
基于差异性代码克隆的代码块补全提示方法
2020-01-16 07:32殷康麒王鹏程
计算机工程 2020年1期
殷康麒,吴 鸣,王鹏程,徐 云
(中国科学技术大学 a.计算机科学与技术学院; b.安徽省高性能计算重点实验室,合肥 230027)
0 概述
软件编程作为软件开发中的重要步骤,其效率将直接影响软件开发的整体进程。由于集成开发环境(Integrated Development Environment,IDE)中的代码补全功能可以减少软件编程中的拼写错误和编码所需记忆,有效提高编程效率,因此被程序员广泛使用。
目前多数IDE通过增加一些简单的提示用于帮助代码补全,如已经拼写出一个对象名,然后通过查询这个对象所属的类列出此对象所有的变量名和函数名。但是目前IDE只能对特定的关键词(如对象和函数)进行补全。为能补全代码中所有的关键词,文献[1-2]对源代码进行词法分析,将其转变为基于token的源码,使用统计语言模型(如n-gram和RNN)学习token序列的规律,并利用学习后的统计语言模型对下一个token进行提示。
此外,研究者还提出了对代码行和代码块进行补全提示的方法。文献[3]提取出代码中对象所使用的API,通过API的使用序列预测下次使用的API,从而对下一行语句进行补全。文献[4]根据API的使用频率并通过关联规则挖掘等对可能会使用的API进行补全。文献[5]通过使用代码克隆方法在代码库中查找出相似的代码对代码块进行补全。
随着软件应用领域的不断扩大,基于关键词和单行函数调用的补全已不能满足编程人员的需求,是否能够实现若干连续行的代码块补全,对于提高软件开发效率至关重要。随着GitHub、SourceForge等大型代码库的出现,可供参考的代码数量变得更多,并且种类也更丰富。在此环境下,本文提出一种新的代码块补全提示方法,利用差异性代码克隆检测技术在代码库中查找与待补全代码块相似的候选代码块,并对其进行特征提取、聚类和相关性排名,从而得到候选代码块的提示顺序。
1 相关概念及问题定义
