannon熵具有优于标准差和β系数的特性。Caraiani[20]研究发现熵可以预测市场的动态变化,显示熵在预测基金业绩方面具有重要的特性。
针对晨星评级的上述考虑风险调整和预测能力不足的缺陷,Chiew等[21]提出期望效用-熵(EU-E)模型对基金进行评级的方法,并在美国基金市场上进行了实证研究。在本文中,我们将进一步研究该基金评级方法在中国基金市场中的适用性。我们首先对基金进行评级,并利用固定效应面板数据回归方法研究基于期望效用-熵模型基金评级的基金业绩预测能力;分别采用Sharpe指数、Jensen、Fama-French三因素和Carhart四因素α等四个不同的风险调整业绩指标作为度量基金的业绩预测指标。进一步,我们对基于期望效用-熵的基金评价方法和晨星评级利用这四个指标进行预测能力比较;具体采用2011年2月1日到2016年6月30日期间中国的261只开放式基金为研究样本。
2 基于期望效用-熵模型的基金评级方法
本文首先介绍期望效用-熵模型[16-17],以及基于期望效用-熵模型的基金评级方法如下[21]。

(1)
式中,λ∈[0,1]为常数,Ha(θ)表示行动方案a对应状态的熵,X(a,θ)表示行动方案a在状态θ下所能产生的后果(收益或损失)。
在期望效用-熵风险度量中,期望效用反映决策者的主观偏好,熵度量风险行动对应状态的客观不确定性。期望效用-熵风险度量通过系数λ将两部分结合起来,将决策者对于风险的感知表示为风险行动的期望效用和状态的熵线性组合。
在定义中,λ表示决策者对于所面临决策问题的主观期望效用和决策行动对应状态的客观不确定性大小的平衡系数,它随着决策者不同而不同,称为决策行动的期望效用-熵平衡系数。当决策者希望决策结果的期望效用的确定性程度的影响大时,也即决策结果的不确定性对行动方案影响小时,λ接近于0;如果希望期望效用的确定性程度有完全影响时,λ=0;此时期望效用-熵模型的风险度量与期望效用模型一致。当决策者希望决策的期望效用的确定性程度的影响小时,也即决策结果的不确定性对行动方案影响较大时,λ接近于1。当每个行动对应的状态有相同的分布时,即每个行动方案a对应的状态θ的熵都相同,此时状态θ的熵对于决策行动的选择无影响。
投资者选择基金进行投资实际上是风险型决策问题,假设投资者从m只基金中选择部分绩优基金进行投资,我们基于期望效用-熵模型风险度量方法对基金进行排序或评级,然后再进行选择。具体地,本文应用如下基于期望效用-熵的基金评级方法。