代码块是指一个函数或者是一个大括号({})里的一段语句序列[6]。代码克隆是指2个代码块有相同或相似的代码片段[7]。差异性代码克隆[6]是指2个在代码规模上有较大差异的代码块有相同或相似的代码片段,如图1所示。

图1 差异性克隆实例
IDE中的代码补全提示功能是指通过提示一些相关的信息将未完成的代码补全完整,如图2所示[1,5]。代码补全提示根据补全的粒度可以划分为关键词粒度的补全、语句粒度的补全和代码块粒度的补全,本文主要研究代码块粒度的补全提示。下文中待补全代码块是指正在编写但没有全部完成的代码块。
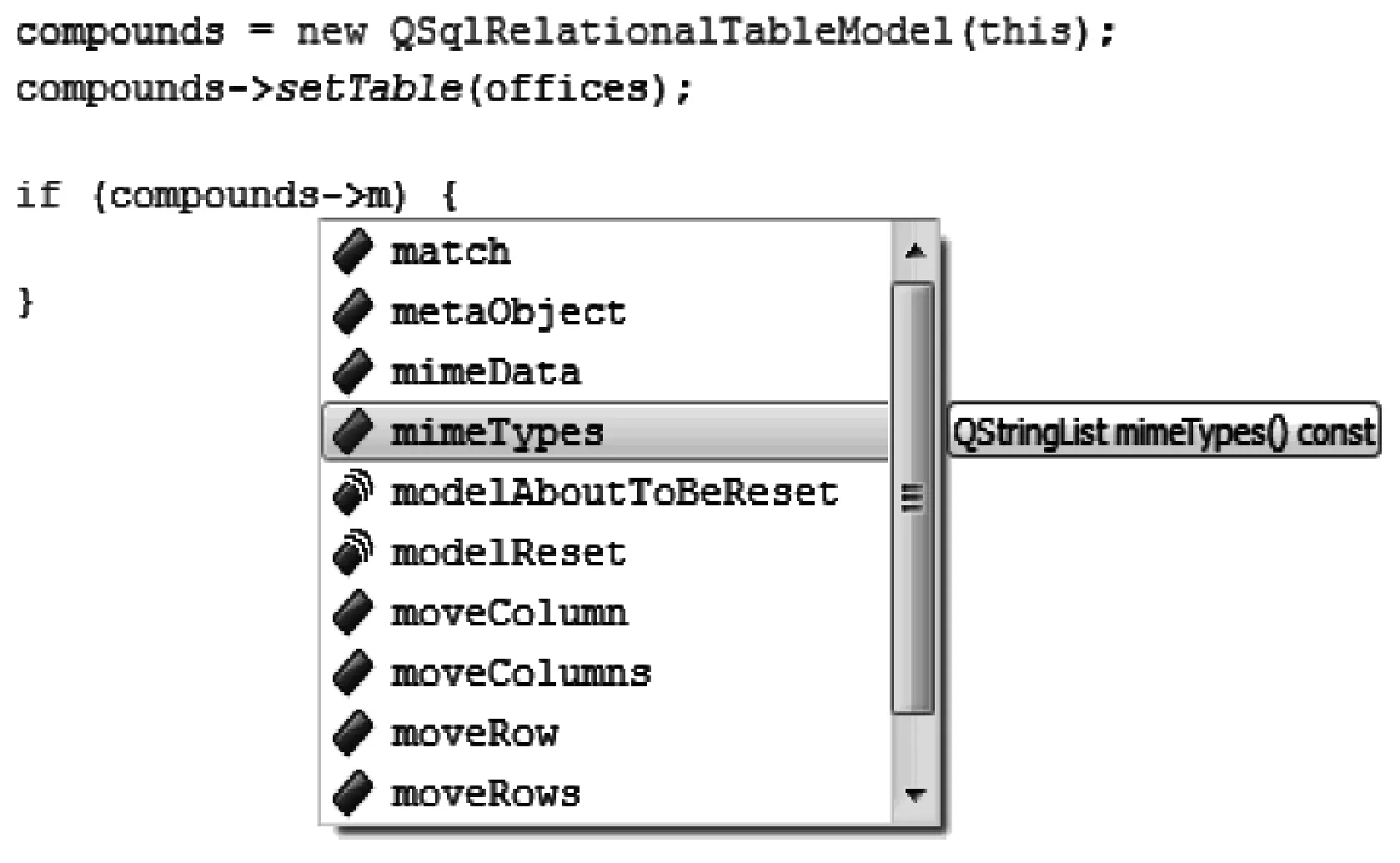
图2 代码补全提示实例
对一个正在编写但没有完成的代码块,在代码块待补全的部分添加“???”和与这部分要实现的功能相关的方法名或关键词以构造待补全代码块,如图3所示。可使用代码块补全方法在代码库中查找出与待补全代码块相似的代码块提示给程序员以辅助编程,如图4所示。

图3 待补全代码块实例

图4 代码块补全提示实例
2 补全提示方法设计
本文将差异性代码克隆方法应用于代码块补全问题,然后对克隆技术的查找结果进行特征提取、聚类、相关性打分,最后为程序员提示有用的代码块以提高编程效率,其总体流程如图5所示。
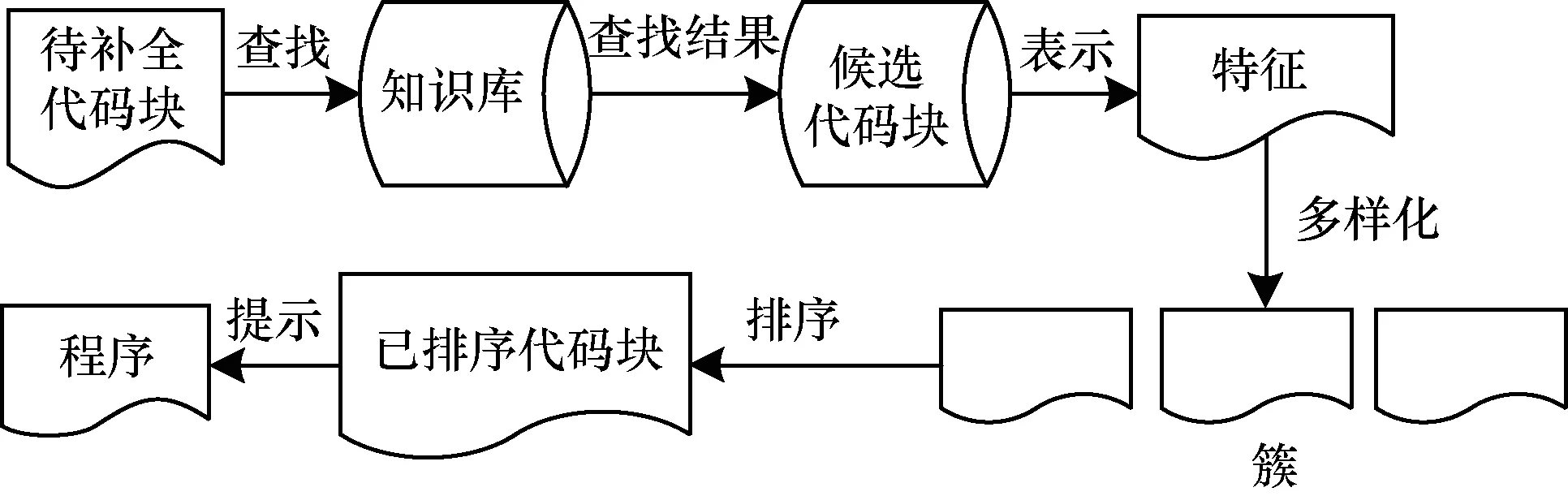
图5 代码块补全提示流程
2.1 代码克隆方法的选取与改进
为在代码库中找到与待补全代码相似的代码块,需要选取一个合适的代码克隆方法对代码库中的代码块进行粗粒度的过滤,将与待补全代码相似的代码块留下。为比较代码块之间的相似性,首先要对代码进行预处理,常用的技术有文本化[8-9]、token化[10-11]、AST化[12-13]和PDG化[14-15],因为是在大型代码库中进行查找比较,所以需要速度较快的预处理方法。AST化和PDG化技术由于算法复杂度高时间性能很差,不适合在大规模的代码库中进行查找,而文本化后的特征过于简单,查找效果很差。token化的预处理技术不仅时间性能较优,而且还保留了代码的一些的词法特征,查找效果较好。
此外,由于是对待补全代码和完整的代码块进行比较,两部分代码的规模有较大的差异,因此需要选取一个在代码规模有较大差异情况下能有效检测出代码相似性的方法。文献[6]提出的基于滑动窗口技术和带误配索引技术的匹配算法,可以有效解决这一问题,与其他的基于token化的相似代码查找方法不同,本文使用滑动的代码窗口(即连续的代码片段),而不是单个token作为比对的基本单元。对每个长为q的代码窗口,如果每个窗口允许e个误配,提取其所有的长为q-e的子串,如果至少存在一个子串匹配,则认为2个窗口是一次成功的匹配。如果2个代码块中匹配上的窗口数目符合设定的相似度阈值,则认为这2块代码段是相似代码。本文基于此算法进行改进,使其适用于代码块补全问题,具体步骤如下:
1)由于进行粗粒度过滤,因此本文在查找时设定的相似度阈值比一般查找相似代码的相似度阈值低,以找到更多的候选代码块。
2)由于只对待补全代码块进行相似代码查找,因此本文将查找模式由代码克隆的多对多模式改为一对多模式。
3)由于补全的目标是扩展代码块,因此在预处理过程直接过滤所有小于待补全代码块的代码块。
4)由于只需要寻找和待补全代码块相似的代码块,因此本文并没有存储所有滑动窗口的键值对,而只存待补全代码块窗口的键值对,有效减少了存储空间。
2.2 代码特征向量设计与聚类算法应用
用改进后的差异性代码克隆方法会在代码库找出很多符合相似性要求的代码块,本文称之为候选代码块。
因为这些代码块是在代码库中查找出来,而代码库的代码量很大且不同程序中有很多相同实现的代码块,所以找出的候选代码块数量也会很大,因此下一步需要对找出的候选代码块进行细粒度划分。
首先对代码进行特征向量设计,代码的特征有很多种,例如:衡量源代码复杂性的特征如McCabe度量元、代码块的长度[16];衡量源代码模块化的特征如调用其他方法的数量;代码中关键词和变量的种类和数量[17];建立抽象语法树从中提取表示代码结构关系的特征[18]。本文综合各类型的特征建立特征向量,具体如表1所示。
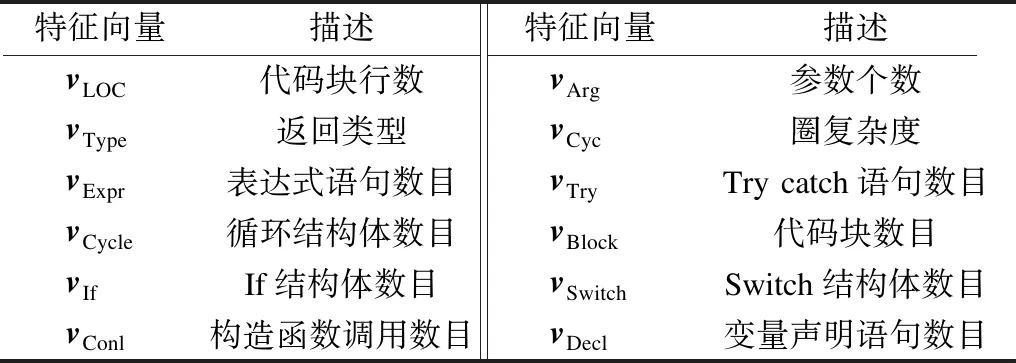
表1 代码的特征向量