由概率分布,可得投资基金Si的规范化熵为:
(2)
其规范化期望效用为:
EU(ai)
(3)
根据期望效用-熵模型风险度量方法,得到投资基金Si的行动方案ai的期望效用-熵风险为:
(4)
将投资基金Si的期望效用与公式4定义的风险相减得到第i只基金Si的净期望效用为:
NetEU(ai)=EU(ai)-R(ai)
(5)
净期望效用反映了决策者考虑了行动方案的不确定的情况下,得到的经过期望效用-熵风险调整后净效用。该净效用既考虑期望效用,又考虑到期望效用-熵风险度量因素,进行调整后期望效用相对可以取得较大权重。
对于行动方案a1和a2,如果NetEU(a1)>NetEU(a2),则行动方案a1优于行动方案a2;即净期望效用越高,行动方案越优。根据净期望效用对基金进行排名评级。不同于Chiew等[21]中利用多个样本期基金净期望效用排名的加权平均,本文采用3年期基金净期望效用,使用与晨星评级相同的分位数给予当月排名后的基金5星到1星级的评级,即排序在前10%的基金评为5星级;在接下来的22.5%评为4星级;中间的35%评为3星级;随后的22.5%评为2星级;最后的10%评为1星级。
3 基金评级预测能力评价的面板数据回归模型
在对基金业绩表现的评价上,本文主要采用Sharpe指数、詹森α、Fama-French三因子α和Carhart四因子α四大经典风险调整业绩评价指标进行中国基金业绩表现的衡量与检验[22-24]。Sharpe指数是用来计算风险调整后收益的经典业绩评价指标[25]。詹森α是1968年詹森在对美国共同基金的业绩进行研究后,基于资本资产定价模型(CAPM)提出的基金业绩评价指标[26]。随后,Fama和French[27]提出使用上市公司的市场收益率因素、规模因素和账面市值比可以解释证券回报率的差异。Carhart四因子模型是在三因子模型的基础上加入了动量因子,其研究发现证券的动量效应对基金业绩有非常明显的影响,因此,首先将证券的动量效应纳入了基金业绩的考察之中[28]。
使用面板数据模型来评估EU-E模型评级和晨星评级的预测能力,Sharpe指数、詹森α、Fama-French三因子α和Carhart四因子α分别作为被解释变量,评级结果作为解释变量。我们拟合以下回归模型:
Si,t+1=δ5+δ4D4it+δ3D3it+δ2D2it+δ1D1it+εit
(6)
其中,Si,t+1为基金i在样本外t+1期的业绩评价指标;D4it,D3it,D2it,D1it为虚拟变量,如果基金i在t期分别被评为4,3,2,1星级,则取值为1,否则为0;i=1, 2, …,N,N是每个样本中的基金个数;t=1, 2, …,M,其中M是每个样本中的月数。
系数δ5对应于5星级基金的业绩。因此,其余虚拟变量的系数表示对应的星级类别相对于5星级基金的业绩。例如,如果δ4为负,这表明在该样本期,4星级基金平均表现低于5星级基金。因此,如果基金评级结果具有良好的预测能力,那么评级越高的基金对应的系数应该越大,即我们应该观察到δ1<δ2<δ3<δ4<0<δ5。
对于面板回归模型,选择合适的估计方法很重要。静态面板回归模型有三种估计方法,即混合回归模型、固定效应模型和随机效应模型。本文使用F检验和Hausman检验来确定模型的估计方法[29-30]。
F检验用于确定模型是混合回归模型还是固定效应模型。相对于一般线性回归模型,混合回归模型可以有效地扩大样本容量,增强估计的有效性。在面板数据在时间和横截面个体之间均无显著性差异的假设成立的前提下,混合回归模型比固定效应模型估计的效率高。F检验的原假设为:相对于固定效应模型,混合回归模型更有效。F检验的统计量如下所示:
(7)


(8)

Hausman检验统计量渐进服从于自由度为k的χ2分布,若在置信水平下接受原假设,则使用随机效应模型来估计;否则,采用固定效应模型。
4 基于期望效用-熵模型和晨星基金评级的业绩预测能力
4.1 样本选取及基本统计分析
4.1.1 样本选取及基本统计分析
晨星评级公司目前为国内的开放式基金提供评级,不对货币市场基金、保本基金、其它基金、QDII行业股票基金进行评级。同时,只对存在时间在三年或三年以上的基金进行晨星评级。对于同类基金数量少于10只的类别,不公开发布其评级结果,因此本文计算基金三年的评级结果。晨星评级结果从锐思数据库直接获得。搜集锐思数据库里基金的月度收益数据进行编程计算得到EU-E模型的评级结果。
为了比较EU-E模型评级和晨星评级的预测能力,使用面板数据模型来分析基金评级结果的预测能力,并使用了Sharpe指数、Jensen、Fama-French三因素和Carhart四因素α四个不同的风险调整业绩指标来衡量基金的业绩。在计算每项指标时,按照Füss等[8]和Watson等[10]的计算方法,对于样本期内每只基金,对其每个月之前三年的数据进行滚动OLS回归得到基金业绩评价指标。为了计算这些业绩评价指标,从锐思数据库收集了以下数据:无风险利率、市场溢酬因子(Rm-Rf),市值因子(SMB),账面市值比因子(HML)和动量因子(MOM)。其中Shibor自2007年正式推出以来,在货币市场和金融产品定价中的基准作用得到了有效发挥,因此使用上海银行间3个月同业拆放利率作为无风险利率。
为了计算基金的业绩评价指标,在连续评级3年以上的642只基金中寻找月度收益数据长度大于等于101个月的基金,按照这一标准筛选后,我们获得了从2011年2月1日到2016年6月30日包含261支开放式基金的样本。对样本中261只基金从2011年2月1日到2016年6月30日的基金月度收益率序列进行基本统计分析,结果如表1所示。
整个样本期的月度收益率偏度为-0.3358,峰度为4.8754,表明基金收益不服从正态分布。同时,JB统计量为1378.10,整个样本期的月度收益是非正态分布的。传统的风险测量指标都要求收益率服从正态分布,而熵的使用是不需要已知样本收益的分布,这也可以在一定程度说明了我们使用EU-E模型的合理性。