对于划分而言,另一个重点是准确度量特征向量之间的相似度。由于每个特征度量的量纲不统一,如代码块行数的绝对数值相对其他特征绝对数值过大,如果使用欧式距离度量就会导致一些特征在度量时权重变得很大,其他一些特征的权重就会变得很小,余弦相似度更多是从方向上区分差异,而对绝对数值不敏感从而修正了量纲标准不统一问题,因此,本文选择余弦相似度用于度量特征向量的相似度。
在选取合适的相似度度量方法之后,下一步需要选取聚类算法对候选代码块进行细粒度划分。考虑到预先未知代码的特征向量在数据空间的分布,也未知需要划分为多少类,因此,本文选取DBSCAN作为聚类方法,这是一种基于密度的聚类算法,有一定抗噪声的能力,不需要设定生成的类别数,只需要设定一个相似度阈值,如果两个代码块的特征向量之间的相似度小于设定的阈值,便认为这两个代码块是属于一类的。
2.3 候选代码块的推荐排序
使用聚类算法对候选代码集完成进一步的划分后,本文选取每个类中与待补全代码块关键词匹配最多的代码块作为这个类别的代表性代码块。在选出代表性代码块之后,本文通过计算每个代表性代码块所属类别的代码块数(代表此类代码在代码库出现的频率)、与待补全代码块匹配的代码占总代码的比例和与待补全代码块的方法名或关键词的匹配数。根据以上3个指标的数值对每个候选代码块进行相关性打分,最后按照候选代码块的分数顺序提示给程序员。
3 实验与结果分析
3.1 数据集
3.1.1 数据集来源
首先建立供查找的代码库,为了更好地测试本文方法的效果,建立的代码库与待补全代码块之间需要较高的相似度,可以通过从大型的开源网站搜寻同类型软件的源码以建立同类型软件代码库。
本文从GitHub上搜寻了44个同属于Android Social Network类型软件的源码,然后使用TXL[19]从这44个软件的源码中提取出所有的代码块,在此基础上,对提取出的代码块进行词法分析以得到token化的代码块,将代码块转化为token化的形式是为了加快在代码库中的查找速度,最后将词法分析后的代码块与处理前的源码建立一一对应关系,通过上述操作建立Android Social Network同类型的软件代码库。
3.1.2 测试数据集构建
本文从代码库中随机挑选出代码块,从中删除部分关键代码,并在删除的部分添加与这部分要实现功能相关的关键词,对保留部分代码有2种处理,分别是不进行改变和引入一些代码突变[20](如进行变量名的替换和少数语句的添加删减),将处理完后的代码块作为待补全代码块。
3.2 评估指标
本文主要通过以下3个指标来衡量补全提示方法的效果:
1)Top-1,表示代码块补全提示方法的精确率。此指标排名第一的代码块实现了预定功能。
2)Top-3,选取此指标是考虑到程序员一般编程时重点关注前三个提示。此指标排名前三的代码块中有实现预定功能的代码块。
3)Top-10,表示代码块补全提示方法的召回率。此指标排名前十的代码块中有实现预定功能的代码块。
3.3 结果分析
本文使用交叉验证的方式对结果进行检验,把19 764个代码块随机分为4份,然后将每一份代码轮流作为测试集,而剩下的另外3份代码作为代码库。本文方法从作为测试集的每份代码中随机抽取20个代码块按照上节描述的做法构造待补全代码块。
由于文献[5]方法只能应用于代码块最后一部分缺少的情况,不能应用于代码块中间部分缺少的情况,因此本文根据代码块中缺失代码的位置进行2组实验。
第1组实验的80个待补全代码块缺失部分全部位于代码块的最后部分,2种补全方法对第1组的待补全代码块的补全结果如图6所示。
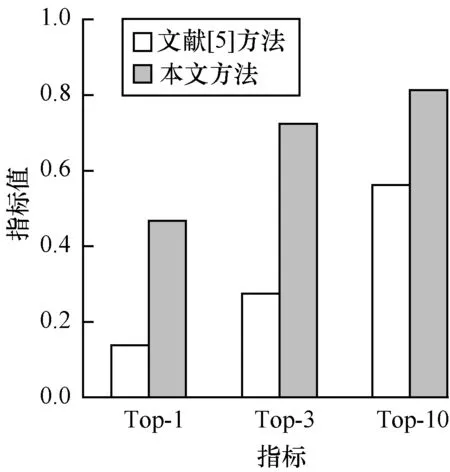
图6 第1组实验中2种补全方法的结果对比
Fig.6 Results comparison between two completion methods in experiment 1
从图6可以看出,本文方法在补全推荐的Top-1、Top-3和Top-10指标上较文献[5]方法均更优,这是因为本文使用的差异性代码克隆方法非常适用于代码块补全的问题,该查找方法可以根据现有代码的各种信息(如token的种类、位置、数量)使用局部匹配的方式在代码库中查找相似代码,而文献[5]使用的查找方法只使用了已编写代码的token种类和数量信息,查找准确率较低,因此,本文方法在Top-10上的效果更好。