表1 基金月度收益率序列基本统计特征
如表2所示,为保证计算结果的稳健性,我们将总的样本划分为一、三和五年期的子样本来评估基金评级在短期、中期以及长期的预测能力。为了尽可能的使用样本的信息,我们将样本期划分如下。

表2 子样本期划分
4.1.2 基金业绩评价指标的相关性分析
Eling和Schuhmacher[31]研究结果表明选择何种业绩评价指标不会影响对冲基金的排名。即使资产收益分布不服从正态分布,这些业绩评价指标也可以用来评估资产的业绩。如前所述,本文计算了四种基金业绩的评价指标,进一步计算业绩评价指标的Pearson相关性来考查不同的业绩评价指标分别作为被解释变量对基金评级结果回归的稳健性。表3显示了基金业绩评价指标的Pearson相关性。与Eling和Schuhmacher[31]的研究结果一致,各个业绩评价指标之间都存在很强的正相关性,因此在进行评级结果的预测分析中,我们列出的Sharpe指数作为被解释变量的回归结果是具有代表性的。
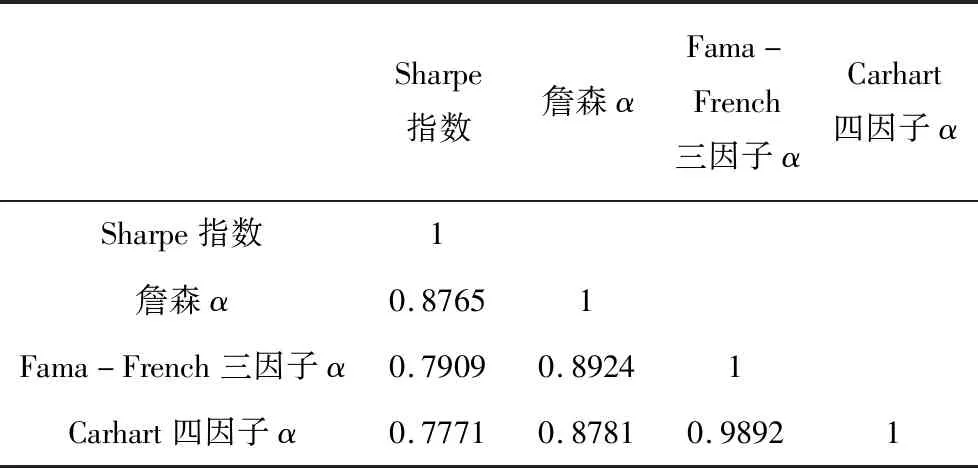
表3 四种样本业绩评价指标的Pearson相关性
4.2 基于期望效用-熵模型评级结果的预测能力
我们首先对EU-E模型结果的预测能力进行分析。本文选取效用函数为线性函数,研究λ值从0到1连续变化时基于EU-E模型的评级结果和晨星评级结果的相关性。特别地,为了说明λ值从0到1连续变化时EU-E模型的评级结果和晨星评级结果之间的相关性,以三年期样本为例,以半年期为时长滚动得到5个三年期样本,对λ从0到1连续变化的情况下,基于EU-E模型与晨星基金评级结果的Spearman秩相关系数如图1所示:

图1 基于EU-E模型与晨星基金评级结果的Spearman秩相关系数
在5个不同的三年期样本中,基于EU-E模型与晨星的基金评级结果的Spearman秩相关系数随着λ取值的变化,秩相关系数变化趋势大致相同。从图1可以看到,Spearman秩相关系数随λ值的增加而增加,且增加一定值后开始降低。基于这种相关性的变化,我们主要研究当λ=0.25和λ=0.75时基于EU-E模型与晨星基金评级的比较。
首先研究EU-E(λ=0.25)模型基金评级结果的预测能力。F检验和Hausman检验的结果均显示Sharpe指数作为被解释变量,EU-E(λ=0.25)模型基金评级结果作为解释变量的15个面板回归应采用固定效应回归模型,回归结果如表4所示。
首先,系数δ5在所有子样本中都是正的,这表明EU-E(λ=0.25)模型的5星级基金在所有子样本都获得了正的风险调整后收益。此外,系数δ4到δ1均显著,全部为负值且绝对值越来越大,即随着基金评级下降,基金的收益也随之下降。这意味着基于EU-E(λ=0.25)模型的基金评级结果具有显著的预测基金未来表现的能力。

表4 基于Sharpe指数为被解释变量的EU-E(λ=0.25)基金评级的面板回归结果
注:OBS代表观测值的个数,括号里是变量的标准差。‘***’、‘**’、‘*’分别表示0.01、0.05、0.1水平下系数的统计学显著性。固定效应面板回归结果不对常数项进行显著性检验。
进一步研究EU-E(λ=0.75)模型基金评级结果的预测能力。F检验和Hausman检验的结果均显示Sharpe指数作为被解释变量,EU-E(λ=0.75)基金评级作为解释变量的15个面板回归应该使用固定效应模型。
与基于EU-E(λ=0.25)的基金评级结果类似,基于EU-E(λ=0.75)模型的基金评级可以预测最高评级的基金,在所有子样本中获得正的风险调整后收益。此外,回归结果也呈现出从δ4到δ1的显著的且越来越负的关系,这意味着基于EU-E(λ=0.75)模型的基金评级,具有显著的预测未来基金表现的能力。
4.3 晨星基金评级结果的预测能力
F检验的结果显示,Sharpe指数作为被解释变量,晨星基金评级结果作为解释变量的15个面板回归采用固定效应回归模型好于混合回归模型,Hausman检验的结果显示随机效应回归模型好于固定效应回归模型,回归结果如表5所示。