此外,由于代码库中重复代码很多,为了防止重复推荐,本方法通过使用聚类解决这个问题,但是文献[5]补全方法并没有解决这个问题,而且本文还使用关键词和方法名匹配作为辅助手段,使更相关的代码块排名更高,所以,本文方法在Top-1上的效果较好。
第2组实验的80个待补全代码块缺失部分随机分布于代码块的各个部分,本文方法对其补全的结果如图7所示。结合图6可以发现,相对于第1组实验的结果,本文方法在第2组实验中的结果略差,原因是由于待补全代码块缺失代码可能位于代码块的中间,从而在查找时缺失代码对前后的窗口都造成影响,加大了查找的难度。
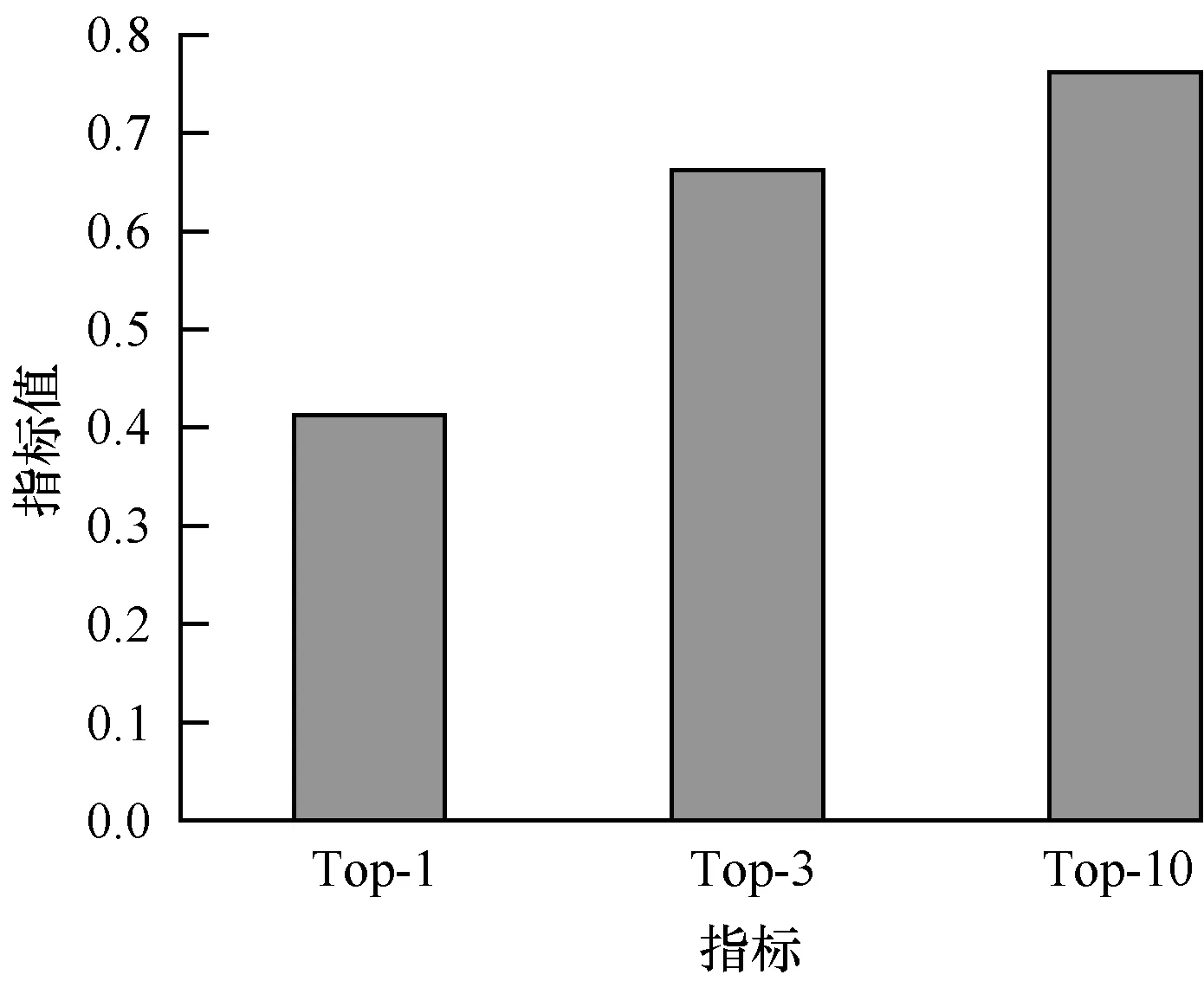
图7 第2组实验中本文方法的补全结果
Fig.7 Completion results of the proposed method in experiment 2
4 结束语
IDE代码补全难以查找规模差异较大的相似代码。针对该问题,本文提出一种基于差异性代码克隆的代码块补全提示方法。使用差异性代码克隆方法查找与待补全代码相似的候选代码集,并通过特征提取、聚类划分和相关性打分从候选代码集中挑选相关性最强的代码推荐给程序员。实验结果表明,该方法相对于文献[5]方法在Top-10指标上有大幅提高,而使用已有代码的结构信息和提示来进行精确推荐,使其在Top-1指标上也具有较好的提升效果。后续将利用代码注释等文本信息进一步提高本文方法补全提示的准确性。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
萍乡学院学报(2022年2期)2022-09-27
保定学院学报(2022年2期)2022-04-07
散文百家(2021年1期)2021-11-12
影像视觉(2020年5期)2020-06-30
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
许昌学院学报(2018年4期)2018-05-02