表5 基于Sharpe指数为被解释变量的晨星基金评级的面板回归结果
注:OBS代表观测值的个数,括号里是系数的标准差。 ‘***’、‘**’、‘*’分别表示0.01、0.05、0.1水平下系数的统计学显著性。
系数δ5表示样本期5星级基金的业绩。每个虚拟变量的系数表示对应的星级类别相对于5星级基金的表现。例如,2011年2月到2012年1月的一年期子样本中,δ4为-0.020,该系数表明,在2011年2月到2012年1月期间,4星级基金平均获得的风险调整后收益比5星级基金少了2.0%。另外,系数δ3为-0.000,系数δ2为0.006,系数δ1为-0.007。这表明2星级基金表现最好,胜过1星级、3星级、4星级和5星级基金,即晨星基金评级结果在该样本中并没有表现出应有的预测能力。
4.4 EU-E模型与晨星基金评级结果的预测能力比较
对于样本期分别为一年、三年和五年共15个样本期,以四个不同业绩评价指标分别作被解释变量的EU-E模型和晨星基金评级的预测能力结果进行总结。
在研究的15个样本期,以四个不同业绩评价指标分别作被解释变量的60次回归模型中,基于EU-E(λ=0.25)和EU-E(λ=0.75)模型的基金评级结果满足δ1<δ2<δ3<δ4<0<δ5的次数均达到60次,即这两个模型都具有良好的预测能力;而晨星基金评级预测能力较弱。
基于EU-E(λ=0.25)和EU-E(λ=0.75)模型的基金评级在不同样本期都可以预测基金未来业绩,即研究结论对于一年、三年和五年的样本期都是稳健的。而对于不同的样本期,晨星评级虽有一定预测能力,但是预测能力均较弱。这与Blake和Morey[6],Gerrans[7],Füss等[8],Sah等[9]以及Watson等[10]得到的晨星评级的预测能力很弱的研究结果相符合。
我们进一步分析基于EU-E模型和晨星基金评级方法区分不同星级基金表现的能力。利用模型对5星级基金预测业绩时,因为δ5表示研究样本期内5星级基金的预测业绩,因此基于EU-E模型预测能力优于晨星评级的特征为δ5,EU-E>δ5,晨星。对于4星到1星基金预测业绩能力,由于每个被评为4星到1星的虚拟变量的系数表示被评为对应星级的基金低于5星级基金的预测业绩的差。因此,不同星级之间预测业绩的差值越大说明基金评级方法区分基金预测业绩的能力越强。这样,我们优先选取被评为4星到1星的基金相对于其上一级的基金预测业绩的差值较大的模型。据此,被评为3星到1星级的基金的EU-E模型优于晨星评级定义为:EU-E模型某一星级与前一星级的预测业绩之差大于晨星基金评级对应的星级预测业绩之差。例如考虑3星级基金预测业绩时,EU-E模型评级优于晨星评级意味着δ4,EU-E-δ3,EU-E>δ4,晨星评级-δ3,晨星评级。
在以四个不同的业绩评价指标分别作为被解释变量情况下,基于EU-E(λ=0.25)和EU-E(λ=0.75)模型的基金评级结果与晨星评级各星级基金业绩比较如表6所示。每个模型进行的回归总数是60,考虑了一、三和五年的子样本和四个不同的被解释变量。
表6结果显示,在考虑5星级基金表现时,在全部的60个回归结果中,EU-E(λ=0.25)、EU-E(λ=0.75)均优于晨星评级。在考虑1-4星级基金表现时,EU-E(λ=0.25)、EU-E(λ=0.75)也优于晨星评级,即EU-E模型评级可以更好地区分不同星级基金的业绩。

表6 基于EU-E模型与晨星两种基金评级模型面板回归的预测能力比较
5 结语
对于基金过去的业绩,市场上现有的晨星评级方法可以给予客观的评价,但不能预测基金未来的业绩。但投资者进行决策时不可避免地要考虑基金评级结果对于基金未来业绩的预测能力。本文利用EU-E模型进行基金评级,得到了2011年2月1日到2016年6月30日期间,261只基金,共65个月的16965个基金评级数据。接下来使用面板数据模型来评估EU-E(λ=0.25)、EU-E(λ=0.75)模型评级结果和晨星基金评级的预测能力。
在研究的一、三和五年共15个不同样本期,λ取值为0.25和0.75的EU-E模型评级都具有良好的基金业绩预测能力,而晨星评级预测能力较弱。同时EU-E(λ=0.25)、EU-E(λ=0.75)模型评级的5星级基金业绩优于晨星评级对应的基金业绩,EU-E(λ=0.25)和EU-E(λ=0.75)模型相比于晨星评级可以更好地区分不同星级基金的业绩。研究结论对于一年、三年和五年的样本期都是稳健的。
猜你喜欢
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
音乐天地(音乐创作版)(2020年8期)2020-11-05
中学生博览(2020年10期)2020-05-28
世界汽车(2019年2期)2019-03-01
世界汽车(2019年2期)2019-03-01
世界汽车(2019年2期)2019-03-01
冰雪运动(2018年3期)2018-12-29
琴童(2017年1期)2017-02-18
留学(2015年16期)2015-03-21
